基于机器学习聚类算法的门禁数据异常检测方法与流程
本发明涉及门禁
技术领域:
,特别涉及一种基于机器学习聚类算法的门禁数据异常检测方法。
背景技术:
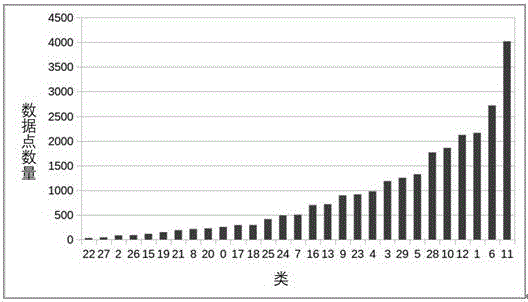
:大数据分析技术与社会化行为数据的结合在近年来得到了飞速发展,这一方面得益于大数据平台的持续发展,比如开源的Hadoop、Spark、Hbase等分布式计算、存储框架的成熟。这些新技术伴随着互联网行业的爆发,已经被广泛应用于服务器的恶意请求分析、垃圾邮件过滤、购物推荐、图像识别等领域。基于机器学习的聚类、分类、回归等算法借助分布式大数据平台和工具的威力使得人们有能力对不断增长的数据规模进行深度分析。另一方面,得益于多种类型的传感器被大量应用于检测和收集社会化行为数据,可供分析的数据资源空前丰富。怎样从所获得的数据中挖掘出社会化行为的规律、特征及其他深度信息,成为一个具有相当高研究价值的问题。已有的应用比较成熟的领域有医疗疾病治疗、人类基因编码分析、交通导航等。而在非商业领域,新技术推进的步伐并不是很快,比如对出入社区门禁人员的异常刷卡行为的监测方面,门禁记录数据的分析利用仍处于初级阶段,仅限于记录社区人员和来访人员的进出门禁情况,用以统计常住人口和来访人员。而且门禁系统自身的运行效率和状态往往受到人为管理水平不稳定和门禁设备不够完善等缺陷的约束,对记录的进一步挖掘和利用极其匮乏。技术实现要素:为了解决上述发明问题,本发明提供了一种基于机器学习聚类算法的门禁数据异常检测方法,实现对门禁记录数据的自动分类,根据每类中记录的数量值可以合理给出异常度的定义,其中记录数量最少的类即为最异常类。具体地,为达到上述目的,本发明提出了基于机器学习聚类算法的门禁记录异常度分析方法,内容包括:步骤1、数据清洗:清除原始门禁记录中的无效数据。原始门禁记录中因违规管理(多人同时使用一张门卡进出门禁等情况)、设备功能不完善(设备采样率设置不合理或异常)等问题,出现个别门卡刷卡次数远高于多数门卡、短时内重复刷卡等情况,进而表现为门禁记录中的无效数据。数据清洗的方法为:统计门禁记录中每个门卡号的刷卡次数和刷卡时间序列,删除刷卡次数超过某个阈值(例如每日刷卡次数排名前十)的门卡号记录,再删除相邻刷卡时间间隔小于某个阈值(例如30秒)的记录。经此处理,得到可进一步分析的有效门禁记录数据。步骤2、提取门禁记录的刷卡行为特征。特征提取是整个方法中最关键的一步,所提取的特征需能够合理反映门禁刷卡行为是否存在异常。经步骤1清洗之后的单条门禁记录的存储格式为(Index,ID,time,gateflag),其中Index为刷卡记录的序号,ID为门卡号,time为刷卡时间,gateflag为进出门禁的标识,gateflag=1表示进入小区,gateflag=0表示离开小区。可以预见,与一个门卡是否存在异常相关联的因素至少包含:一天内的刷卡次数、刷卡时间分布、进出门禁的比例。基于此,统计在一天内单个门卡在0-5时、6-11时、12-17时、18-23时四个时间段内的刷卡次数,记为n1、n2、n3、n4,将原门禁记录格式转化为(ID,n1,n2,n3,n4,gateflag),新格式能表征前述与门卡异常度相关联的三个因素,即为所提取的门禁记录刷卡行为特征。步骤3、基于机器学习的聚类分析。一个中等规模社区的门禁系统经过三个月到半年时间将累积产生几十万到上百万条记录,此数据规模适合采用机器学习方法。所采用的K均值聚类算法的核心思想:将步骤2得到的特征记录投射到特征空间中,每条记录对应为空间中的一点,将空间中的所有数据点按照距离远近进行分类,最终所有的数据点都被划分到与其最近的类中。聚类计算需要人为设定合理的类数量,一个简单的办法是考虑数据点与所对应类的中心的距离,当将所有数据点划分到n个类时,计算所有数据点与其类心距离的总和,该值随着分类数量增加而逐渐减少,在n达到某一个阈值时,再增加分类数量不会明显减小总距离,这个阈值即可设为最终的分类数量。步骤4、定义异常度、抽取异常刷卡行为。通过K均值方法可以将记录数据划分到n个类中,有两种方法定义数据的异常度,一是计算每个数据点距离所有数据中心的距离,值越大表示该点异常度越高,二是按照每一类的数据量定义异常度,类内数据点越少表示该类越异常。因为第一种方法计算量较大,所以本发明采用第二种方法,数据点最少的类中的记录即为异常刷卡行为。本发明实施例的有益效果是:深度挖掘出社区门禁信息,能够得到异常记录,是加强社区安全管理的有力工具。开创性地运用机器学习技术,与常规的人工搜索相比,能够更精准地得到数据中的异常信息,尤其适用于动态递增的海量数据情况。根据由计算得到的异常度,能有效判断任一记录的安全等级。由历史纪录提炼出的数据模型,可实时处理新出现的记录,实时判断该记录的异常度。附图说明图1为本发明实施例的基于机器学习聚类算法的门禁数据异常检测方法流程图。图2为本发明实施例的异常类计算结果。具体实施方式实施例1参见图1与图2,本发明提供一种基于机器学习聚类算法的门禁数据异常检测方法。以某社区的真实门禁数据为例,详细描述本发明的操作步骤。步骤1、数据清洗。原始数据记录的时间跨度为三个月,典型的刷卡记录如下:表1社区门禁刷卡原始记录示例记录序号卡号刷卡时间进出标识8079002345212016-03-1821:45:3218100002374532016-03-1913:18:2618314002354192016-03-1913:33:4718682002301732016-03-1914:11:2708802002325172016-03-1914:19:131表中第一列为每条记录对应的序号;第二列为门卡号;第三列为刷卡时间;第四列为进出门禁的方向标识,“1”表示出,“0”表示进。门禁系统因为存在管理疏漏,经常出现管理人员使用同一张卡打开门禁的情况,所以原始数据中存在个别门卡号刷卡次数过多;同时门禁系统的刷卡设备存在采样率设置不当或采样不稳定等问题,间断性地出现在短时内(比如10秒)多次记录同一刷卡行为,导致原始记录中存在一定量的冗余。由这些因素导致的无效记录信息,需要通过统计分析进行排除,采用开源的ApacheSpark进行数据清洗操作,代码如下。//导入时间处理相关的三个库,对原始记录中的时间格式进行调整importjava.sql.Timestampimportjava.text.SimpleDateFormatimportjava.util.Date//导入原始数据,并对数据进行初步解析valinput=sc.textFile("dir/to/data.csv").map{x=>x.split(",")}.map{x=>(x(2),(x(3),x(1),x(4),x(0)))}//转换数据中的时间格式valresidents=input.map{case(x,(y,z,g,h))=>(x,List(Timestamp.valueOf(y).getTime.toString,z,g,h))}.cache//检索刷卡次数最多的门卡号valresidentCount=residents.countByKey.toList.sortBy{case(id,count)=>count}.reverse//删除出现次数过多、时间间隔过小的记录valperIdInfor=residents.groupByKey.map{case(id,other)=>{vartemp1=other.toList.sortBy{x=>x(0).toLong};(id,temp1)}}valreducedRecords=perIdInfor.map{case(id,other)=>{vartemp2=List(other(0));for(i<-0toother.length-2){if(other(i)(2).toInt!=other(i+1)(2).toInt){vartemp3=temp2:::List(other(i+1));temp2=temp3;}else{if(other(i+1)(0).toLong-other(i)(0).toLong>300000){vartemp3=temp2:::List(other(i+1));temp2=temp3;}}};(id,(temp2.length,temp2))}}步骤2、特征提取。原始数据以每一次刷卡记录为一条数据,而我们关心的是同一门卡号在一天内的总体刷卡行为,所以需要对清洗后的数据按天进行划分,并统计一天内同一门卡号的刷卡行为,代码如下:valreducedData=reducedRecords.flatMapValues{case(n,records)=>records}//以天为单位统计单个门卡号的记录,并提取其在0-5时、6-11时、12-17时、18-23时四个时间段上刷卡次数作为特征。valrefDate=Timestamp.valueOf("1970-01-0100:00:00").getTimevalperDayData=reducedData.map{case(id,other)=>{vardayGap=(other(0).toLong-refDate)/86400000;varquartDayNum=(other(0).toLong-refDate)/21600000%4;(id++"#"++dayGap.toString,List(dayGap.toString,quartDayNum.toString,other(1),other(2),other(3)))}}valperIdDayData=perDayData.groupByKeyvalperDayFeature=perIdDayData.map{case(id,other)=>{vartempOther=other.toList;varflagOne=other.toList.map(x=>x(3).toInt).sum;varq0=other.toList.filter(x=>x(1).toInt==0).length;varq1=other.toList.filter(x=>x(1).toInt==1).length;varq2=other.toList.filter(x=>x(1).toInt==2).length;varq3=tempOther.length-q0-q1-q2;(id,List(q0,q1,q2,q3,flagOne*1.0/tempOther.length))}}在上述代码中,将以(ID,time,gateflag)格式存储的记录转变为(ID,特征)的格式。将全天时间根据当地时区分为0-5时、6-11时、12-17时、18-23时四个时间段,分别统计单个ID在一天内在前述四个时间段内的刷卡次数,相应记为n1、n2、n3、n4。经此处理,原记录转变为(ID,n1,n2,n3,n4,gateflag)的格式,其中特征项n1、n2、n3、n4能同时体现某个ID在某一天内的刷卡时间分布特征和刷卡次数特征,特征项gateflag能体现该ID进出门禁的方向特征。步骤3、聚类分析。聚类算法分析中需要人工设定分类数目K,所选定的K值需使得分类结果趋于稳定。判断分类结果质量的一种方法是计算所有数据点与相应类心的距离平均值。为此,在下面所示的代码中定义了distToCentroid函数用以计算该距离,并在K值范围5-40内分别计算平均距离,通过比对不同K值的平均距离,以选定合理的K值,在本实例中,最终选定的K=30。defdistance(a:Vector,b:Vector)={math.sqrt(a.toArray.zip(b.toArray).map(p=>p._1-p._2).map(d=>d*d).sum)}defdistToCentroid(datum:Vector,model:KMeansModel)={valcluster=model.predict(datum);valcentroid=model.clusterCenters(cluster);distance(centroid,datum)}importorg.apache.spark.rdd._defclusteringScore(data:RDD[Vector],k:Int)={valkmeans=newKMeans();kmeans.setK(k);valmodel=kmeans.run(data);data.map(datum=>distToCentroid(datum,model)).mean()}(5to40by5).map(k=>(k,clusteringScore(K_data,k))).foreach(println)需要注意的是,上述代码仅用于选取K值,一旦该值给定,这些代码将不再使用,不包含在生产代码中。选定K值后,下一步工作是对数据进行机器学习,代码如下。valkmeans=newKMeans()kmeans.setK(30)valmodel=kmeans.run(K_data)步骤4、结果提取。使用上述机器学习获得的聚类模型,应用于所有数据记录,可得到每一记录的归属类,并统计每一类的记录数量。代码如下。//计算每个数据点所属的类,并统计类内的数据点数量。valcluster_feature=feature.map{case(label,datum)=>valcluster=model.predict(datum);(cluster,label,datum)}valclusterCounts=cluster_feature.map{case(x,y,z)=>x}.countByValue.map{case(x,y)=>(y,x)}.toList.sortBy{case(x,y)=>x}然后统计记录数量最小的类,这些类即是需要查找的异常类,代码如下。valabnormalCluster=clusterCounts.take(selected_K/5)valabnormalRecords=abnormalCluster.map{case(count,cluster)=>cluster_feature.filter{case(c,label,datum)=>c==cluster}.collect}valabnormalData=abnormalRecords.flatMap(x=>x.toList)//抽取异常类中的记录valabnormalID=abnormalData.map{case(cluster,id,vector)=>(id.slice(0,18),cluster)}valabnormalID_2=sc.makeRDD(abnormalID).repartition(1).countByKey.toList.sortBy{case(id,count)=>count}.reverse步骤5、结果验证。K均值分析得到的聚类结果如图2所示。类内记录数量直接与异常度关联,类22的异常度最高,类11的异常度最低。本实例中选取所有类的1/5作为异常类输出,即为类22、27、2、26、15和19,由上面可见,这6个类的记录总数并不是很多,较合理地定义了异常类。随机选取类22和11中个5条记录,以验证分类质量。结果如下表所示。表2类22中的记录示例ID0-5时(次)6-11时(次)12-17时(次)18-23时(次)“出”占比100780.53201590.4300760.464301060.42500570.5表3类11中的记录示例ID0-5时(次)6-11时(次)12-17时(次)18-23时(次)“出”占比100011200010300010400010500010表2表示异常的刷卡行为包括下午和晚上的多次刷卡,表3表示最正常的刷卡行为是晚上出现的单次刷卡。这里需要进一步解释为什么最正常的刷卡行为出现在下班之后,而不是早上上班时,原因是早上上班人流较集中,一次刷卡,多人可以一起出门禁,多数人都不用刷卡,而晚上下班时,分散的陆陆续续的刷卡较多。通过简单的对比,能够说明此聚类分析结果的质量较好。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1