一种基于关联规则的重特大交通事故致因识别方法与流程
本发明属于交通事故安全研究领域,涉及一种基于关联规则的重特大交通事故事故致因识别方法。
背景技术:
近年来,随着居民出行的安全意识不断提升以及各种信息化智能控制和诱导技术在交通安全领域中的大量使用,我国的道路交通安全形势总体平稳,交通事故万人伤亡率正逐年不断降低,但是群死群伤的重特大道路交通事故问题却日趋突出,给社会和人民生活带来了巨大的负面影响。
重特大交通事故为一次死亡10人以上的交通事故。与传统道路交通事故相比,我国重特大道路交通事故的调查工作更加全面。一次死亡10-29人的重特大道路交通事故是由事故发生地省级人民政府、设区的市级人民政府、县级人民政府组织事故调查组负责调查;一次死亡30人以上的重特大道路交通事故由国务院或者国务院授权有关部门组织事故调查组进行调查。事故调查组会在事故发生之日起60日内提交一份较为详细的事故调查报告。所有重特大道路交通事故数据最终是由公安部交通管理局进行汇总统计,并发表在每年的道路交通事故年报中。
由于重特大交通事故的伤亡程度和带来的经济损失都远远超过普通交通事故,因此近年来重特大道路交通事故的致因分析和事故机理研究受到了越来越多的重视。而目前国内外关于道路交通事故的致因分析和机理研究,其研究对象均侧重于传统交通事故,而较少涉及重特大交通事故。由于重特大交通事故通常是由多个致因共同导致,其事故特征和发生机理与传统交通事故存在一定差异。此外我国现有的重特大交通事故致因研究大多基于定性分析,缺乏现成的重特大交通事故数据库,加上重特大交通事故的发生频次较低,属于稀疏型数据,故将传统交通事故的统计分析方法直接用于重特大交通事故会导致评价结果不准确。
随着机器学习和人工智能方法的发展,许多成熟的理论与方法不断用于交通安全分析领域中。关联规则分析用于发现事件中频繁发生的属性集,早期被用于分析顾客购物篮中不同商品之间的联系,分析顾客的购买习惯。与传统的统计分析方法相比,关联规则分析无需事先明确研究中的因变量和自变量,这使得一些不易发现却有研究价值的关联关系,可以在关联规则中得到充分挖掘。
技术实现要素:
技术问题:本发明提供了一种降低了随机性和决策人员主观判断影响,可以有效进行重特大交通事故致因识别、分析重特大交通事故机理的基于关联规则分析的基于关联规则的重特大交通事故致因识别方法,克服了传统交通事故致因分析方法无法直接用于重特大交通事故致因分析的缺陷,解决现有重特大交通事故致因分析主观性过强,缺乏定量分析的问题,
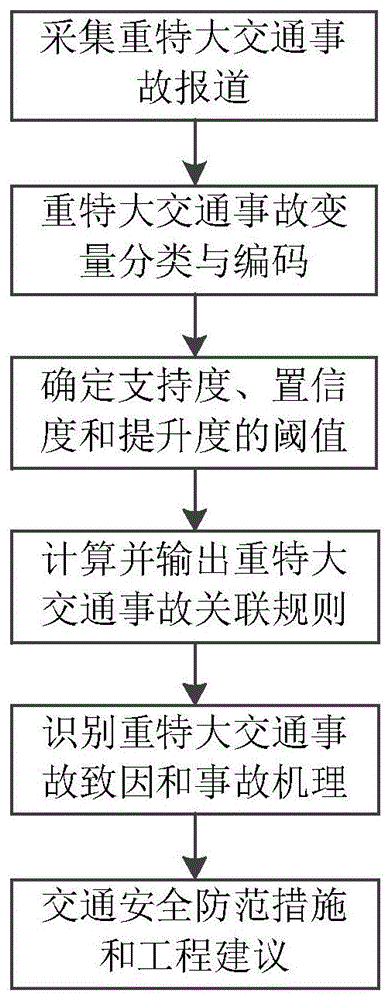
技术方案:本发明的一种基于关联规则的重特大交通事故致因识别方法,包括以下步骤:
1)采集历年重特大交通事故信息,统计驾驶人、车辆、道路以及环境四方面的事故致因信息,将四方面事故致因信息合计丢失度超过20%的事故信息剔除;
2)根据所述步骤1)中采集到的重特大交通事故信息,将每起事故信息中的文本信息编码为驾驶人、车辆、道路、环境、其他共五个维度的事故变量:I1,I2,I3,I4,I5,每个维度的事故变量下面又划分为若干个子变量:I11,I12,I13,I14,...;
3)根据下式计算重特大交通事故关联规则A→B的支持度Support(A→B):
其中N代表重特交通事故的样本总数,#(A∩ B)代表重特大交通事故中事故致因A和事故致因B同时发生的频次;对于重特大交通事故关联规则A→B,A称为规则前件,B称为规则后件;
根据下式计算重特大交通事故关联规则A→B的置信度Confidence(A→B),即在规则前件发生的条件下,规则后件发生的条件概率:
其中,Support(A)为事故致因A的支持度,即由事故致因A引起的事故占事故样本总数的比例;
根据下式计算重特大交通事故关联规则A→B的提升度Lift(A→B),即用于反映规则前件和规则后件之间的相互依赖程度:
其中,Support(B)为事故致因B的支持度,即由事故致因B引起的事故占事故样本总数的比例;
4)设定支持度、置信度和提升度的最小阈值,根据所述步骤3)得到的关联规则的支持度、置信度和提升度,将同时满足这三个参数最小阈值的关联规则选出,作为重特大交通事故致因分析的对象;
5)对所述步骤4)中确定的作为重特大交通事故致因分析对象的关联规则,统计规则的前件和后件中出现的事故致因项,对事故致因项出现的次数进行排序,选取排在前10%的事故致因项作为重特大交通事故的常见致因。
进一步的,本发明方法中,步骤1中,驾驶员特征包括年龄、性别、驾龄、驾照类型以及交通违法记录信息;车辆特征包括车辆类型、车牌号、车辆注册日期、车辆保险日期、车辆年检日期以及车辆所有人信息;道路特征包括道路等级、道路宽度、道路线形、路面条件、标志标线以及视距信息;环境特征包括天气条件、事故地点、事故发生日期和时间信息。
进一步的,本发明方法中,步骤4)中,过滤重特大交通事故关联规则的支持度的最小阈值Support、置信度的最小阈值Confidence和提升度的最小阈值Lift分别为:Support≥10%,Confidence≥70%以及Lift≥1.5。
进一步的,本发明方法中,步骤2中子变量的划分按照下表进行:
本发明将关联规则分析用于重特大交通事故的机理研究,其中每起事故可以看作是一笔购物记录,而重特大事故的致因则可看作是购物篮中的商品项。通过关联规则分析可以挖掘出重特大道路交通事故中频繁出现的事故致因及其相互关系。将关联规则分析方法用于重特大交通事故致因识别与事故机理研究中,可以定量分析各个事故致因之间的联系,操作简便,且无需实证。
有益效果:本发明与现有技术相比,具有以下优点:
本发明的一种基于关联规则的重特大交通事故致因识别方法,从我国历年道路交通事故年报中提取重特大交通事故数据,并将提取的事故数据划分为人、车、路、环境以及其他因素共五类事故变量。在此基础上,该方法运用关联规则分析,识别重特大道路交通事故常见致因和事故发生机理。而传统装置的分析方法的随机性较大,受决策人员主观判断影响较大,缺乏定量性的事故致因描述的缺陷。根据本发明可以有效进行重特大交通事故致因识别、分析重特大交通事故机理,对加强工程安全防范方面具有实际的工程运用价值。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合实施例和说明书附图对本发明作进一步的说明。
本实施例中,对我国2009年至2013年的重特大交通事故进行数据采集,并进行以下操作。
1)构建重特大交通事故数据库。按照附表1所示的变量分类和编码方式,将2009年至2013年的重特大交通事故事故报道编码为对应的事故变量:
表1 2009年至2013年我国重特大交通事故数据列表(部分)
2)将上面的重特大交通事故数据列表输入至R语言统计分析软件,选择关联规则分析的算法为Apriori算法,并且设置关联规则支持度、置信度以及提升度的阈值。在实践中这三个指标的阈值是依据经验反复实验而定,每次根据过滤出的规则的含义来调整相应阈值大小,直到过滤出的规则可以指导交通安全实践。在本实施方式中,关联规则分析的支持度(S)、置信度(C)和提升度(L)的阈值分别设为:S≥10%,C≥70%以及L≥1.5,过滤出的重特大交通事故关联规则见表2。
表2重特大交通事故关联规则结果(部分)
4)根据步骤3中获取的关联规则,统计规则的前件和后件中出现的事故致因项,对事故致因项出现的次数进行排序,选取排在前10%的事故致因项作为重特大交通事故的常见致因;并结合交通安全的领域知识,解释规则前后件蕴含的因果关系。最终可总结出如下五条重特大交通事故机理:
(1)驾龄较短的司机在超载驾驶时更易发生重特大交通事故;
(2)驾驶人的超速和不当驾驶行为构成了高速和国道上重特大事故的主要致因;
(3)在安全设施较好的高等级道路上,车辆性能故障是重特大交通事故的重要致因,这些性能故障通常包括爆胎、制动失效以及转向功能故障。
(4)在低等级公路和下坡弯道处发生重特大坠车和翻车事故的概率较高;
(5)恶劣天气下,驾驶人的超速和不当驾驶行为会增加重特大交通事故的风险。
基于上述事故机理分析,总结如下三条重特大交通事故工程防范措施和政策建议:
(1)加强驾培市场的管理,提高驾驶人培训质量,针对六年以上驾龄的司机,加大对其驾驶行为考核和安全态度认知教育工作的力度。
(2)加大对故障车辆的核查并禁止其在高速行驶,并加强对高速超速、超载行为的处罚力度和监管水平。
(3)提高公路护栏安全防护设置标准,适度提高下陡坡、急弯组合线形路段、长下坡底部加弯道路段等特殊路段的护栏等级,优化山区公路事故易发路段的减速标志和振动减速标线的设置。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!