面向BS架构的数据接口生成方法与流程
本发明涉及一种面向BS架构的数据接口生成方法。
背景技术:
对于大多数网站而言,网站没有配置参数和查看参数的API使得开发者如果要更改或查询服务器的配置或参数必须先进行登录,然后点击多个页面完成参数配置。而开发者大部分的时间都花在了参数配置和查看信息上,这样的效率显然是低下的。如果有API的话,开发者可以通过调用API获取或是修改服务器相关配置信息。但是大部分网站提供很少或是没有提供相对应的API,而且让开发者自己封装API也是十分困难的,因为这需要开发者对网站结构,后台发送的HTTP请求等信息有所了解,同时开发者也不应该在与开发无关的工作上面花费多余的时间。然而在封装API的过程中可能会碰到以下困难:
对HTTP数据请求的处理:1、对于网站操作而言,我们能获取到的信息只有HTTP请求包,然而我们应该从这些请求中提取出哪些有用的信息,以及这些信息之间的有什么样的联系等等,这些问题都给后续工作带来一定的困难。
2、网站的状态性维持:对于实现一个操作而言,我们需要连续发送一系列的HTTP请求,而请求之间是有顺序关系并且如果缺少某一个请求可能操作就没有办法实现。这就涉及到请求之间状态的转化,所以如何维持网页的状态也是研究中所面临的挑战。
所以我们需要有一套能自适应封装API的系统来简化开发者日常的管理工作,免去开发者自己封装API的繁琐。
技术实现要素:
本发明的目的在于提供一种面向BS架构的数据接口生成方法,通过该方法,用户只需要上传数据集,填写所需API信息,便可自动封装出特定API。
为实现上述目的,本发明的技术方案是:一种面向BS架构的数据接口生成方法,包括如下步骤,
S1、源数据处理:从用户上传的HTTP请求集合中提取出关键信息,建立HTTP请求模型,并对集合进行分类;
S2、模型到图的转化:根据HTTP请求模型,定义有向图的节点和边的含义,并对图进行优化;
S3、API封装:根据有向图中信息,形成请求路径,按照不同功能生成对应API。
在本发明一实施例中,所述步骤S1中,所述HTTP请求模型为Request请求模型,该Request请求模型包括请求目的地址、请求源地址、请求类型、请求方法、请求头部、请求参数、返回页面。
在本发明一实施例中,所述步骤S2具体实现如下,
首先,定义有向图的节点Node在形式上相当于一个页面,该节点包括页面地址url和页面内容content;有向图的边Edge表示一个节点可达另一个节点;
其次,根据Request请求模型,映射出有向图的节点集合和有向图的边集合,进而获得有向图G:
G=<Nodes,Egdes>
其中,Nodes表示有向图的节点集合,Node∈Nodes,Edges表示有向图的边集合,Edge∈Edges;
最后,采用路径优化、相似节点优化方式对有向图进行优化。
在本发明一实施例中,所述路径优化,即将有向图转换为树的形式,
对于每一个树的节点Tnode∈Tnodes ,Tnodes 表示树的节点集合:Tnode=<nodeType,url,childs,content>;
其中,nodeType表示树节点Tnode的节点类型,url等价于有向图G中 Node.url,childs 表示子节点集合,content等价于有向图G中Node.content;
对于树的边集合TEdges∈有向图的边集合Edges。
在本发明一实施例中,所述相似节点优化,具体实现如下,
通过遍历树中所有节点,通过比较每个节点的子节点DOM树结构来判断该节点是否存在相似子节点,若存在将相似节点合并成新节点;并在树的节点集合TNodes 中加入属性ProSame用于表示该树的节点Tnode下相似节点集合,取出相似节点的最长前缀作为默认值,将前缀后的内容作为新的参数需要用户输入;其中,DOM树结构是通过对node.content中的xml文档转化而来。
相较于现有技术,本发明具有以下有益效果:
本发明提出一种自动化封装网站API的方法,简化用户日常复杂繁琐的操作,用户无需对网络请求报文或是API等知识有相关了解。用户只需要填入所需要的参数信息,设置API名称,系统便可以封装出对于API,在以后的操作中无需重复的步骤,便可以直接调用该API。
附图说明
图1为本发明方法概览图。
图2为未优化的有向图路径。
图3相似节点图。
图4为优化后的有向图路径。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1-4所示,本发明的一种面向BS架构的数据接口生成方法,包括如下步骤,
S1、源数据处理:从用户上传的HTTP请求集合中提取出关键信息,建立HTTP请求模型,并对集合进行分类;
S2、模型到图的转化:根据HTTP请求模型,定义有向图的节点和边的含义,并对图进行优化;
S3、API封装:根据有向图中信息,形成请求路径,按照不同功能生成对应API。
所述步骤S1中,所述HTTP请求模型为Request请求模型,该Request请求模型包括请求目的地址、请求源地址、请求类型、请求方法、请求头部、请求参数、返回页面。
所述步骤S2具体实现如下,
首先,定义有向图的节点Node在形式上相当于一个页面,该节点包括页面地址url和页面内容content;有向图的边Edge表示一个节点可达另一个节点;
其次,根据Request请求模型,映射出有向图的节点集合和有向图的边集合,进而获得有向图G:
G=<Nodes,Egdes>
其中,Nodes表示有向图的节点集合,Node∈Nodes,Edges表示有向图的边集合,Edge∈Edges;
最后,采用路径优化、相似节点优化方式对有向图进行优化。
所述路径优化,即将有向图转换为树的形式,
对于每一个树的节点Tnode∈Tnodes ,Tnodes 表示树的节点集合:Tnode=<nodeType,url,childs,content>;
其中,nodeType表示树节点Tnode的节点类型,url等价于有向图G中 Node.url,childs 表示子节点集合,content等价于有向图G中Node.content;
对于树的边集合TEdges∈有向图的边集合Edges。
所述相似节点优化,具体实现如下,
通过遍历树中所有节点,通过比较每个节点的子节点DOM树结构来判断该节点是否存在相似子节点,若存在将相似节点合并成新节点;并在树的节点集合TNodes 中加入属性ProSame用于表示该树的节点Tnode下相似节点集合,取出相似节点的最长前缀作为默认值,将前缀后的内容作为新的参数需要用户输入;其中,DOM树结构是通过对Node.content中的xml文档转化而来。
以下为本发明的具体实现过程。
如图1所示,本发明的面向BS架构的数据接口生成方法由三个部分组成:源数据处理,模型到图的转化,API封装。其中,源数据处理是从用户上传的HTTP请求集合中提取出关键信息,建立HTTP请求模型,并对集合进行分类;数据到有向图的转化是为了建立数据之间的关联,根据HTTP请求模型,定义有向图的节点和边的含义,并对图进行优化;API封装是根据有向图中信息,形成请求路径,按照不同功能生成对应API。通过本发明,用户只需要上传数据集,填写所需API信息(包括API名称,所含参数),便可自动封装出特定API。
、源数据处理
网站使用者在网站内进行一项操作实际上是后台发送HTTP请求实现的。因此在进行信息浏览或是数据处理的过程中会产生一系列HTTP请求,而这些请求便是我们实现API封装所需要的数据。但是,数据中有很多信息不是我们所需要的。所以,我们需要对HTTP请求进行处理。
首先,我们将请求分成两类,一类是SET类型,另一类是GET类型。GET类型我们认为是用来到达某个页面的路径的方式,并且GET类型请求会带来状态的改变,因为用户的每一次页面的点击是有顺序的,到达某一页面是通过发送多次请求并按一定顺序实现的,而不是直接发送一个请求就可以完成的,所以不同的GET类型请求会带来状态的改变。对于SET类型请求,我们认为是无状态的,是为了用于实现某一操作,例如提交表单和上传文件。但这并不代表可以在任意页面直接发送不属于该页面的SET类型请求实现操作,我们仍需要到达特定页面才能发送特定的SET类型请求。而到达特定页面的方式就是通过发送GET类型请求实现的。
我们从HTTP请求中提取特定信息,建立Request请求模型。一个Request模型包括请求目的地址(url),请求源地址(refer),请求类型(type),请求方法(method),请求头部(headers),请求参数(parameters),返回页面(content)。
以下是一个请求模型:
<Request>
<url>http://tomcat.apache.org/whichversion.html</url>
<refer>http://tomcat.apache.org/</refer>
<type>GET</type>
<method>GET</method>
<headers>
<Host>tomcat.apache.org</Host>
<User-Agent>
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0
</ User-Agent>
<Accept-Language>zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3</ Accept-Language>
<Connection>keep</ Connection>
</headers>
<parameters>
<sitesearch>tomcat.apache.org</sitesearch>
<p>java</p>
</parameters>
<content></content>
</Request>
2、数据到图的转化
完成一个完整的操作需要多个Request请求配合实现的,所以我们需要找出Request请求之间的联系。有向图能够很好的表达节点之间的关系,比如我们可以把从某一页面到达另一个页面的过程看作是从某一节点到达另外一个节点的路径。而具体需要做的操作则是到达特定页面时才可以完成的。所以我们需要从Request请求中提取关键信息,定义节点和边的含义,完成从数据到有向图的转化。
节点的描述:一个节点(Node)在形式上相当于一个页面,但并不代表一个具体的HTML页面,一个Node包含页面地址(url)和页面内容(content)。url信息表示了该节点的标识符,用来识别不同节点。content表示了该节点的详细内容,通常来说,当我们需要得到网页上的数据时,我们需要通过访问该节点的content来获取特定的数据内容。
边的描述:若一个节点可达另一个节点,即在某一页面发送HTTP请求后跳转到另一个页面,则我们说两节点间存在一条有向边(Edge)。一条Edge包含对应request请求的编号requestID,前驱节点的url属性值(from),To表示后继节点的url属性值。当点Node1和点Node2有边edge相连时,我们可以通过查找edge中requestID所对应的具体请求信息发送HTTP请求,从而从Node1对应页面到达Node2对应页面。
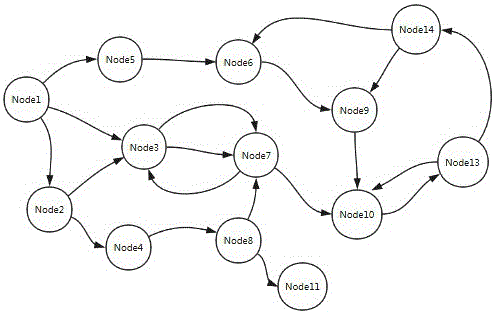
通过算法1,我们可以从Request集合映射出节点集合和边集合,进而获得有向图G=<Nodes,Egdes> ,如图2所示。进一步说,我们可以通过构造出的有向图得到从某一页面到达另一页面的路径,如要到达Node9对应页面,我们需要依次经过如下步骤到达:Node1->Node5->Node6->Node9。为了维持网页内的状态,当我们需要完成某一操作时,需要沿着图中所给定的路径,依次发送有向边所对应实际HTTP请求,直到到达指定页面,再继续完成对应操作。
算法1:节点和边集合构造
输入: Request[]←请求集合
输出: Node[]←节点集合
Edge[]←边集合
开始
…
for request in Rrequests[]
If(request.url 不在 Nodes[]集合中)
node=new node(request.url,request.content)
Nodes.add(node)
for request in Request[]
If(edge in Edge[]&&(edge.from=request.referer&&edge.to=request.url)
edge.id=request.requestID
else
edge=new edge(request.requestID,request.referer,request.url)
…
结束
优化:
(1)路径优化:实际上我们已经获得到达每个节点路径,但是这并不一定是最高效的路径。我们需要解决下面两种问题:(1)两个页面实际上应该只有一种方式到达(两点之间理论上应该只有一条有向边相连)。实际上,在封装某一API时我们需要确保到达某一页面完成特定功能时仅存在唯一一条路径,否则在封装过程中可能会出现二义性,给工作带来一定的麻烦。(2)从某一页面到达另一页面存在更短的路径。之前的路径图是根据用户上传的数据请求所构造出的,而用户上传的数据是通过记录日常操作所得到的,对于用户日常的操作往往存在不确定性和随机性。例如,页面A通过页面B到达页面C。而在保持状态的情况下可能存在一种方式使得页面A直接到达页面C。对于这些问题的解决方案,我们采用将图转成树的形式。具体做法如下:将主页面作为树的根节点,对于任何操作我们都认为是从主页面开始执行的。树的形式保证了从根节点到达子孙节点存在唯一路径,而第N层节点仅能到达第N+1层节点,而不能访问其他层次节点。任意节点都可以且必须从根节点为起点到达为后续封装API时带来一定的便利。经过优化以后,我们可以得到从主页面到达任意页面最高效同时不丢失状态信息的路径,详细见算法2。
算法2:路径优化,图转成树
输入: G[][]←有向图
输出: 优化树Tree
开始
…
令Count 表示节点层数
令P[]表示某节点所属层数
令level[][]表示某一层上的所有节点
Procedure create(Nodei,count):
for(j=1;j<节点数;j++):
if G[i][j]==1:
if p[j]==0:
将节点j加入level[count]
P[j]=count
else P[j]>count
P[j]=count
在Level[P[j]]中删除Nodej
在Nodej的父节点中删除Nodej子节点
在Level[count]中加入Nodej
将节点j作为结点i的子节点
for nodej in Nodei的子节点
create(nodej,count+1)
…
结束
算法2 将节点按层次划分,从主页面能到达的节点作为第二层节点,从第N层可达的节点属于第N+1层,若某一结点属于层次信息大于待更新层次,或是本身没有层次信息便更新其层次信息。 对于每个树节点Tnode∈Tnodes ,Tnode=<nodeType,url,childs,content>
其中nodeType表示 Tnode节点类型(根节点,叶节点,普通节点)url 等价于 有向图G中 node.url,childs 表示 子节点集合,content 等价于 有向图G中 node.content,对于树的边TEdges ∈有向图的Edges。
2、相似节点:我们称页面结构相同,但是页面展示内容不同的一类节点为相似节点。我们通过查看node.content来获得页面具体信息。而content的信息往往是以xml文档的形式呈现的,而我们需要查看具体数据时需要将xml文档转化成对应得DOM树。而我们称DOM树的形态为页面结构,而DOM树中结点的值称为页面内容。而在实际操作中,往往存在许多相似节点,例如在上传GITHUB项目时,我们需要填写项目详细信息(包括项目名称,项目内容等),而在查看具体项目时,这些项目所在的页面往往页面结构相同,只是具体展示的信息(项目名称和内容等)不同,如图3中Project1,2,3所对应的页面。而对于这类型的节点,我们没有必要在树中全部罗列,因为这些节点可能会增加图的复杂性,对于封装API时造成大量重复性的操作。所以我们需要找出树中多组相似节点,对它们进行合并成新节点,形成带参数的GET请求,只需要在访问时添加节点ID参数来区分相似节点中具体的特定节点。具体做法如下:通过遍历树中所有节点,通过比较每个节点的子节点DOM树结构来判断该节点是否存在相似子节点,若存在将相似节点合并成新节点。在原来树的定义下 在TNodes 中加入属性ProSame用于表示该Tnode节点下相似节点集合,取出相似节点的最长前缀作为默认值,将前缀后的内容(节点标识符)作为新的参数需要用户输入。
经过构造图和图优化等步骤,我们最终可以得到一个完整的请求路径图,如图4所示。对于任意节点,均有一条从根节点到达该节点的唯一路径,我们可以通过访问其沿边所对应的 request请求,发送相应HTTP数据,从而在实际上到达该节点。而对于相似节点的情况,我们也只需要在之前基础上增加节点ID的参数到达指定节点。
、API封装
要实现API的封装需要两个步骤,第一步到达特定页面,第二步则是在指定页面进行相应的操作。针对第一步来说,我们需要按照所构造图的路径形成相应的请求序列,让用户填写请求参数等信息。而第二步则是在指定页面完成数据获取或是处理等操作,我们把操作分为两种一种是数据获取的getAPI,另一种是数据处理的setAPI。
对于getAPI来说,主要是为了获取网页上的信息。不同的用户要获取同一个网页上的信息可能各不相同。为了实现数据的提取,最重要的是对页面进行解析得到数据并记录其位置。对于一个HTML页面,我们可以转化成DOM树的结构。而针对用户所需的数据,则属于DOM树下某一节点的属性值。所以我们可以通过解析DOM树来获取不同数据的XPATH路径DataPath。
对于用户所访问的页面,我们认为其页面结构是不变的,会更改的只有页面呈现的数据。所以每一次根据所获得的页面解析出的DataPath是相同的。当用户输入目标节点的URL时,我们查找PathTree 中对应的Node节点,向用户展示Node.content对应的页面,根据用户选择自动生成DataPath。
对于setAPI来说,主要是为了进行数据处理,比如修改密码或是上传一个新项目等。在之前的处理中,我们将请求划分成set类型和get类型。对于get类型,我们认为是用来生成请求路径的,而set类型则是用来封装setAPI的。而在处理setAPI时存在两种情况,一种是到达某页面,并在此页面直接进行set操作。另一种是发送连续多个set类型请求完成set操作。针对第一种情况,我们依然可以用getAPI的算法获得到达该node的路径,此时用户只需要填写该post请求发送的参数,便可以封装成setAPI。而针对另一种情况,我们认为这样的set操作实际上是发送了一系列的set类型请求所构成的。我们只需找出这样的post序列,将参数统一填写好封装成一个统一的API,而不是多个API。
以一个调用GET API完整过程为例,用户只需要输入API名称,设置API参数,选定为GET类型API,同时设置所需返回数据在原页面的实际地址便可自动封装出对于getAPI。在实际调用时输入API名称,以及参数,便可获得对于API返回结果,调用过程具体如下所示。
以下是服务器端提供的GET类型API的接口代码:
@GET
@Path("/GET/{APIname}")
@Produces(MediaType.APPLICATION_JSON)
public String GetData(@PathParam("APIname") String APIname){
resendRequest=new ResendRequest();
String result=resendRequest.getResendRequest(APIname);
return result;
}
以下是处理用户调用API请求的代码:
public String getResendRequest(String APIname){
…
api=apiDao.selectAPI(APIname); //查询该API的参数
request=requestDao.selectRequest(api.getRequestID()); //查询需要重发的请求
GetMethod getMethod=new GetMethod(request.getURL());
HashMap<String,String> headers=request.getHeader();
for(Entry<String, String> entry : headers.entrySet()){
getMethod.addRequestHeader(entry.getKey(), entry.getValue());//重新构建该请求
}
String returnName=api.getReturnDes().get(0);//提取用户需要返回参数的位置
String realPosition=api.getReturnParameter().get(0);
try{
client.executeMethod(getMethod); //重新发送该请求
String html = getMethod.getResponseBodyAsString();
result=returnName+":"+parserHtml.getData(html,api.getReturnParameter().get(0));//返回参数
}catch(IOException e){
e.printStackTrace();
}
return result;
}
本发明提出一种自动化封装网站API的方法,简化用户日常复杂繁琐的操作,用户无需对网络请求报文或是API等知识有相关了解。用户只需要填入所需要的参数信息,设置API名称,系统便可以封装出对于API,在以后的操作中无需重复的步骤,便可以直接调用该API。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!