一种近似熵和样本熵共同最优参数m、r确定的新方法与流程
本发明涉及复杂性测度领域,尤其涉及一种近似熵和样本熵共同最优参数m、r确定的新方法。
背景技术:
熵的概念来源于热动力学,其表示不能用来做功的那部分能量。熵经常被用于描述时间序列的复杂性,目前已直接或间接地应用于经济学、社会科学、地学、生命科学、工程学、信息科学、数学等学科领域并取得重要研究进展。其中Kolmogorov–Sinai熵是一种应用较为广泛的熵,其作为近似熵的基础,可有效分析短序列的复杂性。近似熵是一种非线性参数识别方法,可用于反映时间序列的复杂性、动态性以及测量动态序列的不规则性。近似熵值越大表示序列越随机或越不规则,值越小表示序列中可识别的特征或模式越小。因此,近似熵对一些奇异点具有较好的鲁棒性,常用于分析噪声信号,且表现出较好的性能。但是,近似熵存在一些不足,如对数据长度的过分依赖和结果缺乏相对的一致性,从而导致样本熵的提出。相对于近似熵,样本熵有更高的计算效率,通过判断时间序列中不同数据长度的重复模式,为“有序结构”的测量提供了有用的工具。近似熵和样本熵均表示时间序列结构的复杂性:两个相邻部分相似性的条件概率越低,时间序列越复杂,近似熵和样本熵值就越大。它们不仅仅是两个非线性的动态参数,在随机过程和确定性过程中均具有广泛的适用性,故在描述时间序列的复杂性方面具有一般的意义。
近似熵和样本熵都是无参数变量,其有两个重要的未知参数,即维度数目m和容度阈值r。参数m用来描述对比的序列长度,参数r是接受两部分为相似模式的阈值。这两个参数对近似熵和样本熵值有重要的影响,对时间序列计算结果的合理性解释亦具有重要意义。因此,正确选择参数m和r显得异常重要。传统的做法是,m和r一般取为2和0.1~0.25倍的序列标准差。但是,这些值大都是某些领域的经验值,在其它领域,就算取相同的值也有可能会导致不同的结果。更为严重的是,对相同或相似的研究对象,取不同的m和r值会导致非一致性问题的出现,严重破坏了近似熵和样本熵两者进行对比时的一致性要求,使得近似熵和样本熵进行对比时没有共同的参照点,从而导致对比的无效或没有意义。因此,在系统复杂性分析中,对于相同的研究对象,优选同时适用于近似熵和样本熵的m、r参数对于保障结果的一致性就显得异常重要。但当前并没有什么有效的方法来确定相同研究对象的近似熵和样本熵的共同最优参数m和r,这在很大程度上制约了这两种复杂性测度的应用。因此,寻找一种适用于相同研究对象的近似熵和样本熵参数m和r的优选方法,对于保障近似熵和样本熵结果的一致性、拓展近似熵和样本熵的应用领域具有重要的理论意义和实用价值,应用前景广阔。
技术实现要素:
针对上述问题,本发明的目的是提供一种近似熵和样本熵共同最优参数m、r确定的新方法。它的核心在于近似熵和样本熵在对同一个研究对象进行对比时,必须要满足一致性要求,即保证有共同的比较基础或相同的参照点,而参照点或共同的比较基础就要求对比的近似熵和样本熵有共同的m、r值。本发明首先设定近似熵和样本熵参数m和r的不同情景值;然后计算每个时间序列的近似熵和样本熵值;进而确定某时间序列的近似熵和样本熵的曲线交点,得到该时间序列某参数m下的近似熵和样本熵的共同最优参数r;最后基于该时间序列与其复杂度的相关系数的正负号得到该时间序列的最优m、r值,并进一步通过所有时间序列与其复杂度的相关系数的绝对值之和的大小来确定适用于所有时间序列的两种复杂度的最优参数m和r值。
为解决上述问题,本发明采取以下技术方案:
一种近似熵和样本熵的共同最优参数m、r确定的新方法,它适用于不同研究领域、不同时间序列的近似熵和样本熵的对比分析计算,该方法具体步骤如下:
步骤一:设定时间序列的近似熵和样本熵的参数m和r的不同情景;
步骤二:计算不同参数m和r情景下的近似熵和样本熵值。对近似熵,设时间序列为x(1),x(2),…,x(N),N为序列总长度,定义m维矢量X(i)为[x(i),x(i+1),…,x(i+m-1)],i=1,2,…,N-m+1,矢量X(i)与X(j)之间的距离d[X(i),X(j)]为则近似熵可由下式确定:
ApEn(m,r)=Cm(r)–Cm+1(r) (1)
式中,Cm(r)表示由参数m和r确定的比值因子的对数累积平均值,其大小为其中表示距离d[X(i),X(j)]小于参数r的比值因子,其大小为{d[X(i),X(j)]<r的个数}/(N-m+1),i=1,2,…,N-m+1。
对样本熵,对相同的时间序列x(1),x(2),…,x(N),定义m维矢量X(i)为[x(i),x(i+1),…,x(i+m-1)],i=1,2,…,N-m+1,矢量X(i)与X(j)之间的距离d[X(i),X(j)]为且j≠i,则样本熵可由下式进行计算:
SampEn(m,r)=ln[Cm(r)/Cm+1(r)] (2)
式中,Cm(r)表示由参数m和r确定的比值因子的累积平均值,其大小为其中表示距离d[X(i),X(j)]小于参数r的比值因子,其大小为{d[X(i),X(j)]<r的个数}/(N-m),i=1,2,…,N-m+1。
步骤三:确定某时间序列不同参数m下的近似熵和样本熵的共同最优参数r。以某时间序列的近似熵和样本熵为纵坐标,参数r为横坐标,点绘某参数m下的点(r,近似熵值)和(r,样本熵值)到各参数m的X-Y坐标系中,近似熵和样本熵曲线将会相交于一点,此交点处的参数r值即为此时间序列某参数m下近似熵和样本熵的共同最优值;
步骤四:基于相关系数及其绝对值之和的大小确定适用于所有时间序列的近似熵和样本熵的共同最优参数m、r。计算某时间序列与其复杂度序列的相关系数,基于此相关系数的正负号确定此时间序列的最优参数m和r,并进一步计算所有时间序列与其复杂度序列的相关系数的绝对值之和,基于此绝对值之和的大小确定适用于所有时间序列的近似熵和样本熵的共同最优参数m、r值。
本发明由于采取以上技术方案,其具有以下优点:
1.保障了两种不同的复杂性测度——近似熵和样本熵计算结果的一致性,使这两种复杂性测度进行对比时有共同的参照点,从理论上解决了不同的m和r参数导致的近似熵和样本熵值的非一致性问题。
2.该方法简单易操作,条理清楚,计算效率高,计算成果更准确、更科学。
3.该方法具有更好的适用性,既适用于近似熵和样本熵应用于单一研究对象的情况,也适用于近似熵和样本熵应用于多研究对象的情况,有重要的理论意义和实用价值,应用前景广阔。
附图说明
图1为本发明方法的流程框图。
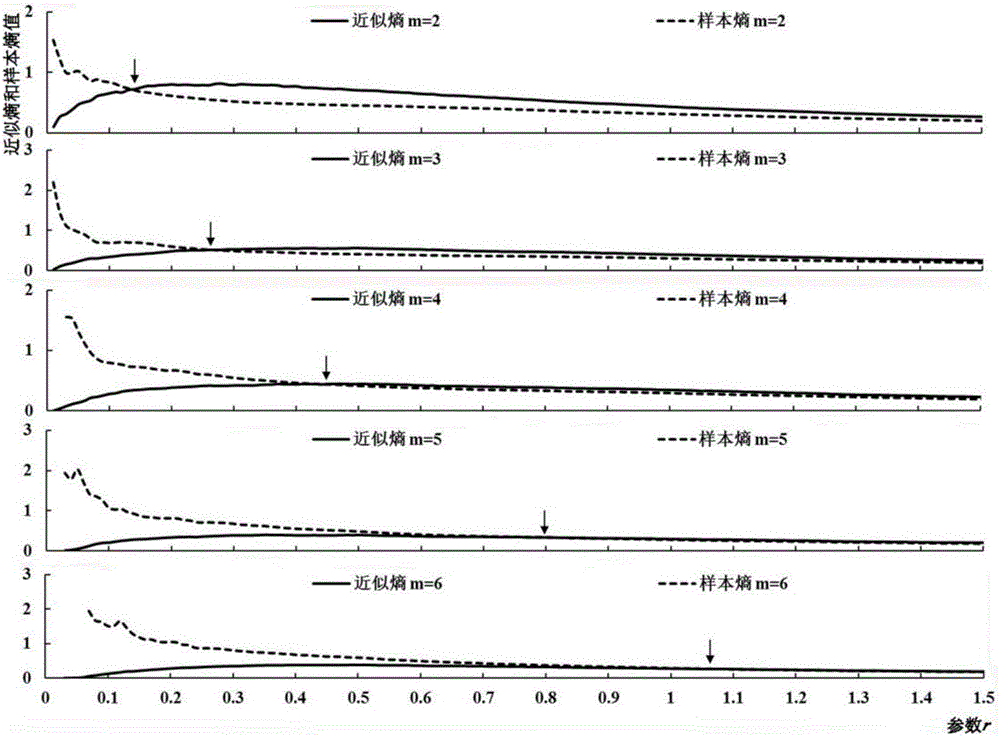
图2为黄河上游贵德水文站1960~1990年径流序列不同参数m下的近似熵和样本熵的共同最优参数r。
图3为黄河上游贵德水文站以上流域1960~1990年降水序列不同参数m下的近似熵和样本熵的共同最优参数r。
图4为基于相关系数绝对值之和的径流和降水序列的近似熵和样本熵最优参数m=6时的两种参数r情景的优选结果。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步详细说明。
如图1所示,本发明一种近似熵和样本熵共同最优参数m、r确定的新方法,包括设定不同时间序列的近似熵和样本熵的参数m和r的情景、计算不同参数m、r情景的近似熵和样本熵值、基于某时间序列近似熵和样本熵曲线交点确定该时间序列不同参数m下的近似熵和样本熵的最优参数r以及确定同时适用于所有时间序列的近似熵和样本熵的共同最优参数m和r四部分。
以水文系统的径流和降水时间序列为例,本发明的具体实施按照以下步骤进行:
步骤一:设定径流和降水序列的近似熵和样本熵的不同参数m、r情景;
步骤二:计算不同参数m、r情景下的径流和降水序列的近似熵和样本熵值。对近似熵,设径流或降水时间序列为x(1),x(2),…,x(N),N为序列长度,定义m维矢量X(i)为[x(i),x(i+1),…,x(i+m-1)],i=1,2,…,N-m+1,矢量X(i)与X(j)之间的距离d[X(i),X(j)]为则近似熵可由下式确定:
ApEn(m,r)=Cm(r)–Cm+1(r) (1)
式中,Cm(r)表示由参数m和r确定的比值因子的对数累积平均值,其大小为其中表示距离d[X(i),X(j)]小于参数r的比值因子,其大小为{d[X(i),X(j)]<r的个数}/(N-m+1),i=1,2,…,N-m+1。
对样本熵,对相同的径流或降水时间序列x(1),x(2),…,x(N),定义m维矢量X(i)为[x(i),x(i+1),…,x(i+m-1)],i=1,2,…,N-m+1,矢量X(i)与X(j)之间的距离d[X(i),X(j)]为且j≠i,则样本熵可由下式进行计算:
SampEn(m,r)=–ln[Cm+1(r)/Cm(r)] (2)
式中,Cm(r)表示由参数m和r确定的比值因子的累积平均值,其大小为其中表示距离d[X(i),X(j)]小于参数r的比值因子,其大小为{d[X(i),X(j)]<r的个数}/(N-m),i=1,2,…,N-m+1。
步骤三:确定径流或降水时间序列不同参数m下的近似熵和样本熵的共同最优参数r。以径流或降水的近似熵和样本熵值为纵坐标,参数r为横坐标,分别点绘径流序列和降水序列某参数m下的点(r,近似熵值)和(r,样本熵值)到各参数m的X-Y坐标系中,径流或降水的近似熵和样本熵曲线将会相交于一点,此交点处的参数r值即为径流或降水序列某参数m下近似熵和样本熵的共同最优值;
步骤四:基于相关系数及其绝对值之和的大小确定适用于径流和降水序列的近似熵和样本熵的共同最优参数m、r。计算径流或降水与其复杂度之间的相关系数,基于此相关系数的正负号选出适用于径流或降水序列的近似熵和样本熵的最优参数m和r,并进一步计算径流和降水与其复杂度之间的相关系数的绝对值之和,基于此绝对值之和的大小来确定同时适用于径流和降水序列的近似熵和样本熵的共同最优参数m、r值。
实施案例
本发明以黄河上游贵德水文站1960~1990年的月径流和贵德水文站以上流域的面平均月降水为研究对象,设定参数m为2~6、参数r为0.01~1.5SD,其中SD为序列的标准差,步长取为0.01,计算不同参数m和r情景下的径流和降水的近似熵和样本熵值,求出不同参数m下的径流或降水序列的两种复杂度的共同最优参数r值,再基于相关系数和相关系数的绝对值之和,确定适用于径流和降水的近似熵和样本熵的共同最优参数m、r值。
其结果,分别见图2、图3、图4。
图2为黄河上游贵德水文站1960~1990年径流序列不同参数m下的近似熵和样本熵的共同最优参数r。
图3为黄河上游贵德水文站以上流域1960~1990年降水序列不同参数m下的近似熵和样本熵的共同最优参数r。
图4为基于相关系数绝对值之和的径流和降水序列的近似熵和样本熵最优参数m=6时的两种参数r情景的优选结果。
从上述实例可以看出,本发明提供的一种新的近似熵和样本熵共同最优参数m和r确定的方法,适用于一种时间序列的近似熵和样本熵的共同最优参数m和r的确定,也适用于多种时间序列的近似熵和样本熵的共同最优参数m和r的确定,对于保障近似熵和样本熵结果的一致性、拓展近似熵和样本熵的应用领域具有重要的理论意义和实用价值,应用前景广阔。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!