一种基于多标签组合多分类器的恐怖行为预测方法与流程
本发明涉及数据挖掘与应用领域,具体而言涉及一种基于多标签组合多分类器的恐怖行为预测方法。
背景技术:
恐怖行为是指实施者对非武装人员有组织地使用暴力或以暴力相威胁,通过将一定的对象置于恐怖之中,来达成宗教、政治或意识形态上的目的。恐怖袭击自上世纪九十年代以来,有在全球范围内迅速蔓延的严峻趋势。恐怖袭击的发生不仅会直接造成巨大的人员伤亡和财产损失,同时也会给受害国带来巨大的反恐压力,造成受害国人员的极大恐慌。如何利用现有的技术预测将会发生的恐怖行为,成为一个重要的研究方向。
恐怖行为预测是知识挖掘的典型应用,它根据已有的知识信息并利用数据挖掘和机器学习等相关智能技术,预测恐怖组织实施恐怖行为的发展趋势。研究恐怖行为预测的目的主要是预测组织未来的活动,为决策者提供决策支持,从而可以采取有效的预防措施,降低恐怖袭击行为造成的生命财产损失。恐怖袭击事件发生的原因包括政治、经济、文化等方面的因素,各种原因交织在一起,导致恐怖行为的预测变得更加复杂。对恐怖行为预测的研究不能仅仅考虑事件发生的时间、地点及影响程度等信息,应该在考虑这些因素的基础上,综合考虑恐怖组织的政治、经济、文化等背景因素,从而为决策者提供更有效的决策支持。
目前,基于背景知识预测恐怖行为的预测方法大都把背景数据中的行为属性看作一个整体,然后利用背景向量之间的相似度预测对应的行为向量,再对预测的行为向量进行某种计算,得到行为向量中各行为的概率,然后根据各行为的发生概率给出预测结果。然而,采用这种方式进行恐怖行为的预测,将多个行为属性分解到多个行为子空间,在每个子空间进行单独恐怖行为的预测,没有考虑同一时间段可能发生多种行为属性,忽略了行为属性之间的联系对预测结果造成的影响。再者预测的模型大多采用单一模型及其模型改进或者通过修改参数来提高系统的预测效果。但是单一模型的预测只能考虑行为的单个方面,没有考虑到不同行为属性之间的关联对恐怖行为预测准确度造成的影响。
技术实现要素:
本发明的目的在于提出一种基于多标签组合多分类器的恐怖行为预测方法,针对以往通过数据分解方式将行为属性分解到多个行为子空间,在每个子空间单独进行恐怖行为预测造成预测结果的片面性问题,提出一种基于多标签的恐怖行为预测算法,充分利用背景数据,同时预测多个恐怖行为。对于通过单一模型进行分类预测造成预测精度低的问题,采用组合多分类器的方式,利用多个分类器模型预测方式的多样性,组合多个分类模型的预测结果,提高分类预测的精度。具体技术方案如下:
一种基于多标签组合多分类器的恐怖行为预测方法,包括以下步骤:
步骤1,原始数据的预处理:原始数据由恐怖组织的基本信息、背景知识和行为知识构成,提取背景知识和行为知识,构成背景知识与恐怖行为的多标签数据集;
步骤2,训练多标签决策树和随机游走模型:基于步骤1获得的背景知识与恐怖行为的多标签数据集,定义背景属性关联重要度,并根据背景属性关联重要度训练决策树分类器,利用标签之间的关联训练随机游走模型;
步骤3,测试多标签决策树和随机游走模型:使用步骤2获得的多标签决策树和随机游走模型预测在每种训练模型下待分类标签样本,获得所有恐怖行为的概率;
步骤4,组合基分类器预测模型:通过步骤3在多标签决策树分类器中获得每种恐怖行为的权值与预测的随机游走分类器对应的标签相乘,生成决策函数,根据决策函数得到最终恐怖行为的预测结果。
进一步地,所述步骤1中,原始数据的预处理包括以下步骤:
步骤1.1,提取原始数据中的背景知识和恐怖行为,构成三元组(U,CS,AS),其中U={X1,X2,...Xt}代表样本集,CS={C1,C2,...,Cn}表示背景数据中的背景属性,AS={A1,A2,...,Am}表示背景数据中涉及的恐怖行为;其中t代表样本的个数,n代表属性的个数,m代表标签的个数;
步骤1.2,采用基于邻域粗糙集的特征选择方法去除数据集中大量的冗余与无关背景知识;其中,多标签属性依赖度定义为:其中B代表背景属性子集,选择条件属性Ci∈CS-B的重要度的属性作为背景属性,获得最终的数据集(U,CS,AS)。
进一步地,所述步骤2中,建立多标签决策树和随机游走模型包括以下步骤:
步骤2.1,采用自顶向下的贪婪搜索方法训练多标签决策树,具体步骤如下:
步骤2.1.1,选择背景属性关联重要度作为属性选择度量:选择当前属性关联重要度最大的属性作为分类属性,反复迭代形成最终的多标签决策树模型;
步骤2.1.2,计算训练集中每个标签的概率作为标签预测的权重增加因子。
步骤2.2,训练随机游走模型,具体步骤如下:
步骤2.2.1,利用背景数据集映射为多标签随机游走图G:将每个训练样本映射为游走图中的一个点Xi,如果两个训练数据Xi、Xj具有相同的标签,则将这两个训练数据对应的顶点Xi、Xj相连,形成随机游走图G=(V,E);其中V={Xi|Xi∈U,1≤i≤t},E={(Xi,Xj)|Xi,Xj∈V,Yi∩Yj≠Φ,i≠j},Yi,Yj是Xi,Xj的真实标签集,Φ表示空集;
步骤2.2.2,计算随机游走图G上的权重矩阵并进行归一化处理转化成邻接矩阵;其中,权重矩阵中边的权值
进一步地,所述步骤3中测试多标签决策树和随机游走模型,包括以下步骤:
步骤3.1,多标签决策树中预测标签的权重因子:在多标签决策树预测实例的过程中将所有的标签设置相同的基础权重因子其中从树的根节点开始,根据测试属性选择分支,到达叶节点,得到标签预测结果R=(r1,r2,...,rm),其中,ri为0或1,0表示标签不被命中,1表示命中;根据R生成m×m矩阵R’,使R’ii=ri,ri∈R,其他元素为0;然后,统计每种标签在训练数据集中出现的频次fi,构造矩阵F=(f1,f2,...,fm);最后,计算每个标签的权重增加因子Δw=R’FT/t,修改权重因子wA=wA+Δw;
步骤3.2,使用随机游走模型预测实例的标签概率,包括以下步骤:
步骤3.2.1,构建多标签随机游走图系列:输入测试实例X,将X记作U,随机游走过程以U为起点构成多标签随机游走图系列,该多标签随机游走图系列T={Gk|k=1,2,...,m},Gk=(Vk,Ek),Vk=V∪{X},Ek=E∪{(X,Xi)|Ak∈Yi,1≤i≤m};
步骤3.2.2,设置初始概率分布向量s0、跳转发生概率α、发生跳转时跳转到图中每个顶点的概率分布向量d;
步骤3.2.3,随机游走过程中,输入步骤3.2.2各参数,迭代更新输出概率分布向量s,直到s收敛;其中s计算公式如下:s=(1-α)pTs0+αd,0<α<1,p表示邻接矩阵;
步骤3.2.4,运用条件概率模型获得恐怖行为标签概率分布结果:待分类样本X具有标签Ak的概率计算公式为:其中,λk表示第k个随机游走图,先验概率p(X<Ak)使用U点和具有标签Ak的数据对应顶点的平均距离计算,最终将概率进行归一化处理获得各恐怖行为概率
进一步地,所述步骤4中的具体实现方法如下:
将多标签决策树中的权重因子wA中每个权值与随机游走模型对应的标签概率pA加权组合p=wApA,并将该概率归一化处理获得最终的预测恐怖行为标签的概率;设置概率选择阈值k,概率大于该阈值的恐怖行为作为该测试实例的预测恐怖行为集。
进一步地,步骤2.1.1中所述的背景属性关联重要度的计算表达式为:
进一步地,所述步骤3.2.2中初始概率分布向量s0的计算方法为:首先计算s'0,s'0是一个m维向量,它的第i个元素为然后对该s'0进行归一化处理得到s0;
所述发生跳转时跳转到图中每个顶点的概率分布向量d的计算方法为:设从某个顶点出发跳转到图中任意一个顶点的概率是相等的,得到随机跳转到每个顶点的概率分布向量
进一步地,所述α设置为0.15。
进一步地,所述阈值k的选取方法为:根据两个分类器预测结果的取值范围,选择每个分类器预测概率大于0.5的组合函数的最小值,并对该值进行归一化处理获得阈值k。
本发明的有益效果:
采用多标签组合多分类器的方法进行恐怖行为预测,一方面充分考虑在同一时间段可能发生多种恐怖行为,并利用恐怖行为之间的联系建立了多标签恐怖行为预测算法,改善了恐怖行为预测结果的片面性。另一方面,针对恐怖行为预测结果精度低的问题,采用组合多分类器方法,在建立恐怖行为预测算法的过程中既利用了背景知识之间的关联性,又利用恐怖行为之间的关联性,综合考虑多种分类器的预测结果,采用概率组合方式构成决策函数,提高了恐怖行为预测的准确性。与以往采用数据分解方式进行单独预测的方法相比,本方法通过多种方式相结合,充分利用背景数据的特点,提高了恐怖行为预测的准确性和客观性,提高了预测精度。
附图说明
图1为本发明实施例提供的基于多标签组合多分类器的恐怖行为预测方法的流程示意图。
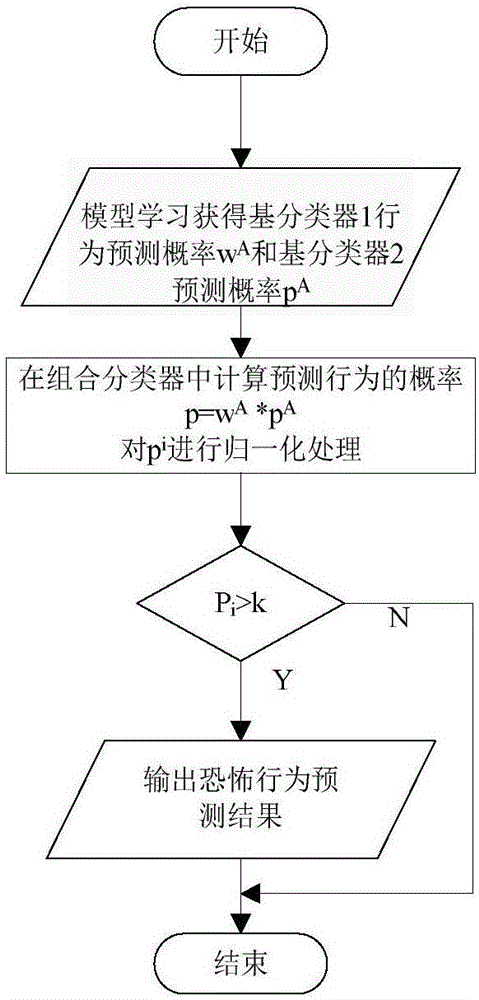
图2为本发明实施例中的关于多标签组合多分类器预测标签集合方法的流程图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优势更加清楚,下面将结合附图及具体实施例进行详细描述。
如图1所示,根据本发明的实施例,基于多标签组合多分类器的恐怖行为预测方法包括四个基本步骤:原始数据的预处理;建立并训练多标签决策树和随机游走模型,获得恐怖行为预测模型;预测某一时间段中各种恐怖行为发生的概率;组合基分类器中某一时间段内各种行为发生的概率,给出最终的恐怖行为预测结果。
一、原始数据的预处理
原始数据由恐怖组织的基本信息、背景知识和行为知识构成。基本信息包括组织代号、名字等,背景属性包括恐怖组织所处地理位置、该组织的意识形态、宗教信仰、政治主张、经济情况等,恐怖组织实施的各种恐怖行为包括武装冲突、绑架、自杀袭击等。
经过特征选择以后获得如下表1所示的背景数据子集,本实施例中共设置了11个字段,分别标记为ID、C1、C2、C3、C4、C5、C6和A1、A2、A3,其中ID标记为记录在表中的编号,{C1,C2,C3,C4,C5,C6}属于背景知识属性,{A1,A2,A3}属于恐怖行为。其中,1表示包含该属性,0表示不包含。
二、训练多标签决策树和随机游走模型为基分类器的多标签分类模型
将样本数据集分为训练数据集和测试数据集,使用训练样本训练多标签决策树和随机游走模型。
1、本实施例中训练多标签决策树的具体步骤如下:
(1)选择背景属性关联重要度为分裂条件:选择当前最大值属性作为分类属性。反复迭代得到多标签决策树模型。背景属性关联重要度的计算表达式为:
(2)计算训练集中每个标签的概率并作为相应标签权重增加因子:假设训练集的对象为Xt,类别标签Ai的权重为
2、本实施例中训练多标签随机游走模型的具体步骤如下:
(1)将训练数据集映射成为多标签随机游走图G:将训练集中的每个训练实例Xi∈X映射成为图中的一个点Xi,如果两个训练实例Xi、Xj具有相同的标签,则将这两个训练实例对应的顶点Xi、Xj相连。
(2)计算随机游走图G上的权重矩阵并将权重矩阵转化成邻接矩阵,其中,权重矩阵中边的权值Ca表示属性,Xi,a表示第i个点的第a个属性,Xj,a表示第j个点的第a个属性;权重矩阵中元素的权重计算公式如下:获得权重矩阵的各元素对Mij归一化处理得到M'ij=(Mij-avg(Mij))/std{Mi},其中avg(Mij)代表Mij的平均值,std(Mi)代表Mi的标准偏差,最终得到邻接矩阵中元素
三、使用测试集获得基分类器的预测概率。将测试数据集分别在两个分类模型中进行测试,获得每个基分类器的预测概率。本实施例中具体包括以下步骤:
1、获得多标签决策树中预测标签的权重因子:在多标签决策树预测实例的过程中将所有的标签设置相同的基础权重因子其中从树的根节点开始,根据测试属性选择分支,到达叶节点,得到标签预测结果R=(r1,r2,...,rm)(其中,ri为0或1,1表示标签被命中,0表示未被命中)。根据R生成m×m矩阵R’,使R’ii=ri(ri∈R),其他元素为0。然后,统计每种标签在训练数据集中出现的频次,构成矩阵F=(f1,f2,...,fm)。那么,每个标签的权重增加因子Δw=R’FT/t(t为实例的总数),修改权重因子wA=wA+Δw。
2、使用随机游走模型预测实例的类别标签集合,包括以下步骤:
(1)构建多标签随机游走图系列:输入测试实例X,将X记作U,随机游走过程将以U为起点构成多标签随机游走图系列,T={Gk|k=1,2,...,m},其中Gk=(Vk,Ek),Vk=V∪{U},Ek=E∪{(U,Xi)|Ak∈Yi,1≤i≤m}。
(2)初始化初始概率分布向量s0,跳转发生概率α,发生跳转时跳转到图中每个顶点的概率分布向量d。
初始概率分布向量s0,首先计算s'0,s'0是一个m维向量,它的第i个元素为然后对该s'0进行归一化处理得到s0。
跳转发生概率:本实施例中α设置为0.15。
发生跳转时跳转到图中每个顶点的概率分布向量d:设从某个顶点出发跳转到图中任意一个顶点的概率是相等的,得到随机跳转到每个顶点的概率分布向量
(3)随机游走过程:输入(2)各参数,迭代更新输出概率分布向量s,直到s收敛。s计算公式如下:s=(1-α)pTs0+αd,0<α<1。
(4)运用条件概率模型得到标签概率分布结果:根据条件概率模型,数据X具有标签λk的概率为:其中,先验概率p(X<Ak)使用U点和具有标签Ak的数据对应顶点的平均距离计算。最终将概率进行归一化处理得到最终的概率分布结果
四、组合基分类器Ci的分类结果。本实施例中,如附图2所示,组合基分类器Ci的分类结果采用加权组合概率函数实施,首先在决策树基分类器中通过测试数据获得标签的权重因子wA=wA+Δw。将该权重因子中的每个权值与随机游走模型对应的标签概率加权组合,即p=wApA,其中获得的结果进行归一化处理pi=(pi-avgp)/std{p},本实施例中pi的阈值k设置为0.375,pi概率大于该阈值的预测为该测试实例的预测恐怖行为集。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以进行多种变化、修改、替换和变型,均应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!