一种网页页面正文内容抽取方法及装置与流程
本发明涉及网页抽取技术领域,特别涉及一种网页页面正文内容抽取方法及装置。
背景技术:
在大数据时代,数据的价值日益受到企业重视,现代企业不再单纯地依靠企业内部的结构化数据来进行价值提取和发现,互联网作为理想的数据海洋,包含着大量的价值数据,这些数据对行情研判、网络征信、品牌价值推广等多个领域具有重要意义。而互联网上发布的信息通常以网页形式存在,而这些互联网网页页面异构性大,且通常被包含大量HMTL标签、JS脚本或广告推广等的噪声信息所包围,给数据整合和分析工作带来了巨大的困扰,因此迫切需要一种通用、智能和高效的网页抽取方案。
网页抽取的目的是将网页页面中的正文信息抽取出来并标示为结构化、自描述的数据结构。当前在这一领域主要的技术方案包括:一是基于网页标记语言的去除,利用网页形式的页面标签包括“<”和“>”的特点,通过简单的程序遍历和赋值,将所要抽取的信息抽取出来。二是在学习特定网页结构的基础上采用正则表达式,精准地抽取正文部分。三是采用DOM树的方式,将HTML文件转换成XML文档,同样需要在学习相关网页结构的基础上确定内容部分节点,最终抽取正文内容。
然而上述技术方案,本质上都是一种“监督”学习机制,需要人为地认知网页页面结构,进而判断此类页面那些是正文内容,无法做到通用抽取,解析抽取的自动化程度受限,不利于大规模推广;并且,当前的技术方案需要对网页结构有精准的了解,需要针对不同的页面类型定制抽取规则,装置人工成本极高;另外,在互联网上,网页页面的更新周期往往非常短,当页面结构发生变化时,需要修改装置的解析模板进行适配,大大降低了装置的稳定性和鲁棒性。
技术实现要素:
本发明提供一种网页页面正文内容抽取方法及装置,以提供一种自动且通用的抽取方案。
为实现上述目的,本申请提供的技术方案如下:
一种网页页面正文内容抽取方法,包括:
读取原始网页内容;
以行为粒度,统计各行出现的超级链接数目,并记录各行超级链接字符长度;
根据所述行超级链接字符长度,将网页源码中的HTML标签、JS代码部分进行清洗去除,得到纯文本文件;
将所述纯文本文件按照预设行数进行行块划分;
根据所述纯文本文件的各个行块,计算得到相邻行块之间的引力因子;
根据所述纯文本文件的各个行块进行处理,得到相邻行块之间的关联因子;
根据所述引力因子和所述关联因子,计算得到全部相邻行块的正文因子;
将正文因子大于阈值的相邻行块,标记为正文行块;
按照行块顺序将标记为所述正文行块的相邻模块内容进行拼接,生成网页正文。
优选的,所述将所述纯文本文件按照预设行数进行行块划分,包括:
若所述纯文本文件的总行数N能够被预设行数L整除,则将所述纯文本文件划分为N/L个行块,第m个行块为第(m-1)×L+1行到第m×L行构成,1≤m≤N/L;
若所述纯文本文件的总行数N不能被预设行数L整除,则将所述纯文本文件划分为K个行块,K为大于N/L的第一个整数,第m个行块为第(m-1)×L+1行到第m×L行构成,1≤m<K,第K个行块为第(K-1)×L+1到第N行构成。
优选的,所述根据所述纯文本文件的各个行块,计算得到相邻行块之间的引力因子,包括:
根据所述纯文本文件的各个行块,计算得到各个行块的字符数、超链接字符数及相邻行块之间的距离;
根据各个行块的字符数、超链接字符数及相邻行块之间的距离,计算得到相邻行块之间的引力因子。
优选的,计算得到相邻行块之间的距离,所采用的公式为:
R=D minm-D maxn;
其中:m>n,D minm为第m个行块内有效字符数Sl小于阈值θ的最小行号,D maxn为第n个行块内有效字符数Sl小于阈值θ的最大行号,Sl为第l行字符数减去第l行链接字符数的差值,R为相邻的第m个行块与第n个行块之间的距离。
优选的,所述计算得到相邻行块之间的引力因子,所采用的公式为:
其中,α为引力调整因子,Sm为第m个行块有效字符数,Sm为第m个行块字符数减去第m个行块链接字符数的差值,Sn为第n个行块有效字符数,Sn为第n个行块字符数减去第n个行块链接字符数的差值,R为相邻的第m个行块与第n个行块之间的距离,Fmn为相邻的第m个行块与第n个行块之间的引力因子。
优选的,所述根据所述纯文本文件的各个行块进行处理,得到相邻行块之间的关联因子,包括:
根据所述纯文本文件的各个行块,对各个行块内容进行分词处理;
将分词后的各个行块内容进行修正;
根据修正后的各个行块内容,计算得到相邻行块之间的关联因子。
优选的,所述计算得到相邻行块之间的关联因子,所采用的公式为:
其中,β为关联度调整因子,Wm为第m个行块分词、修正后的词集合,Wn为第n个行块分词、修正后的词集合,Lmn为相邻的第m个行块与第n个行块之间的关联因子。
优选的,所述根据所述引力因子和所述关联因子,计算得到全部相邻行块的正文因子,所采用的公式为:
C=Fmn+Lmn;
其中,Fmn为相邻的第m个行块与第n个行块之间的引力因子,Lmn为相邻的第m个行块与第n个行块之间的关联因子。
一种网页页面正文内容抽取装置,包括:
数据读取单元,用于读取原始网页内容;
第一计算单元,以行为粒度,统计各行出现的超级链接数目,并记录各行超级链接字符长度;
清洗单元,用于根据所述行超级链接字符长度,将网页源码中的HTML标签、JS代码部分进行清洗去除,得到纯文本文件;
划块单元,用于将所述纯文本文件按照预设行数进行行块划分;
第二计算单元,用于根据所述纯文本文件的各个行块,计算得到相邻行块之间的引力因子;
处理单元,用于根据所述纯文本文件的各个行块进行处理,得到相邻行块之间的关联因子;
第三计算单元,用于根据所述引力因子和所述关联因子,计算得到全部相邻行块的正文因子;
标记单元,用于将正文因子大于阈值的相邻行块,标记为正文行块;
生成单元,用于按照行块顺序将标记为所述正文行块的相邻模块内容进行拼接,生成网页正文。
优选的,所述第二计算单元包括:
第一计算模块,用于根据所述纯文本文件的各个行块,计算得到各个行块的字符数、超链接字符数及相邻行块之间的距离;
第二计算模块,用于根据各个行块的字符数、超链接字符数及相邻行块之间的距离,计算得到相邻行块之间的引力因子。
优选的,所述处理单元包括:
分词模块,用于根据所述纯文本文件的各个行块,对各个行块内容进行分词处理;
修正模块,用于将分词后的各个行块内容进行修正;
第三计算模块,用于根据修正后的各个行块内容,计算得到相邻行块之间的关联因子。
本发明提供的所述网页页面正文内容抽取方法,通过将原始网页内容进行清洗和行块划分,再计算相邻行块之间的引力因子和关联因子,得到正文因子,最后将正文因子大于阈值的相邻行块的内容进行拼接,生成网页正文;整个过程采用通用的方式进行网页正文内容的抽取工作,无需考虑页面的异构特征,使装置的可靠性和通用性大大增强,便于大规模推广实施;并且无需对页面进行学习认知、制定特定的解析规则和模板,可以大大降低人工成本;另外,无需复杂的参数设定和适配过程,避免了过多的指导参数,人工干预小,自动化程度高。
附图说明
为了更清楚地说明本发明实施例或现有技术内的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述内的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的网页页面正文内容抽取方法的流程图;
图2是本发明另一实施例提供的网页页面正文内容抽取方法的另一流程图;
图3是本发明另一实施例提供的网页页面正文内容抽取方法的另一流程图;
图4是本发明另一实施例提供的网页页面正文内容抽取装置的结构示意图;
图5是本发明另一实施例提供的网页页面正文内容抽取装置的另一结构示意图;
图6是本发明另一实施例提供的网页页面正文内容抽取装置的另一结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
本发明提供一种网页页面正文内容抽取方法,以提供一种自动且通用的抽取方案。
具体的,所述网页页面正文内容抽取方法,参见图1,包括:
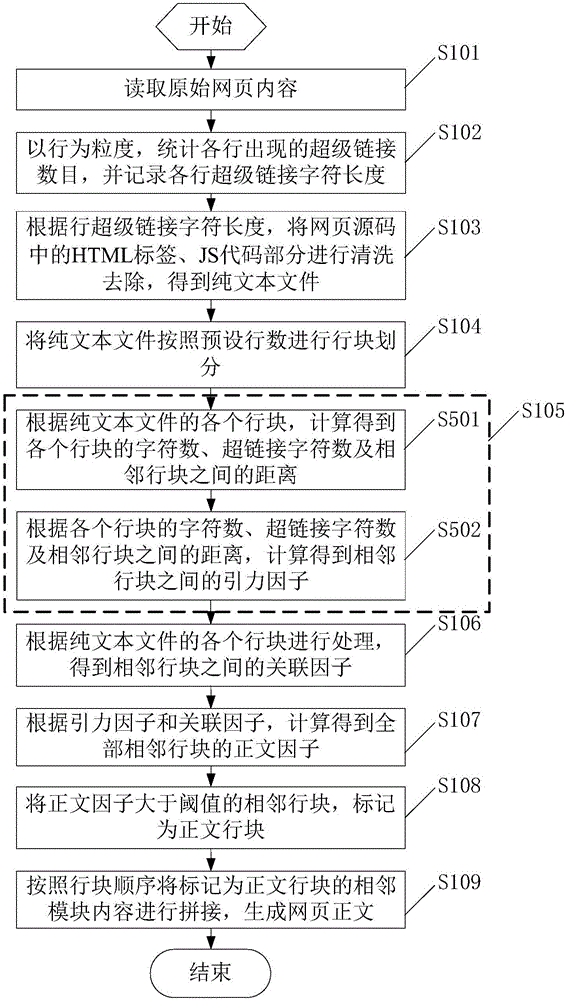
S101、读取原始网页内容;
S102、以行为粒度,统计各行出现的超级链接数目,并记录各行超级链接字符长度;
S103、根据所述行超级链接字符长度,将网页源码中的HTML标签、JS代码部分进行清洗去除,得到纯文本文件;
S104、将所述纯文本文件按照预设行数进行行块划分;
优选的,若所述纯文本文件的总行数N能够被预设行数L整除,则将所述纯文本文件划分为N/L个行块,第m个行块为第(m-1)×L+1行到第m×L行构成,1≤m≤N/L;
若所述纯文本文件的总行数N不能被预设行数L整除,则将所述纯文本文件划分为K个行块,K为大于N/L的第一个整数,第m个行块为第(m-1)×L+1行到第m×L行构成,1≤m<K,第K个行块为第(K-1)×L+1到第N行构成。
S105、根据所述纯文本文件的各个行块,计算得到相邻行块之间的引力因子;
优选的,在图1的基础之上,参见图2,步骤S105包括:
S501、根据所述纯文本文件的各个行块,计算得到各个行块的字符数、超链接字符数及相邻行块之间的距离;
具体的,步骤S501中,首先需要加载所述纯文本文件的各个行块,然后统计各个行块的字符数Nw,计算各个行块内的超链接字符数Na,再统计相邻行块之间的距离;相邻行块之间的距离用于衡量相邻行块之间有效内容的位置差距,计算得到相邻行块之间的距离,所采用的公式为:
R=D minm-D maxn;
其中:m>n,D minm为第m个行块内有效字符数Sl小于阈值θ的最小行号,D maxn为第n个行块内有效字符数Sl小于阈值θ的最大行号,Sl为第l行字符数减去第l行链接字符数的差值,R为相邻的第m个行块与第n个行块之间的距离。
S502、根据各个行块的字符数、超链接字符数及相邻行块之间的距离,计算得到相邻行块之间的引力因子,所采用的公式为:
其中,α为引力调整因子,Sm为第m个行块有效字符数,Sm为第m个行块字符数减去第m个行块链接字符数的差值,Sn为第n个行块有效字符数,Sn为第n个行块字符数减去第n个行块链接字符数的差值,R为相邻的第m个行块与第n个行块之间的距离,Fmn为相邻的第m个行块与第n个行块之间的引力因子。
S106、根据所述纯文本文件的各个行块进行处理,得到相邻行块之间的关联因子;
优选的,在图1的基础之上,参见图3,步骤S106包括:
S601、根据所述纯文本文件的各个行块,对各个行块内容进行分词处理;
S602、将分词后的各个行块内容进行修正,比如去除停用词;
S603、根据修正后的各个行块内容,计算得到相邻行块之间的关联因子,所采用的公式为:
其中,β为关联度调整因子,Wm为第m个行块分词、修正后的词集合,Wn为第n个行块分词、修正后的词集合,Lmn为相邻的第m个行块与第n个行块之间的关联因子。
S107、根据所述引力因子和所述关联因子,计算得到全部相邻行块的正文因子;
优选的,所采用的公式为:
其中,Fmn为相邻的第m个行块与第n个行块之间的引力因子,Lmn为相邻的第m个行块与第n个行块之间的关联因子。
S108、将正文因子大于阈值的相邻行块,标记为正文行块;
S109、按照行块顺序将标记为所述正文行块的相邻模块内容进行拼接,生成网页正文。
本实施例提供的所述网页页面正文内容抽取方法,通过将原始网页内容进行清洗和行块划分,再计算相邻行块之间的引力因子和关联因子,得到正文因子,最后将正文因子大于阈值的相邻行块的内容进行拼接,生成网页正文;整个过程采用通用的方式进行网页正文内容的抽取工作,无需考虑页面的异构特征,使装置的可靠性和通用性大大增强,便于大规模推广实施;并且无需对页面进行学习认知、制定特定的解析规则和模板,可以大大降低人工成本。
另外,值得说明的是,现有技术为了适应页面结构更新,使抽取方案具备一定的鲁棒性,需要进行修改或者复杂的参数设定,而本实施例所述的网页页面正文内容抽取方法仅需设定各行有效字符长度、引力调整因子α、关联度调整因子β和正文因子的比较阈值即可,无需复杂的参数设定和适配过程,避免了过多的指导参数,人工干预小,自动化程度高。
本发明另一实施例还提供了一种网页页面正文内容抽取装置,参见图4,包括:数据读取单元101、第一计算单元102、清洗单元103、划块单元104、第二计算单元105、处理单元106、第三计算单元107、标记单元108及生成单元109;其中:
数据读取单元101,用于读取原始网页内容;
第一计算单元102,以行为粒度,统计各行出现的超级链接数目,并记录各行超级链接字符长度;
清洗单元103,用于根据所述行超级链接字符长度,将网页源码中的HTML标签、JS代码部分进行清洗去除,得到纯文本文件;
划块单元104,用于将所述纯文本文件按照预设行数进行行块划分;
第二计算单元105,用于根据所述纯文本文件的各个行块,计算得到相邻行块之间的引力因子;
处理单元106,用于根据所述纯文本文件的各个行块进行处理,得到相邻行块之间的关联因子;
第三计算单元107,用于根据所述引力因子和所述关联因子,计算得到全部相邻行块的正文因子;
标记单元108,用于将正文因子大于阈值的相邻行块,标记为正文行块;
生成单元109,用于按照行块顺序将标记为所述正文行块的相邻模块内容进行拼接,生成网页正文。
优选的,在图4的基础之上,参见图5,第二计算单元105包括:
第一计算模块501,用于根据所述纯文本文件的各个行块,计算得到各个行块的字符数、超链接字符数及相邻行块之间的距离;
第二计算模块502,用于根据各个行块的字符数、超链接字符数及相邻行块之间的距离,计算得到相邻行块之间的引力因子。
优选的,在图4的基础之上,参见图6,处理单元106包括:
分词模块601,用于根据所述纯文本文件的各个行块,对各个行块内容进行分词处理;
修正模块602,用于将分词后的各个行块内容进行修正;
第三计算模块603,用于根据修正后的各个行块内容,计算得到相邻行块之间的关联因子。
本实施例提供的所述网页页面正文内容抽取装置,通过将原始网页内容进行清洗和行块划分,再计算相邻行块之间的引力因子和关联因子,得到正文因子,最后将正文因子大于阈值的相邻行块的内容进行拼接,生成网页正文;整个过程采用通用的方式进行网页正文内容的抽取工作,无需考虑页面的异构特征,使装置的可靠性和通用性大大增强,便于大规模推广实施;并且无需对页面进行学习认知、制定特定的解析规则和模板,可以大大降低人工成本。另外,仅需设定各行有效字符长度、引力调整因子α、关联度调整因子β和正文因子的比较阈值即可,无需复杂的参数设定和适配过程,避免了过多的指导参数,人工干预小,自动化程度高。
具体的工作原理与上述实施例相同,此处不再一一赘述。
本发明中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!