Squid按照目录格式清除缓存文件的方法与流程
本发明涉及计算机软件领域,尤其涉及一种Squid按照目录格式清除缓存文件的方法。
背景技术:
Squid是一个流行的开源软件,有着广泛的用途,经常被用来做缓存服务器。当用户要访问web,下载数据时,用户机向Squid发出一个申请,Squid连接所申请网站并请求该数据,接着把数据传递给用户的同时保留一个备份。当其他用户申请同样数据时,Squid把保存的备份立刻传给用户,节省后端请求环节,响应更快,用户体验更好。
但当用户抱怨总接收过时的数据(缓存),或Squid某个缓存需要更新修改时,就需要通过清除缓存来解决。
不过当想清除同一个目录结构下的缓存时,因为很多原因,Squid并没有提供一个好的机制。比如说Squid必须遍历所有缓存对象,执行线性搜索,这很耗费CPU,并且耗时较长。
目前比较常见的解决方式有两种。一种是从access.log获取URI列表;另一种是删除缓存索引文件。这两种方式均有一定限制性和局限性。第一种方式通过抓取squid的access.log来获取URI列表,将URI列表用于squidclient产生PURGE请求,这种方法可以提高清除缓存的准确性,但,效率较低,重复性较高。第二种方式删除swap.state文件,这种方式需要停止squid服务,并且删除并无指向性。
本专利将提供一种效率较高,维护成本低,又不用停机,热删除一组目录缓存的方法。
技术实现要素:
本发明的目的在于提供一种Squid按照目录格式清除缓存文件的方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明所述Squid按照目录格式清除缓存文件的方法,所述方法包括:
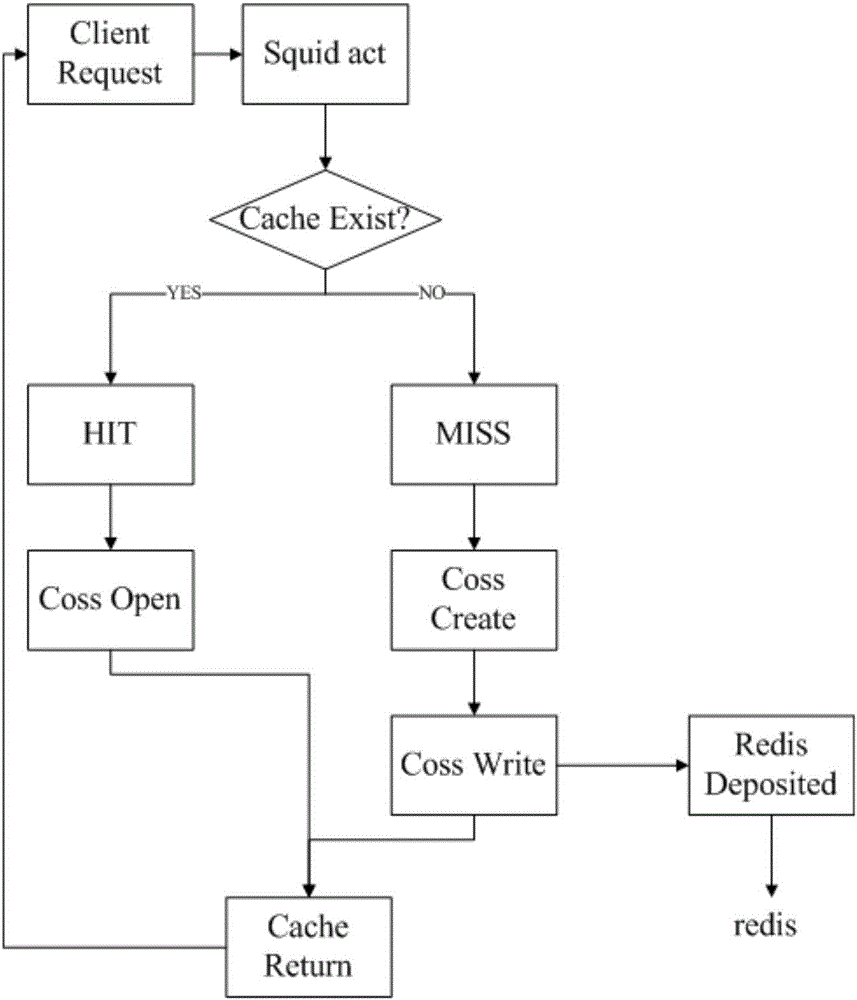
S1,将redis结合至squid:当缓存未命中时,将客户端访问的URL转换成域名-目录结构的key-value对应关系,存储至redis;
S2,当收到清除任意一组缓存的指令时,squid首先在redis中抓取符合条件的一组URL,逐个清除后,再清除存储在redis中的与符合条件的一组URL相关存储信息。
优选地,步骤S1,具体按照下述步骤实现:
S11,作为服务端的squid接收到客户端发出的访问域名,结合squid的访问控制列表,判断客户端发出的访问域名是否符合squid的配置规则,如果是,则允许访问,进入S12;如果否,则不允许访问;
S12,从squid coss文件系统中读取到访问域名所对应的缓存数据;
S13,squid从源服务器中读取访问域名所对应的目标数据,进入S14,同时,将所述目标数据写入squid coss文件系统保留备份;
S14,将缓存数据反馈到客户端。
更优选地,步骤S13,当目标数据写入squid coss文件系统中做保留备份时,squid将客户端的URL拆分成域名-目录结构的key-value结构,存储至redis。
优选地,步骤S2,调用squid client清除缓存时,指定目标缓存目录,并修改method名为PURGEDIR+目录名称。
优选地,步骤S2,具体按照下述步骤实现:
S21,作为服务端的squid接收到客户端发出的指令,解析请求内容,判断请求内容是否为清除目录的指令,如果是,则进入S22;如果否,执行清除缓存的指令,则进入S24;
S22,作为服务端的squid根据请求内容,再结合请求内容的域名-目录结构,从redis中抓取匹配条件的URL列表;
S23,遍历从redis中抓取到的匹配条件的URL列表,对匹配条件的URL,进行文件系统释放,遍历完成后,在redis对成功清除的URL进行删除,进入S24;
S24,将操作完成信息反馈到客户端。
更优选地,从redis中抓取与客户端URL匹配的URL列表。
更优选地,将抓取到的URL列表,逐个进行squid文件系统的缓存资源释放。
本发明的有益效果是:
本发明所述方法在不增加运维学习和操作成本的基础上,实现了高效的清除一组缓存。
对于squid清除缓存的场景,本发明使用redis这样的高性能内存服务器,不仅性能较高,而且可以通过配置提高数据安全性。
清除目录缓存时,本发明不需要停机清除,用户访问无感知,操作人员基本无学习成本。
附图说明
图1是缓存信息的redis存储流程;
图2是缓存信息的redis存储流程;
图3是清除目录内缓存的流程;
图4是清除目录内缓存的流程。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
关于本申请中专用名词的解释说明:
redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
squid是一个流行的自由软件(GNU通用公共许可证)的代理服务器和Web缓存服务器。Squid有广泛的用途,从作为网页服务器的前置cache服务器缓存相关请求来提高Web服务器的速度,到为一组人共享网络资源而缓存万维网,域名系统和其他网络搜索,到通过过滤流量帮助网络安全,到局域网通过代理上网。Squid主要设计用于在Linux一类系统运行。
实施例
本实施例所述Squid按照目录格式清除缓存文件的方法,所述方法包括:
S1,将redis结合至squid,当缓存未命中时,将客户端访问的URL转换成域名-目录结构的key-value对应关系,存储至redis;
S2,当收到清除一组缓存的指令时,squid首先去redis抓取符合条件的一组URL,逐个清除后,再清除存储在redis中的与目标URL相关存储信息。
(一)参照图1和图2,步骤S1,具体按照下述步骤实现:
S11,作为服务端的squid接收到客户端发出的访问域名,结合squid的访问控制列表,判断客户端发出的访问域名是否符合squid的配置规则,如果是,则允许访问,进入S12;如果否,则不允许访问;
S12,从squid coss文件系统中读取到访问域名所对应的缓存数据;
S13,squid从源服务器中读取访问域名所对应的目标数据,进入S14,同时,将所述目标数据写入squid coss文件系统保留备份;
S14,将缓存数据反馈到客户端。
步骤S13,当目标数据写入squid coss文件系统中做保留备份时,squid将客户端的URL拆分成“域名-目录结构”的”key-value”结构,存储至redis。
(二)参照图3和图4,步骤S2,具体按照下述步骤实现:
S21,作为服务端的squid接收到客户端发出的指令,解析请求内容,判断请求内容是否为清除目录的指令,如果是,则进入S22;如果否,执行清除缓存的指令,则进入S24;
S22,作为服务端的squid根据请求内容,结合请求内容的域名-目录结构,从redis中抓取匹配条件的URL列表;
S23,遍历从redis中抓取到的匹配条件的URL列表,对匹配条件的URL,进行文件系统释放,遍历完成后,在redis对成功清除的URL进行删除,进入S24;
S24,将操作完成信息反馈到客户端。
步骤S2,调用squid client清除缓存时,指定目标缓存目录,并修改method名为PURGEDIR+目录名称。
从redis中抓取与客户端URL匹配的URL列表。
将抓取到的URL列表,逐个进行squid文件系统的缓存资源释放。
本申请提供一种效率较高,维护成本低,又不用停机,热删除一组目录缓存的方法。在存储”key-value”至redis时,通过S11-S13-S14,拆分URL的方式,记录下一个域名对应了多个目录地址,为高效清除目录缓存时做准备。
通过S21步骤,用户操作squidclient进行缓存目录清除时,只需修改method名称即可,操作人员无学习成本。
通过S22步骤,将客户端URL,通过redis正确匹配后的URL列表,减少了通过抓取access.log对服务器的负载,提高了整个过程的效率。通过redis存储,在降低负载的同时,又可以保证数据的安全性,降低维护成本。
通过S23步骤,将抓到的URL列表,逐个进行squid文件系统的缓存资源释放,有指向性删除的同时,又可以做到不停机,热删除,达到了用户无感知,7x24正确运行的目标。
通过S13和S23步骤,使用redis,对应较大的数据量时,redis依然可以高效的进行读写操作,又可以通过主从配置,可以提高数据的安全性。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
本发明所述方法在不增加运维学习和操作成本的基础上,实现了高效的清除一组缓存。
对于squid清除缓存的场景,本发明使用redis这样的高性能内存服务器,不仅性能较高,而且可以通过配置提高数据安全性。
清除目录缓存时,本发明不需要停机清除,用户访问无感知,操作人员基本无学习成本。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!