一种软件模块划分方法与流程
本发明属于软件工程技术领域,具体涉及到软件系统中模块划分的问题,提供了一种基于搜索的软件模块划分方法,主要解决在软件系统中如何优化系统代码结构的问题,使每个模块尽可能独立的执行其预期功能,达到消除系统冗余,增加软件系统的可理解性,降低软件系统维护费用的目的。
背景技术:
软件维护是软件生命周期中一个非常重要的阶段,其维护成本往往很高。随着业务需求的增加,软件系统逐渐发生变化,这使理解和维护一个规模庞大的软件系统变得越来越复杂,这一问题迫使需要一种合理的软件模块划分方法,特别对于那些缺少文档的遗留系统,如何分解软件结构,使软件系统变得易于理解、维护和管理是一个亟待解决的问题。
软件模块划分是组织或重新组织软件系统的一种活动,使每个模块尽可能独立的执行其预期功能,以达到优化软件系统结构,消除冗余,增加软件系统的可理解性,降低软件系统维护费用的目的。软件模块聚类是软件模块划分的一种重要手段,软件聚类是通过模块依赖图利用聚类算法对软件系统进行模块结构划分,将软件系统分解为一些子系统,使复杂的软件系统变得易于理解和管理。目前使用聚类方式进行模块划分的方法主要有以下策略:(1)将经典的聚类技术直接应用到软件模块划分中;(2)根据软件领域的特性将经典的聚类算法改进并使用;(3)应用新的聚类技术进行软件模块划分。用于软件聚类的技术主要可以分为图理论技术、基于信息检索的技术、基于数据挖掘的技术、基于模式匹配的技术和元启发式方法。利用图理论技术的方法是将软件表示为一个图,其中软件实体(如:方法或类)作为节点,方法之间的调用或类之间的继承关系作为边,用图方法在图中找到最好的划分方式。然而图理论方法解决聚类问题随着软件系统规模的增加,搜索空间呈指数级增长。软件模块划分问题是一个NP问题,由于搜索过程中会产生巨大的解空间,使用传统的优化技术无法得到问题的有效解。为了减小计算的复杂性,Mancoridis等提出用基于搜索的方法进行软件模块划分并实现了软件系统模块划分工具Bunch。随后,相继将爬山算法,模拟退火算法,遗传算法等元启发式方法应用于软件模块划分问题上,使问题得到一定程度的解决,但存在收敛速度慢,易陷入局部最优等缺点。
Hussain等提出将粒子群优化算法(PSO)用于软件模块划分问题,但是由于没有考虑软件模块划分问题解空间离散的特点,位置更新没有将软件模块划分的评估标准考虑在内,而是盲目的在解空间中搜索,使得优化过程收敛速度慢,而且计算量大,不利于进行大规模复杂系统的软件模块划分。
为此,本发明以离散粒子群算法为基础,结合软件模块划分问题的特殊性对传统离散粒子群算法加以改进,位置更新采用以软件模块化评估标准为依据的位置更新方式,使每次的位置更新都更加接近最优的软件模块划分结果;同时,软件模块划分的评估标准遵循高内聚、低耦合的软件设计原则,从根本上保证了产生一个结构合理,划分有效的结果。
技术实现要素:
本发明解决的问题:克服现有方法的不足,将改进的离散粒子群算法应用于软件模块划分问题中,为软件模块划分问题提供一种划分效果更好的方法,使规模庞大的复杂软件系统划分成规模更小、更易于管理的子系统。
本发明解决方案:为实现上述目的,本发明的技术方案包括以下步骤,如图1所示:
(1)在面向对象语言编写的软件系统中,以代码中的方法作为节点,方法之间的调用关系作为边,将软件系统表示为一个图,并以矩阵形式存储。若该系统中有n个方法,这些方法可以用集合F表示为F={f1,f2,...,fj,...,fn},j为1到n之间的任意一个整数值,fj(1≤j≤n)表示该软件系统中的第j个方法,则该软件系统中方法之间的调用关系用一个n×n的二维矩阵B进行编码表示。若方法fi(1≤i≤n)调用方法fj(1≤j≤n),则B的第i行第j列的元素值为1,即bij=1,若方法fi(1≤i≤n)没有调用方法fj(1≤j≤n),则B的第i行第j列的元素值为0,即bij=0,按照上述方法,软件系统的方法调用关系编码表示为:
(2)假设该软件系统需要被划分为m(m<<n)个模块,则经过模块划分之后的软件系统可以用集合C表示为C={c1,c2,...ci,...cm},i为1到m之间的任意一个整数值,ci(1≤i≤m)表示软件系统经过模块划分后的第i个模块。在离散粒子群算法中,假设初始种群规模为N,种群中的第w个粒子用Pw表示,则种群可以用集合P表示,P={P1,P2,...,Pw,...,PN}(1≤w≤N),对该软件系统的模块划分方案编码表示为一个m×n的二维矩阵A。矩阵A的每一列代表一个方法,每一行代表划分成的一个模块,则第w个粒子在迭代到第t步时软件系统的模块划分情况由中每一个元素的值决定。若方法fj(1≤j≤n)属于ci(1≤i≤m)模块,则中的第i行第j列的元素值为1,即而第j列的其它元素值为0,即则第w个粒子在迭代到第t步时的模块划分情况编码表示为:n为该软件系统中的方法个数,m为软件系统模块划分后的模块数,t为迭代步数(t≥0)。
(3)设定基于离散粒子群算法的参数,所述的参数包括粒子群中粒子的数量N、软件系统划分的模块数量m、迭代终止条件。
(4)对每个粒子进行初始化
种群P中粒子Pw的初始值采用随机生成方式初始化,具体如下:假设对于第w个粒子Pw中的第j(1≤j≤n)个方法fj,则随机生成一个1到m之间的随机整数。当随机生成的整数为i(1≤i≤m)时,代表粒子Pw的第j个方法属于第i个模块,则中而第j列的其它元素值为0,即按照此方法可以确定出粒子Pw中每个方法的所属模块。编码中1的个数应该有n个,分别代表n个方法所选的模块位置,种群中的所有粒子以上述方法进行初始化编码,令迭代次数t=1,开始进行软件系统模块划分。
(5)计算每个粒子的适应度值
假设第i个模块ci中的方法个数用Ni(1≤i≤m)表示,模块ci与模块cj之间方法的调用次数通过方法调用矩阵B计算,并用Ei,j表示:
模块ci内部方法之间的调用次数用Mi表示:
软件系统进行模块划分后,第i个模块ci和第j个模块cj之间的耦合性用εi,j表示:
第i个模块ci的内聚性由μi表示:
高内聚、低耦合是评价软件模块划分优劣的标准,使用软件模块质量(Modularization Quality,简称MQ)将模块内部的内聚性和模块之间的耦合性结合起来综合评价软件模块划分的优劣,第w个粒子代表的模块划分方案用MQw进行评估表示,
其中,m表示将软件系统划分成m个模块。在优化过程中,软件系统耦合性尽可能减小,内聚性尽可能增大,即MQ的值不断增大。以函数MQ作为粒子群算法中的适应度函数,第w个粒子当前位置的适应度值用fitnessw表示。
(6)对于第w(1≤w≤N,N为种群规模)个粒子,将当前适应度值和该粒子局部最优位置的适应度值lwBest进行比较,若其值大于lwBest,则将粒子的当前位置作为该粒子的局部最优位置LocBestw=Aw,且该粒子的当前适应度值作为该粒子的局部最优适应度值lwBest=fitnessw。
(7)对于第w(1≤w≤N,N为种群规模)个粒子,将其局部最优适应度值lwBest和全局经历过最优位置的适应度值LGBest进行比较,若第w个粒子Pw的局部最优适应度值lwBest大于LGBest,则将其局部最优位置作为当前粒子群的全局最优位置gBest=LocBestw,该粒子的局部最优适应度值作为粒子群的全局最优适应度值LGBest=lwBest。
(8)根据下面方法更新每个粒子各维的位置,第w个粒子在迭代到第t步时的位置表示为要确定迭代到第t+1步时的位置编码即要确定迭代到t+1步时粒子Pw中每个方法所属的模块。假设要确定方法fj(1≤j≤n),使的第i(1≤i≤m)行第j(1≤j≤n)列的值为1,第j列的其它值为0,即由此构造矩阵
一共可以构造出m个这样的矩阵根据公式(5)计算每个位置编码的适应度值根据计算出的适应度值分别计算选择每个位置编码的概率值
则方法fj以概率选择模块i,由此确定方法fj所属的模块,并确定第w个粒子中每个方法所属的模块,即的取值。
(9)如果当前的迭代次数t等于最大迭代次数max,或者当前粒子群的LGBest达到期望值1,则全局最优位置gBest所对应的粒子代表的软件模块划分方案即为软件模块划分的最优方案,结束循环;否则,t=t+1,返回第(5)步。
有益效果:
目前,解决软件模块划分问题的方法很多,但是传统的软件模块划分方法都是简单使用一些经典的聚类算法,可以得出划分结果,但由于软件模块划分问题是一个NP问题,应用传统方法进行聚类随着软件系统的规模增加,搜索空间呈指数级增长,使用传统的优化技术使软件模块划分问题无法得到有效解决。使用基于搜索的启发式方法是解决NP问题的有效途径,目前使用的启发式方法主要有:爬山算法、模拟退火算法、遗传算法、粒子群优化算法等,但是在使用这些方法时,没有充分考虑软件模块划分问题离散解空间的特点,使得不能得到理想的划分结果。
传统的离散粒子群优化算法(DPSO)是Kennedy和Eberhart于1997年在粒子群算法基础上为解决离散空间问题提出的,传统的离散粒子群算法沿用基本连续粒子群优化算法的速度更新公式,即速度仍然作用于连续空间,而位置则利用sigmoid函数将其离散化,但是由于位置更新未考虑连续量与离散量运算规律的不同,并且没有从实际问题出发,没有有效利用基本粒子群优化算法的性能,使得寻优效果一般。
基于粒子群算法的模块划分问题就是根据软件系统中方法之间的调用关系对每个方法进行聚类,将软件系统的结构进行分解,使每个模块内部具有高的内聚性,而模块之间具有低的耦合性,使软件系统的结构更加合理,达到优化软件结构的目的。在本发明中,粒子位置每一维值的选择只有0,1两个离散值,0代表此方法不属于该模块,1代表此方法属于该模块,根据目前软件模块的划分情况可以重新确定下次每个方法所属的模块,计算在目前软件模块划分基础上某一方法属于各个模块的适应度值,适应度值高的所属模块在下次选择该模块的概率大;相反,适应度值低的所属模块在下次选择该模块的概率小。所以,粒子的更新就更加易于趋向最优值,可以加快找到软件系统最优模块划分的速度。本方法位置更新采用每个方法分别选择各个模块进行试探,以不同概率确定新的位置,提高算法的收敛速度,同时简化位置更新的操作。
传统的离散粒子群算法没有考虑软件模块划分问题的特点,位置更新没有将软件模块划分的评估标准考虑在内,而是盲目的在解空间中搜索,使得用传统离散粒子群算法解决软件模块划分问题的收敛速度慢,而且计算量大,不利于进行大规模复杂系统的软件模块划分。为此,本发明的方法以离散粒子群算法为基础,结合软件模块划分问题的特殊性对传统离散粒子群算法加以改进,位置更新采用以软件模块化评估标准为依据的位置更新方式,使每次的位置更新都更加接近最优的软件模块划分,同时软件模块划分的评估标准遵循高内聚、低耦合的软件设计原则,从根本上保证了产生一个结构合理,划分有效的软件系统结构。
典型实例实验结果证实该方法的有效性:对如图2所示的软件系统调用关系图,分别用传统离散粒子群算法(DPSO)和本方法进行软件模块划分,10次迭代过程中适应度值变化如图3所示。从实验结果可以看出,本发明提出的基于改进离散粒子群算法的软件模块划分方法与传统离散粒子群算法的软件模块划分方法相比,本发明的方法能找到更加接近最优的划分结果,方法稳定性好,收敛速度快,是一种有效的软件模块划分方法。
附图说明
附图1本发明的流程图。
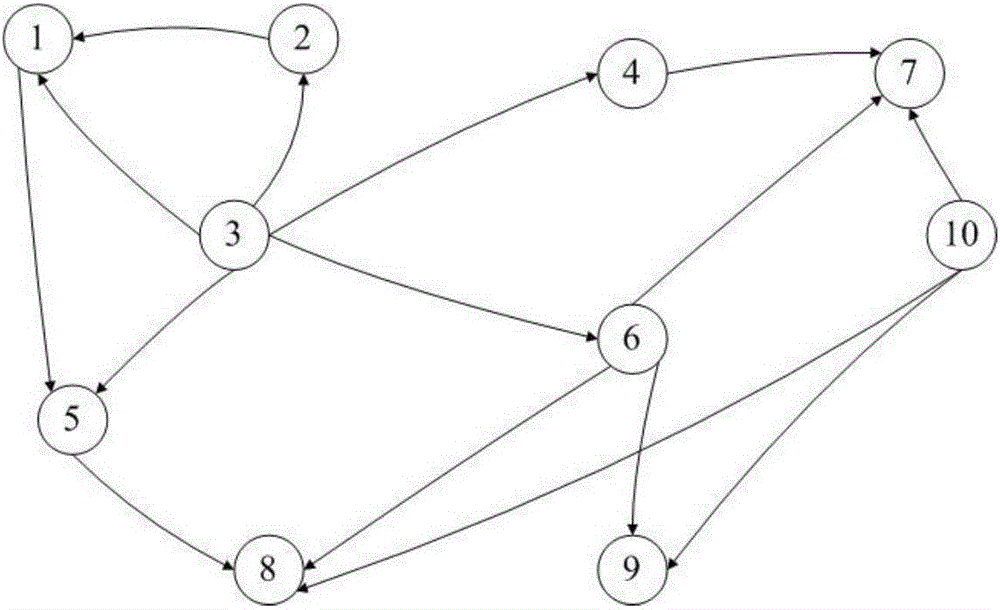
附图2某软件系统方法调用关系图。
附图3 DPSO与本方法适应值变化图。
附图4某软件系统模块划分情况图。
具体实施方式
以某软件系统为例,如图2所示是该软件系统的方法调用关系图,具体说明本发明公开的软件模块划分方法的具体实施方式。
(1)对如图2所示的方法调用关系图编码,该软件系统中有10个方法,这些方法可以用集合F表示为F={f1,f2,...,fj,...,f10},j为1到10之间的任意一个整数值,fj(1≤j≤10)表示该软件系统中的第j个方法,并用一个10×10的二维矩阵B编码表示,
(2)对该软件系统划分成3个模块,则经过模块划分之后的软件系统可以用集合C表示为C={c1,c2,c3},分别表示c1,c2,c3三个模块。对该软件系统的模块划分情况编码表示为一个3×10的二维矩阵A,表示将软件系统中的10个方法划分成了3个模块。第w个粒子的模块初始化划分情况编码表示为迭代到第t(t≥1)步时软件系统的模块划分情况编码表示为
(3)设定基于粒子群算法的参数,所述的参数中粒子的数量为5,软件系统划分成的模块数量为3,初始化各个粒子的局部最优值为0,全局最优值为0。
(4)对每个粒子进行初始化
例如对P1粒子进行初始化,确定方法f1所属的模块,则随机生成1,2,3三个随机整数,假设生成的随机数是3,则方法f1属于第3个模块c3。分别对F={f1,f2,...,fj,...,f10}(1≤j≤10)中的每个方法生成随机数,生成的10个随机数分别为3,3,3,3,1,2,3,2,3,1,则可以确定P1粒子的初始化编码为:
分别对P2,P3,P4,P5进行初始化编码为:
(5)计算每个粒子的当前适应度值
以计算P1粒子的初始化适应度值为例:
由方法调用矩阵B,首先计算P1粒子三个模块中的方法个数,N1=2;N2=2;N3=6;模块c1中包含方法f5和f10,模块c2中包含方法f6和f8,模块c3中包含方法f1、f2、f3、f4、f7、f9。
计算模块ci中的方法调用模块cj中方法的次数为:
计算模块ci内部方法之间的调用次数为:
软件系统进行模块划分后,计算第i个模块ci和第j个模块cj之间的耦合性εi,j:
计算第i个模块ci的内聚性μi:
计算粒子当前位置的适应度值:
(6)对于粒子P1,将当前适应度值0.35307和该粒子局部最优位置的适应度值l1Best=0进行比较,当前位置较好,则将粒子的当前位置作为该粒子的局部最优位置LocBest1=A1,粒子的当前适应度值作为该粒子的局部最优适应度值l1Best=fitness1=MQ1=0.35307。
(7)对于粒子P1,将其局部最优适应度值l1Best和全局经过的最优位置的适应度值LGBest进行比较,若粒子P1的局部最优值l1Best比LGBest好,则将其局部最优位置作为当前粒子群的全局最优位置gBest=LocBest1,该粒子的局部最优适应度值作为粒子群的全局最优适应度值LGBest=l1Best=0.35307。
(8)更新粒子各维的位置,以粒子P1中确定第3个方法f3所属的模块为例,假设方法f3属于第1个模块c1,使中则可以构造一个位置编码假设方法f3属于第2个模块c2,使中则可以构造一个位置编码假设方法f3属于第3个模块c3,使中则可以构造一个位置编码分别计算这三个位置的适应度值:
根据计算出的适应度值分别计算选择每个位置编码的概率值:
则方法f3以39.86%的概率选择模块c1,以26.81%的概率选择模块c2,以33.33%的概率选择模块c3。
按照上述方法,计算出方法f1选择三个模块的概率分别是:43.98%、23.74%、32.28%;方法f2选择三个模块的概率分别是:35.46%、27.68%、36.86%;方法f3选择三个模块的概率分别是:39.86%、26.81%、33.33%;方法f4选择三个模块的概率分别是:35.46%、27.68%、36.86%;方法f5选择三个模块的概率分别是:33.23%、33.52%、33.25%;方法f6选择三个模块的概率分别是:26.13%、47.05%、26.82%;方法f7选择三个模块的概率分别是:41.29%、30.18%、28.53%;方法f8选择三个模块的概率分别是:43.77%、44.15%、12.08%;方法f9选择三个模块的概率分别是:41.76%、31.32%、26.92%;方法f10选择三个模块的概率分别是:33.23%、33.52%、33.25%。
按照以上计算的各方法选择每个模块的概率取值,得到t=1时的模块划分情况为:此时粒子P1当前位置的适应度值为:
(9)经过10次迭代,达到最大迭代次数,则结束循环,此时粒子群的最优位置为作为软件系统的最终模块划分,如图4示。此时,将包含10个方法的软件系统划分为3个模块A、B、C,模块A中包含方法f1、f2、f3、f8、f9、f10;模块B中包含方法f4;模块C中包含方法f5、f6、f7;此时,模块划分的适应度值为fitness=0.8437。
本软件系统的模块划分达到高内聚,低耦合,有利于软件系统后期的维护和管理。
- 还没有人留言评论。精彩留言会获得点赞!