一种基于物品相似度的实时推荐方法与流程
本发明属于数据处理技术领域,具体涉及一种基于item-based的实时推荐方法。
背景技术:
近年来,随着互联网的飞速发展,网络已经逐渐成为人们选购商品、查询商品信息数据的第一选择。商品种类繁多,信息细化,网站在为用户提供越来越多选择的同时其结构也变得更加复杂,面对不计其数的商品信息,用户经常会迷失在大量的商品信息空间中,无法顺利找到自己需要的商品。
为解决这一问题,个性化推荐方法应运而生。传统推荐方法基于物品的协同过滤技术,即是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户历史访问的物品相类似的topn物品推荐给用户。其具体思想是:先预处理用户访问记录,根据用户物品偏好值计算物品相似矩阵,向用户推荐其偏好物品的相似物品。
但采用传统推荐方法的效果并不理想,不仅推荐准确度不高,而且运算效率低下。究其原因,是因为传统方法有如下几个缺陷:首先由于用户偏好值设置较为简单,导致传统的用户偏好矩阵不能很好地表示用户喜好,这就导致了后续计算的偏差会被持续放大。其次运算时每次都需要计算全量用户,这就重复计算了访问行为实际没有变化的用户推荐列表,导致消耗计算资源较多。此外,目前基于协同过滤技术基本应用于t+1推荐,没有拓展到实时推荐,使得推荐列表更新速度太慢,难以满足实际需求。
技术实现要素:
为解决上述问题,本发明公开了一种基于物品相似度的实时推荐方法,能够将登陆和未登录用户的用户标识进行统一,并定义了更为精确的用户偏好值函数,更为重要的是根据实时获取的用户行为数据进行计算,从而大大提升了推荐效率和计算精确度。
为了达到上述目的,本发明提供如下技术方案:
一种基于物品相似度的实时推荐方法,包括如下步骤:
步骤a,收集近期用户行为数据,对行为数据进行预处理,当用户在登陆状态,使用userid的murmur哈希值作为用户标识;用户在非登陆状态下,使用visitor_trace的murmur哈希值作为用户标识,将用户标识转换成统一的长整型数据值;
步骤b,采用偏好函数模型计算每个用户对浏览商品的偏好值,生成基础用户物品偏好值矩阵,计算物品相似矩阵,
所述偏好函数模型如下:
score=i+
其中i为初始值,xj表示当前时间与用户访问时间的时间差值;
步骤c,筛选出当前访客的最新行为数据,处理成实时偏好矩阵,结合物品相似矩阵,计算用户推荐列表,包括:
步骤c-1,筛选最新的访客用户的所有行为数据,对数据进行预处理,当用户在登陆状态,使用userid的murmur哈希值作为用户标识;用户在非登陆状态下,使用visitor_trace的murmur哈希值作为用户标识,将用户标识统一转换成长整型数值;
步骤c-2,采用偏好函数模型转换每个用户对浏览商品的偏好值,将所有用户对某个物品的偏好值作为一个向量来计算物品之间的相似度,生成实时用户物品偏好矩阵;
步骤c-3,利用步骤b得到的当天已保存的物品相似矩阵,采用矩阵乘法,通过下式计算:
物品相似矩阵*实时用户物品偏好矩阵
步骤c-4,基于步骤c-3得到的结果,计算各用户在同一物品下的中间值之和,得到各用户对各产品的预测值,过滤掉用户已浏览和已下单商品后,按偏好值大小排序,取排在前面的若干商品为推荐列表。
作为改进,为了避免推荐热门产品,步骤c-4中,加入相似度作为惩罚因子,预测值通过下式计算得到:
预测值=σ中间值/σ相似度。
作为优选,所述步骤c基于mapreduce开发。
作为优选,所述步骤c筛选5分钟内访客用户的所有行为数据。
作为优选,所述步骤c基于sparkstreaming开发。
作为优选,时间窗口设置为5s,每隔5s检测数据流更新情况,一旦更新,则收集更新的数据运算后进行推荐。
作为优选,所述物品相似矩阵通过调用mahout-itembased接口得到。
作为优选,所述物品相似矩阵采用稀疏矩阵来保存。
作为优选,当用户在用户物品偏好值矩阵中只对一个物品打分时,则不计算该用户的推荐列表。
与现有技术相比,本发明具有如下优点和有益效果:
1.融合useid和visitor_trace两个字段,并将用户标识散射成唯一长整型数据值,实现两个字段合并统一,整合登陆和未登陆用户的访问数据,保证登陆用户和非登陆用户的标识一致。
2.提出了合理的偏好值计算逻辑,加入时间因素,同时兼顾点击次数两个权重因子,合理地把用户对产品行为操作转换成数值化的喜好值,最大程度上逼近用户的真实喜好,使得用户偏好值的计算更为精确。
3.实时筛选出当前访客的历史及当前行为数据,预处理成偏好矩阵,结合通过近期全量数据计算并保存得到的物品相似矩阵,计算用户推荐列表。大大提高了推荐方法的效率,可以将推荐时间缩小到秒级内完成。
附图说明
图1为本发明方法流程图。
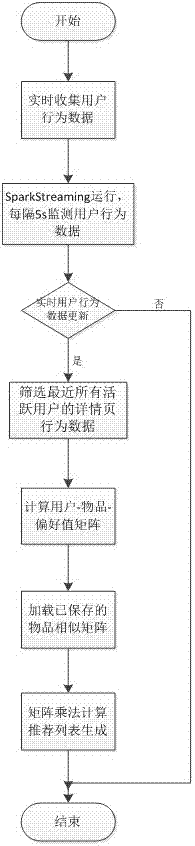
图2为基于sparkstreaming开发的实时推荐方法流程图。
具体实施方式
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
在传统技术中,用userid来区分不同用户,非登陆用户不可识别,这样会漏掉大量非登陆用户的访问行为数据,造成基础数据的缺失,导致后续运算的可靠性下降。本发明首先解决了这一问题,本发明结合userid和visitor_trace综合生成每位网站访客的唯一标识,当用户在登陆状态,优先使用userid的murmur哈希值作为用户标识;用户在非登陆状态下,则使用visitor_trace(硬件编码)的murmur哈希值作为用户标识,具体是采用murmur哈希函数把相应的字符串(userid、visitor_trace)转换成long值。本发明中凡是涉及到用户标识的地方均做此处理。这样能够解决未登陆用户不可识别的问题,且完整保留了所有访问行为数据,在计算物品相似度和推荐列表过程中增加了可靠性。
本发明的改进重点在于对用户偏好值进行了重新定义,在偏好函数数学模型中加入时间因素和点击次数两个权重因子,合理地把用户对产品行为操作转换成数值化的喜好值。偏好函数模型定义如下:
首先对偏好值进行初始化,具体的用户行为有:浏览、收藏、取消收藏、下单、退单等数种,基于此,偏好值初始化如下表1所示:
表1
随后定义时间权重模型和点击次数权重模型:
我们认为,距离当前时间越近的用户行为,越能反映用户偏好;反之,距离当前时间越久远的用户行为,对用户偏好定义越弱。
基于以上思路,定义时间权重具体计算公式为k*
我们认为,用户对某一个商品点击越频繁,表示用户对该商品的喜好度越强。基于以上思路,定义点击次数权重,用户每点击一次商品,即在偏好值上累计加入该次浏览的偏好值。
综合时间权重模型和点击次数权重模型得到真实的用户喜好值如下:
score=i+
基于以上改进基础,本发明提供的基于物品相似度的实时推荐方法,如图1所示,包括以下步骤:
步骤a,收集近期(本例选值15天)用户行为数据(包括但不限于visitor_trace、uid,产品id,具体操作,点击时间,产品类型),对行为数据进行预处理,预处理过程主要采用现有技术中的常规方式,不同的是,在行为数据预处理过程中,本发明融合用户标识(uid、visitor_trace),散射成统一的长整型数据值。
步骤b,采用偏好函数模型转换每个用户对浏览商品的偏好值,生成基础用户物品偏好值矩阵,将用户对某个物品的偏好值作为一个向量来计算物品之间的相似度,调用mahout-itembased接口(mahout-itembased接口为优选方式,也可以采用其他方式计算物品相似度,如基于物品本质内容来计算相似度),计算得到物品相似矩阵,并生成t+1初始化推荐列表。基于物品相似矩阵的稀疏性,我们采用稀疏矩阵来保存物品相似矩阵,具体相似矩阵存储格式为:(itema,itemb,similarity),以物品编号210054274的相似度数据如下表2所示:
表2
步骤c,采用基于mapreduce开发的批处理近实时推荐方法或基于sparkstreaming开发的实时推荐方法进行产品推荐。
近实时推荐方法基于mapreduce开发,筛选最新(如5分钟内)访客用户的所有行为数据,具体包括如下步骤:
步骤c-1,筛选最新的访客用户的所有行为数据(包括但不限于visit_trace,uid,产品id,具体操作,点击时间,产品类型),对数据进行预处理,将用户标识统一转换成长整型数值;本例取得了用户10001的行为数据,他在网站上浏览了两个物品(101,104)。
步骤c-2,采用偏好函数模型转换每个用户对浏览商品的偏好值,将所有用户对某个物品的偏好值作为一个向量来计算物品之间的相似度,生成实时用户物品偏好值矩阵。基于步骤c-1中得到的行为数据,本步骤得到的实时用户物品偏好值矩阵如下表所示:
表3
如果某用户在实时用户物品偏好值矩阵中只对一个物品打分,那么不计算他的推荐列表。
步骤c-3,利用步骤b得到的当天已保存的物品相似矩阵,采用矩阵乘法,通过下式计算:
物品相似矩阵*实时用户物品偏好矩阵
从已保存的相似矩阵中得知101,104与其他物品有相似的关系如下表所示:
表4
通过物品相似矩阵*实时用户物品偏好矩阵计算得到用户对这个相似物品的中间结果,即计算偏好值*对应相似度,得到结果如下表所示:
表5
步骤c-4,基于步骤c-3得到的结果,计算各用户在同一物品下的中间值之和,得到各用户对各商品的预测值。
例如,用户10001对物品102的最终预测分值计算过程是:预测值=0.805+1.722=2.527。
再过滤掉用户已浏览和已下单商品后,按偏好值大小排序,取排在前面的若干商品为推荐列表,本例取前36个商品。推荐列表被输入到hbase表中,便于分布式程序调用推荐数据。
作为改进,步骤c-4中,为了避免推荐热门产品,加入相似度数据作为惩罚因子,通过下式计算得到优化后的预测值:
预测值=σ中间值/σ相似度
例如,用户10001对物品102的最终预测分值计算过程是:预测值=(0.805+1.722)/(0.23+0.41)=3.948。
最终推荐合并预测结果如下表所示:
表6
实时推荐方法基于sparkstreaming开发,其主要步骤与近实时方式近似,不同点在于,本方法设置时间窗口为5s,每隔5s检测数据流更新情况,一旦更新,则收集更新的数据并进行推荐。此外,实时用户物品偏好矩阵保存在spark-rdd数据结构中,已保存的物品相似矩阵也被读取到spark-rdd中,利用spark实现矩阵乘法操作,得到用户-物品打分值。实时推荐方法流程图如图2所示。使用基于内存的spark作为执行引擎,具有高效和容错的特性,应用sparkstreaming实现推荐算法,能达到推荐列表实时生成的目的。
我们根据途牛网15天的点击流数据对本发明方法进行试验,这些数据中的用户行为数据是每天pv数为2000w左右。如果按照传统方法每次都对全量数据计算推荐列表,推荐程序运行时长大约需要90分钟。而采用本发明提供的实时推荐方法,收集最新访客行为,最近5分钟内的访客数基本在1.5w左右,抽取得到这部分访客的用户行为后,做标识统一化和用户偏好矩阵预处理,和已保存的物品相似矩阵做矩阵运算得到推荐列表,则推荐时间可以缩小到秒级内完成推荐列表更新。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!