一种跨年龄人脸识别方法与流程
本发明涉及人脸图像处理领域,更具体地,涉及一种跨年龄人脸识别方法。
背景技术:
随着科学技术的不断进步以及社会各方面对于快速有效的自动身份验证的迫切需要,生物特征识别技术在近几十年中得到了飞速的发展和应用,其中人脸识别技术成为了一个非常热门的研究课题。但目前的人脸识别技术还存在一些问题,其中一个很重要的问题就是人脸识别的识别率受年龄的影响较大。在人脸识别中,不同个体之间的人脸差异往往小于相同个体在不同情况下的人脸差异,这种情形在跨年龄人脸识别问题中尤为常见。
人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数特征等。人脸特征提取就是针对人脸的某些特征进行的。其中一个经典的方法是采用提取局部人脸特征的方法,比如提取局部二值模式(LBP)和尺度不变特征转换(SIFT)来做特征表达,虽然这些方法取得了一定的成功,但是依旧存在一些局限性,比如采用传统的特征描述符(例如LBP和SIFT等)来提取通用的人脸局部特征,而传统的LBP算法是基于经验编码的方式,其主观地认为人脸特征中等价二值模式出现的频率远大于非等价二值模式,即认为大部分LBP码中0、1的跳变次数不多于两次,从而经验地将非均匀的二值模式一律用同一个编码来代表。事实上,在跨年龄人脸识别中,非均匀二值模式出现的频率往往是很高的,这就导致了用LBP特征描述符描述丢失了大量的人脸特征信息,从而影响识别性能。
另一类解决跨年龄阶段的人脸识别问题的方法是用老化感知去噪自动编码器进行合成不同年龄的人脸,然后比较合成的同一年龄段的人脸来进行跨年龄人脸识别。这种方法有效地消除了年龄带来的人脸识别的困难,但是这种方法中的自动编码器的输入输出均为人脸图像,没有使用有效的特征描述符,因此存在效率低下、合成的人脸的鲁棒性不好等问题。
综上所述,现有技术提供的人脸识别方法,对跨年龄阶段人脸的识别能力比较差。
技术实现要素:
本发明提供一种跨年龄人脸识别方法,该方法解决现有技术对跨年龄人脸的识别能力较差的问题。
为了达到上述技术效果,本发明的技术方案如下:
一种跨年龄人脸识别方法,包括以下步骤:
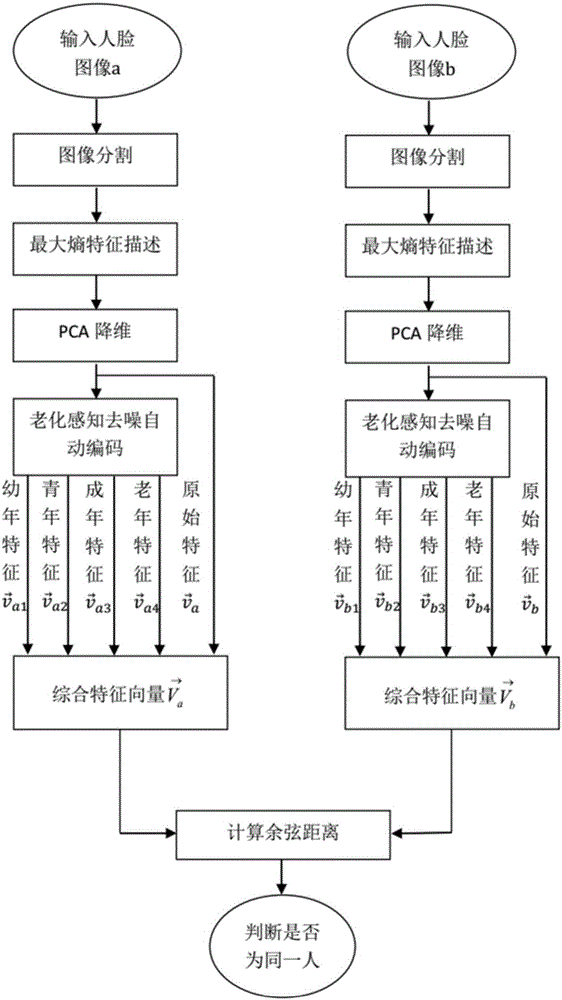
S1:对要识别的人脸图像进行密集采样,即将人脸图像划分为多个互相重叠的块,对每一块进行像素矢量的提取,划分时块的重叠半径采取多个值来尽可能保留人脸的局部信息;
S2:对于已提取的像素矢量,建立一棵决策树,将树的根节点概率值设置为1,采用最大熵的原则递归扩展树,最后为树的每个叶子节点分配一个编码,其中,每个叶子节点代表了一个局部特征;
S3:对每一幅人脸图像,将获取的最大熵特征描述编码串联成一个特征向量,对该特征向量重新进行分割,采用主成分分析等方法对特征向量进行降维,获得的低维特征向量v作为老化感知自动编码器的输入;
S4:用老化感知自动编码器对特征向量v进行编码,生成4个年龄段的人脸特征向量v'i(i=1,...,4),其中4个年龄段包括:幼年,青年,成年,老年;
S5:将两幅人脸合成的特征向量按照年龄段串联成一个长向量,同时原始人脸的特征向量也合并入该向量,通过计算两向量的余弦距离来判断两幅人脸是否来自同一人;
S6:模型训练时,提取同一个人的四个年龄段的人脸最大熵特征,将特征向量v加入一定噪声后映射到隐含层得到一个有损压缩码h,然后用h来预测四个年龄段的特征向量v'i,通过最小化损失函数得到自动编码器,通过多次上述地映射与重构过程生成多层老化感知去噪自动编码器,在构造多层去噪自动编码器时,需要用严格玻尔兹曼机以非监督的方式逐层地进行预训练。
进一步地,所述步骤S1中,为保证局部一致性,划分块时使重叠部分占整个块的50%,对划分好的块,采用采样半径r={1,3,5,7}进行采样,通过计算中心像素与半径r处的8个临近像素点的差值获得像素矢量。
进一步地,所述步骤S2中,决策树采用贪婪的模式进行扩展,在每一次节点分裂中,都使得编码分配的熵最大,在把第i个节点分成两个子节点的过程中,信息增益为:
G(i)=p(i)log p(i)-(p1log p1+p2log p2).
由于对给定的i,概率p(i)是固定的,通过使分裂后两个子节点概率分布尽量相同来最大化信息增益G(i)。
进一步地,所述步骤S3中,对于每一个块,获取了一个d维的最大熵特征向量,对于给定的一张人脸图像,将每一块的特征向量串联起来,获得一个M×N×4×d维的整幅人脸的最大熵特征向量,其中M×N为划分的块数,最后利用主成分分析对向量进行压缩获得m维的最大熵特征描述符v用于后续分析。
进一步地,所述步骤S4中,将步骤S3中获得的最大熵特征描述符v作为老化感知自动编码器的输入,映射出四个年龄段的特征向量{vi∈Rm|i=1,...,4},映射函数如下:
hi=Wiσ(hi-1)+bi,i=1,2,3
h'kj=W'k+1,jσ(h'k+1)+b'k+1,j,k=2,1,j=1,...,4
v'j=W'1,jσ(h'1j)+b'1,j,j=1,...,4
其中,激励函数σ(h)=(1+exp(-h))-1,i代表隐藏层的层号,j表示年龄段,k是重构层的层号,W是权重矩阵,W'是系重且有W'i=WiT,b是偏移向量,v'j表示重构出的第j个年龄段的人脸特征。
进一步地,所述步骤S5中,将要识别的两幅人脸以及用它们重构出的两组四个年龄段的特征向量进行串联得到两个总特征向量通过计算两向量的余弦距离来判断两幅人脸图像是否来自同一个人。
进一步地,所述步骤S6中,在训练时,先提取同一人脸的四个年龄段的特征,输入任意年龄段的特征到经过严格玻尔兹曼机预训练的老化感知去噪自动编码器中,通过步骤S4中的映射与重构方法,得到该人脸的四个年龄段的重构特征,然后最小化平方误差函数来训练老化感知去噪自动编码器,误差函数如下:
式中ε1是所有层的权重衰减系数,vi是第i个年龄段的原始人脸特征,v'i是第i个年龄段的重构人脸特征。
与现有技术相比,本发明技术方案的有益效果是:
1、采用最大熵特征描述符作为人脸特征的表达,有效解决了一些传统描述符出现的包含信息量不足、大量特征信息丢失等带来的跨年龄人脸识别率低下的问题。
2、采用高效的描述符作为老化感知去噪自动编码器的输入,避免了直接使用人脸图像作为自动编码器输入所带来的模型复杂、重构效果不稳定等问题。
3、直接计算合成特征的余弦距离来获得跨年龄人脸的匹配度,避免了使用卷积神经网络等较复杂的学习方法,在保证识别率的前提下降低模型复杂度,提高识别效率。
附图说明
图1为本发明总体流程图;
图2为本发明的老化感知去噪自动编码器步骤子流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种基于最大熵特征描述符及老化感知去噪自动编码器的跨年龄人脸识别方法,包括以下步骤:
(1)对要识别的人脸图像进行密集采样,即将人脸图像划分为多个互相重叠的块,对每一块进行像素矢量的提取,划分时块的重叠半径采取多个值来尽可能保留人脸的局部信息;
(2)对于已提取的像素矢量,建立一棵决策树,将树的根节点概率值设置为1,采用最大熵的原则递归扩展树,最后为树的每个叶子节点分配一个编码,其中,每个叶子节点代表了一个局部特征;
(3)对每一幅人脸图像,将获取的最大熵特征描述编码串联成一个特征向量,对该特征向量重新进行分割,采用主成分分析等方法对特征向量进行降维,获得的低维特征向量v作为老化感知自动编码器的输入;
(4)用老化感知自动编码器对特征向量v进行编码,生成4个年龄段的人脸特征向量v'i(i=1,...,4),其中4个年龄段包括:幼年,青年,成年,老年;
(5)将两幅人脸合成的特征向量按照年龄段串联成一个长向量,同时原始人脸的特征向量也合并入该向量,通过计算两向量的余弦距离来判断两幅人脸是否来自同一人;
(6)模型训练时,提取同一个人的四个年龄段的人脸最大熵特征,将特征向量v加入一定噪声后映射到隐含层得到一个有损压缩码h,然后用h来预测四个年龄段的特征向量v'i,通过最小化损失函数得到自动编码器,通过多次上述地映射与重构过程生成多层老化感知去噪自动编码器,在构造多层去噪自动编码器时,需要用严格玻尔兹曼机以非监督的方式逐层地进行预训练。
步骤(1)中的具体过程如下:为保证局部一致性,划分块时使重叠部分占整个块的50%,对划分好的块,采用采样半径r={1,3,5,7}进行采样,通过计算中心像素与半径r处的8个临近像素点的差值获得像素矢量。
步骤(2)中的具体过程如下:决策树采用贪婪的模式进行扩展,在每一次节点分裂中,都使得编码分配的熵最大,在把第i个节点分成两个子节点的过程中,信息增益为:
G(i)=p(i)log p(i)-(p1log p1+p2log p2).
由于对给定的i,概率p(i)是固定的,通过使分裂后两个子节点概率分布尽量相同来最大化信息增益G(i)。
步骤(3)中的具体过程如下:对于每一个块,获取了一个d维的最大熵特征向量,对于给定的一张人脸图像,将每一块的特征向量串联起来,获得一个M×N×4×d维的整幅人脸的最大熵特征向量,其中M×N为划分的块数,最后利用主成分分析对向量进行压缩获得m维的最大熵特征描述符v用于后续分析。
步骤(4)中的具体过程如下:将步骤(3)中获得的最大熵特征描述符v作为老化感知自动编码器的输入,映射出四个年龄段的特征向量{vi∈Rm|i=1,...,4},映射函数如下:
hi=Wiσ(hi-1)+bi,i=1,2,3
h'kj=W'k+1,jσ(h'k+1)+b'k+1,j,k=2,1,j=1,...,4
v'j=W'1,jσ(h'1j)+b'1,j,j=1,...,4
其中,激励函数σ(h)=(1+exp(-h))-1,i代表隐藏层的层号,j表示年龄段,k是重构层的层号,W是权重矩阵,W'是系重且有W'i=WiT,b是偏移向量,v'j表示重构出的第j个年龄段的人脸特征。
步骤(5)中的具体过程如下:将要识别的两幅人脸以及用它们重构出的两组四个年龄段的特征向量进行串联得到两个总特征向量通过计算两向量的余弦距离来判断两幅人脸图像是否来自同一个人。
步骤(6)中的具体过程如下:在训练时,先提取同一人脸的四个年龄段的特征,输入任意年龄段的特征到经过严格玻尔兹曼机预训练的老化感知去噪自动编码器中,通过步骤(4)中的映射与重构方法,得到该人脸的四个年龄段的重构特征,然后最小化平方误差函数来训练老化感知去噪自动编码器,误差函数如下:
式中ε1是所有层的权重衰减系数,vi是第i个年龄段的原始人脸特征,v'i是第i个年龄段的重构人脸特征。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!