一种考虑节点局部标注特性的符号预测方法与流程
本发明涉及一种互联网技术,特别是一种考虑节点局部标注特性的符号预测方法。
背景技术:
符号网络是指边具有正或负符号属性的网络,符号为正表示网络中两用户间具有相互信任的、积极的朋友关系,负边则表示不信任的、消极的敌对关系。具有符号属性的网络普遍存在,因为在许多复杂系统中都存在对立关系:在线社交网络中的用户可以对其他用户表达信任或不信任的态度、标注朋友或敌人关系,对某一问题给出不同的观点;生物系统中,神经元之间存在促进和抑制作用;国际关系中更是存在合作与敌对关系,研究网络的符号属性有利于理解网络的基本结构特征、理解信任和不信任的传播方式。这些复杂系统用现有针对无符号的二值网络建模不能准确反映节点间的关系,简单网络的研究思路和方法并不适用于符号网络。符号网络的研究始于Heider基于社会心理学对人类关系的研究,随着复杂网络研究的逐步展开,符号网络的结构特征与演化规律受到研究者的关注。
在符号网络中,由于边的符号属性能够直接反映节点间的态度,因此在推荐系统、舆情分析与观点形成、网络欺凌与社会排斥等问题中都有应用。于是,如何通过部分观测到的网络符号预测未知的边符号成为符号网络中非常重要的研究方向,关于它的研究近几年受到来自复杂网络、机器学习等领域的重视,并提出了许多有效方法。
符号预测方法根据考虑网络结构特征的不同大致可以分为两类:①考虑网络局部特征的方法;②考虑网络全局特征的方法。考虑网络局部特征的方法主要利用节点的邻域特征如:节点的出度、入度以及三元组结构特征进行符号预测。这类方法主要基于节点邻居的统计特征以及社会学相关理论:结构平衡理论(弱结构平衡)和地位理论通过分析节点邻居间的标注特征实现边符号的预测,所有基于结构平衡和地位理论的预测方法均要求两节点间必须具有共同邻居,否则无法构成三元组。例如:Guha等最早研究了网络模型上的符号预测问题,他们将信任网络表示为矩阵并运用不同的矩阵运算代表信任关系在网络上的不同传播方式,成功实现了信任关系的预测。Leskove c等首先采用机器学习的方法对符号预测问题进行了研究。他们利用节点的出度、入度、节点的嵌入性以及基于地位理论的所有16种待预测边所处的三角形的关系模式作为特征采用逻辑回归模型训练分类器,得到了较高的预测精度。文献则通过网络局部特征和地位理论为特征采用SVM算法进行二值分类实现符号预测。相对于Leskovec考虑长度为3的有序环构建的网络特征,Chiang等,利用Katz指标提出一个不平衡测度指标并通过长度为
的环的平衡程度构建特征集,然后使用逻辑回归模型进行符号预测,当环的长度从3增加到5时,预测精度有所提高,但是当>5后对预测精确度的影响不大。事实上能够反映符号网络不平衡程度的测度都可以用于符号预测,因为对于未知符号的预测就是使图的不平衡程度最小。文献通过分析两节点间不同的连接形式,提出符号预测的方法,使得在没有共同邻居的情形下的预测精度有所提高。
研究发现符合结构平衡(弱结构平衡)的局部结构特征反过来会促使一些有趣的全局特征的出现,当然也就催生了利用网络全局结构进行符号预测的方法。文献就从谱分析的角度出发进行符号预测并指出许多基于谱分析的方法可以从简单的二值网络扩展到符号网络。他们将拉普拉斯矩阵的定义扩充到符号网络,通过拉普拉斯矩阵的核函数进行网络符号的预测。Hsieh等发现满足弱结构平衡理论的符号网络其邻接矩阵具有低秩特征于是将符号预测问题转化为矩阵填充问题,用低秩填充法有效地进行了符号预测。他们还将符号预测近似为低秩矩阵分解问题进行了符号预测。文献也研究了矩阵分解在符号预测中的应用并解决了数据不平衡对预测精度的影响。文献提出了一种区别于Hsieh以逐点误差衡量原矩阵与结果矩阵误差的方法,他们将成对误差应用到矩阵分解的损失函数中,给出的算法MF-LiSP取得了较高精确度。另外,为提高矩阵填充、矩阵分解的效率也提出相应方法。另外,符号网络中除了结构信息外还有丰富的元数据信息,它们代表用户的熟识度、声誉、语义与态度等,运用元数据与网络结构信息共同进行符号预测也受到关注。通过以上介绍发现,符号网络的局部结构特征反过来会促使全局特征的出现,可见两者间联系紧密,因此符号预测方法仅使用局部特征或全局特征都不够全面,在预测算法中如何同时利用局部和全局特征是一个需要进一步研究的问题。另外,对于局部特征目前的依据只有结构平衡(弱结构平衡理论)和地位理论,需要进一步丰富。
技术实现要素:
本发明的目的在于提供一种考虑节点局部标注特性的符号预测方法,用合适的模型描述在线社会网络中用户间友好或敌对的态度,从全局和局部两个角度共同考察用户的标注行为。
一种考虑节点局部标注特性的符号预测方法,包括以下步骤:
步骤1,获取符号网络的形式表达;
步骤2,分析符号网络结构特征,获取网络邻接矩阵的秩与结构平衡和弱结构平衡理论间的关系,利用低秩矩阵分解对低秩矩阵进行分解,且满足矩阵秩最小的约束条件;
步骤3,根据符号网络结构特征结论,将符号预测问题转化为优化问题;
步骤4,利用随机梯度下降法对低秩矩阵分解,得到考虑网络全局特征。
本发明公开了一种考虑节点局部标注特性的符号预测方法及技术方案,该技术方案利用图论、矩阵论、低秩矩阵分解以及随机梯度下降等计算机技术手段对在线社会网络的标注行为进行建模,基于低秩矩阵分解方法设计了同时考虑网络全局和局部方法标注特征的符号预测方法,该方法具有运算速度快预测精度高的特点,适合应用于大规模在线社会网络数据处理。本发明在三个这是网络数据集上进行了实验,采用两种指标评价预测效果,实验结果显示本发明提出的方法优于其他四种经典算法。
下面结合说明书附图对本发明作进一步描述。
附图说明
图1为预测方法流程图。
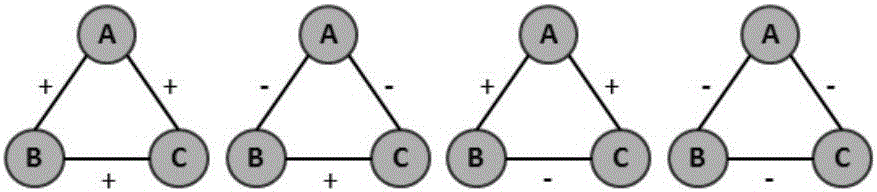
图2为四种三角形模体结构示意图。
图3为弱平衡结构与矩阵的低秩特性示意图。
图4为待预测边与节点标注的偏置行为示意图。
图5为数据集统计特征示意图。
图6为互惠边信息对符号预测的提高示意图。
图7为三个符号网络的预测效果示意图。
图8为预测精度与K间的关系示意图。
具体实施方式
符号网络的形式化表达:用符号网络表示在线社会网络中用户间的关系。符号为正表示网络中两用户间具有相互信任的、积极的朋友关系,负边则表示不信任的、消极的敌对关系。
结合图1,一种考虑节点局部标注特性的符号预测方法,包括以下步骤:
步骤1,获取符号网络的形式表达;
步骤2,分析符号网络结构特征,获取网络邻接矩阵的秩与结构平衡和弱结构平衡理论间的关系,利用低秩矩阵分解对低秩矩阵进行分解,且满足矩阵秩最小的约束条件;
步骤3,根据符号网络结构特征结论,将符号预测问题转化为优化问题;
步骤4,利用随机梯度下降法对低秩矩阵分解,得到考虑网络全局特征;
步骤5,在预测结果上利用互惠边信息优化预测效果。
步骤3中加入偏置项用以描述不同节点的标注行为,由全局和局部特征共同决定预测结果,达到提高预测精度的目的。
最后利用真实符号网络数据证明本发明能够获得较其他方法好的预测效果且算法效率高。
步骤1的具体过程为定义符号网络G为:G=(V,E,S),其中V={1,2,3,...,n}为节点集合,E={1,2,3,...,m}为边集合,S={-1,0,1}表示边的符号,O为已观测到的边集,i,j∈V,e(i,j)∈E,s(i,j)∈S,若节点i与j的边符号为正则s(i,j)=1,节点i与j的边符号为负则s(i,j)=-1,节点i与j的边符号未被观测到时s(i,j)=0。符号网络G对应有邻接矩阵A∈im×n:
步骤2的具体过程为:符号网络中三个节点间的关系共形成四种三角形模体(如图2所示),从社会心理学角度看,在三角形模体中,三符号积为正则平衡,否则不平衡。平衡网络的判别条件极其严苛,放宽结构平衡的约束,则有弱结构平衡理论:只要三角形模体中不存在两正一负的关系就构成弱平衡。当网络满足弱平衡结构时,节点可以被分成K个子集,且子集内节点间的边全为正,子集间节点的边全为负。这类符号网也被称为K-平衡网。当符号网络满足K-
平衡条件时,网络节点可以被分成K个子集,若对网络节点编号排序,此时其邻接矩阵将为分块矩阵,这个矩阵的秩小于邻接矩阵的行列数,由此可以判定:符号网络具有低秩性。
结合图3,步骤3的具体过程为:
步骤3.1,将邻接矩阵A中为0的元素替换为1形成矩阵X;
步骤3.2,将符号预测问题转化为优化问题,形式化描述为
由于求解矩阵填充为NP难问题,可以用核范数代替目标函数,然而矩阵填充被运用还有一个条件,即:被观测边符号要均匀分布,有时这一条件不容易被满足,且矩阵填充的运算速度较慢,因此矩阵填充经常用低秩矩阵分解问题来近似;
步骤3.3,将邻接矩阵A分解为两个K行n列的矩阵PT和Q,使得PT与Q的积与A之间的误差最小;
步骤3.4,令为预测到的用户i对用户j的评价;
步骤3.5,将矩阵模型转化为最优化问题
其中,l为损失函数,用于衡量原矩阵与预测结果矩阵PTQ间的误差,Ω为用来防止过拟合的正则化项,λ为惩罚因子。λ太大会导致模型欠拟合,而太小导致过拟合,实践中,要根据实际情况对λ的值做出调整,以上为基本矩阵分解的符号预测算法。损失函数l是Square_loss、Exp_loss函数或Hinge_loss中的任意一个。
结合图4,基本的矩阵分解模型仅表现了邻接矩阵的全局特性,并不考虑网络的局部特征,事实上,在被符号网络所代表的社会关系网中,不同节点的标注行为是不同的,常常带有偏置,因此要准确预测边的符号需要考虑与该边相连的两个节点的局部标注特性,可在预测中可添加以下偏置项:
bij=μ+Uiout+Ujin
其中,μ为符号网络平均评价倾向,μ为负表示当前网络用户更倾向于给其他用户以负面评价,反之则表示相反的情况;Uiout表示节点i发出的边符号的总和,表达了节点i对其他相邻节点的评价特特征,当节点i发出的边有一半以上为负时被预测边符号为负的可能性就增加;Ujin表示节点j收到的边符号的总和,当j的偏置项Ujin为负时表示节点j收到了更多的负面评价,因此被预测边的符号为负的可能性也将增加。
步骤选择Square_loss为损失函数,改写优化目标函数为:
节点i对节点j的评价预测结果为
步骤4的具体过程为:
步骤4.1,令通过求梯度以确定优化函数下降方向并获取目标函数对Uiout、Ujin的偏导数:
步骤4.2,由于沿梯度方向相反的方向下降最快,于是得到如下迭代公式:
Pi←Pi+α(eij*Qj-λPi)
Qj←Qj+α(eij*Pi-λQj)
Uiout←Uiout+α(eij-λUiout)
Ujin←Ujin+α(eij-λUjin)
通过反复迭代并不断优化参数,使矩阵A与分解后矩阵PTQ间的误差小于设定的误差值即最终收敛。其中α为学习速度,α越大下降就越快。随机梯度下降的时间复杂度为O(t*m*K),t为迭代并收敛次数。由于符号网络满足低秩特性通常K值很小且收敛较快,因此采用随机梯度下降法求解最小化问题速度较快。
步骤5,在带有偏置项的预测算法基础上利用互惠边信息进一步改善预测效果;
Matlab编程统计符号网络中互惠边在整个符号网络中的占比,根据社会学中“镜子效应”可得,当i→j有正边,使得j→i间存在正边的可能性大大增加,因此可以利用这一现象增强预测效果:在训练集上使用预测算法得到预测结果,找出训练集中的边e(i,j),若在测试集中存在边e(j,i)则令边e(i,j)符号与边e(j,i)符号相同,若与预测结果不符则修改预测结果。
步骤6利用真实符号网络数据证明本发明能够获得较其他方法好的预测效果且算法效率高;
实验中的三个真实大型社会网络数据来自于斯坦福大学的SNAP项目(http://snap.stanford.edu)。
为证明所提带有偏置的矩阵分解模型SLB-MF(Square_loss Matrix Factorization with Bias)对符号预测问题的有效性,将它与以下基准预测算法进行比较:
(1)OutDegree(简写为OD);
(2)InDegree(简写为ID);
(3)LR(Logistic Regression);
(4)SL-MF(Square_loss Matrix Factoriza-tion);
算法评价
用以下指标评价预测的效果:
(1)RMSE均方根误差
(2)精确性(Accuracy) 。
- 还没有人留言评论。精彩留言会获得点赞!