一种数据感知的Spark配置参数自动优化方法与流程
本发明属于电子信息、大数据、云计算等技术领域,特别涉及一种数据感知的Spark配置参数自动优化方法。
背景技术:
Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce通用并行框架。它发展迅速,仅用了短短五年时间,就成为Apache基金的顶级项目。由于Spark具有将中间结果存储在内存中的特点,Spark运行迭代和交互式程序比传统的磁盘计算框架Hadoop提高了10倍。由于Spark在大数据分析领域具有重要地位,根据Typesafe公司的调查,2015年已有超过500家企业使用Spark。
配置参数优化一直是大数据系统的研究热点之一,由于配置参数众多(多于100个),性能受配置参数影响很大,应用程序具有不同特点。因此使用默认配置远未达到最佳性能。Spark是一种新兴的大数据内存计算框架,由于Spark具有“内存计算”的特性,集群中的所有资源:CPU、网络带宽、内存,都会成为制约Spark程序的瓶颈。而不同的Spark应用程序又具有不同特点,比如Kmeans指令局部性好但数据局部性差,PageRank的shuffle和迭代选择都比KMeans多,WordCount不包含迭代等等。本发明要解决的问题是对特定的集群环境、输入数据集和应用程序,为自动Spark找到最优的配置参数。
基于随机森林的Hadoop参数自动优化方法RFHOC(A Random-Forest Approach to Auto-Tuning Hadoop’s Configuration,简称RFHOC)是一种针对运行在一个给定集群上的应用程序的配置参数优化方法,主要分为三个步骤:
1.性能测试
2.构建性能模型
3.迭代搜索最优配置
当用户第一次运行一个Hadoop应用程序时,RFHOC workload profiler收集运行时Hadoop的配置参数和MapReduce阶段的执行时间。随后,不同阶段的执行时间和对应的配置参数将作为随机森林算法的输入用于构建性能预测模型。RFHOC为map和reduce阶段分别构建回归模型用于预测各个阶段的性能。首先每个阶段要产生一个训练集S,S的每一行为向量vj,vj包含了每次执行时间和对应的Hadoop配置参数值。建好性能模型后,RFHOC运用遗传算法搜索Hadoop最优参数。遗传算法使用随机森林模型预测的性能和对应的配置作为输入做全局搜索。Map和reduce阶段的执行时间相加为程序运行的总时间,也是遗传算法的适应值。
现有技术是手动配置参数和自动配置参数。手动配置参数方法弊端在于太耗时,而且要求用户对Spark的运行机制、参数的意义,作用和取值范围具有较深的了解。用户需要手动增大或减少Spark参数值,然后配置Spark,运行应用程序,找到使执行时间最短的参数值。由于不同集群环境、不同应用程序、和不同输入数据集的最优配置参数不同,手动配置参数方法是一个耗时、枯燥的工作。
现有的自动配置参数方法缺点在于性能模型精度低、建模成本高。有些方法用人工神经网络(Artificial Neural Network)、支持向量机(Support Vector Machine)建模,但是若要达到较高精度(10%以内),需要使用很庞大的训练集。
技术实现要素:
基于上述情况,有必要提供了一种数据感知的Spark配置参数自动优化方法。
一种数据感知的Spark配置参数自动优化方法,包括如下步骤:
收集数据;所述收集数据具体包括:选定Spark应用程序,进一步确定上述应用程序中影响Spark性能的参数,确定上述参数的取值范围;在取值范围内随机生成参数,并生成配置文件配置Spark,配置后运行应用程序并收集数据;所述数据包括但不限于:Spark运行时间、输入数据集、配置参数值;
构建性能模型;将收集的Spark运行时间、输入数据集、配置参数值数据构成横向量,多个向量构成训练集,通过随机森林算法对上述训练集进行建模;
搜索最优配置参数;使用构建好的性能模型,通过遗传算法搜索最优配置参数。
进一步的,在所述搜索最优配置参数步骤之后还包括一验证步骤,所述验证步骤为将搜索到的最优配置参数进行配置Spark,并运行验证执行时间是否为最短。
更进一步的,在收集数据步骤中所述随机生成参数为:假设参数s取值范围是[a,b],在该取值范围内统一、均匀、随机地取值c,a≦c≦b,则产生一条记录“s/tc”(/t是一个制表符),按照这个方法,生成其他配置参数。
作为一种改进,所述通过随机森林算法对上述训练集进行建模具体包括如下步骤:
随机森林算法从给定的训练集通过多次随机的可重复的采样得到多个bootstrap数据集;
对每个bootstrap数据集构造一棵决策树,构造是通过迭代的将数据点分到左右两个子集中实现的,这个分割过程是一个搜索分割函数的参数空间以寻求最大信息增量意义下最佳参数的过程;
在每个叶节点处通过统计训练集中达到此叶节点的分类标签的直方图经验的估计此叶节点上的类分布;
迭代训练过程一直执行到用户设定的最大树深度或者直到不能通过继续分割获取更大的信息增益为止;
在随机森林算法中,执行时间作为因变量,输入集和配置参数作为自变量,还需要确定ntree和mtry值,ntree值是随机森林中建立的决策树数量,mtry值是决策树在每一个分裂节点处样本预测器的个数。
作为进一步改进,所述通过遗传算法搜索最优配置参数具体为:
把一组向量{c1,…,cm}设为初始配置参数值输入性能模型,模型输出执行时间t1,再变化初始值,输入性能模型,模型输出执行时间t2,t2与t1做比较,时间较短所对应的配置参数作为最优配置,再重复以上步骤,直至找到执行时间最短的配置。
具体的,所述随机森林算法如下所示:
输入:训练集S,引导函数F,整数ntree(bootstrap样本数)
1.for i=1to ntree{
2.S’=从S中抽取bootstrap样本(独立同分布样本,有放回抽取)
3.Ci=F(S’)
4.}
5.
输出:聚合C*。
本发明提供了一种数据感知的Spark配置参数自动优化方法,通过事先确定Spark应用程序以及影响Spark性能的参数,随机配置参数得到训练集,将训练集通过随机森林算法构建性能模型,通过遗传算法搜索出最优配置参数。本发明不要求用户理解Spark运行机制、参数意义作用和取值范围,以及应用程序特点和输入集的情况下,能为用户找到运行在特定集群环境下特定应用程序的最优配置参数,较之以前的参数配置方法更简单快捷本发明使用的随机森林算法结合了机器学习和统计推理的长处,能够使用较少训练集,达到较高精度。
附图说明
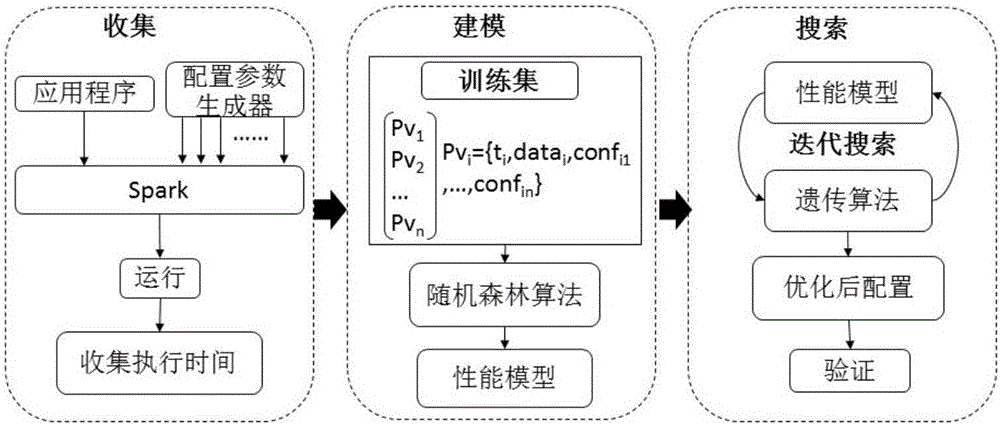
图1为本发明一种数据感知的Spark配置参数自动优化方法整体流程示意图;
图2为本发明一种数据感知的Spark配置参数自动优化方法中遗传算法示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清晰,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1-2所示,一种数据感知的Spark配置参数自动优化方法,包括如下三大步骤:
1)收集数据;所述收集数据包括四个小步骤,如下所示:
(1)从Spark所有参数中找到影响性能的参数;
(2)确定参数的取值范围;
(3)选择应用程序的输入集;
(4)在确定的取值范围内随机变化参数,配置Spark,运行不同输入数据集的应用程序,收集到的数据作为训练集;
在收集数据(Collecting)阶段,上述四小步骤具体可以表述为:选定实验用的Spark应用程序,比较常用的是HiBench基准测试程序,HiBench包含了图计算、机器学习、非迭代式应用程序,从中选取若干代表性的程序,如KMeans、Bayesian、PageRank、WordCount、TeraSort,进一步确定上述应用程序中影响Spark性能的参数,确定上述参数的取值范围;在取值范围内随机生成参数,并生成配置文件配置Spark,每个应用程序选择若干输入集,Conf Generator是配置参数生成器,使用Conf Generator来产生配置文件,配置文件包含随机生成的参数,配置后运行应用程序并收集数据;所述数据包括但不限于:Spark运行时间、输入数据集、配置参数值。
在收集数据步骤中所述随机生成参数具体通过如下方式产生:假设参数s取值范围是[a,b],在该取值范围内统一、均匀、随机地取值c,a≦c≦b,则产生一条记录“s/tc”(/t是一个制表符),按照这个方法,生成其他配置参数。
2)构建性能模型;将收集的Spark运行时间、输入数据集、配置参数值数据构成横向量,多个向量构成训练集,通过随机森林算法对上述训练集进行建模。
具体的,随机森林算法对上述训练集进行建模具体包括从给定的训练集通过多次随机的可重复的采样得到多个bootstrap数据集;对每个bootstrap数据集构造一棵决策树,构造是通过迭代的将数据点分到左右两个子集中实现的,这个分割过程是一个搜索分割函数的参数空间以寻求最大信息增量意义下最佳参数的过程;在每个叶节点处通过统计训练集中达到此叶节点的分类标签的直方图经验的估计此叶节点上的类分布;迭代训练过程一直执行到用户设定的最大树深度或者直到不能通过继续分割获取更大的信息增益为止;在随机森林算法中,执行时间作为因变量,输入集和配置参数作为自变量,还需要确定ntree和mtry值,ntree值是随机森林中建立的决策树数量,mtry值是决策树在每一个分裂节点处样本预测器的个数。
其中,所述随机森林算法具体如下所示:
输入:训练集S,引导函数F,整数ntree(bootstrap样本数)
1.for i=1to ntree{
2.S’=从S中抽取bootstrap样本(独立同分布样本,有放回抽取)
3.Ci=F(S’)
4.}
5.
输出:聚合C*。
本发明用机器学习中的集成算法——随机森林建模;机器学习相较于传统的统计学习方法,具有能够组织和拟合参数,能够处理更大的数据集的优势;随机森林相比于其他机器算法,能解决过拟合问题,处理特征较多(高维)情况等等效果。
3)搜索最优配置参数;使用构建好的性能模型,通过遗传算法搜索最优配置参数。具体的做法是把一组向量{c1,…,cm}设为初始配置参数值输入性能模型,模型输出执行时间t1,再变化初始值,输入性能模型,模型输出执行时间t2,t2与t1做比较,时间较短所对应的配置参数作为最优配置,再重复以上步骤,直至找到执行时间最短的配置。
遗传算法相比于其他优化算法,如穷举法、贪心法、模拟退火算法、蚁群算法,具有良好的全局搜索能力,可以快速地将解空间中的全体解搜索出,而不会陷入局部最优解的快速下降陷阱;搜索从群体出发,具有潜在的并行性,可以进行多个个体的比较;搜索过程简单,使用评价函数启发;使用概率机制进行迭代,具有随机性等优点。
最后,作为一种优选方式,在所述搜索最优配置参数步骤之后还包括一验证步骤,所述验证步骤为将搜索到的最优配置参数进行配置Spark,并运行验证执行时间是否为最短。
本发明提供了一种数据感知的Spark配置参数自动优化方法,通过事先确定Spark应用程序以及影响Spark性能的参数,随机配置参数得到训练集,将训练集通过随机森林算法构建性能模型,通过遗传算法搜索出最优配置参数。本发明不要求用户理解Spark运行机制、参数意义作用和取值范围,以及应用程序特点和输入集的情况下,能为用户找到运行在特定集群环境下特定应用程序的最优配置参数,较之以前的参数配置方法更简单快捷本发明使用的随机森林算法结合了机器学习和统计推理的长处,能够使用较少训练集,达到较高精度。本发明可以为任意输入数据集寻找最优配置参数,由于在实际情况下用户在运行应用程序时,输入集是任意变化的,考虑到了实际应用情况。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!