一种基于NVRAM的内存分配链表及内存分配方法与流程
本发明属于内存管理领域,更具体地,涉及一种基于NVRAM的内存分配链表及内存分配方法。
背景技术:
根据Gartner技术成熟度曲线2014年到2015年的变化,大数据已经历膨胀期和高峰期,消失在了2015年的曲线上,这表明大数据的基本概念、关键技术及对其利用已得到了业界的广泛认可,对大数据处理分析,以发现其中蕴含的经济价值,成为了业界的共识。大数据也为存储提出了新的挑战,面向大数据的内存计算等新应用需要的内存容量是现在的1000倍。而与此同时,传统的DRAM(动态随机存取存储器)的发展已经遇到瓶颈:现有的DRAM尺寸工艺已经达到20nm的极限,同时数据刷新所产生的功耗问题随着其容量扩大变得不可忽视。
诸如PCM(相变存储器),ReRAM(阻变式存储器)以及STT-RAM(自旋转移力矩存储器)等这类新型非易失存储器有非易失性、位可寻址、位可修改、读延迟短、读能耗低、无需刷新等杰出优点,使得其很有可能作为主存的替代品。以PCM为例,其对比DRAM能耗更低,同时其非易失性和比较高的存储密度也使得它成为理想的内存替代品。当然,PCM也有缺陷,特别是写性能、写功耗和寿命问题。
就内存管理和内存分配而言,近几十年来,通用的内存分配器glibc malloc一直都是软件的基本元素,如图1所示,glibc malloc的空闲内存分配链表通过bins,也就是链表数据结构来管理空闲chunks,基于所管理的chunk大小不同,将bin分为fast bin、small bin、large bin和unsorted bin,在所有的bin中:fast bin在内存分配以及释放上速度更快,fast bin记录着大小以8字节递增的着free chunk单链表,链表内的chunk被称为fast chunk,大小为16~80字节,每一个单链表内的chunk大小均相同且使用LIFO进行链表中chunk的插入/删除;小于512字节的chunk被称为small chunk,而保存small chunk的bins被称为small bins,small bins比large bins在内存分配/释放的速度上更快,同样的,small bins记录着大小以8字节递增的free chunk双向循环链表,每一个双向循环链表内的chunk大小均相同且使用FIFO进行链表中chunk的插入/删除,两个相邻的空闲chunk会被合并成一个空闲的chunk,合并消除了碎片化的影响但是减慢了释放的速度;大于等于512字节的chunk被称为large chunk,而保存large chunk的bins被称为large bins。每个large bin都包括一个空闲chunk的双向循环链表,但是其中的chunk大小不一定相同,以递减的形式保存,即最大的chunk保存在最前的位置而最小的chunk保存在最后的位置。同样,也会将两个相连的空闲chunk合并成一个更大的空闲chunk。当small chunk和large chunk被释放时,它们并非被添加到前面提到的各自的bin中,而是被添加到一个叫“unsorted bin”中,其包括一个用于保存空闲chunk的双向循环链表,而且没有chunk大小限制,任何大小的chunk都可以添加进来。这种途径给予分配器重新使用最近刚释放掉chunk的第二次机会,如此一来寻找合适bin和chunk的时间开销就被抹掉了,因此内存的分配和释放也会更快一点。
如今对动态内存管理的需求现如今也转移到了NVRAM领域。但是glibc malloc内存分配器的内存分配链表设计非但不适合NVRAM,而且会加速NVRAM的磨损。
对NVRAM内存来说,使用现有的内存分配器存在两个方面的缺陷:(1)内存分配策略导致NVRAM局部热区;(2)固定的从虚拟内存地址到物理地址的映射导致原地内存写。
技术实现要素:
针对现有传统技术的以上缺陷或改进需求,本发明提供了一种基于NVRAM的内存分配链表及内存分配方法,其目的在于Fastbins中的fast bin链表采用FIFO法进行链表中chunk的插入或删除;Bins为每个small bin和new bin链表添加一个分配计数器,监控每个bin的分配次数,为超分配阈值的bin分配新的new bin降低高读写区域的磨损;延迟分配链表为重新分配的内存区域提供一个延迟时间。由此解决现有非易失存储器NVRAM在内存分配时存在的磨损均衡问题,以求提升NVRAM内存的使用寿命。
为实现上述目的,按照本发明的一个方面,提供了一种基于NVRAM的内存分配链表,该内存分配链表包括以下部分:
Fastbins,一个数组,用于记录所有fast bin链表,链表使用FIFO(先进先出)法进行链表中chunk的插入或删除;
Bins,一个数组,用于记录所有new bin、small bin和large bin链表,new bin和small bin链表采用FIFO法进行链表中chunk的插入或删除,每个new bin和small bin链表都设置一个计数器,记录各自的分配次数,当分配次数到达分配阈值k时,则向系统空闲内存空间申请一个新的new bin,用于存放新分配的chunk,new bin的大小Nnb为
Nnb=k×Nc,
其中,Nc为新分配chunk的大小;分配阈值k的取值范围为100<k<50000,优选k=4096;
延迟分配链表,用于保存刚被用户释放的fast chunk、small chunk和large chunk,链表使用FIFO法进行链表中chunk的插入或删除,每个新进入的chunk会被标记一个窗口,窗口初始大小为φ,φ的取值范围为1KB<φ<4096KB,优选φ=4KB;同时更新其他分配窗口的大小
Ni=Ni-δn,i=1,2,3,...,n-1,
其中,Ni表示第i个进入延迟分配链表的chunk的标记窗口的大小;δn是新进入延迟分配链表的chunk的大小;当N1<0时,将延迟分配链表中最先进入的chunk取出放回到其他空闲内存分配链表中以待下一次分配,同时更新所有chunk进入链表的顺序i=i-1。
进一步地,所述new bin中的chunk被用户释放后,若new bin的分配次数大于分配阈值,则释放new bin所占内存空间;否则不释放new bin所占内存空间,该chunk将被还回new bin中。
按照本发明的另一方面,提供了基于NVRAM的内存分配方法,该方法包括以下步骤:
(1)将用户请求内存空间的大小转换为实际需要分配的chunk空间大小;
(2)判断chunk空间大小是否小于64B,若是则进行步骤(3);否则进行步骤(4);
(3)在Fastbins中找到一个合适的chunk;分配完成,进入步骤(7);
(4)在Bins中找到一个合适的chunk;分配完成;
(5)判断chunk是否在small bin或large bin中,若是则进入步骤(7);否则进入下一步;
(6)用户释放chunk,判断new bin的分配次数是否大于分配阈值,是则释放new bin所占内存空间,结束;否则不释放new bin所在内存空间,结束;
(7)用户释放chunk,chunk进入延迟分配链表,结束。
进一步地,所述步骤(4)具体包括以下子步骤:
(41)根据chunk的大小在small bin和large bin中找到相应大小的bin,若在small bin中找到合适bin,则进入步骤(42);否则在large bin中找到合适的bin后分配结束;
(42)判断该bin的分配次数是否小于分配阈值k;若是则进入步骤(45);否则进入下一步;
(43)判断该chunk是否已有申请的new bin,是则回到步骤(42);否则进入下一步;
(44)申请一个新的new bin,若申请成功则new bin的大小Nnb=k×Nc,其中Nc为新分配chunk的大小,之后回到步骤(42);否则报错系统内存不足,结束分配;
(45)从该bin链表中选取一个chunk返回给用户,同时该bin的分配次数累加1,分配结束。
进一步地,所述步骤(7)具体包括以下子步骤:
(71)大小为δn的chunk被释放后进入延迟分配链表,延迟分配链表为其标记一个窗口,窗口初始大小为φ;
(72)更新延迟分配链表中其他chunk标记窗口的大小Ni=Ni-δn,i=1,2,3,...,n-1,其中i表示chunk进入延迟分配链表的顺序;
(73)判断N1<0是否成立,是则将延迟分配链表链表中最先进入的chunk取出放回到其他空闲内存分配链表中以待下一次分配,同时更新所有chunk进入链表的顺序i=i-1,结束;否则直接结束。
进一步地,分配阈值k的取值范围为100<k<50000,优选k=4096;延迟分配链表的标记窗口初始大小为φ,φ的取值范围为1KB<φ<4096KB,优选φ=4KB,
总体而言,通过本发明所构思的以上技术方案与现有技术相比,采用本发明技术方案可以有效的降低NVRAM内存的使用损耗,提高NVRAM内存使用寿命。
附图说明
图1为glibc malloc内存分配器中内存分配链表示意图;
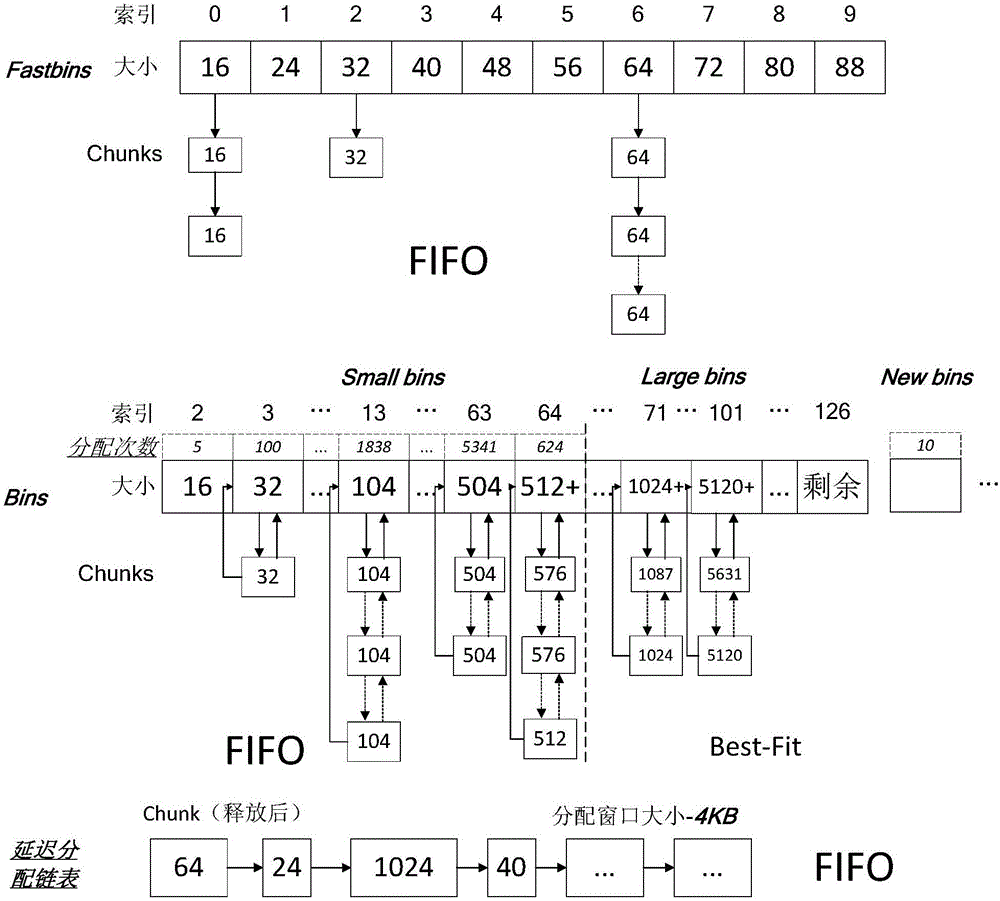
图2为本发明内存分配链表示意图;
图3为本发明方法总流程图;
图4为本发明方法在Bins中根据chunk大小寻找合适bin的方法流程图;
图5为本发明方法在chunk进入延迟分配链表的方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图2所示为本发明内存分配链实施例示意图,其中包括:
Fastbins,一个数组,用于记录所有fast bin链表,链表使用FIFO法进行链表中chunk的插入或删除;
Bins,一个数组,用于记录所有new bin、small bin和large bin链表,new bin和small bin链表采用FIFO法进行链表中chunk的插入或删除,每个new bin和small bin链表都设置一个计数器,记录各自的分配次数,考虑到现在以PCM为代表的NVRAM寿命普遍为107到108次写入,广泛使用的64位机器下int数据类型为32比特,232=4294967296,达到了109数量级,所以int数据类型完全够用。那么本方案额外引入的空间开销仅为:63×32bit=252B,是非常小的。
现在预先设定分配阈值k=4096,即当某个bin链表内大小为104B的chunks被分配了4096次之后,表明用户正在频繁申请大小为104B的chunks。那么为了避免对刚释放块的重用,此时就不再从空闲分配链表中获取大小为104B的chunk了,而是直接以4KB为单位向操作系统通过mmap()系统调用申请一块新的大小为104*4096/1024=416KB的内存区域,暂且命名为new bin1。然后将new bin1按chunk的大小进行划分,并将new bin1的分配阈值k也设置为4096,正好是划分后的可以供每个chunk分配一次。后续所有对大小为n的chunk的分配请求都将被new bin1处理而不是由空闲分配链表处理。一段时间后如果new bin1的分配次数也达到了分配阈值k,那么同样,先以4KB为单位向操作系统通过mmap()系统调用申请一块新的大小为416KB的内存区域,命名为new bin2,同样将new bin2按chunk的大小进行划分,并将new bin2的分配阈值k也设置为4096。以此类推。
值得注意的是,如果new bin1中的chunk被释放,将被还回new bin1而不是空闲分配链表中。另外,申请new bin2后new bin1所占用的内存区域才有可能被释放。如此确保了向操作系统申请的mmap()区域也不是刚释放回去的。
延迟分配链表,用于保存刚被用户释放的fast chunk、small chunk和large chunk,链表使用FIFO法进行链表中chunk的插入或删除,每个新进入的chunk会被标记一个窗口,现在假设预先定好的窗口大小φ=4KB,最近释放的3个chunk的大小分别为δ=64B、δ1=24B和δ2=1024B。当第一个chunk被释放时,它将首先进入延迟分配链表并将其窗口大小window_alloc初始化为φ=4KB;当第二个大小为δ1的chunk被释放进入该链表时,就将第一个chunk的窗口大小改为φ-δ1,同时将第二个大小为δ1的chunk的窗口大小也初始化为φ=4KB;当第三个大小为δ2的chunk进入链表时,将第一个chunk的窗口改为φ-δ1-δ2,第二个chunk的窗口改为φ-δ2,第三个大小为δ2的chunk的窗口大小初始化为φ=4KB。
在每次插入新的chunk之后,都进行对链表头的检查工作。如果链表头部的chunk的窗口大小在减去刚进入链表的chunk大小之后小于零,则将之从链表头部取出并放回到管理chunks的空闲分配链表中去以待下一次被分配。这样可以保证同一个chunk在分配φ大小的空间前不会再被使用到,有效避免了对刚释放块的重用。
值得注意的是,可以看出延迟分配链表总是会占用φ大小的空间,φ可以由系统管理人员设定以适应不同的负载均衡需求。当负载的磨损极其不均匀时(比如恶意攻击),φ可以适当设定地大一些,有助于实现更大地址空间的磨损均衡;当负载是相对典型的应用时,φ可以适当设定地小一些,减少系统调用的次数有助于提升应用分配的性能。
如图3所示本发明内存分配方法包括以下步骤:
(1)将用户请求内存空间的大小转换为实际需要分配的chunk空间大小;
(2)判断chunk空间大小是否小于64B,若是则进行步骤(3);否则进行步骤(4);
(3)在Fastbins中找到一个合适的chunk;分配完成,进入步骤(7);
(4)在Bins中找到一个合适的chunk;分配完成;
(5)判断chunk是否在small bin或large bin中,若是则进入步骤(7);否则进入下一步;
(6)用户释放chunk,判断new bin的分配次数是否大于分配阈值,是则释放new bin所占内存空间,结束;否则不释放new bin所在内存空间,结束;
(7)用户释放chunk,chunk进入延迟分配链表,结束。
如图4所示本发明步骤中步骤(4)包括以下子步骤:
(41)根据chunk的大小在small bin和large bin中找到相应大小的bin,若在small bin中找到合适bin,则进入步骤(42);否则在large bin中找到合适的bin后分配结束;
(42)判断该bin的分配次数是否小于分配阈值k;若是则进入步骤(45);否则进入下一步;
(43)判断该chunk是否已有申请的new bin,是则回到步骤(42);否则进入下一步;
(44)申请一个新的new bin,若申请成功则new bin的大小Nnb=k×Nc,其中Nc为新分配chunk的大小,之后回到步骤(42);否则报错系统内存不足,结束分配;
(45)从该bin链表中选取一个chunk返回给用户,同时该bin的分配次数累加1,分配结束。
如图5所示本发明步骤中步骤(7)包括以下子步骤:
(71)大小为δn的chunk被释放后进入延迟分配链表,延迟分配链表为其标记一个窗口,窗口初始大小为φ;
(72)更新延迟分配链表中其他chunk标记窗口的大小Ni=Ni-δn,i=1,2,3,...,n-1,其中i表示chunk进入延迟分配链表的顺序;
(73)判断N1<0是否成立,是则将延迟分配链表链表中最先进入的chunk取出放回到其他空闲内存分配链表中以待下一次分配,同时更新所有chunk进入链表的顺序i=i-1,结束;否则直接结束。
进一步地,分配阈值k的取值范围为100<k<50000,优选k=4096;延迟分配链表的标记窗口初始大小为φ,φ的取值范围为1KB<φ<4096KB,优选φ=4KB,
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!