一种实现高速缓存替换的方法及装置与流程
本发明涉及计算机领域,尤指一种实现高速缓存替换的方法及装置。
背景技术:
由于处理器和主存之间的性能差距越来越大,在高速缓存失效时处理器往往要等待较长时间。因此如何通过改进高速缓存的替换方法来提高高速缓存的性能成为了当前的一个重要课题。当前大部分高速缓存替换方法的主要目标是减少高速缓存的总失效数量,它们假设所有失效的代价都是相同的。但是在现代处理器中由于访存延迟可变,并且处理器使用多种访存延迟隐藏技术(如非阻塞高速缓存和预取),导致高速缓存的失效代价可变。因此只考虑减少总失效数量是不够的,高速缓存替换方法应该以减少高速缓存的整体失效代价作为设计的目标。
按照高速缓存的替换方法的目标,高速缓存替换方法可以分为面向失效数的和面向失效代价的两种:
面向失效数的高速缓存替换方法主要包括以下几种:1、动态插入策略(DIP)通过把局部性差的块的插入最近最少使用(Least Recently Used,LRU)位置来避免缓存的颠簸。2、再访问插入预测(Re-Reference Interval Prediction,RRIP)通过区分在缓存中被访问过的块和没被访问过的块,使得前者在高速缓存中停留的时间更长来改善性能。3、伪后进先出(Pseudo Last-In-First-Out)通过优先排出栈顶端的块,使得栈低端的块被保存的时间更长。4、基于签名的命中预测(Signature-based Hit Predictor,SHiP)通过预测块的重用距离来在RRIP的基础上改善性能。5、死亡块预测(Dead Block Prediction)技术通过预测一个块的最后一次访问来提高性能。基于预测的方法,死亡块预测技术可以分为基于踪迹的、基于时间的和基于计数器的。6、合并连续访问方法通过对连续的访问进行预测来提高准确率。7、基于采样的死亡块预测(Sampling Dead Block Prediction,SDBP)通过采样一部分访问来训练预测器,从而减少硬件开销和提高预测准确率。8、旁路方法通过预测并旁路那些在被排出之前没被使用的块来提高性能。根据预测的方法可以分为基于程序计数器(Program Counter,PC)的和基于地址的。9、较少再用过滤器(Less Reused Filter,LRF)通过既使用基于PC的又使用基于地址的预测器来提高性能。10、使用自适应旁路的分段替换(Dueling Segment replacement with adaptive Bypassing)在失效时记录进入块和排出块的对,通过比较它们被访问的顺序来决定旁路的使用概率。
面向失效代价的高速缓存替换方法主要包括:1、Jeong等人提出在访存时延变化时区分长失效代价和短失效代价,并用于辅助LRU算法来指导替换块选择。2、关键高速缓存(Critical Cache)和局部性感知和代价敏感型高速缓存替换(Locality-Aware Cost-Sensitive cache replacement)通过使用失效期间处理器发射的指令数来表示失效代价。3、存储并行性感知替换(MLP-aware replacement)用存储并行性代价(MLP cost)来表示由于处理器访存延迟隐藏能力造成的失效代价的差异,然后使用MLP cost来指导替换方法。
以上这些缓存替换的方法要么是针对失效数的,要么只关注失效代价,而只关注失效代价是不够的。在如下例子中,假设块A在被装入高速缓存时失效代价为200周期,并且块A只被访问一次,因此没有得到命中;而块B在被装入高速缓存时失效代价为50周期,然后块B得到了9次命中,每次命中时可以防止处理器停顿50周期。对于上述例子,保留B可以总共防止处理器停顿500周期,而保留A只能防止处理器停顿200周期,因此高速缓存应该优先保留B而不是A。但是如果只考虑失效代价,那么高速缓存将优先保留A而不是B。只考虑访问失效时的失效代价并不能对高速缓存的整个过程进行评价,影响高速缓存替换的高效合理进行。
技术实现要素:
为了解决上述技术问题,本发明提供一种实现高速缓存替换的方法及装置,能够针对高速缓存的不同的访问结果进行综合考虑,降低高速缓存替换对高速缓存的整体失效代价。
为了达到上述发明目的,本发明公开了一种实现高速缓存替换的方法,包括:获取对高速缓存的块的访问结果,当访问结果为访问失效时,移动访问失效所在组的所述高速缓存的块中收益值RBV最小的块,并将访问失效的块放置在访问失效所在组的RBV最小的块移动前所在的位置;对访问失效的块计算失效代价,将计算出的失效代价赋值给访问失效的块装入的位置对应的RBV;
当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,根据计算出的命中收益更新命中的块对应的RBV。
进一步地,根据计算出的命中收益更新命中的块对应的RBV为:
将计算出的命中收益进行规格化处理后累加到访问命中的块的RBV;
将计算出的失效代价赋值给访问失效的块装入的位置对应RBV为:将所述失效代价进行规格化处理后赋值给所述访问失效装入块的RBV。
进一步地,当对高速缓存的块访问失效时,该方法还包括:将所述访问失效所在组的所有高速缓存的块的RBV都分别减去所述RBV最小的块的RBV。
进一步地,当累加到访问命中的块的RBV超出其所能表示的最大值时,该方法还包括:
更新的命中的块对应的RBV为、访问命中的块的RBV所能表示的最大值。
进一步地,计算失效代价包括:计算所述访问失效对高速缓存带来的需要增加的处理时间。
进一步地,当同时存在并行的多个高速缓存的访问失效时,该方法还包括:将所述访问失效对高速缓存带来的需要增加的处理时间均分给并行的访问失效的块。
进一步地,计算命中收益包括:将所述访问命中假设为访问失效,获得由该假设的访问失效对高速缓存带来的需要增加的处理时间作为命中收益。
进一步地,获得由该假设的失效对高速缓存带来的需要增加的处理时间作为命中收益包括:计算平均缓存延迟与当前正在处理的失效数加1后的商,将该商值作为所述命中收益。
进一步地,规格化处理为:预先设置不大于RBV最大值的一数值作为线性规格参数,将失效代价与线性规格参数相乘后除以最大缓存延迟。
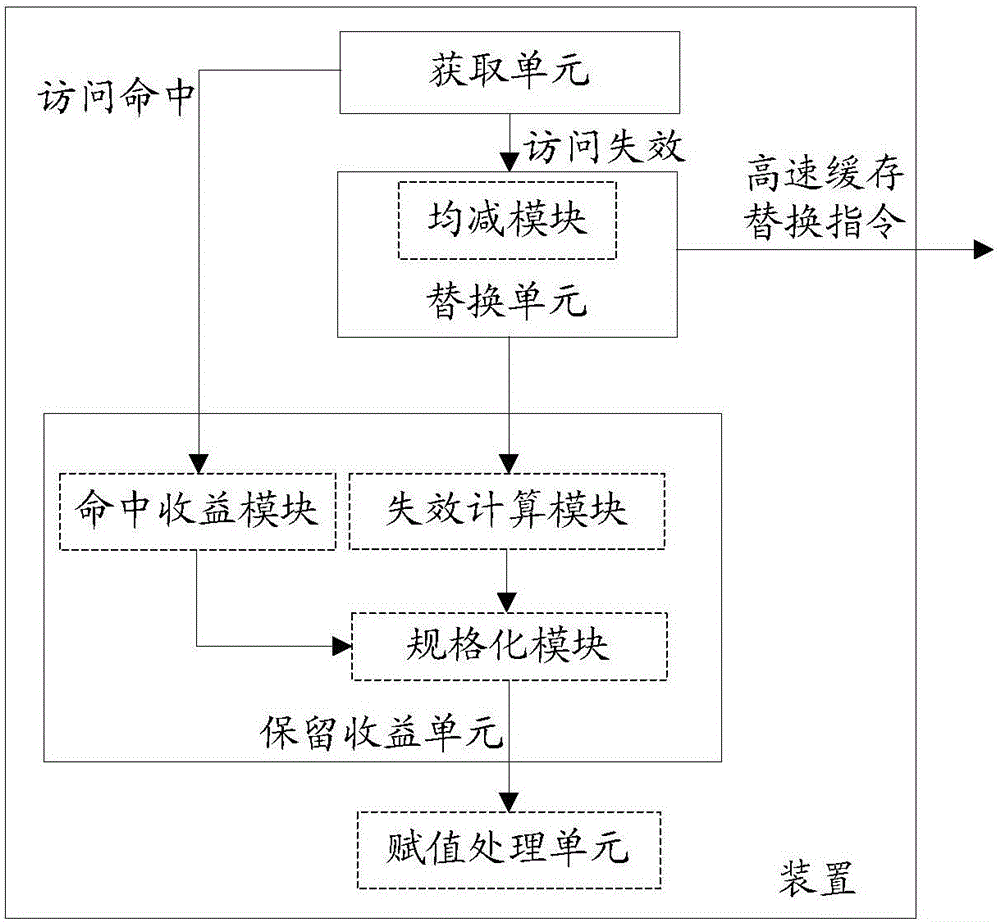
另一方面,本申请还提供一种实现高速缓存替换的装置,包括:获取单元、替换单元和保留收益单元;其中,
获取单元,用于获取对高速缓存的块的访问结果;
替换单元,用于当访问结果为访问失效时,移动访问失效所在组的所述高速缓存的块中收益值RBV最小的块,并将访问失效的块放置在访问失效所在组的RBV最小的块移动前所在的位置;
保留收益单元,用于当访问结果为访问失效时,对访问失效的块计算失效代价,将计算出的失效代价赋值给访问失效的块装入的位置对应的RBV;当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,根据计算出的命中收益更新命中的块对应的RBV。
进一步地,保留收益单元具体用于,
当访问结果为访问失效时,对访问失效的块计算失效代价,将所述失效代价进行规格化处理后赋值给所述访问失效装入块的RBV;
当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,将所述计算出的命中收益进行规格化处理后累加到访问命中的块的RBV。
进一步地,替换单元还包括均减模块,用于当对高速缓存的块访问失效时,将访问失效所在组的所有高速缓存的块的RBV分别减去所述RBV最小的块的RBV。
进一步地,该装置还包括赋值处理单元,用于当累加到访问命中的块的RBV超出其所能表示的最大值时,赋值给更新的命中的块对应的RBV为、访问命中的块的RBV所能表示的最大值。
进一步地,保留收益单元包括失效计算模块,用于计算所述访问失效对高速缓存带来的需要增加的处理时间。
进一步地,失效计算模块还用于,当同时存在并行的多个高速缓存的访问失效时,将访问失效对高速缓存带来的需要增加的处理时间均分给并行的访问失效的块。
进一步地,保留收益单元还包含命中收益模块,用于将所述访问命中假设为访问失效,获得由该假设的访问失效对高速缓存带来的需要增加的处理时间作为命中收益。
进一步地,命中收益模块具体用于,将所述访问结果由访问命中假设为访问失效,计算平均缓存延迟与当前正在处理的失效数加1的商,将该商值作为所述命中收益。
进一步地,保留收益单元还包括规格化模块,用于预先设置不大于RBV最大值的一数值作为线性规格参数,将失效代价与线性规格参数相乘后除以最大缓存延迟,完成规格化处理。
本申请技术方案包括:获取对高速缓存的块的访问结果,当访问结果为访问失效时,移动访问失效所在组的高速缓存的块中收益值(RBV)最小的块,并将访问失效的块放置在访问失效所在组的RBV最小的块移动前所在的位置;对访问失效的块计算失效代价,将计算出的失效代价赋值给访问失效的块装入的位置对应的RBV;当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,根据计算出的命中收益更新命中的块对应的RBV。本发明通过对高速缓存替换的访问结果进行命中收益或失效代价计算,通过处理后,对访问命中及失效的块赋值相应的RBV,通过保留收益值,对高速缓存的整体失效代价进行相应的评估,从而实现高速缓存替换的合理高效。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实现高速缓存替换的方法的流程图;
图2为本发明实现高速缓存替换的装置的结构框图;
图3为本发明实现高速缓存替换的实施例示意图。
具体实施方式
图1为本发明实现高速缓存替换的方法的流程图,如图1所示,包括:
步骤100、获取对高速缓存的块的访问结果,当对高速缓存的块访问失效时,执行步骤1020;当对高速缓存的块访问命中时,执行步骤1030;
步骤1020、移动访问失效所在组的所述高速缓存的块中收益值(RBV)最小的块,并将访问失效的块放置在访问失效所在组的RBV最小的块移动前所在的位置;对访问失效的块计算失效代价,将计算出的失效代价赋值给访问失效的块装入的位置对应的RBV。
本步骤中,将计算出的失效代价赋值给访问失效的块装入的位置对应RBV为:将所述失效代价进行规格化后赋值给所述访问失效装入块的RBV。
步骤1030、当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,根据计算出的命中收益更新命中的块对应的RBV。
本步骤中,根据计算出的命中收益更新命中的块对应的RBV为:
将所述计算出的命中收益进行规格化处理后累加到访问命中的块的RBV
需要说明的是,对于高速缓存的访问命中时,直接按照现有的命中处理方法进行运行,本发明只是增加了对命中收益的计算机命中收益的保留收益值的计算。
当对高速缓存的块访问失效时,本发明方法还包括:将访问失效所在组的所有高速缓存的块的RBV分别减去RBV最小的块的RBV。
当累加到访问命中的块的RBV超出其所能表示的最大值时,本发明方法还包括:更新的命中的块对应的RBV为、访问命中的块的RBV所能表示的最大值。
需要说明的是,通过将访问失效所在组的所有块的RBV都减去RBV最小块的RBV,可以避免高速缓存的保留收益值溢出。当累加到访问命中的块的RBV超出其所能表示的最大值时,只赋值给命中的块RBV所能表示的最大值,依旧可以对高速缓存的块的失效代价进行比较。
计算失效代价包括:计算访问失效对高速缓存带来的需要增加的处理时间。
进一步地当同时存在并行的多个高速缓存的访问失效时,本发明方法还包括:将访问失效对高速缓存带来的需要增加的处理时间均分给并行的访问失效的块。
计算命中收益包括:将访问命中假设为访问失效,获得由该假设的访问失效对高速缓存带来的需要增加的处理时间作为命中收益。
进一步地,获得由该假设的失效对高速缓存带来的需要增加的处理时间作为命中收益包括:计算平均缓存延迟与当前正在处理的失效数加1后的商,将该商值作为所述命中收益。
需要说明的是平均缓存延迟为现有高速缓存替换统计出来的经验值。
规格化处理为:预先设置不大于RBV最大值的一数值作为线性规格参数,将失效代价与线性规格参数相乘后除以最大缓存延迟。
需要说明的是,线性规格参数是预先设置的定值,在设置完成后进行RBV数值计算,而RBV的最大值由寄存器的位数进行确定,根据实际情况可以对寄存器的位数进行合理的设定,假设是3位,则其最大值为7,则可以设定线性规格参数为1~7的任意参数,一般的选择4作为线性规格参数。
本发明通过对高速缓存替换的访问结果进行相应的收益计算,通过处理后,赋值给相应的高速缓存块中,通过保留收益值,对高速缓存的整体失效代价进行相应的评估,从而实现高速缓存替换的合理高效。
图2为本发明实现高速缓存替换的装置的结构框图,如图2所示,包括:获取单元、替换单元和保留收益单元;其中,
获取单元,用于获取对高速缓存的块的访问结果;
替换单元,用于当访问结果为访问失效时,移动访问失效所在组的所述高速缓存的块中收益值RBV最小的块,并将访问失效的块放置在访问失效所在组的RBV最小的块移动前所在的位置;
保留收益单元,用于当访问结果为访问失效时,对访问失效的块计算失效代价,将计算出的失效代价赋值给访问失效的块装入的位置对应的RBV;当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,根据计算出的命中收益更新命中的块对应的RBV。
保留收益单元具体用于,
当访问结果为访问失效时,对访问失效的块计算失效代价,将所述失效代价进行规格化处理后赋值给所述访问失效装入块的RBV;
当访问结果为访问命中时,对高速缓存的访问命中的块计算命中收益,将所述计算出的命中收益进行规格化处理后累加到访问命中的块的RBV。
替换单元还包括均减模块,用于当对高速缓存的块访问失效时,将访问失效所在组的所有高速缓存的块的RBV分别减去所述RBV最小的块的RBV。
本发明装置还包括赋值处理单元,用于当累加到访问命中的块的RBV超出其所能表示的最大值时,赋值给更新的命中的块对应的RBV为、访问命中的块的RBV所能表示的最大值。
保留收益单元包含失效计算模块,用于计算访问失效对高速缓存带来的需要增加的处理时间。
需要说明的是,为了实现计算访问失效对高速缓存带来的需要增加的处理时间,在高速缓存失效状态保存器MSHR会拓展出一个寄存器,用于失效代价的计算,本领域技术人员还应该能理解,在失效请求开始时,初始化寄存器为零。
失效计算模块还用于,当同时存在并行的多个高速缓存的访问失效时,将访问失效对高速缓存带来的需要增加的处理时间均分给并行的访问失效的块。
保留收益单元还包含命中收益模块,用于将访问命中假设为访问失效,获得由该假设的访问失效对高速缓存带来的需要增加的处理时间作为命中收益。
命中收益模块具体用于,将访问结果由访问命中假设为访问失效,计算平均缓存延迟与当前正在处理的失效数加1的商,将该商值作为所述命中收益。
保留收益单元还包括规格化模块,替换赋值单元还包括规格化模块,用于预先设置不大于RBV最大值的一数值作为线性规格参数,将失效代价与线性规格参数相乘后除以最大缓存延迟,完成规格化处理。
以下结合具体实施例,对本发明方法进行更为详尽的说明,实施例只为更为清楚的陈述,并不用于限制本发明的保护范围。
实施例1
图3为本发明实施例进行高速缓存替换的3个应用处理过程。图中A、B、C、D和E表示高速缓存的块,假设高速缓存为4路组相联结构,因此每组包含4个块,每个块右侧的数字为本发明方法失效状态保存寄存器扩展的计算失效代价的位,用于表示该块的RBV的数值,假设RBV为3位,因此RBV的范围是0到7,假设访问E的访问请求的失效代价规格化处理后为4,访问B的请求的命中收益规格化后也为4。
在第一个访问E的高速缓存替换应用处理过程中,当前访问块E失效;
选择保留收益值RBV最小的块换出高速缓存,因为块A的RBV最小为0,因此选择A作为换出高速缓存的块。因为RBV的最小值为0,所以A所在的访问失效所在组的其他块的RBV做减零处理。
把高速缓存块E装入高速缓存块A的位置,并把E的RBV初始化为它的失效代价4。
在第二个访问E的高速缓存替换应用处理过程中,当前访问块E失效;
选择保留收益值RBV最小的块换出高速缓存,因块C的RBV最小,为1,因此选择C作为换出高速缓存的块。同时高速缓存访问失效所在组的其他块,即高速缓存的块A、B、D的RBV都减去最小的RBV值1。最后把E装入C的位置,并把E的RBV初始化为它的失效代价4。
在第三个访问B的高速缓存替换应用处理过程中,当前访问块B命中。这时把规格化后的命中收益累加到B的RBV上,因此B的RBV由3变为7。由于7没有超过RBV的表示的最大值范围,因此不需进行赋值处理。
虽然本申请所揭露的实施方式如上,但所述的内容仅为便于理解本申请而采用的实施方式,并非用以限定本申请。任何本申请所属领域内的技术人员,在不脱离本申请所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本申请的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!