一种基于搜索引擎的检索信息匹配方法及装置与流程
本发明涉及互联网
技术领域:
,尤其涉及一种基于搜索引擎的检索信息匹配方法及装置。
背景技术:
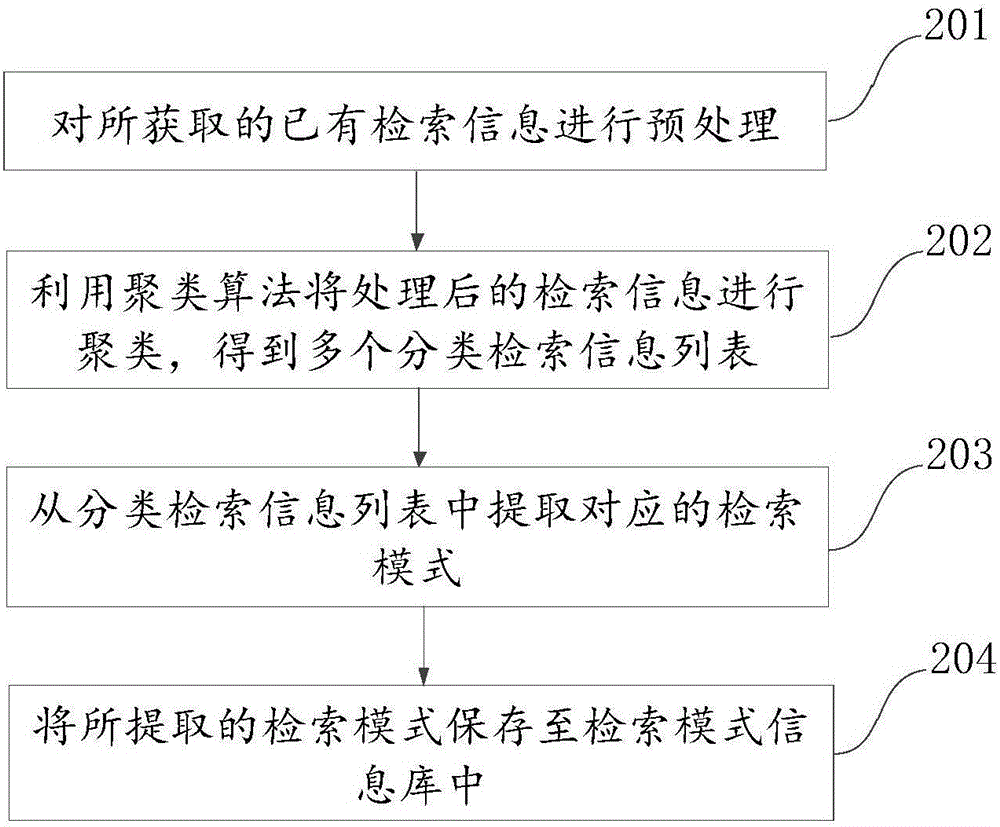
:随着互联网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找自己所需的信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题。搜索引擎是指互联网上专门提供检索服务的一类网站,这些站点的服务器通过网络搜索软件或网络登录等方式,将Intenet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库,从而对用户提出的各种检索作出响应,提供用户所需的信息或相关指针。用户的检索途径主要包括自由词全文检索、关键词检索、分类检索及其他特殊信息的检索。然而,当用户存在对某一类信息进行检索的需求时,一般是通过对同类或近似的关键词进行多次检索,分别得到所需的检索结果,或者是通过构建上位概括的检索信息实现,但是这种用户自建的检索信息对用户的概括能力要求较高,否则很难得到用户想要的检索结果。可见,目前对于一类信息的检索需求缺少操作简单,匹配准确的实现方式。技术实现要素:有鉴于此,本发明提供一种基于搜索引擎的检索信息匹配方法及装置,通过构建检索模式匹配用户提出的检索信息,为用户提供更加全面的与所述检索信息向匹配的检索结果。依据本发明的一个方面,提出了一种基于搜索引擎的检索信息匹配方法,该方法包括:创建检索模式信息库,所述检索模式是对已有检索信息统计分析得到的能够代表一类检索信息的模式化信息;将网页的标题以及搜索引擎获取的新检索信息分别与所述信息库中的检索模式进行匹配;当匹配出的检索模式的相似度达到阈值时,将所述网页作为所述新检索信息的检索结果输出。依据本发明的另一个方面,提出了一种基于搜索引擎的检索信息匹配装置,该装置包括:创建单元,用于创建检索模式信息库,所述检索模式是对已有检索信息统计分析得到的能够代表一类检索信息的模式化信息;匹配单元,用于将网页的标题以及搜索引擎获取的新检索信息分别与所述创建单元创建的信息库中的检索模式进行匹配;输出单元,用于当所述匹配单元匹配出的检索模式的相似度达到阈值时,将所述网页作为所述新检索信息的检索结果输出。本发明所采用的一种基于搜索引擎的检索信息匹配方法及装置,通过为搜索引擎配置检索模式信息库,将用户录入的检索信息与信息库中的检索模式进行匹配,实现解析用户的检索意图,将用户的检索内容扩展到一类信息的查询与检索。同时,通过信息库中的检索模式,也为互联网中的网页匹配对应的检索模式,在为用户匹配对应的检索结果时,通过计算用户录入的检索模式与网页对应检索模式的相似度来判断网页是否符合用户的检索意图,从而确定是否将该网页作为检索结果输出给用户。此外,本发明通过对检索模式的不断的更新与训练,可以有效提高对用户检索意图的识别与判断,从而为用户匹配出更为准确的检索结果,提高用户的检索体验。上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。附图说明通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:图1示出了本发明实施例提出的一种基于搜索引擎的检索信息匹配方法流程图;图2示出了本发明实施例提出的另一种基于搜索引擎的检索信息匹配方法流程图;图3示出了本发明实施例提出的一种基于搜索引擎的检索信息匹配装置的组成框图;图4示出了本发明实施例提出的另一种基于搜索引擎的检索信息匹配装置的组成框图。具体实施方式下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。本发明实施例提供了一种基于搜索引擎的检索信息匹配方法,该方法主要应用搜索引擎中,针对用户的对某一类信息检索的需求,以检索模式为关联纽带匹配出相关性较高的网页作为检索结果,其具体步骤如图1所示,包括:101、创建检索模式信息库。其中,检索模式是对已有的检索信息进行统计分析后得到的能够代表一类检索信息的模式化信息。由于搜索引擎中保存有用户的检索日志,累积了海量的用户历史检索信息,通过对这些检索信息进行有效的挖掘,就可以得到本步骤的检索模式信息库中的检索模式。因此,创建检索模式也是本发明实施例中的核心步骤。检索模式信息库中的检索模式是通过对搜索引擎中保存的用户历史检索信息的分析所得到的,具体的,检索模式信息库的创建可以分为如下的几个步骤:第一,对所获取的已有检索信息进行预处理。通过获取搜索引擎中保存的用户历史检索信息并对其进行整理,以便于后续步骤的文本分析。其中,预处理主要包括对检索信息逐条地进行分词,词性标注,以及对各个分词进行向量化表示等。经过处理后的检索信息是以词向量表示的检索信息。通过词向量的表示,可以实现分词之间相关或相似的计算,比如,通过欧氏距离来衡量分词之间的远近,或者是通过余弦相似度计算两个分词之间的相关性。第二,利用聚类算法将处理后的检索信息进行聚类,得到多个分类检索信息列表。该步骤是将对向量化的检索信息进行聚类,也就是将可能含有相似检索模式的检索信息聚合在一起。进行聚类操作的前提,是出于对检索模式在同类检索信息中具有共性的认知,一般的,同义词、近义词或同位词的上下文信息是相似的,而在用户检索信息中的上下文信息就包含有所要挖掘的检索模式,由于检索模式一般是通过词向量表示的形式加以保存,那么,相反的,通过分析检索信息的词向量表示,就可以总结出对应的检索模式。因此,本步骤中的核心就是如何将具有相似的上下文信息的检索信息聚类到一起。一般的,检索信息都比较短小,因此,绝大所述的检索信息中都是以名词性词项为核心,围绕该词就基本可以确定检索信息中的上下文关系。所以,本发明实施例中,通过提取检索信息中的名词性词项,来分析这些词项的语义关系,即判断哪些名词性分词具有同义词、近义词或同位词的关系,将含有该关系分词的检索信息聚类到一起,再分析其中所具有的相似的上下文关系,即检索模式。第三,从分类检索信息列表中提取对应的检索模式。上一步是将已有的检索信息通过聚类算法分为多个分类检索信息列表,每一个分类检索信息列表中存储有一类的检索信息。一般的,认为这一类的检索信息中会包含有同一类的检索模式,也就是根据检索信息中的非名词性分词的排序方式,来确定对应的检索模式。而在确定出的检索模式中含有的名词性分词的数量决定了该检索模式的阶数,阶数越高,说明用户检索的一类信息的关联计算的维度也就越大,对应得到的检索结果也就可能越满足用户的检索意图,从而提高检索准确性。第四,将所提取的检索模式保存至检索模式信息库中。该步骤是将所有从分类检索信息列表中提取出的检索模式统一保存在一个信息数据库中,得到检索模式信息库。需要指出的是,所创建的检索模式信息库是基于搜索引擎保存的已有的检索信息。而随着搜索引擎的应用,还会有大量的检索信息被记录下来,因此,对于检索模式信息库中的检索模式也需要不断的更新,以保证检索模式与用户的录入检索信息的语言方式相匹配,从而保证检索结果的准确性。而对于检索模式的具体更新方式,本发明实施例则不限定采用实时更新或定期更新的方式。102、将网页的标题以及搜索引擎获取的新检索信息分别与信息库中的检索模式进行匹配。本步骤主要执行的是两个操作,即为网页的标题匹配检索模式,和为用户录入的检索信息匹配检索模式。对于为网页的标题匹配检索模式,是在建立检索模式信息库时,或者是对检索模式信息库中的检索模式进行更新后,将搜索引擎所能够检索到的网页进行网页标题的匹配,为其匹配对应的检索模式。而对于为用户录入的检索信息匹配检索模式,则是在检测到有用户使用搜索引擎进行检索,并且录入了检索信息后,搜索引擎将为该检索信息匹配对应的检索模式。具体的,匹配检索模式的过程是提取检索模式的一个逆过程,即对检索信息或网页标题进行分词、向量化等处理,通过提取其中的名词性分词可以确定出检索模式的分类,而通过其非名词性分词的排序与内容就可以进一步的匹配对应的检索模式。103、当匹配出的检索模式的相似度达到阈值时,将对应的网页作为新检索信息的检索结果输出。本步骤是在搜索引擎为用户的检索信息匹配出对应的检索模式后,将根据该检索模式匹配对应的网页,由于每个网页存在有对应的检索模式,即通过网页标题所匹配的检索模式。其中,匹配网页的过程可以通过计算检索模式之间的相似度来实现。而对于相似度计算的具体的方式,本发明实施例则不做限定。根据上述步骤中所创建的检索模式可以确定,检索模式在本发明实施例中是以词向量的形式表示的,因此,优选的相似度计算可采用向量空间模型计算,该模型也是应用最广泛的一个基础相似度计算模型,例如,欧式距离,余弦相似度等计算模型。通过相似度计算,将相似度达到某一阈值的网页确定为该用户录入检索信息的检索结果,并加以输出显示。其中,用于判断的阈值一般是可以自定义设置的经验值,根据实际情况的需要可以调整阈值的大小。阈值大,则对应的检索结果的数量将变少,反之,检索的结果将增多。进一步的,在输出显示网页结果时,还可以根据所计算的相似度的值对网页的显示进行排序,相似度越高,排名也越靠前。上述本发明实施例提供的一种基于搜索引擎的检索信息匹配方法,通过为搜索引擎配置检索模式信息库,将用户录入的检索信息与信息库中的检索模式进行匹配,实现解析用户的检索意图,将用户的检索内容扩展到一类信息的查询与检索。同时,通过信息库中的检索模式,也为互联网中的网页匹配对应的检索模式,在为用户匹配对应的检索结果时,通过计算用户录入的检索模式与网页对应检索模式的相似度来判断网页是否符合用户的检索意图,从而确定是否将该网页作为检索结果输出给用户。此外,本发明实施例通过对检索模式的不断的更新与训练,可以有效提高对用户检索意图的识别与判断,从而为用户匹配出更为准确的检索结果,提高用户的检索体验。进一步的,为了更加详细的说明上述的基于搜索引擎的检索信息匹配方法在实际应用中的具体实现,特别是对检索模式信息库中如何构建检索模式,以下实施例中将进行详细说明,具体如图2所示,包括:201、对所获取的已有检索信息进行预处理。本步骤中,对于检索信息的预处理主要是对所保存的已有检索信息进行的自然语言处理,其中,主要包括如下环节:首先,将所获取的已有检索信息逐条添加到有第一检索信息列表中。在该第一检索信息列表中,每一行记录有一条检索信息,例如,表中的一行为“从霍山到英山有多远”。而这些检索信息都是搜索引擎记录的用户曾经检索过的检索信息。将该第一检索信息列表以文件的形式加以保存。需要说明的是,在向第一检索信息列表中添加检索信息时,不需要对检索信息进行去重处理。其次,对第一检索信息列表中的检索信息进行分词以及词性标注处理,从而得到第二检索信息列表和第三检索信息列表。其中,将分词后的检索信息保存在第二检索信息列表中,将对分词标注有词性信息的检索信息保存在第三检索信息列表中。也就是说,第二检索信息列表所保存的检索信息与第一检索信息列表中相对应,而区别在于第二检索信息列表中的检索信息进行了分词处理,例如,在该表中的一行检索信息为“从霍山到英山有多远”。与此向类似的,第三检索信息列表中的检索信息是在第二检索信息列表中的内容基础上进行的词性标注,每行中记载了检索信息和词性标注的分词结果,例如,在该表中的一行检索信息为“从霍山到英山有多远从:p霍山:ns到:p英山:ns有:v多:m远:a”。下表示出了部分词性标注的对照表:表1:部分词性标注对照表第三,利用文本深度表示模型word2vec对第二检索信息列表中的分词进行向量化表示,将向量化的分词存储在词向量文件中。其中,文本深度表示模型word2vec是Google在2013年年中开源的一款将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。Word2vec输出的词向量可以被用来做很多NLP(Neuro-LinguisticProgramming,神经语言程序学)相关的工作,比如聚类、找同义词、词性分析等。在使用word2vec对第二检索信息列表中的分词进行向量化表示时,该模型的中的K维向量空间可根据实际需要进行自定义设置,例如,设置K的值为300是,对应的word2vec的参数为“-cbow1-size300-window8-negative25-hs0-sample1e-4-threads24-binary0-iter15”。经过文本深度表示模型word2vec的处理后,第二检索信息列表中的分词以词向量的形式加以表示。同时,将这些分词的词向量保存在一个词向量文件中。第四,提取第三检索信息列表中词性标注为名词性的分词,并将该分词添加到分词列表中。其中,分词列表中记录有分词以及所述分词在第三检索信息列表中出现的次数。例如,分词列表中的一行显示为:“霍山”,有180万行。此外,具有名词性的词性标注主要包括:n、nd、nh、nl、ns、nt、nz、b、i、j,具体的对照请参照上述的表1。通过上述的预处理环节后,可以将所获取的已有检索信息处理为第一检索信息列表、第二检索信息列表、第三检索信息列表和分词列表,以及词向量文件。202、利用聚类算法将处理后的检索信息进行聚类,得到多个分类检索信息列表。本步骤中所执行的聚类操作是创建检索模式的核心步骤,其执行过程主要是获取检索信息中的名词性分词,再根据文本深度表示模型word2vec中的欧氏距离,选择这些词分词的邻近分词,并将含有这些分词或邻近分词的检索信息聚类到一起,得到一个分类检索信息列表。对此,具体的实现需要基于上述步骤中对检索信息进行的预处理结果,其详细步骤包括:1、在词向量文件中查找分词列表中分词的向量值。其中,所查找的分词是对分词列表中的每一个分词逐一地进行提取。2、根据向量值计算分词列表中任意两个分词间的欧氏距离。通过该步骤的计算就可以得到所提取的分词与该分词列表中其他分词的欧氏距离值。其中,欧氏距离是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。而关于具体的欧氏距离的计算过程本发明实施例不进行具体说明。3、对分词列表中每个分词提取预置数量的邻近分词,组成分词组。其中,邻近分词是指根据欧氏距离计算后,按照由近至远的排序选择的一组距离最近的分词。而预置数量的大小决定了分类检索信息列表中所含有的检索信息的具体数量,数量的大小又会影响到所提取的检索模式,因此,该预置数量的设定往往需要根据实际检索信息的数量而确定,一般为经验值。以上文中的“霍山”为例,与其欧氏距离较近的分词多为县级行政单位,如下表:表2:霍山的近邻词项,根据word2vec的欧氏距离排序此外,需要指出的是,所得到的分词组是对分词列表中的所有分词进行的分配。也就是说,一个分词经过分配后只出现在一个分词组中。4、在第一检索信息列表中提取含有分词组中至少一个分词的检索信息。根据得到的分词组,遍历第一检索信息列表中的所有检索信息,将含有该分词组中至少一个分词的检索信息进行复制并提取出来。5、将提取的检索信息保存在一个分类检索信息列表中。执行该步骤后得到的分类检索信息列表中记录有一批具有相似上下文的检索信息,如下表所示:表3:一个分类检索信息列表中的部分检索信息内容从青岛到徐州有多远从河南周口到北京有多远从海口到泰州有多远从烟台到鞍山有多远从砀山到蒙城有多远从太康到夏邑有多远从柘城到夏邑有多远从霍山到英山有多远从集宁市到兴和县有多远需要指出的是,通过一组分词将得到对应的一个分类检索信息列表,通过对不同的分词组在第一检索信息列表中提取对应的检索信息,就会生成多个分类检索信息列表。203、从分类检索信息列表中提取对应的检索模式。根据上述步骤202中得到的多个分类检索信息列表,本发明实施例中提取检索模式的具体流程为:1、通过FPGrowth算法逐一计算每个分类检索信息列表中的频繁项集合。FPGrowth算法是韩家炜等人在2000年提出的关联分析算法,它采取如下的分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。FPGrowth算法主要分为两个步骤:FP-tree构建、递归挖掘FP-tree。FP-tree构建通过两次数据扫描,将原始数据中的事务压缩到一个FP-tree树,该FP-tree类似于前缀树,相同前缀的路径可以共用,从而达到压缩数据的目的。接着通过FP-tree找出每个项目的条件模式基、条件FP-tree,递归的挖掘条件FP-tree得到所有的频繁项集。对于具体的计算过程在本发明实施例中做详细说明。在该步骤中,由于每个分类检索信息列表中各条检索信息中的名词性分词都是同义词、近义词或同位词等具有较高关联关系的分词,因此,检索信息具有相似的上下文,所对应提取的检索模式也属于同一类的检索模式。也就是说,针对一个分类检索信息列表计算出的频繁项集可能存在多个,对此,将得到的频繁项集以列表的形式加以保存,就得到了频繁项集合,该集合中包含有多个频繁项集,以及每个频繁项集多出现的频数。下表示例性地展示了一个分类检索信息列表经过计算后得到的部分频繁项集。表4:频繁项集合中的部分频繁项集频繁项集频数有、和、不同1110到、坐、车、从、去196到、从、远、多、有29232、调整频繁项集中频繁项的顺序,生成分类检索信息列表对应的检索模式。首先,由于FPGrowth算法所产生的频繁项集中的频繁项是无序的,因此,需要将无序的频繁项转换成有序的频繁项,一个有序的频繁项集就是一个检索模式。具体的顺序转换过程包括:提取频繁项集中的一组频繁项,将这组频繁项代入分类检索信息列表中进行匹配,提取含有这一组频繁项的检索信息。需要指出的是,该检索信息中需要包含这组频繁项中的所有频繁项。之后,将所提取的检索信息中使用通用符替换所有非频繁项的分词,将含有通用符和这组频繁项的信息确定为分类检索信息列表所对应的检索模式,其中,含有通用符和这组频繁项的信息中的分词顺序是按照原检索信息中分词的顺序排列的。例如,设定通用符为“#”,频繁集“到、从、远、多、有”,进过匹配后得到的原始检索信息之一是“从霍山到英山有多远”,经过替换后生成的一个检索模式“从#到#有多远”,如果还匹配到另一个检索信息为“坐车从霍山到英山有多远”,经过替换后生成的另一个检索模式“#从#到#有多远”。可见,一个频繁项集中根据频繁项排序的不同就可以生成多个不同的检索模式。其次,当一个频繁项集中产生过个不同的检索模式时,为了确保检索模式的代表性,在得到所有的检索模式后,将对所有的检索模式进行统计,将相同的检索模式进行合并,并累加合并的个数。根据预设的阈值,保留累加个数大于该阈值的检索模式,确定这些检索模式为有效、可用的检索模式。204、将所提取的检索模式保存至检索模式信息库中。统计各个分类检索信息列表对应的检索模式,将其保存在检索模式信息库中,得到的检索模式以列表的形式加以展示,每个检索模式根据所替换的通用符的个数确定检索模式的阶数,下表示例性的展示了部分的检索模式,该表中的检索模式根据阶数的递增进行排序展示:表5:检索模式信息库中的部分检索模式通过上述实施例可以得到较高质量的检索模式,利用这些检索模式,搜索引擎变可以对网页标题以及用户录入的检索信息进行匹配,从而为用户检索出更符合用户意图的检索结果,简化了用户构建检索信息的复杂性,提高的用户的检索体验。以上详细说明了基于搜索引擎的检索信息匹配方法在实际应用中的具体实现,作为实现上述方法的具体装置,本发明实施例还提供了一种基于搜索引擎的检索信息匹配装置,如图3所示,该装置包括:创建单元31,用于创建检索模式信息库,所述检索模式是对已有检索信息统计分析得到的能够代表一类检索信息的模式化信息;匹配单元32,用于将网页的标题以及搜索引擎获取的新检索信息分别与所述创建单元31创建的信息库中的检索模式进行匹配;输出单元33,用于当所述匹配单元32匹配出的检索模式的相似度达到阈值时,将所述网页作为所述新检索信息的检索结果输出。进一步的,如图4所示,所述创建单元31包括:处理模块311,用于对所获取的已有检索信息进行预处理,得到词向量表示的检索信息;聚类模块312,用于利用聚类算法将所述处理模块311处理后的检索信息进行聚类,得到多个分类检索信息列表,所述分类检索信息列表中记录有相似上下文信息的检索信息;提取模块313,用于从所述聚类模块312得到的分类检索信息列表中提取对应的检索模式;存储模块314,用于将所述提取模块313得到的检索模式保存至检索模式信息库中。进一步的,如图4所示,所述处理模块311包括:第一处理子模块3111,用于将所获取的已有检索信息逐条添加到有第一检索信息列表中;第二处理子模块3112,用于对所述第一处理子模块3111得到的第一检索信息列表中的检索信息进行分词以及词性标注处理,得到第二检索信息列表和第三检索信息列表,所述第二检索信息列表中保存有分词后的检索信息,所述第三检索信息列表中保存有对分词结果进行词性标注的检索信息;第三处理子模块3113,用于利用文本深度表示模型word2vec对所述第二处理子模块3112得到的第二检索信息列表中的分词进行向量化表示,将所述向量化的分词存储在词向量文件中;第四处理子模块3114,用于提取所述第二处理子模块3112得到的第三检索信息列表中词性标注为名词性的分词,将所述分词添加到分词列表中,所述分词列表中记录有分词以及所述分词在所述第三检索信息列表中出现的次数。进一步的,如图4所示,所述聚类模块312包括:查找子模块3121,用于在所述词向量文件中查找所述分词列表中分词的向量值;计算子模块3122,用于根据所述查找子模块3121查询到的向量值计算所述分词列表中任意两个分词间的欧氏距离;组合子模块3123,用于对所述分词列表中每个分词提取预置数量的邻近分词,组成分词组,所述邻近分词是根据所述计算子模块3122计算的欧氏距离进行由近至远排序得到的分词;提取子模块3124,用于在所述第一检索信息列表中提取含有所述组合子模块3123组成的分词组中至少一个分词的检索信息;存储子模块3125,用于将所述提取子模块3124提取的检索信息保存在一个分类检索信息列表中。进一步的,如图4所示,所述提取模块313包括:计算子模块3131,用于利用FPGrowth算法逐一计算每个分类检索信息列表中的频繁项集合,所述频繁项集合含有至少一个频繁项集;生成子模块3132,用于调整所述计算子模块3131得到的频繁项集中频繁项的顺序,生成所述分类检索信息列表对应的检索模式。进一步的,所述生成子模块3132还用于,提取所述频繁项集中的一组频繁项;在所述分类检索信息列表中匹配含有所述一组频繁项的检索信息;将所述检索信息中非频繁项的分词替换为通用符;将含有通用符和所述一组频繁项且按照所述检索信息中的分词排序排列的信息确定为所述分类检索信息列表对应的检索模式。进一步的,所述生成子模块3132还用于,统计所生成的检索模式,计算所生成的相同检索模式的个数;保留所述个数大于阈值的检索模式。进一步的,如图4所示,所述装置还包括:排序单元34,用于根据所述相似度的值确定所述输出单元33输出的检索结果中网页的排序。综上所述,本发明实施例所提供的一种基于搜索引擎的检索信息匹配方法及装置,通过为搜索引擎配置检索模式信息库,将用户录入的检索信息与信息库中的检索模式进行匹配,实现解析用户的检索意图,将用户的检索内容扩展到一类信息的查询与检索。同时,通过信息库中的检索模式,也为互联网中的网页匹配对应的检索模式,在为用户匹配对应的检索结果时,通过计算用户录入的检索模式与网页对应检索模式的相似度来判断网页是否符合用户的检索意图,从而确定是否将该网页作为检索结果输出给用户。此外,本发明实施例通过对检索模式的不断的更新与训练,可以有效提高对用户检索意图的识别与判断,从而为用户匹配出更为准确的检索结果,提高用户的检索体验。在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。可以理解的是,上述云端服务器及装置中的相关特征可以相互参考。另外,上述实施例中的“第一”、“第二”等是用于区分各实施例,而并不代表各实施例的优劣。所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述云端服务器实施例中的对应过程,在此不再赘述。在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的云端服务器、结构和技术,以便不模糊对本说明书的理解。类似地,应当理解,为了精简本发明并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的云端服务器解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何云端服务器或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。此外,本领域的技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(DSP)来实现根据本发明实施例的发明名称(如确定网站内连接等级的装置)中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的云端服务器的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。本发明实施例还公开了以下技术方案:A1、一种基于搜索引擎的检索信息匹配方法,所述方法包括:创建检索模式信息库,所述检索模式是对已有检索信息统计分析得到的能够代表一类检索信息的模式化信息;将网页的标题以及搜索引擎获取的新检索信息分别与所述信息库中的检索模式进行匹配;当匹配出的检索模式的相似度达到阈值时,将所述网页作为所述新检索信息的检索结果输出。A2、根据A1所述的方法,所述创建检索模式信息库包括:对所获取的已有检索信息进行预处理,得到词向量表示的检索信息;利用聚类算法将处理后的检索信息进行聚类,得到多个分类检索信息列表,所述分类检索信息列表中记录有相似上下文信息的检索信息;从所述分类检索信息列表中提取对应的检索模式;将所述检索模式保存至检索模式信息库中。A3、根据A2所述的方法,所述对所获取的已有检索信息进行预处理包括:将所获取的已有检索信息逐条添加到有第一检索信息列表中;对所述第一检索信息列表中的检索信息进行分词以及词性标注处理,得到第二检索信息列表和第三检索信息列表,所述第二检索信息列表中保存有分词后的检索信息,所述第三检索信息列表中保存有对分词结果进行词性标注的检索信息;利用文本深度表示模型word2vec对第二检索信息列表中的分词进行向量化表示,将所述向量化的分词存储在词向量文件中;提取所述第三检索信息列表中词性标注为名词性的分词,将所述分词添加到分词列表中,所述分词列表中记录有分词以及所述分词在所述第三检索信息列表中出现的次数。A4、根据A3所述的方法,所述利用聚类算法将处理后的检索信息进行聚类,得到多个分类检索信息列表包括:在所述词向量文件中查找所述分词列表中分词的向量值;根据所述向量值计算所述分词列表中任意两个分词间的欧氏距离;对所述分词列表中每个分词提取预置数量的邻近分词,组成分词组,所述邻近分词是根据所述欧氏距离进行由近至远排序得到的分词;在所述第一检索信息列表中提取含有所述分词组中至少一个分词的检索信息;将所提取的检索信息保存在一个分类检索信息列表中。A5、根据A2-A4中任一项所述的方法,所述从所述分类检索信息列表中提取对应的检索模式包括:利用FPGrowth算法逐一计算每个分类检索信息列表中的频繁项集合,所述频繁项集合含有至少一个频繁项集;调整所述频繁项集中频繁项的顺序,生成所述分类检索信息列表对应的检索模式。A6、根据A5所述的方法,所述调整所述频繁项集中频繁项的顺序,生成所述分类检索信息列表对应的检索模式包括:提取所述频繁项集中的一组频繁项;在所述分类检索信息列表中匹配含有所述一组频繁项的检索信息;将所述检索信息中非频繁项的分词替换为通用符;将含有通用符和所述一组频繁项且按照所述检索信息中的分词排序排列的信息确定为所述分类检索信息列表对应的检索模式。A7、根据A6所述的方法,所述调整所述频繁项集中频繁项的顺序,生成所述分类检索信息列表对应的检索模式还包括:统计所生成的检索模式,计算所生成的相同检索模式的个数;保留所述个数大于阈值的检索模式。A8、根据A1所述的方法,所述方法还包括:根据所述相似度的值确定所述检索结果中网页的排序。B9、一种基于搜索引擎的检索信息匹配装置,所述装置包括:创建单元,用于创建检索模式信息库,所述检索模式是对已有检索信息统计分析得到的能够代表一类检索信息的模式化信息;匹配单元,用于将网页的标题以及搜索引擎获取的新检索信息分别与所述创建单元创建的信息库中的检索模式进行匹配;输出单元,用于当所述匹配单元匹配出的检索模式的相似度达到阈值时,将所述网页作为所述新检索信息的检索结果输出。B10、根据B9所述的装置,所述创建单元包括:处理模块,用于对所获取的已有检索信息进行预处理,得到词向量表示的检索信息;聚类模块,用于利用聚类算法将所述处理模块处理后的检索信息进行聚类,得到多个分类检索信息列表,所述分类检索信息列表中记录有相似上下文信息的检索信息;提取模块,用于从所述聚类模块得到的分类检索信息列表中提取对应的检索模式;存储模块,用于将所述提取模块得到的检索模式保存至检索模式信息库中。B11、根据B10所述的装置,所述处理模块包括:第一处理子模块,用于将所获取的已有检索信息逐条添加到有第一检索信息列表中;第二处理子模块,用于对所述第一处理子模块得到的第一检索信息列表中的检索信息进行分词以及词性标注处理,得到第二检索信息列表和第三检索信息列表,所述第二检索信息列表中保存有分词后的检索信息,所述第三检索信息列表中保存有对分词结果进行词性标注的检索信息;第三处理子模块,用于利用文本深度表示模型word2vec对所述第二处理子模块得到的第二检索信息列表中的分词进行向量化表示,将所述向量化的分词存储在词向量文件中;第四处理子模块,用于提取所述第二处理子模块得到的第三检索信息列表中词性标注为名词性的分词,将所述分词添加到分词列表中,所述分词列表中记录有分词以及所述分词在所述第三检索信息列表中出现的次数。B12、根据B11所述的装置,所述聚类模块包括:查找子模块,用于在所述词向量文件中查找所述分词列表中分词的向量值;计算子模块,用于根据所述查找子模块查询到的向量值计算所述分词列表中任意两个分词间的欧氏距离;组合子模块,用于对所述分词列表中每个分词提取预置数量的邻近分词,组成分词组,所述邻近分词是根据所述计算子模块计算的欧氏距离进行由近至远排序得到的分词;提取子模块,用于在所述第一检索信息列表中提取含有所述组合子模块组成的分词组中至少一个分词的检索信息;存储子模块,用于将所述提取子模块提取的检索信息保存在一个分类检索信息列表中。B13、根据B10-B12中任一项所述的装置,所述提取模块包括:计算子模块,用于利用FPGrowth算法逐一计算每个分类检索信息列表中的频繁项集合,所述频繁项集合含有至少一个频繁项集;生成子模块,用于调整所述计算子模块得到的频繁项集中频繁项的顺序,生成所述分类检索信息列表对应的检索模式。B14、根据B13所述的装置,所述生成子模块还用于,提取所述频繁项集中的一组频繁项;在所述分类检索信息列表中匹配含有所述一组频繁项的检索信息;将所述检索信息中非频繁项的分词替换为通用符;将含有通用符和所述一组频繁项且按照所述检索信息中的分词排序排列的信息确定为所述分类检索信息列表对应的检索模式。B15、根据B14所述的装置,所述生成子模块还用于,统计所生成的检索模式,计算所生成的相同检索模式的个数;保留所述个数大于阈值的检索模式。B16、根据B9所述的装置,所述装置还包括:排序单元,用于根据所述相似度的值确定所述输出单元输出的检索结果中网页的排序。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1