一种依存结构树库获取方法及系统与流程
本发明涉及树库转换,尤指一种依存结构树库获取方法及系统。
背景技术:
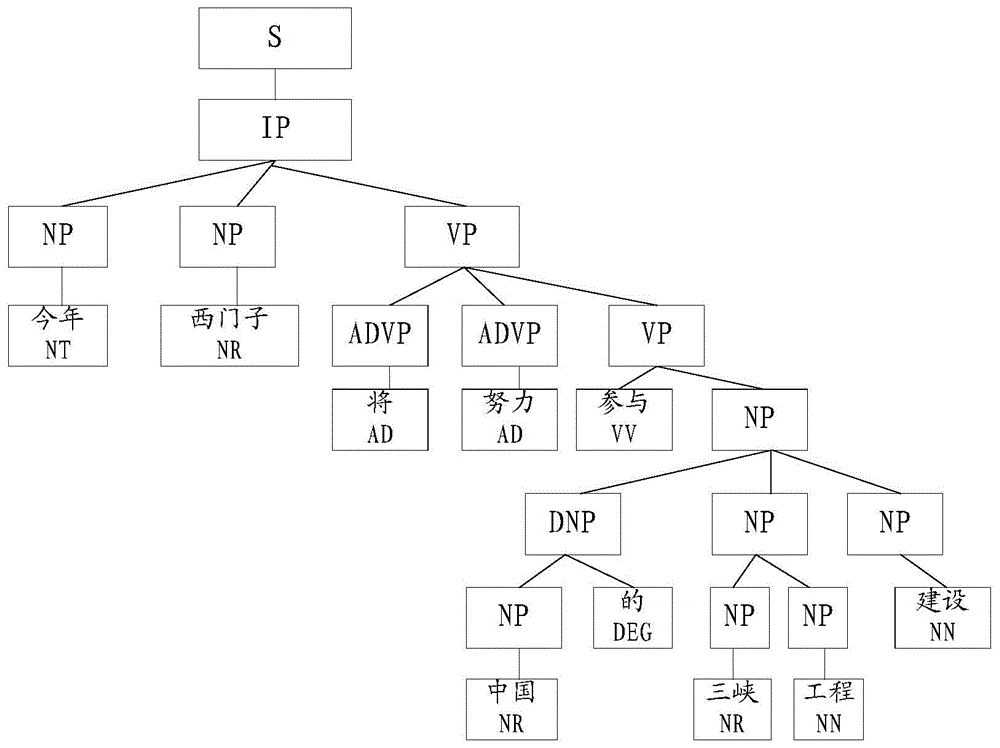
:句法分析是自然语言处理领域非常重要的研究方向。在基于统计的句法分析方法中,根据所使用的语料不同,可以分为有指导的方法和无指导的方法。有指导的方法需要事先按照一定的语法规范,人工标注好一些句子作为训练数据,然后通过各种概率统计方法或机器学习方法,从训练数据中获取句法分析所需要的知识。无指导的方法则使用没有经过标注的数据进行训练,按照一定的机制,从中自动学习语法规律。有指导的句法分析是现在的主流方法,目前在英语等语言中已经达到了较高的准确率。在有指导的句法分析中,事先标注的用于训练的句子集叫做树库。目前绝大多数的统计句法分析模型都是利用标注好的树库以有指导学习方式来训练模型的参数。因此,树库建设是一个非常重要的工作,其质量和规模直接关系到句法分析的训练效果。句法分析首先要遵循某一语法体系,根据该语法体系的语法确定语法树的表示形式。目前,在句法分析中使用比较广泛的有短语结构语法和依存语法。例如:“今年西门子将努力参与中国的三峡工程建设。”其短语结构分析结果如图1a,是类似于树的层层拆分结构。第一级为“S”即指整个句子“今年西门子将努力参与中国的三峡工程建设。”。第二级分为四个部分,第二级的第一部分“NP”即指名词短语,对应“今年”;第二级的第二部分“NP”即指名词短语,对应“西门子”;第二级的第三部分“VP”即指动词短语,对应“将努力参与中国的三峡工程建设”;第二级的第四部分“PU”即指标点符号,对应“。”。第三级分为三个部分,第三级的第一部分“ADVP”即指状语短语,对应“将”;第三级的第二部分“ADVP”即指状语短语,对应“努力”;第三级的第三部分“VP”即指动词短语,对应“参与中国的三峡工程建设”。第四级分为两个部分,第四级的第一部分“VV”即指动词,对应“参与”;第四级的第二部分“NP”即指名词短语,对应“中国的三峡工程建设”。第五级分为三个部分,第五级的第一部分“DNP”即指定语短语,对应“中国的”;第五级的第二部分“NP”即指名语短语,对应“三峡工程”;第五级的第三部分“NP”即指名词短语,对应“建设”。第六级分为四个部分,第六级的第一部分“NP”即指定语短语,对应“中国”;第六级的第二部分“DEG”即助词短语,对应“的”;第六级的第三部分“NP”即指定语短语,对应“三峡”;第六级的第四部分“NP”即指定语短语,对应“工程”。利用依存结构分析“中国的三峡工程建设”,结果如图1b。依存结构是利用带方向的弧线标注出各个词之间的关系。依存结构的分析结构比短语结构的分析结构更加直观。“今年西门子将努力参与中国的三峡工程建设。”的核心节点“VG”对应“参与”,“今年”、“将”和“努力”都是“参与”的“ADV”即状语关系,“西门子”与“参与”是“SBV”关系即主谓关系,“中国”与“的”是“ATT”关系即定语关系,“三峡”与“工程”是“ATT”关系即定语关系,“工程”与“建设”是“ATT”关系即定语关系。“。”后的“EOS”即空节点表示结束。如何利用图1a所示的短语结构分析结果转换为图1b所示的依存结构,是本领域需要解决的技术问题。英语句法分析的发展得益于PennTreebank(佩恩树库)的建立,PennTreebank的规模大,标注质量高,已成为英语句法分析事实上的标准,几乎所有的研究工作都基于该树库进行。同时,将PennTreebank转换为依存结构的工作也已经成熟。反观汉语方面,树库建设工作还有差距,既缺少统一的依存标注体系,也缺少大规模的依存树库。现存的汉语短语结构树库最著名的有宾夕法尼亚大学的中文树库PCT(PennChineseTreebank)、TCT(清华大学的汉语树库)等等。而汉语依存树库则相对比较少,著名的有HIT-IR-CDT(哈工大汉语依存树库)、SDN(清华大学电子系标注的树库)。HIT-IR-CDT是哈尔滨工业大学信息检索研究室标注的汉语依存树库。将PennTreebank转换为依存结构的技术已很成熟。相对应于英文依存语法而言,中文(汉语)短语结构树库转换为依存结构的工作还很不成熟。现有Penn2Malt转换工具中提供了PennChineseTreebank转换为依存结构的规则文件,可以将PennChineseTreebank转换为依存结构。转换工具Penn2Malt提供的汉语结构转换规则文件包含的规则无法准确的描述各种语言现象,没有能力处理并列关系,以及PennChineseTreebank中的扁平结构。现有将TCT转换为依存结构,完全采用规则的方法。这样就要求对TCT中的语法体系非常熟悉,然后对一种规约形式进行规则转换,包括指定核心节点、指定关系类型。这种将TCT转换为依存结构的做法没有很好的通用性,需要投入相对较大的人力。而且,其依存体系主要集中于跟动词相关的各种关系成分的描述。上述的工作,都是将短语结构的树库转换为某种依存树库。转换后的依存树库的体系和任何现有的依存树库都不一致,这样不利于有效利用转换后的树库。只能把转换后的树库作为独立的树库,然后使用。树库的规模和质量直接影响句法分析的性能,树库规模越大,质量越好,训练出来的句法分析器的性能必然越好。因此,如何将汉语短语结构树库转换为依存结构树库,充分利用汉语短语结构树库和依存结构树库的树库规模大,质量好的优势,是本领域技术人员亟需解决的技术问题。技术实现要素:为了解决现有转换后的依存树库的体系不统一的问题,本发明提供一种依存结构树库获取方法及系统,将短语结构树库转换为依存结构树库,转换后的树库可以很方便的和原有的依存结构树库合并,从而增大树库规模,进而有效地提高句法分析器的性能。为解决上述问题,本发明提供一种依存结构树库获取方法,包括以下步骤:调用第一树库;所述第一树库为汉语短语结构树库;分别采用第一树库的转换工具以及句法分析器,将所述第一树库中的短语结构转换为依存结构;所述第二树库为依存结构的树库;其中,采用第一树库的转换工具将所述第一树库中的短语结构转换为依存结构包括:利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构;以及,基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构;其中,采用句法分析器,将所述第一树库中的短语结构转换为依存结构包括:利用所述句法分析器,将所述第一树库中的扁平结构的短语结构转换为依存结构;利用训练得到的依存关系映射模型,对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库。可选的,所述利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构,包括:根据预先建立的Head核心节点映射表,确定所述第一树库的短语结构树库中语法推导的核心节点;利用所述映射表,并依据所述映射表中的规则,针对所述核心节点进行扫描,得到其他子节点与所述核心节点的依存关系;其中,所述Head核心节点映射表为依据所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则所形成的。可选的,所述利用句法分析器,将所述第一树库中的扁平结构的短语结构转换为依存结构,具体包括:利用所述句法分析器,对所述第一树库中的扁平结构的短语结构,在有向图中寻找最大生成树,确定所述扁平结构的短语结构中不同短语的依存概率;根据所述不同短语的依存概率将所述第一树库中的扁平结构的短语结构转换为依存结构。可选的,利用所述第二树库中的短语对所述句法分析器进行训练。可选的,该方法进一步包括:获得所述扁平结构的短语结构转换为依存结构的转换准确率,依据所述准确率,对所述句法分析器进行调整训练。可选的,利用互联网资源,搜索及统计转换后的所述依存结构的出现概率,依据所述概率确定所述转换准确率。可选的,所述基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构,具体包括:将所述并列结构的短语结构切分为多个片段;分别确定各个片段的核心节点,以及,将每个片段中除核心节点外的其他节点确定为依存于该片段中的核心节点;将除第一个片段之外的其他片段的各个核心节点,确定为依存于所述第一个片段的核心节点。可选的,所述将所述并列结构的短语结构切分为多个片段,具体包括:以连词词性或顿号作为切分依据进行所述切分。可选的,所述将所述并列结构的短语结构切分为多个片段,具体包括:获得输入法输入情况,以输入法输入情况中的输入间断为切分依据进行所述切分。可选的,所述将所述并列结构的短语结构切分为多个片段,具体包括:当所述并列结构的短语结构中的不同短语具有关联关系时,以所述关联关系作为切分依据进行所述切分。可选的,所述确定各个片段的核心节点包括:以所述短语结构所在语句作为分析对象,确定所述片段的各个节点的在所述语句上下文中的出现次数,根据不同节点出现次数的比较情况,确定出现次数满足要求的节点作为所述核心节点。可选的,所述依存关系映射模型的建立包括:利用所述第二树库训练依存关系标注模型;利用所述依存关系标注模型对所述第一树库进行依存关系标注;利用所述第一树库的原有词性和句法信息,纠正所述依存关系标注的结果,建立所述依存关系映射模型。可选的,所述依存关系标注模型使用第二线性对数模型进行依存关系标注;其中,i=0,对应wordword_f词语,父亲词语特征,i=1,对应wordpos_f词语,父节点词性特征,i=2,对应posword_f词性特征,i=3,对应pospos_fdistance父节点词性特征,λ0:对应i=0时wordword_f特征的权值;λ1:对应i=1时wordpos_f特征的权值;λ2:对应i=2时posword_f特征的权值;λ3:对应i=3时pospos_fdistance特征的权值。可选的,所述依存关系映射模型使用第三线性对数模型进行依存关系标注;其中,i=0,对应phrase自身短语类型特征,i=1,对应phrase_s生成自身短语类型特征,i=2,对应phrase_f父亲短语类型特征,λ0:对应i=0时phrase特征的权值;λ1:对应i=1时phrase_s特征的权值;λ2:对应i=2时phrase_f特征的权值。可选的,该方法进一步包括:将所述第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集。可选的,所述中国标准词性标注集为863词性标注集。可选的,所述将所述第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集,包括:利用所述第二树库对第一树库的词语进行词性标注,并利用预先建立的词性映射模型进行词性划分,纠正所述标注的词性。可选的,所述词性映射模型使用第一线性对数模型:进行词性转化;其中,i=0,对应pos自身词性特征,i=1,对应pos_spos子节点词性,自身词性特征,i=2,对应pospos_f自身词性特征,父节点词性,λ0:对应i=0时pos特征的权值;λ1:对应i=1时pos_spos特征的权值;λ2:对应i=2时pospos_f特征的权值。可选的,所述第一树库为PennChineseTreeBank宾夕法尼亚大学中文树库,所述第二树库为HIT-IR-CDT哈工大汉语依存树库。本发明还提供一种依存结构树库获取系统,包括调用单元和转换单元:所述调用单元,用于调用第一树库;所述第一树库为汉语短语结构树库;所述转换单元,用于分别采用第一树库的转换工具以及句法分析器,将所述第一树库中的短语结构转换为依存结构;所述第二树库为依存结构的树库;其中,采用第一树库的转换工具将所述第一树库中的短语结构转换为依存结构包括:利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构;以及,基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构;其中,采用句法分析器,将所述第一树库中的短语结构转换为依存结构包括:利用所述句法分析器,将所述第一树库中的扁平结构的短语结构转换为依存结构;所述转换单元还用于利用训练得到的依存关系映射模型,对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库。可选的,所述转换单元具体包括确定子单元和扫描子单元:所述确定子单元,用于根据预先建立的Head核心节点映射表,确定所述第一树库的短语结构树库中语法推导的核心节点;所述扫描子单元,用于利用所述映射表,并依据所述映射表中的规则,针对所述核心节点进行扫描,得到其他子节点与所述核心节点的依存关系;其中,所述Head核心节点映射表为依据所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则所形成的。可选的,所述转换单元具体用于利用所述句法分析器,对所述第一树库中的扁平结构的短语结构,在有向图中寻找最大生成树,确定所述扁平结构的短语结构中不同短语的依存概率;根据所述不同短语的依存概率将所述第一树库中的扁平结构的短语结构转换为依存结构。可选的,该系统进一步包括句法分析器训练单元,用于利用所述第二树库中的短语对所述句法分析器进行训练。可选的,该系统进一步包括调整单元,用于获得所述扁平结构的短语结构转换为依存结构的转换准确率,依据所述准确率,对所述句法分析器进行调整训练。可选的,所述调整单元,具体用于利用互联网资源,搜索及统计转换后的所述依存结构的出现概率,依据所述概率确定所述转换准确率。可选的,所述转换单元具体包括切分子单元和依存确定子单元,所述切分子单元,用于将所述并列结构的短语结构切分为多个片段;所述依存确定子单元,用于分别确定各个片段的核心节点,以及,将每个片段中除核心节点外的其他节点确定为依存于该片段中的核心节点;所述依存确定子单元,还用于将除第一个片段之外的其他片段的各个核心节点,确定为依存于所述第一个片段的核心节点。可选的,所述切分子单元,用于将所述并列结构的短语结构以连词词性或顿号作为切分依据进行所述切分。可选的,所述切分子单元,用于获得输入法输入情况,以输入法输入情况中的输入间断为切分依据进行所述切分。可选的,所述切分子单元,用于当所述并列结构的短语结构中的不同短语具有关联关系时,以所述关联关系作为切分依据进行所述切分。可选的,所述依存确定子单元,用于以所述短语结构所在语句作为分析对象,确定所述片段的各个节点的在所述语句上下文中的出现次数,根据不同节点出现次数的比较情况,确定出现次数满足要求的节点作为所述核心节点。可选的,根据依存关系映射模型的建立,该系统还包括训练单元、标注单元和纠正单元:所述训练单元,用于利用所述第二树库训练依存关系标注模型;所述标注单元,用于利用所述依存关系标注模型对所述第一树库进行依存关系标注;所述纠正单元,用于利用所述第一树库的原有词性和句法信息,纠正所述依存关系标注的结果,建立所述依存关系映射模型。可选的,所述依存关系标注模型使用第二线性对数模型进行依存关系标注;其中,i=0,对应wordword_f词语,父亲词语特征,i=1,对应wordpos_f词语,父节点词性特征,i=2,对应posword_f词性特征,i=3,对应pospos_fdistance父节点词性特征,λ0:对应i=0时wordword_f特征的权值;λ1:对应i=1时wordpos_f特征的权值;λ2:对应i=2时posword_f特征的权值;λ3:对应i=3时pospos_fdistance特征的权值。可选的,所述依存关系映射模型使用第三线性对数模型进行依存关系标注;其中,i=0,对应phrase自身短语类型特征,i=1,对应phrase_s生成自身短语类型特征,i=2,对应phrase_f父亲短语类型特征,λ0:对应i=0时phrase特征的权值;λ1:对应i=1时phrase_s特征的权值;λ2:对应i=2时phrase_f特征的权值。可选的,该系统进一步包括转化单元:所述转化单元,用于将所述第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集。可选的,所述中国标准词性标注集为863词性标注集。可选的,所述转化单元具体用于利用所述第二树库对第一树库的词语进行词性标注,并利用预先建立的词性映射模型进行词性划分,纠正所述标注的词性。可选的,所述词性映射模型使用第一线性对数模型:进行词性转化;其中,i=0,对应pos自身词性特征,i=1,对应pos_spos子节点词性,自身词性特征,i=2,对应pospos_f自身词性特征,父节点词性,λ0:对应i=0时pos特征的权值;λ1:对应i=1时pos_spos特征的权值;λ2:对应i=2时pospos_f特征的权值。可选的,所述第一树库为PennChineseTreeBank宾夕法尼亚大学中文树库,所述第二树库为HIT-IR-CDT哈工大汉语依存树库。与上述现有技术相比,本发明实施例所述依存结构树库获取方法包含将第一树库如汉语短语结构树库转换为第二树库类型的依存结构树库的步骤。本发明实施例所述依存结构树库获取方法将汉语短语结构树库转换为依存结构树库,这样,转换后的树库可以很方便的和原有的依存结构树库进行合并,从而增大树库规模,进而有效地提高句法分析器的性能。同时,本发明实施例所述依存结构树库获取方法包含利用句法分析器对第一树库中的扁平结构的短语结构转换为依存结构的步骤,解决了名词复合短语等扁平结构的短语结构转换为依存结构困难的问题。附图说明图1a是现有技术短语结构分析结果图;图1b是现有技术依存结构分析结果图;图2是本发明所述依存结构树库获取方法第一实施例流程图;图3是本发明所述依存关系映射模型的建立流程图;图4a是本发明所述扁平短语结构示意图;图4b是图4a所述扁平短语结构转换为依存结构的示意图;图5是本发明所述并列结构的短语结构转换为依存结构方法的流程图;图6是本发明所述并列结构的短语结构转换为依存结构的示意图;图7是本发明所述依存结构树库获取方法第二实施例流程图;图8是本发明所述依存关系示意图;图9是本发明所述依存结构树库获取系统第一实施例结构图;图10是本发明所述依存结构树库获取系统第二实施例结构图。具体实施方式本发明提供一种依存结构树库获取方法,将第一树库如汉语短语结构树库转换为第二树库类型的依存结构树库,转换后的依存结构树库可以很方便的和原有的依存结构树库合并,从而增大树库规模,进而有效地提高句法分析器的性能。参见图2和图3,图2为本发明所述依存结构树库获取方法第一实施例流程图;图3是本发明所述依存关系映射模型的建立流程图。本发明第一实施例所述依存结构树库获取方法,如图2所示,包括以下步骤:S201、调用第一树库。所述第一树库可以为汉语短语结构树库,例如,PennChineseTreebank、TCT等。S202、分别采用第一树库的转换工具以及句法分析器,将所述第一树库中的短语结构转换为依存结构。所述第二树库可以为依存结构的树库,例如,HIT-IR-CDT、SDN等。在本发明实施例中,所述第一树库可以为PennChineseTreebank,所述第二树库可以为HIT-IR-CDT。其中,采用第一树库的转换工具将所述第一树库中的短语结构转换为依存结构包括:利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构;以及,基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构。接下来将对采用第一树库的转换工具将所述第一树库中的短语结构转换为依存结构的具体操作展开介绍。具体的,所述利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构,包括:根据预先建立的Head核心节点映射表,确定所述第一树库的短语结构树库中语法推导的核心节点;利用所述映射表,并依据所述映射表中的规则,针对所述核心节点进行扫描,得到其他子节点与所述核心节点的依存关系;其中,所述Head核心节点映射表为依据所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则所形成的。为了后续方便介绍,接下来展开介绍的内容中均以第一树库为PennChineseTreebank,第二树库为HIT-IR-CDT为例进行介绍。通过对PennChineseTreebank中所有的语法推导进行观察,对Penn2Malt提供的规则文件进行了修正,形成Head映射表,进而对并列等结构进行处理,最终将PennChineseTreebank短语结构转换为符合HIT-IR-CDT体系的依存结构。利用Head映射表将PennChineseTreebank的短语结构转换为依存结构。表1:Head映射表Head映射表用于确定一个语法推导中的核心节点。利用Head映射表确定子节点序列中哪一个为父节点的(Head)核心节点。上表中每一个短语类型都对应一个规则集。PennChineseTreebank树库短语结构应用这些规则进行转换。每一个规则包含两方面,方向及核心短语类型。方向为r或l。r表示从右到左扫描子节点序列,l表示从左到右扫描子节点序列。例如,在PennChineseTreebank树库中存在一个短语结构的语法推导:NP==>ADJPDNPNNNN。“==>”表示方向,“==>”左边的NP为父节点,ADJPDNPNNNN为子节点序列。对NN进行编号以区分,将NP==>ADJPDNPNNNN标注为NP==>ADJPDNPNN(1)NN(2)。参见表1Head映射表,确定NP对应的规则集为:首先考察规则1,规则1的方向为r。从右向左扫描预核心节点序列,发现第一个预核心节点NP没有在子节点序列“ADJPDNPNN(1)NN(2)”出现。继续从右向左重新扫描预核心节点序列,发现第二个预核心节点NN出现在子节点序列“ADJPDNPNN(1)NN(2)”中,由于是从右向左扫描,因此首先发现NN(2),则确定NN(2)为核心节点,退出。确定其它子节点“ADJPDNPNN(1)”都依存于核心节点NN(2)。最后一个规则为默认规则。如果前面的规则都没有满足,则使用默认规则。此时如果最后一个规则为r,则最右边的子节点作为核心节点。此时如果最后一个规则为l,则最左边的子节点作为核心节点。这样就可以根据表1Head映射表所述确定PennChineseTreebank树库短语结构的依存关系。利用上述规则进行转换适用于常见的短语结构,但是在所需进行转换的短语结构中可能会存在扁平结构的短语结构,对于扁平结构的短语结构,采用上述规则可能无法实现将扁平结构的短语结构转换为依存结构。在本发明实施例中,对于扁平结构的短语结构可以利用句法分析器,将所述第一树库中的扁平结构的短语结构转换为依存结构。接下来将对采用句法分析器,将所述第一树库中的短语结构转换为依存结构的具体操作展开介绍。具体的,可以利用所述句法分析器,对所述第一树库中的扁平结构的短语结构,在有向图中寻找最大生成树,确定所述扁平结构的短语结构中不同短语的依存概率;根据所述不同短语的依存概率将所述第一树库中的扁平结构的短语结构转换为依存结构。依存概率可以反映出不同短语的依存关系,依存概率可以是具体的数值,不同短语的依存概率越高,说明不同短语的依存关系越好。可以通过预设阈值,将大于或等于预设阈值的依存概率所对应的短语结构转换为依存结构。以扁平结构的短语结构中的两个不同短语为例,如果这两个短语的依存概率大于或等于预设阈值,说明这两个短语具有较好的依存关系,即这两个短语之间的依存结构具有较高的参考价值,将其进行依存关系转换后可以作为第二树库类型的依存结构树库中的依存结构,因此可以将大于或等于预设阈值的依存概率所对应的短语结构转换为依存结构;如果这两个短语的依存概率低于预设阈值,说明这两个短语的依存关系较弱,即这两个短语之间的依存结构并不具有较高的参考价值,因此无需在这两个短语间建立依存结构,即无需将低于预设阈值的依存概率所对应的短语结构转换为依存结构。上述转换过程主要利用句法分析器进行,如果可以通过第二树库中的短语对句法分析器进行训练,那么在通过句法分析器将第一树库中的扁平结构的短语结构转换为依存结构时,则转换后的依存结构会更加贴近第二树库类型的依存结构,故此,在本发明实施例中,可以利用第二树库中的短语对所述句法分析器进行训练。通过句法分析器将第一树库中的扁平结构的短语结构转换为依存结构的准确率可能无法达到百分百,即转换得到的依存结构可能并非全部正确,为了进一步提高句法分析器的转换准确率,可以通过获得所述扁平结构的短语结构转换为依存结构的转换准确率,依据所述准确率,对所述句法分析器进行调整训练。转换准确率可以用于表示转换得到的依存结构正确的概率,转换准确率的计算具体可以是利用互联网资源,搜索及统计转换后的所述依存结构的出现概率,依据所述概率确定所述转换准确率。依存结构的出现概率越高说明转换准确率越高,可以通过预设数值,选择出出现概率高于预设数值的依存结构,根据该预设数值选择出的依存结构的准确率可以达到要求,即选择出的依存结构具有较高的参考价值。因此可以利用选择出的依存结构所对应的短语对所述句法分析器进行调整训练。通过对句法分析器的调整训练,可以进一步提高句法分析器将扁平结构的短语结构转换为依存结构的转换准确率,提高句法分析器的性能。下面展开介绍的内容均以第一树库为PennChineseTreebank,第二树库为HIT-IR-CDT为例。为了后续方便介绍,可以将扁平结构的短语结构简称为扁平短语结构。参见图4a和图4b,图4a为本发明所述扁平短语结构示意图;图4b为图4a所述扁平短语结构转换为依存结构的示意图。PennChineseTreebank的短语结构属于比较扁平的,主要体现在名词复合短语。例如:PennChineseTreebank的短语,“医疗机构药品采购服务中心”,其结构示意图如图4a所示。父节点为:NP(名词短语),子节点为6个NN(名词)。6个NN分别为“医疗”、“机构”、“药品”、“采购”、“服务”和“中心”。利用HIT-IR-LTP中的句法分析器对如图4a所示的短语结构进行依存分析,获得其内部依存关系。结果参见图4b。首先,确定第一级依存关系:“医疗”与“机构”、“药品”与“采购”和“服务”与“中心”三个依存关系。用带箭头或者带方向的弧线表示上述依存关系。即“医疗”通过带箭头或者带方向的弧线指向“机构”;“药品”通过带箭头或者带方向的弧线指向“采购”;“服务”通过带箭头或者带方向的弧线指向“中心”。然后,确定第二级依存关系,“机构”与“药品”和“采购”与“服务”两个依存关系。用带箭头或者带方向的弧线表示上述依存关系。即“机构”通过带箭头或者带方向的弧线指向“药品”;“采购”通过带箭头或者带方向的弧线指向“服务”。这样就确定了如图4b所示的依存结构。针对无法采用规则来表达的结构进行特殊的处理,主要针对并列结构。此类并列结构的短语结构数量很大。根据第二树库体系,这种情况需要特殊处理。我们采用基于规则的方法进行归纳,然后特殊处理。在本发明实施例中,对于并列结构的短语结构可以采用基于规则的方法进行归纳,将其转换为依存结构。接下来将对基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构的具体操作展开介绍,如图5所示,具体操作如下:S501:将所述并列结构的短语结构切分为多个片段。将并列结构的短语结构转换为依存结构时,首先需要确定出该并列结构的短语结构的核心节点,核心节点作为进行依存结构转换的关键,需要确保核心节点的准确性。以一段文字为例,确定出该段文字的核心节点,若该段文字的篇幅较长,则确定核心节点的难度会较大,并且可能导致确定出的核心词并不符合要求,为了提高确定核心节点的准确性,在进行核心节点的确定之前,可以先将并列结构的短语结构进行切分为多个片段,以片段为单位,从各片段中确定出的核心节点会更加准确。本发明实施例对于将并列结构的短语结构切分为多个片段的切分方式不作限定,可以是以连词词性或顿号作为切分依据进行所述切分,或者是获得输入法输入情况,以输入法输入情况中的输入间断为切分依据进行所述切分,又或者是当所述并列结构的短语结构中的不同短语具有关联关系时,以所述关联关系作为切分依据进行所述切分。其中不同短语的关联关系可以是不同短语属于同义词或者反义词。S502:分别确定各个片段的核心节点,以及,将每个片段中除核心节点外的其他节点确定为依存于该片段中的核心节点。以一个片段为例,确定该片段的核心节点的方式可以是以所述短语结构所在语句作为分析对象,确定所述片段的各个节点的在所述语句上下文中的出现次数,根据不同节点出现次数的比较情况,确定出现次数满足要求的节点作为所述核心节点。可以是将出现次数最高的节点作为核心节点,或者可以是将出现次数较高的节点作为核心节点,又或者可以是将出现次数高于设定数值的节点作为核心节点。S503:将除第一个片段之外的其他片段的各个核心节点,确定为依存于所述第一个片段的核心节点。在S502中可以确定出一个片段中其他节点和核心节点之间的依存结构,对于各个片段之间的依存结构,可以将第一个片段中的核心节点作为该并列结构的短语结构中的核心节点,其他片段中的核心节点与该核心节点建立依存结构。例如图6所示,“发达国家和深圳等特区”在短语结构中,“发达国家”和“深圳等特区”构成并列关系,即“发达国家和深圳等特区”属于并列结构的短语结构,依据上述方法可以将该并列结构的短语结构进行切分,可以切分为“发达国家”和“深圳等特区”这两个片段,第一个片段“发达国家”的核心节点为“国家”,第一片段中其他节点“发达”依存于核心节点“国家”,即“发达”通过带箭头或者带方向的弧线指向“国家”,第二个片段“深圳等特区”的核心节点为“深圳”,第二片段中其他节点“和”、“等”以及“特区”分别依存于核心节点“深圳”,即“和”通过带箭头或者带方向的弧线指向“深圳”,“等”通过带箭头或者带方向的弧线指向“深圳”,“特区”通过带箭头或者带方向的弧线指向“深圳”。在这两个片段之间,第二片段中的核心节点“深圳”依存于第一个片段中的核心节点“国家”,即“深圳”通过带箭头或者带方向的弧线指向“国家”。通过切分片段的方式确定核心节点,可以提高确定出的核心节点的准确率,从而使得转换后的依存结构更加准确。S203、利用训练得到的依存关系映射模型,对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库。参见图3,所述依存关系映射模型的建立包括以下步骤:S301、利用所述第二树库训练依存关系标注模型。依存关系标注器的工作是为每一条依存弧标注依存关系。每一条弧两端有两个节点:自身节点和父节点。其中自身节点依存于父节点,父节点支配自身节点,父节点为核心词。如上图中:“医疗-〉机构”构成一条弧,其中“医疗”为自身节点,“机构”为父节点。这是一个标注问题,采用线性对数模型。采用如下4个特征:特征说明特征说明wordword_f词语,父亲词语wordpos_f词语,父亲词性posword_f词性,父亲词语pospos_fdistance词性,父亲词性,距离采用极大似然估计来训练概率,得到模型形式如下:f0_这种_认识_ATT1f1_这种_n_ATT0.8f2_r_认识_ATT0.142857f3_r_n_1_ATT0.997324S302、利用所述依存关系标注模型对所述第一树库进行依存关系标注。以第一树库为PennChineseTreebank,第二树库为HIT-IR-CDT为例,利用依存关系标注模型对PennChineseTreebank进行依存关系标注其中四个特征wordword_f、wordpos_f、posword_f、pospos_fdistance的权值分别取0.4,0.2,0.2,0.2。利用HIT-IR-CDT测试语料测试,依存关系标注模型的准确率为89.7%。为了利用PennChineseTreebank中原有的正确的词性、句法信息,训练了一个依存关系映射模型,对依存关系标注结果进行纠正。在短语结构转依存结构的时候,记录三个信息,子节点的短语类型,生成短语类型,及父节点的短语类型。参考图8,该图为本发明所述依存关系示意图。图8表示出“医疗”和“机构”的依存关系记录为“NN-NP-NN”,“医疗”通过带箭头的弧线指向“机构”,在弧线上标注“NN-NP-NN”。S303、利用所述第一树库的原有词性和句法信息,纠正所述依存关系标注的结果,建立所述依存关系映射模型。训练依存关系映射模型时,使用这三个特征参见表2。表2训练依存关系映射模特征表特征说明特征说明phrase自身短语类型phrase_s生成自身短语类型phrase_f父亲短语类型采用极大似然估计来训练概率,得到模型形式如下:f0_NN_ATT0.734f1_NP_ATT0.543f2_NN_ATT0.933利用依存关系映射模型进行依存关系转换其中i=0,phrase特征的权值为0.35;i=1,phrase_s特征的权值为0.3;i=2,phrase_f特征的权值为0.35。进行依存关系映射后,结果如下:词上海浦东开发与法制建设同步编号1234567依存结构(父节点编号)2376630句法关系标注器结果ATTATTSBVLADATTATTHED句法关系映射模型结果ATTATTSBVLADATTCOOHED参见图3,所述依存关系映射模型的建立包括以下步骤:S301、利用所述第二树库训练依存关系标注模型。S302、利用所述依存关系标注模型对所述第一树库进行依存关系标注。S303、利用所述第一树库的原有词性和句法信息,纠正所述依存关系标注的结果,建立所述依存关系映射模型。所述依存关系标注模型使用第二线性对数模型进行所述依存关系标注;其中,i=0,对应wordword_f词语,父亲词语特征;i=1,对应wordpos_f词语,父节点词性特征;i=2,对应posword_f词性特征;i=3,对应pospos_fdistance父节点词性特征;λ0:对应i=0时wordword_f特征的权值;λ1:对应i=1时wordpos_f特征的权值;λ2:对应i=2时posword_f特征的权值;λ3:对应i=2时pospos_fdistance特征的权值。所述依存关系映射模型使用第三线性对数模型进行所述依存关系标注;其中,i=0,对应phrase自身短语类型特征;i=1,对应phrase_s生成自身短语类型特征;i=2,对应phrase_f父亲短语类型特征;λ0:对应i=0时phrase特征的权值;λ1:对应i=1时phrase_s特征的权值;λ2:对应i=2时phrase_f特征的权值。本发明实施例所述依存结构树库获取方法包含将第一树库如汉语短语结构转换为第二树库类型的依存结构树库的步骤。本发明实施例所述依存结构树库获取方法将汉语短语结构树库转换为依存结构树库,这样,转换后的依存结构树库可以很方便的和原有的依存结构树库进行合并,从而增大树库规模,进而有效地提高句法分析器的性能。同时,本发明实施例所述依存结构树库获取方法包含利用句法分析器对第一树库中的扁平结构的短语结构转换为依存结构的步骤,解决了名词复合短语等扁平结构的短语结构转换为依存结构困难的问题。参见图7,该图为本发明所述依存结构树库获取方法第二实施例流程图。本发明所述依存结构树库获取方法第二实施例相对第一实施例的区别在于,在第二实施例中进一步增加了对词性标注集转化的步骤。本发明第二实施例所述依存结构树库获取方法,包括以下步骤:S701、调用第一树库。S702、分别采用第一树库的转换工具以及句法分析器,将所述第一树库中的短语结构转换为依存结构。S702与S202的处理过程类似,在此不再赘述。S703、将所述第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集。所述中国标准词性标注集可以为863词性标注集。一个树库中不仅包含句法结构信息,还可以包含词性信息。各个树库所采用的词性标注集也不尽相同。因此可以增加对词性标注集进行转化的步骤。863词性标注集是我国标准词性标注集之一,本发明实施例所述方法将第一树库例如PennChineseTreebank词性标注集转化为符合中国标准词性标注集要求的标注集例如863词性标注集,这样可以统一树库中词性的标注,提高转化的准确性。接下来将对词性标注集转化过程的具体操作展开介绍。具体的,可以利用所述第二树库对第一树库的词语进行词性标注,并利用预先建立的词性映射模型进行词性划分,纠正所述标注的词性。以第一树库为PennChineseTreebank,第二树库为HIT-IR-CDT为例,利用HIT-IR-CDT对PennChineseTreebank的词语进行词性标注,并利用预先建立的词性映射模型进行所述词性划分,纠正所述标注的词性。所述词性映射模型使用第一线性对数模型:进行所述词性转化;其中,i=0,对应pos自身词性特征;i=1,对应pos_spos子节点词性,自身词性特征;i=2,对应pospos_f自身词性特征,父节点词性;λ0:对应i=0时pos特征的权值;λ1:对应i=1时pos_spos特征的权值;λ2:对应i=2时pospos_f特征的权值。HIT-IR-LTP是哈尔滨工业大学信息检索研究室开发的语言技术平台,其中包含各种包含很多自然语言处理模块如分词、句法分析等,还有一些语料资源如依存树库HIT-IR-CDT。HIT-IR-LTP现免费向学术界共享。HIT-IR-LTP中的词性标注模块的精度达到90%。利用HIT-IR-LTP词性标注器对PennChineseTreebank进行词性标注。虽然HIT-IR-LTP词性标注模块的精度比较高,但是不可避免还是会有错误。为了利用PennChineseTreebank中原有的正确的词性、句法信息,我们训练了一个词性映射模型,对标注结果进行纠正。词性映射模型使用线性对数模型,采用三个特征:参数估计采用极大似然估计,训练出的模型概率如下例。f0_NN_n=0.746038,表示NN映射为n的概率;f0_NN_v=0.1699158,表示NN映射为v的概率;f1_VC_NN_n=0.801055,表示子节点为VC,NN映射为n的概率;f1_VC_NN_v=0.121002,表示子节点为VC,NN映射为v的概率;f2_NN_NN_n=0.776695,表示父节点为NN,NN映射为n的概率;f2_NN_NN_v=0.180412,表示父节点为NN,NN映射为v的概率。利用下面的词性映射模型的公式进行词性转化:λ0=0.4,λ0对应i=0时pos特征的权值;λ1=0.3,λ1对应i=1时pos_spos特征的权值;λ2=0.3,λ2对应i=2时pospos_f特征的权值。例如下表所示词性映射模型纠正标注错误的对照表由上可以看出,利用原有PennChineseTreebank树库信息,可以有效的纠正某些词性标注错误。需要说明的是,S702和S703没有先后顺序上的限定。S704、利用训练得到的依存关系映射模型,对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库。训练依存关系映射模型时,使用表中三个特征。特征说明特征说明phrase自身短语类型phrase_s生成自身短语类型phrase_f父亲短语类型采用极大似然估计来训练概率,得到训练依存关系映射模型形式,利用依存关系映射模型进行依存关系转换。依存关系映射模型的公式如下:其中三个特征phrase、phrase_s、phrase_f的权值分别取0.35,0.3,0.35。进行依存关系映射后,结果如下:词上海浦东开发与法制建设同步编号1234567依存结构(父节点编号)2376630句法关系标注器结果ATTATTSBVLADATTATTHED句法关系映射模型结果ATTATTSBVLADATTCOOHED本发明提供一种依存结构树库获取方法,包括将第一树库如汉语短语结构树库转换为第二树库类型的依存结构树库,将第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集的步骤,包含了句法结构的转换和词性标注集的转化,使得转换后的依存结构树库更准确,转换后的依存结构树库可以很方便的和原有的依存结构树库合并,从而增大树库规模,进而有效地提高句法分析器的性能。参见图9,该图为本发明所述依存结构树库获取系统第一实施例结构图。本发明第一实施例所述依存结构树库获取系统,包括调用单元11和转换单元12。所述调用单元11,用于调用第一树库;所述第一树库为汉语短语结构树库。所述转换单元12,用于分别采用第一树库的转换工具以及句法分析器,将所述第一树库中的短语结构转换为依存结构;所述第二树库为依存结构的树库。其中,采用第一树库的转换工具将所述第一树库中的短语结构转换为依存结构包括:利用所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则,将所述短语结构转换为依存结构;以及,基于规则的方法进行归纳,将所述第一树库中的并列结构的短语结构转换为依存结构。其中,采用句法分析器,将所述第一树库中的短语结构转换为依存结构包括:利用所述句法分析器,将所述第一树库中的扁平结构的短语结构转换为依存结构。所述转换单元12还用于利用训练得到的依存关系映射模型,对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库。所述转换单元12和所述调用单元11相连。可选的,所述转换单元具体包括确定子单元和扫描子单元:所述确定子单元,用于根据预先建立的Head核心节点映射表,确定所述第一树库的短语结构树库中语法推导的核心节点。所述扫描子单元,用于利用所述映射表,并依据所述映射表中的规则,针对所述核心节点进行扫描,得到其他子节点与所述核心节点的依存关系。其中,所述Head核心节点映射表为依据所述转换工具所提供的将第一树库中的短语结构转换为依存结构的规则,或对所述规则进行修正后所得到的规则所形成的。可选的,所述转换单元具体用于利用所述句法分析器,对所述第一树库中的扁平结构的短语结构,在有向图中寻找最大生成树,确定所述扁平结构的短语结构中不同短语的依存概率;根据所述不同短语的依存概率将所述第一树库中的扁平结构的短语结构转换为依存结构。可选的,该系统进一步包括句法分析器训练单元,用于利用所述第二树库中的短语对所述句法分析器进行训练。可选的,该系统进一步包括调整单元,用于获得所述扁平结构的短语结构转换为依存结构的转换准确率,依据所述准确率,对所述句法分析器进行调整训练。可选的,所述调整单元,具体用于利用互联网资源,搜索及统计转换后的所述依存结构的出现概率,依据所述概率确定所述转换准确率。可选的,所述转换单元具体包括切分子单元和依存确定子单元,所述切分子单元,用于将所述并列结构的短语结构切分为多个片段;所述依存确定子单元,用于分别确定各个片段的核心节点,以及,将每个片段中除核心节点外的其他节点确定为依存于该片段中的核心节点;所述依存确定子单元,还用于将除第一个片段之外的其他片段的各个核心节点,确定为依存于所述第一个片段的核心节点。可选的,所述切分子单元,用于将所述并列结构的短语结构以连词词性或顿号作为切分依据进行所述切分。可选的,所述切分子单元,用于获得输入法输入情况,以输入法输入情况中的输入间断为切分依据进行所述切分。可选的,所述切分子单元,用于当所述并列结构的短语结构中的不同短语具有关联关系时,以所述关联关系作为切分依据进行所述切分。可选的,所述依存确定子单元,用于以所述短语结构所在语句作为分析对象,确定所述片段的各个节点的在所述语句上下文中的出现次数,根据不同节点出现次数的比较情况,确定出现次数满足要求的节点作为所述核心节点。可选的,根据依存关系映射模型的建立,该系统还包括训练单元、标注单元和纠正单元:所述训练单元,用于利用所述第二树库训练依存关系标注模型。所述标注单元,用于利用所述依存关系标注模型对所述第一树库进行依存关系标注。所述纠正单元,用于利用所述第一树库的原有词性和句法信息,纠正所述依存关系标注的结果,建立所述依存关系映射模型。可选的,所述依存关系标注模型使用第二线性对数模型进行依存关系标注;其中,i=0,对应wordword_f词语,父亲词语特征,i=1,对应wordpos_f词语,父节点词性特征,i=2,对应posword_f词性特征,i=3,对应pospos_fdistance父节点词性特征,λ0:对应i=0时wordword_f特征的权值;λ1:对应i=1时wordpos_f特征的权值;λ2:对应i=2时posword_f特征的权值;λ3:对应i=3时pospos_fdistance特征的权值。依存关系标注模型可以参见前文所述依存结构树库获取方法中依存关系标注模型的描述。可选的,所述依存关系映射模型使用第三线性对数模型进行依存关系标注;其中,i=0,对应phrase自身短语类型特征,i=1,对应phrase_s生成自身短语类型特征,i=2,对应phrase_f父亲短语类型特征,λ0:对应i=0时phrase特征的权值;λ1:对应i=1时phrase_s特征的权值;λ2:对应i=2时phrase_f特征的权值。依存关系映射模型可以参见前文所述依存结构树库获取方法中依存关系映射模型的描述。可选的,所述第一树库为PennChineseTreeBank宾夕法尼亚大学中文树库,所述第二树库为HIT-IR-CDT哈工大汉语依存树库。本发明实施例所述依存结构树库获取系统包含用于调用第一树库的调用单元11,和将第一树库中的短语结构转换为依存结构,并对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库的转换单元12。本发明实施例所述依存结构树库获取系统能够将汉语短语结构树库转换为依存结构树库,这样,转换后的依存结构树库可以很方便的和原有的依存结构树库进行合并,从而增大树库规模,进而有效地提高句法分析器的性能。同时,本发明实施例所述依存结构树库获取系统包含所述转换单元12能够利用句法分析器对第一树库中的扁平结构的短语结构转换为依存结构,解决了名词复合短语等扁平结构的短语结构转换为依存结构困难的问题。参见图10,该图为本发明所述依存结构树库获取系统第二实施例结构图。本发明所述依存结构树库获取系统第二实施例相对第一实施例增加了转化单元13。本发明所述依存结构树库获取系统进一步包括与所述转换单元12相连的转化单元13,用于将所述第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集。可选的,所述中国标准词性标注集为863词性标注集。可选的,所述转化单元具体用于利用所述第二树库对第一树库的词语进行词性标注,并利用预先建立的词性映射模型进行词性划分,纠正所述标注的词性。可选的,所述词性映射模型使用第一线性对数模型:进行词性转化;其中,i=0,对应pos自身词性特征,i=1,对应pos_spos子节点词性,自身词性特征,i=2,对应pospos_f自身词性特征,父节点词性,λ0:对应i=0时pos特征的权值;λ1:对应i=1时pos_spos特征的权值;λ2:对应i=2时pospos_f特征的权值。词性映射模型可以参见前文所述依存结构树库获取方法中词性映射模型的描述。本发明实施例所述依存结构树库获取系统包含用于调用第一树库的调用单元11,将第一树库中的短语结构转换为依存结构,并对所述第一树库中的依存结构进行依存关系转换,得到第二树库类型的依存结构树库的转换单元12,和将第一树库中的词性标注集转化为符合中国标准词性标注集要求的标注集的转化单元13,从而能够实现句法结构的转换和词性标注集的转化,使得转换后的依存结构树库更准确。转换后的依存结构树库可以很方便的和原有的依存结构树库进行合并,从而增大树库规模,进而有效地提高句法分析器的性能。同时,本发明实施例所述依存结构树库获取系统包含所述转换单元12能够利用句法分析器对第一树库中的扁平结构的短语结构转换为依存结构,解决了名词复合短语等扁平结构的短语结构转换为依存结构困难的问题。以上所述仅为本发明的优选实施方式,并不构成对本发明保护范围的限定。任何在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的权利要求保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1