基于神经机器翻译系统的单词预测方法及系统与流程
本发明涉及自然语言处理技术领域,更具体地,涉及一种基于神经机器翻译系统的单词预测方法及系统。
背景技术:
机器翻译就是用计算机来实现不同语言之间的转换。被翻译的语言通常称为源语言,翻译成的结果语言称为目标语言。机器翻译就是实现从源语言到目标语言转换的过程。
神经机器翻译是近些年来出现的最新的机器翻译方法,在翻译质量上,较原有的统计机器翻译方法有了一个显著的提升。相比于之前的统计机器翻译方法,神经机器翻译所需的工程设计更少,翻译效果也更好。当其首次被提出时,便在中等规模的公共基准数据集上就达到了可与统计方法媲美的准确度。自那以后,研究者已经提出了很多改进神经机器翻译的技术,如今在翻译质量上已经大大超越了统计方法,包括Google翻译和百度翻译在内的诸多业内公司都在近期将自己的翻译系统从基于统计的方法更新为基于神经网络的方法,并广受好评。
然而,机器翻译还远未得到完全解决。神经机器翻译虽然表现卓著,但仍然会做出一些人类翻译者永远不出做出的重大错误,例如:漏词、重复翻译、错误翻译、将句子单独进行翻译而不考虑其段落的上下文等等;而统计机器翻译在上述很多方面的表现是要优于神经机器翻译的,例如在忠实度和可解释性等方面。事实上,目前已经有研究人员注意到这方面的问题,并利用统计方法的信息和特征去对神经网络方法进行改进,但这些方法在利用统计方法的信息的广度和深度上仍然不够充分。
例如目前这类方法利用最多的仍然是单词的翻译表,因为神经网络方法在生成句子时,是以单词作为最小的生成单位,利用单词翻译概率的翻译概率相对比较容易,但是单词的翻译表进行神经机器翻译并不能确保每个词组、短语均被准确翻译,使得通过神经翻译模型得到的单词预测概率相对较差,忠实度和可解释性不高。
因此,如何充分利用统计机器翻译中蕴含的这些思想和信息去解决神经翻译模型得到的单词预测概率相对较差的问题是一个非常值得研究的课题。
技术实现要素:
为了解决现有技术中的上述问题,即为了解决神经翻译模型得到的单词预测概率相对较差的问题,本发明提供了一种基于神经机器翻译系统的单词预测方法及系统。
为解决上述技术问题,本发明提供了如下方案:
一种基于神经机器翻译系统的单词预测方法,所述单词预测方法包括:
利用统计机器翻译系统对平行语料进行训练,从训练结果中抽取,获得短语翻译表;
基于所述短语翻译表,对任意平行句对中的源语言句子进行匹配搜索,确定所述源语言句子中包含的全部源语言短语;
基于各所述源语言短语,从所述短语翻译表中查找各所述源语言短语分别对应的目标短语翻译候选集;
根据所述目标短语翻译候选集及神经机器翻译系统翻译所得的部分译文,获得需要鼓励的目标单词集;
根据基于神经机器翻译系统所得的注意力概率和目标短语翻译候选集,确定所述目标单词集中各所述目标单词的鼓励值;
根据各所述目标单词的鼓励值,获得各所述目标单词的预测概率。
可选的,所述短语翻译表包括多个参考源语言短语、各所述参考源语言短语对应的多个参考目标语言短语,及同一个所述参考源语言短语对应的各所述参考目标语言短语的翻译概率;
所述目标短语翻译候选集包括所述源语言短语对应的多个目标语言短语,及各所述目标语言短语的翻译概率。
可选的,所述获得需要鼓励的目标单词集的方法包括:
步骤S41:从所述目标短语翻译候选集中的所有目标语言短语中,确定一个目标短语前缀;
步骤S42:从所述神经机器翻译系统翻译所得的部分译文中,确定一个译文后缀;
步骤S43:判断所述目标短语前缀与所述译文后缀是否匹配,如果匹配则执行步骤S44,否则执行步骤S45;
步骤S44:选择一个目标短语翻译候选集中各所述目标语言短语中所述目标短语前缀的下一个单词为目标单词;
步骤S45:选择一个目标短语翻译候选集中各所述目标语言短语中的第一个单词为目标单词,从同一个目标短语翻译候选集中选择的全部目标单词形成一个目标单词集。
可选的,所述确定所述目标单词集中各所述目标单词的鼓励值的方法包括:
步骤S51:基于各所述目标单词,从所述目标短语翻译候选集中抽取所述目标单词所在的各目标语言短语的翻译概率,以及各目标语言短语对应的当前源语言短语;
步骤S52:基于各所述目标单词及所述神经机器翻译系统所得的注意力概率确定当前源语言短语的注意力概率;
步骤S53:根据各目标语言短语的翻译概率及当前源语言短语的注意力概率确定各所述目标单词的鼓励值。
可选的,根据以下公式确定当前源语言短语的注意力概率:
其中,aij为目标单词yi和所述目标单词yi对应的源语言句子中的源端单词xj之间注意力概率,i表示目标单词yi的序号,j表示源端单词xj的序号,|fp|为当前源语言短语中所包含单词的个数,为目标端单词yi和当前源语言短语fp之间注意力概率。
可选的,根据以下公式确定各所述目标单词的鼓励值:
Rw(yi)=a(i,fp)pphrase(yi);
其中,yi为目标单词,为目标端单词yi和当前源语言短语fp之间注意力概率,pphrase(yi)为目标单词yi所在目标语言短语的翻译概率,Rw(yi)为目标单词yi的鼓励值。
可选的,根据以下公式获得各所述目标单词的预测概率
其中,i表示目标单词yi的序号,ci为源语言的编码向量,为神经机器翻译系统翻译所得的部分译文,为目标单词yi的词向量,为神经机器翻译系统翻译的输出向量,为神经机器翻译系统对目标单词yi的打分,bs为标准softmax层的偏置向量。
根据本发明的实施例,本发明公开了以下技术效果:
本发明基于神经机器翻译系统的单词预测方法通过引入短语翻译表,获取目标短语翻译候选集及目标单词集,进而确定目标单词的鼓励值,将所述鼓励值添加到神经翻译模型中,从而可准确获得各所述目标单词的预测概率。
为解决上述技术问题,本发明还提供了如下方案:
一种基于神经机器翻译系统的单词预测系统,所述单词预测系统包括:
抽取单元,用于利用统计机器翻译系统对平行语料进行训练,从训练结果中抽取,获得短语翻译表;
搜索单元,用于基于所述短语翻译表,对任意平行句对中的源语言句子进行匹配搜索,确定所述源语言句子中包含的全部源语言短语;
选集单元,用于基于各所述源语言短语,从所述短语翻译表中查找各所述源语言短语分别对应的目标短语翻译候选集;
选词单元,用于根据所述目标短语翻译候选集及神经机器翻译系统翻译所得的部分译文,获得需要鼓励的目标单词集;
计算单元,用于根据基于神经机器翻译系统所得的注意力概率和目标短语翻译候选集,确定所述目标单词集中各所述目标单词的鼓励值;
预测单元,用于根据各所述目标单词的鼓励值,获得各所述目标单词的预测概率。
可选的,所述短语翻译表包括多个参考源语言短语、各所述参考源语言短语对应的多个参考目标语言短语,及同一个所述参考源语言短语对应的各所述参考目标语言短语的翻译概率;
所述目标短语翻译候选集包括所述源语言短语对应的多个目标语言短语,及各所述目标语言短语的翻译概率。
可选的,所述选词单元包括:
第一确定模块,用于从所述目标短语翻译候选集中的所有目标语言短语中,确定一个目标短语前缀;
第二确定模块,用于从所述神经机器翻译系统翻译所得的部分译文中,确定一个译文后缀;
判断模块,用于判断所述目标短语前缀与所述译文后缀是否匹配;
筛选模块,与所述判断模块连接,用于在所述判断模块的判断结果为是时,选择一个目标短语翻译候选集中各所述目标语言短语中所述目标短语前缀的下一个单词为目标单词;以及在所述判断模块的判断结果为否时,选择一个目标短语翻译候选集中各所述目标语言短语中的第一个单词为目标单词,从同一个目标短语翻译候选集中选择的全部目标单词形成一个目标单词集。
根据本发明的实施例,本发明公开了以下技术效果:
本发明基于神经机器翻译系统的单词预测系统通过设置抽取单元抽取短语翻译表,设置选集单元获取目标短语翻译候选集及设置选词单元获取目标单词集,进而确定目标单词的鼓励值,将所述鼓励值添加到神经翻译模型中,从而可准确获得各所述目标单词的预测概率。
附图说明
图1是本发明基于神经机器翻译系统的单词预测方法的流程图;
图2是本发明基于神经机器翻译系统的单词预测方法的一个实施例示意图;
图3是本发明基于神经机器翻译系统的单词预测系统的结构示意图;
图4是本发明基于神经机器翻译系统的单词预测系统与神经机器翻译系统的实施例对比图。
符号说明:
抽取单元—1,搜索单元—2,选集单元—3,选词单元—4,计算单元—5,预测单元—6。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
如图1所示,本发明基于神经机器翻译系统的单词预测方法包括:
步骤100:利用统计机器翻译系统对平行语料进行训练,从训练结果中抽取,获得短语翻译表;
步骤200:基于所述短语翻译表,对任意平行句对中的源语言句子进行匹配搜索,确定所述源语言句子中包含的全部源语言短语;
步骤300:基于各所述源语言短语,从所述短语翻译表中查找各所述源语言短语分别对应的目标短语翻译候选集;
步骤400:根据所述目标短语翻译候选集及神经机器翻译系统翻译所得的部分译文,获得需要鼓励的目标单词集;
步骤500:根据基于神经机器翻译系统所得的注意力概率和目标短语翻译候选集,确定所述目标单词集中各所述目标单词的鼓励值;
步骤600:根据各所述目标单词的鼓励值,获得各所述目标单词的预测概率。
本发明基于神经机器翻译系统的单词预测方法和神经机器翻译系统、统计机器翻译系统一样,均需要一定的平行句对还进行训练,其中,平行句对为一对源语言句子和对应的目标语言句子。
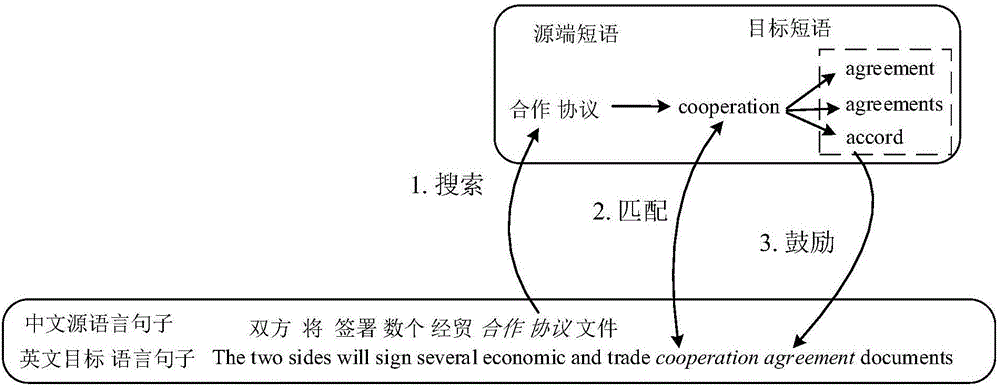
下面我们通过一个具体的实例来进行说明(如图2所示):假设我们的训练语料中有这样一个平行句对,其中源语言句子S为:
“双方将签署数个经贸合作协议文件。”
对应的标准译文T:
“The two sides will sign several economic and trade cooperation agreement documents.”。
可对平行句对中的源语言句子进行自动分词,得到源语言词。
即,经过分词以后,源语言句子即可表示为:
“双方将签署数个经贸合作协议文件。”
其中,对汉语进行分词的方法有很多种。在本实施例中可以开源的分词工具对汉语进行分词。
进一步地,在步骤100中,平行训练语料通过传统的统计机器翻译进行处理,从训练结果中抽取,得到短语翻译表,这里的统计机器翻译系统可以是任何统计机器翻译系统,如著名的开源Moses,Moses拥有比较完善的文档,根据这些文档可以轻松地部署翻译服务器。
所述短语翻译表包括多个参考源语言短语、各所述参考源语言短语对应的多个参考目标语言短语,及同一个所述参考源语言短语对应的各所述参考目标语言短语的翻译概率,且所述参考源语言短语、多个参考目标语言短语及各所述参考目标语言短语的翻译概率为对齐设置。
在步骤200中,在得到短语翻译表后,可对任意平行句对中的源语言句子进行匹配搜索,找到该平行句对的源语言句子所包含的全部源语言短语。
在本实施例中,所述源语言句子S包含一个短语,即“合作协议”。
在步骤300中,得到平行句对中源语言句子所包含的全部源语言短语后,基于各所述源语言短语,通过短语翻译表的对齐关系,从所述短语翻译表中查找各所述源语言短语分别对应的目标短语翻译候选集找到该源端短语所有的目标短语翻译候选集。
所述目标短语翻译候选集包括所述源语言短语对应的多个目标语言短语,及各所述目标语言短语的翻译概率。
在本实施例中,通过查询短语翻译表,假设“合作协议”可能的翻译有三个,分别为:“cooperation agreement”、“cooperation agreements”和“cooperation accords”,翻译概率分别为0.5、0.4和0.1。这三个短语及其翻译概率就构成了目标短语翻译候选集。
进一步地,在步骤400中,所述获得需要鼓励的目标单词集的方法包括:
步骤410:从所述目标短语翻译候选集中的所有目标语言短语中,确定一个目标短语前缀。
所述短语前缀是指目标语言短语中以第一个单词为开始,以非末尾单词为结束的单词序列。
在本实施例中,三个短语(“cooperation agreement”、“cooperation agreements”和“cooperation accords”)的前缀只有一个,均为“cooperation”。
步骤420:从所述神经机器翻译系统翻译所得的部分译文中,确定一个译文后缀。
所述译文后缀是指以部分译文中以任意单词为开始,以部分译文的最后一个单词为结束的单词序列。
假设神经机器翻译所得的部分翻译译文为“The two sides will”,那么该部分译文包含4个后缀,分别为“will”、“sides will”、“two sides will”以及“the two sides will”。
步骤430:判断所述目标短语前缀与所述译文后缀是否匹配,如果匹配则执行步骤440,否则执行步骤450。
步骤440:选择一个目标短语翻译候选集中各所述目标语言短语中所述目标短语前缀的下一个单词为目标单词。
步骤450:选择一个目标短语翻译候选集中各所述目标语言短语中的第一个单词为目标单词,从同一个目标短语翻译候选集中选择的全部目标单词形成一个目标单词集。
在本实施例中,在部分译文为:“The two sides will sign several economic and trade cooperation”时,该部分译文包含一个译文后缀“cooperation”,而短语前缀也包含“cooperation”,此时便为匹配,否则为不匹配。
例如,在部分译文为“The two sides will sign several economic and trade cooperation”时,如果译文后缀和短语前缀能够匹配,则将短语匹配部分的下一个单词加入需要鼓励的目标单词集。在本实施例中,短语候选集中的三个短语(“cooperation agreement”、“cooperation agreements”和“cooperation accords”)的匹配部分(“cooperation”)的下一个单词(“agreement”、“agreements”和“accords”)都是需要鼓励的目标单词。从同一个目标短语翻译候选集中选择的全部目标单词形成一个目标单词集。
如果不匹配,则需要鼓励的目标单词为短语候选集中的三个短语(“cooperation agreement”、“cooperation agreements”和“cooperation accords”)的第一个单词(“cooperation”)。
在步骤500中,所述确定所述目标单词集中各所述目标单词的鼓励值的方法包括:
步骤510:基于各所述目标单词,从所述目标短语翻译候选集中抽取所述目标单词所在的各目标语言短语的翻译概率,以及各目标语言短语对应的当前源语言短语。
在本实施例中,从所述目标短语翻译候选集中抽取所述目标单词所在的目标语言短语有三个,分别为:“cooperation agreement”、“cooperation agreements”和“cooperation accords”,翻译概率分别为0.5、0.4和0.1。
步骤520:基于各所述目标单词及所述神经机器翻译系统所得的注意力概率确定当前源语言短语的注意力概率。
所述注意力概率是神经机器翻译用来衡量当前神经机器翻译系统正在翻译源语言的某个单词的概率。假设神经机器翻译系统正在翻译某个单词,则该单词的注意力概率就高,其他单词的注意力概率就低。可以通过对短语中所有单词的注意力概率做平均,来得到该短语的注意力值,具体根据如下公式所示:
其中,aij为目标单词yi和所述目标单词yi对应的源语言句子中的源端单词xj之间注意力概率,i表示目标单词yi的序号,j表示源端单词xj的序号,|fp|为当前源语言短语中所包含单词的个数,为目标端单词yi和当前源语言短语fp之间注意力概率。
在本实施例中,假设神经机器翻译系统在预测“agreement”时,对单词“协议”的注意力概率为0.8,对单词“合作”的注意力概率为0.2,其余源语言句子中的单词的注意力概率均为0,则目标单词“agreement”对于短语“合作协议”的注意力概率为
步骤530:根据各目标语言短语的翻译概率及当前源语言短语的注意力概率确定各所述目标单词的鼓励值。
具体,根据以下公式确定各所述目标单词的鼓励值:
Rw(yi)=a(i,fp)pphrase(yi) (2);
其中,yi为目标单词,为目标端单词yi和当前源语言短语fp之间注意力概率,pphrase(yi)为目标单词yi所在目标语言短语的翻译概率,Rw(yi)为目标单词yi的鼓励值。
在本实施例中,在预测“agreement”时,需要鼓励的目标单词为三个,即“agreement”、“agreements”和“accords”。这三个单词的源语言短语“合作协议”的注意力概率均为各自目标短语的翻译概率为0.5、0.4和0.1。因此,“agreement”的鼓励值为0.5*0.5=0.25,“agreements”的鼓励值为0.5*0.4=0.2,“accords”的鼓励值为0.5*0.1=0.05。
在步骤600中,将各所述目标单词的鼓励值融合到神经翻译模型中,以获得各所述目标单词的预测概率。具体的,根据以下公式获得各所述目标单词的预测概率
其中,i表示目标单词yi的序号,ci为源语言的编码向量,为神经机器翻译系统翻译所得的部分译文,为目标单词yi的词向量,为神经机器翻译系统翻译的输出向量,为神经机器翻译系统对目标单词yi的打分,bs为标准softmax层的偏置向量。
假设标准神经机器翻译系统对“agreement”的打分为10,则加入鼓励值以后的打分为(1+0.25)*10=12.5,打分越高意味着该目标单词的预测概率就会越高。
本发明的积极效果:由于神经机器翻译系统更倾向于输出通顺但却不忠实的译文,而统计机器翻译系统则更倾向输出忠实却不通顺的译文。因此,能够有效结合这两种方法将有效提高机器翻译系统的翻译效果。本发明能够有效地将统计机器翻译方法所提取到的短语翻译表融合到标准的神经机器翻译模型中。本发明通过在每一个解码的时刻,对每个需要鼓励的单词进行适当鼓励的方式,来提高标准神经方法的翻译效果。本发明基于神经机器翻译系统的单词预测方法,相对于标准的神经网络方法,无论在机器评价还是主观评价上均有提升,其中在机器评价指标上,本发明有了2.25BLEU的提升;在主观评价的译文对源语言的忠实度上,本发明有了11.7%的提高。这充分证明了融合短语翻译表的神经机器翻译方法的有效性和优越性。
此外,本发明还提供一种基于神经机器翻译系统的单词预测系统,准确获得各所述目标单词的预测概率。如图3所示,本发明基于神经机器翻译系统的单词预测系统包括抽取单元1、搜索单元2、选集单元3,选词单元4、计算单元5及预测单元6。
其中,所述抽取单元1用于利用统计机器翻译系统对平行语料进行训练,从训练结果中抽取,获得短语翻译表;
所述搜索单元2与所述抽取单元1连接,基于所述短语翻译表,对任意平行句对中的源语言句子进行匹配搜索,确定所述源语言句子中包含的全部源语言短语。
所述选集单元3与所述搜索单元2连接,基于各所述源语言短语,从所述短语翻译表中查找各所述源语言短语分别对应的目标短语翻译候选集。
所述选词单元4与所述选集单元3连接,根据所述目标短语翻译候选集及神经机器翻译系统翻译所得的部分译文,获得需要鼓励的目标单词集。
所述计算单元5分别连接所述选词单元4和所述选集单元3,根据基于神经机器翻译系统所得的注意力概率和目标短语翻译候选集,确定所述目标单词集中各所述目标单词的鼓励值。
所述预测单元6与所述计算单元5连接,根据各所述目标单词的鼓励值,获得各所述目标单词的预测概率。
进一步地,所述短语翻译表包括多个参考源语言短语、各所述参考源语言短语对应的多个参考目标语言短语,及同一个所述参考源语言短语对应的各所述参考目标语言短语的翻译概率。
所述目标短语翻译候选集包括所述源语言短语对应的多个目标语言短语,及各所述目标语言短语的翻译概率。
优选地,所述选词单元4包括第一确定模块、第二确定模块、判断模块、筛选模块。
其中,所述第一确定模块从所述目标短语翻译候选集中的所有目标语言短语中,确定一个目标短语前缀;所述第二确定模块从所述神经机器翻译系统翻译所得的部分译文中,确定一个译文后缀;所述判断模块判断所述目标短语前缀与所述译文后缀是否匹配;所述筛选模块与所述判断模块连接,用于在所述判断模块的判断结果为是时,选择一个短语翻译表中各所述目标语言短语中所述目标短语前缀的下一个单词为目标单词;以及在所述判断模块的判断结果为否时,选择一个短语翻译表中各所述目标语言短语中的第一个单词为目标单词,从同一个短语翻译表中选择的全部目标单词形成一个目标单词集。
表1所示,本发明与标准神经机器翻译系统和统计机器翻译系统在五组测试数据(MT03、MT04、MT05、MT06以及MT08)上的表现。我们的训练数据包含六十万个平行句对。我们可以看到,本发明在机器自动给出的评价指标(BLEU)上相比于标准的神经机器翻译系统有了2.25BLEU值的提高。这充分说明了将短语翻译表融入神经机器翻译系统方法的有效性和优越性。
除此之外,表2给出了本发明与神经机器翻译系统对源语言忠实度的主观评价。同时从图4中可以看到,本发明在忠实度的主观评价上相比如标准的神经机器翻译系统也有了一定的提高。
总之,实验结果表明本发明将短语翻译表融入神经机器翻译系统能充分有效利用短语对齐信息,能大幅提高神经机器翻译系统的翻译效果。
表1
表2
本发明的方法不是针对两种特定的语言而提出的,所以本发明的方法具有普遍的适用性。本发明虽然只在汉语到英语翻译方向上进行了实验,但本发明同时也适用于其它语言对,如英语到汉语、汉语到法语翻译方向等。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!