一种基于海量小文件高效上传HDFS的方法及系统与流程
本发明涉及移动通讯技术领域,具体为一种基于海量小文件的高效上传HDFS的方法及其系统。
背景技术:
随着新型计算技术的发展,无论是企业还是个人的数据都开始迅速增长。海量数据增长带来的不仅仅是存储容量问题,还给数据管理、存储性能带来了挑战,成为云计算时代需要解决的核心问题。通常我们认为大小在1MB以内的文件称为小文件,百万级数量及以上称为海量,由此量化定义海量小文件。海量小文件应用在目前实际中越来越常见,如社交网站、电子商务、广电、网络视频、高性能计算。在大数据应用场景下,随着数据收集方案的发展,由于大数据领域Flume(分布式海量日志采集、聚合和传输系统)的实时收集方案对小文件的处理性能不好,导致海量小文件末端在HDFS的上传受到极大限制,大量小文件的请求,消耗大量的IO和内存,上传效率低。为了保证数据的高可用、高可靠和经济性,云计算采用分布式存储的方式来存储数据,采用冗余存储的方式来保证数据的可靠性。为了满足大量用户的需求,云计算的存储技术必须具有高吞吐率和高传输率。
Hadoop是近几年发展比较成熟的云计算平台之一,凭借其可靠、高效、可伸缩的特性在互联网领域得到了广泛应用,同时也得到了学术界的普遍关注。HDFS作为Hadoop的分布式文件系统,已经成为海量存储集群上部署的主流文件系统。HDFS由一个NameNode和若干个DataNode组成,其中NameNode负责管理文件系统的命名空间,DataNode是文件系统的工作节点。HDFS这种主从式的架构模式极大地简化了分布式文件系统的结构,但是由于NameNode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目取决于NameNode的内存大小。这就导致了HDFS对海量小文件支持不理想的问题。而且NameNode过大的内存开销和存储的低效严重影响了系统可扩展性和可用性。
HDFS对高数据吞吐量的应用场景进行了优化,换句话说是为访问大文件开发的,如果访问大量小文件,需要不断的从一个Datanode(HDFS的数据节点,为HDFS提供存储块)跳到另一个Datanode,严重影响性能。最后,处理大量小文件速度远远高于处理同等大小的大文件的速度。每一个小文件要占用一个Slot(HDFS的资源单位),而Job(HDFS的任务单位)启动将耗费大量时间甚至大部分时间都耗费在启动Job和释放Job上。所以,当存储海量小文件时,元数据在Namenode(HDFS的控制节点,在HDFS内部提供元数据服务),中所占用的内存大量增加,从而导致HDFS对海量小文件存储性能较差。由于分布式文件系统的设计原理导致海量小文件传输时具有先天缺陷,使得海量小文件的传输速率受到限制。
技术实现要素:
本发明针对现有技术存在的问题,提出了一种基于海量小文件的高效上传HDFS的方法及其系统,通过建立文件池,和对文件池中的数据进行预处理,衔接了Python的数据处理技术和Hadoop的块大小累加,并增加本地HDFS的上传程序,达到海量小文件的高效上传HDFS。
本发明解决其技术问题所采用的技术方案是:
一种基于海量小文件的高效上传HDFS的方法,包括以下步骤:
1)搭建Hadoop2.7.1的集群环境,设置好HIVE、HDFS的环境与配置,设置好名称节点组和资源管理组;其中,HIVE、HDFS分别是基于Hadoop的数据仓库工具。
2)对各结节搭建网站服务器集群;
3)设置HIVE与HDFS的关联表;
4)建立小文件收集的文件池;
5)对文件池中的数据进行预处理程序的部署和调试;
6)设置小文件合并后的大小近似为Hadoop的块大小;
7)启动清洗、提取、合并、累加、上传的程序;
8)将数据上传至HDFS。
作为优选,所述步骤4)包括,通过网站服务器中的业务处理逻辑先进行文件大小的判断,Hadoop块对其长度设定一默认值,逻辑规定小于Hadoop块长度的文件被判定为小文件,以形成文件池;如果文件长度大于Hadoop块的长度,则被判定为大文件,直接放入待上传队列中;循环这一操作直至用户此次上传的所有文件处理完毕。
作为优选,所述步骤5)包括,获取文件池中小文件的文件名、文件长度及文件上传时间戳,通过安全散列算法SHA-1生成文件存储ID。
作为优选,步骤5)中通过安全散列算法SHA-1生成文件存储ID,具体为:利用小文件文件名与上传时间戳进行字符串拼接,再对拼接得到的字符串使用安全散列算法SHA-1,从而生成小文件的存储ID。
作为优选,步骤6)包括,根据服务器内存大小,申请一定内存的缓冲区,所述缓冲区的大小为Hadoop的块大小。
作为优选,步骤7)包括,遍历文件池中的小文件,以最优的方式将找出合并文件总大小与缓冲区大小近似的N个小文件,根据文件存储ID将N个相应的小文件放入待上传队列中。
作为优选,其中,合并文件总大小大于等于阈值S1小于等于阈值S2,其中阈值S1为小于缓冲区大小的某个值,阈值S2等于缓冲区的大小。
作为优选,根据文件存储ID将文件池中的小文件排序,按先后顺序对小文件进行遍历,当已遍历M个小文件,而这M个小文件中有N个小文件的合并文件总大小与缓冲区的大小近似时,则停止遍历,并将相应的N个小文件合并后移至待上传队列中,再按原先的排列顺序对文件池中剩下的小文件重新遍历;当文件池中加入新的小文件时,会根据文件存储ID将新的小文件从原有小文件的后面继续排列下去。
作为优选,将N个小文件合并具体包括,先提取小文件中的元数据,并通过Python处理技术将N组元数据合并。
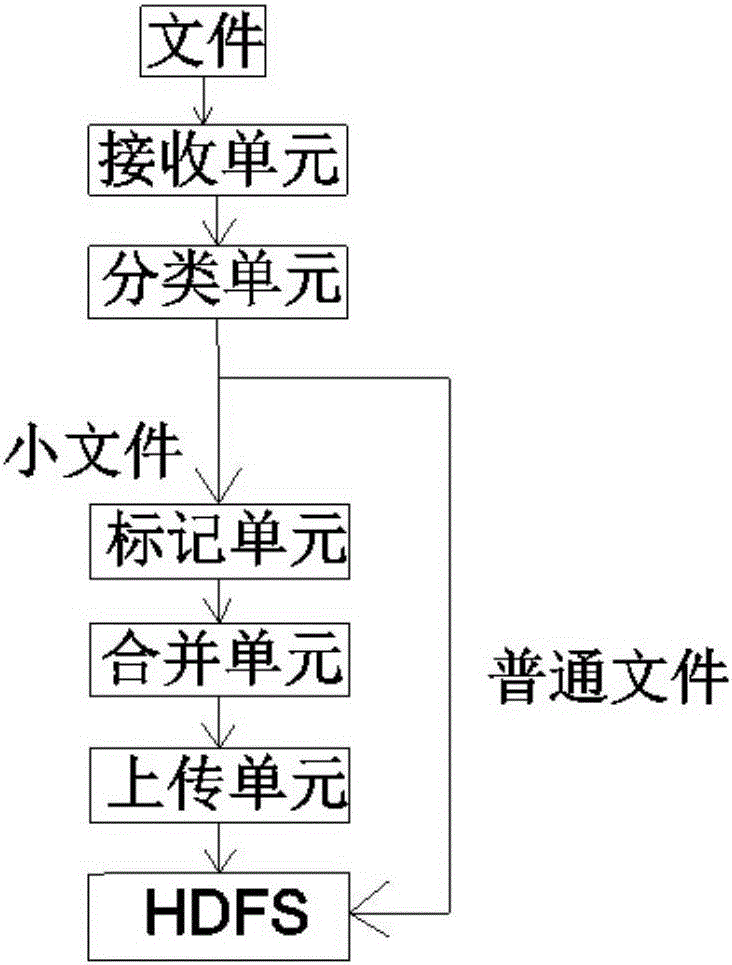
一种实现上述权利要的海量小文件的高效上传HDFS的方法的系统,包括:接收单元,分类单元,标记单元,合并单元和上传单元,其中:
接收单元,用以接收需要上传的文件;
分类单元,将文件与Hadoop块的大小做对比,将文件分为小文件和普通文件两类,普通文件直接上传至HDFS;
标记单元,获取每个小文件的文件名、文件长度及文件上传时间戳;
合并单元,申请一定内存的缓冲区,将总大小与缓冲区大小近似的N个小文件进行合并,并移至待上传队列;
上传单元,将待上传队列中的文件上传至HDFS。
本发明的有益效果是,通过建立文件池和对文件池中的数据进行预处理,衔接了Python的数据处理技术和Hadoop的块大小累加,并增加本地HDFS的上传程序,达到海量小文件的高效上传HDFS。
附图说明
图1为本发明的结构示意图;
图2为本发明的系统结构图。
具体实施方式
以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
本实施例一种基于海量小文件的高效上传HDFS的方法,包括以下步骤:
1)搭建Hadoop2.7.1的集群环境,设置好HIVE、HDFS的环境与配置,设置好名称节点组和资源管理组;
2)对各结节搭建网站服务器集群;
3)设置HIVE与HDFS的关联表;
4)建立小文件收集的文件池。
所述步骤4)包括,通过网站服务器中的业务处理逻辑先进行文件大小的判断,Hadoop块对其长度设定一默认值,逻辑规定小于Hadoop块长度的文件被判定为小文件,以形成文件池;如果文件长度大于Hadoop块的长度,则被判定为大文件,直接放入待上传队列中;循环这一操作直至用户此次上传的所有文件处理完毕。
本发明采用B/S模式,即“浏览器—服务器”模式。用户界面层即客户端机器,为普通的装有浏览器的PC机。业务逻辑层即预处理器,可以为单台服务器或者是服务器集群,其中运行着网站服务器,如Tomcat,用来处理客户机通过浏览器提交过来的请求以及对此请求作出响应的响应。预处理器是介于用户界面层与存储层的Hadoop集群之间的中间件,主要负责对用户的操作作一个预处理,如文件的合并,R树及倒排索引的更新,映射的建立等,然后将处理结果交给下一层,也就是存储层。存储层是真正存储数据的地方,采用Hadoop集群,集群大小依需求而定,生产环境下可以采用服务器,测试环境可以采用普通PC机。存储层还提供与业务逻辑层的预处理器的交互。
5)对文件池中的数据进行预处理程序的部署和调试。
所述步骤5)包括,获取文件池中小文件的文件名、文件长度及文件上传时间戳,通过安全散列算法SHA-1生成文件存储ID。具体为:利用小文件文件名与上传时间戳进行字符串拼接,再对拼接得到的字符串使用安全散列算法SHA-1,从而生成小文件的存储ID。
6)设置小文件合并后的大小近似为Hadoop的块大小;步骤6)包括,根据服务器内存大小,申请一定内存的缓冲区,所述缓冲区的大小为Hadoop的块大小。
7)启动清洗、提取、合并、累加、上传的程序;步骤7)包括,遍历文件池中的小文件,以最优的方式将找出合并文件总大小与缓冲区大小近似的N个小文件,根据文件存储ID将N个相应的小文件放入待上传队列中。其中,合并文件总大小大于等于阈值S1小于等于阈值S2,其中阈值S1为小于缓冲区大小的某个值,阈值S2等于缓冲区的大小。
根据文件存储ID将文件池中的小文件排序,按先后顺序对小文件进行遍历,当已遍历M个小文件,而这M个小文件中有N个小文件的合并文件总大小与缓冲区的大小近似时,则停止遍历,并将相应的N个小文件合并后移至待上传队列中,再按原先的排列顺序对文件池中剩下的小文件重新遍历;当文件池中加入新的小文件时,会根据文件存储ID将新的小文件从原有小文件的后面继续排列下去。将N个小文件合并具体包括,先提取小文件中的元数据,并通过Python处理技术将N组元数据合并。
8)将数据上传至HDFS。
具体步骤包括:
步骤一:小文件判断
在用户界面层,文件经用户通过客户端浏览器上传,此次上传后的文件先被提交至业务逻辑层预处理器的网站服务器中。网站服务器中的业务处理逻辑先进行文件大小的判断,本发明所取Hadoop块大小为其默认值64MB,逻辑规定小于块长度的文件被判定为小文件,放入文件池中,如果文件长度大于块的长度,则被判定为普通文件,直接放入待上传队列中。循环这一操作直至用户此次上传的所有文件处理完毕。
步骤二:元数据提取
小文件元数据提取出来分为两个部分,一是数值化的元数据,如上传时间,最后修改时间,文件大小;二是非数值化的元数据的,如上传者,文件名。文件提取出的元数据如下:
<上传者,文件名,上传时间,最后修改时间,大小等>,通过获取小文件的文件名Name,文件长度Length,上传时间戳CreateTime后,利用小文件文件名Name与上传时间戳CreateTime进行字符串拼接,再对拼接得到的字符串使用SHA-1(安全散列算法),生成小文件的存储ID。
步骤三:生成文件存储ID
依次取出待合并的小文件,提取出其元数据。元数据处理分为两个部分,一是数值化元数据的处理,二是非数值化元数据的处理,二者特性不同,处理方法不同。元数据处理完成后,通过安全散列算法SHA-1生成文件存储ID。
A:数值化元数据的处理
数值化的元数据有<上传时间,最后修改时间,大小>,如<20140712091020,20140610105316,32372>,这些数据的大小有比较意义,可放入R树中。在插入R树之前,做好此元数据到小文件名的映射,采用“键—值”对的形式存储在属性(properties)文件中。properties是这种文件的扩展名。此文件格式的优点在于:文件中的记录存放位置并不是按照插入顺序,而是按照键的哈希值存放,这大大地提高了查询速度。映射结构中,键是数值化的元数据,值为小文件名。因为R树的查询结果是一个点的坐标值,要将其映射为文件名才有意义。此处的映射结构可设计为:
20140712091020_20140610105316_32372=filename
其中,“=”号左边的数字以“_”隔开,分别为文件的上传时间,最后修改时间和大小,“=”号右边的是对应此元数据的小文件名。
B:非数值化元数据的处理
非数值化的元数据有<上传者,文件名>,如<zhangsan,Thinkingin Java>,这些数据不可比较大小,所以不应与数值化的元数据使用相同处理策略。本发明对这类元数据的处理方法是采用倒排索引,记录包含元数据中关键词的文件编号,在查询时可快速查到符合查询要求的文件集合。
步骤四,文件合并
遍历文件池中的小文件,以最优的方式将找出合并文件总大小与缓冲区大小近似的N个小文件,根据文件存储ID将N个相应的小文件放入待上传队列中。其中,合并文件总大小大于等于阈值S1小于等于阈值S2,其中阈值S1为小于缓冲区大小的某个值,阈值S2等于缓冲区的大小。
本发明中缓冲区的大小为64MB,阈值S1设为60MB,阈值S2设为64MB。假设文件池中按先后顺序排列有100个小文件,则从第1个文件开始遍历,如第一个文件为10MB,第二个文件为11MB,第三个文件为3MB,第四个文件为5MB,第六个文件为20MB,第七个文件为25MB,当遍历到第七个文件时,将第一个文件,第三个文件,第四个文件,第五个文件,第六个文件,第七个文件合并的值为63MB,而将第二个文件,第三个文件,第四个文件,第五个文件,第六个文件,第七个文件合并的值为64MB,因此,此时停止遍历,将第二个文件,第三个文件,第四个文件,第五个文件,第六个文件,第七个文件从100个文件中取出合并,并放入待上传队列中。然后继续重新遍历,遍历原先的第一个文件,第八个文件,第九个文件,直到有N个小文件合并后的大小在60MB到64MB之间,再将新的小文件合并放入待上传队列中,该合并文件位于上一个合并文件的后面。当文件池中又有新的小文件放入时,新的小文件从原100个小文件的最后一个文件后面开始排列。
步骤五:文件上传
将待上传队列中的合并文件依次上传到HDFS,即通过名称节点组和资源管理组分配文件存储块并存入HDFS中。合并文件上传后再次分解为小文件,采用分布式无关系型数据库Hbase存储小文件的元数据,并将Hbase数据持久化在HDFS中。采用分布式无关系型数据库Hbase存储小文件的元数据,具体为:以文件存储ID作为行键,建立Attr与Var两个列族,其中,列族Attr包括文件名(Name)、文件长度(Length)、文件存储ID(MapfileID)、文件存储块(BlockID)四个列;列族Var包括文件状态标志位(Status)、文件更新时间(UpdateTime)两个列。
用户将小文件上传后,可进行查询,详细步骤如下:
步骤一:首次请求
用户通过用户界面层的客户端浏览器提出第一次查询请求。此请求可以是待查询的文件名,上传时间,最后修改时间,上传者,文件大小等等。请求可以是这其中一项或几项,可以是一些比较模糊的关键词。
步骤二:处理请求
请求处理分两部分,分别为数值化和非数值化关键词的处理。
A:数值化关键词的处理
请求提交到业务逻辑层预处理器的网站服务器中,服务器根据查询请求,Web将数值化的数据构造出空间坐标后查询R树。R树可以执行范围查询或Top-K查询,查询的的输出为与查询请求相吻合或相似的小文件的数值化元数据。查询元数据到小文件名的映射表,得到对应的小文件名。
B:非数值化关键词的处理
对于非数值化的数据,需查询倒排索引。首先将查询字符串进行分词操作,用分词的结果查询倒排索引,得到包含此关键词文件编号,根据文件编号查询映射表得到对应文件名。
将A,B两步所返回的处理结果做AND操作,即“&”操作,得到首次查询的结果。
步骤三:返回初步查询结果
预处理器将经过首次查询得到的符合条件的小文件根据与查询请求的相关性排名后返回给用户。
步骤四:文件选择
用户选择感兴趣的小文件,查询全局映射文件,得到包含此小文件的合并文件名和待查询小文件在此合并文件中的偏移量及长度。
步骤五:返回最终结果
根据合并文件名向Hadoop发起查询请求,Hadoop将文件返回给预处理器。然后根据前一步得到的偏移量和长度切割合并文件,将得到的小文件返回给用户。查询结束。
一种实现海量小文件的高效上传HDFS的方法的系统,包括:接收单元,分类单元,标记单元,合并单元和上传单元,其中:
接收单元,用以接收需要上传的文件;
分类单元,将文件与Hadoop块的大小做对比,将文件分为小文件和普通文件两类,普通文件直接上传至HDFS;
标记单元,获取每个小文件的文件名、文件长度及文件上传时间戳;
合并单元,申请一定内存的缓冲区,将总大小与缓冲区大小近似的N个小文件进行合并,并移至待上传队列;
上传单元,将待上传队列中的文件上传至HDFS。
本发明通过建立文件池和对文件池中的数据进行预处理,衔接了Python的数据处理技术和Hadoop的块大小累加,并增加本地HDFS的上传程序,达到海量小文件的高效上传HDFS。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!