一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化方法及系统与流程
本发明涉及深度学习,高性能计算,GPGPU编程
技术领域:
,特别涉及一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化方法及系统。
背景技术:
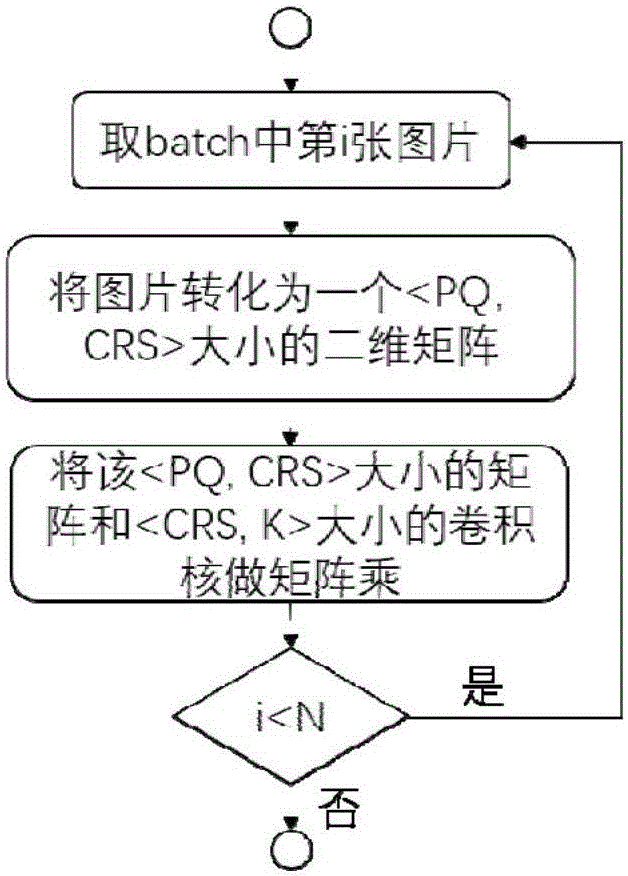
:随着人工智能浪潮的掀起,无人车,图像识别,语音识别等应用得到了广泛的推广,深度学习已经成为支持这些应用的重要模型训练手段,但是长期以来,由于深度学习的模型规模大,数据量多的问题,其训练速度较慢,难以得到普遍的使用,传统的深度学习系统采用大规模CPU,GPU分布式互联的方式来提升其速度,其中,“AndrewLavinandScottGray.FastAlgorithmsForConvolutionalNeuralNetoworks.Arxiv.CoRR,abs/1509.09308,2015.”提出了两种通用的并行模式:模型并行和数据并行,分别解决模型通信时间较长和数据量较大的情况。而“T.Chilimbi,Y.Suzue,J.Apacijble,andK.Kalyanaraman.Projectadam:Buildinganefficientandscalabledeeplearningtrainingsystem.11thUSENIXSymposiumonOperatingSystemsDesignandImplementation,2014.”利用上述并行手段设计了大规模的深度学习框架。在工业界,google发布了tensorflow框架,facebook维护了torch框架,此外开源社区还支持mxnet,caffe等深度学习框架,深度学习的软件框架已经相当成熟。最近,越来越多的关注集中到了用高性能的手段来优化深度学习的性能,传统的深度学习计算程序大多数依赖于现有的BLAS/CUBLAS高性能计算数学库,但这些数学库只提供了基本的运算函数,如矩阵乘,而深度学习中的卷积等运算如果用传统BLAS计算来实现就不能很好的利用计算资源,现有的GPU端的卷积操作的实现存在如下问题:Cudnn“https://developer.nvidia.com/cudnn”:不对外开源。基于矩阵乘的实现只能达到60%左右的峰值性能;基于FFT(快速傅里叶变换)的实现只针对stride=1(步长)的情况,不能通用而且需要大量的额外内存;缺少直接卷积算法实现。Neon“https://github.com/NervanaSystems/neon”:只针对MaxwellGPU实现了直接卷积算法,不能直接高效移植到KeplerGPU,并且在一些特殊的网络配置下性能低。Caffe“https://github.com/BVLC/caffe”:利用现有的BLAS运算,导致其需要额外内存并且效率十分低。技术实现要素:针对现有技术的不足,本发明提出一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化方法及系统。本发明提出一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化方法,将<N,C*R*S>大小的矩阵与<C*R*S,K>大小的矩阵相乘,获得<N,K>大小的输出元素,对N维度用bn做分块,对K维度用bk作分块,获得GPU的block维度为<<<P*Q,N/bx,K/by>>>,其中N为批处理图像数目,K为输出图像深度,C为输入图像深度,R为卷积核高度,S为卷积核宽度,P为输出图像高度,Q为输出图像宽度。还包括:步骤11,首先根据C*R*S与pad的信息,计算出在输入图像上对应取元素的起始地址,存储到GPU上的二级存储;步骤12,读取index信息,在输入图像上每次连续取S行bx个元素,取完R列以后,重复C次;步骤13,在filter取C*R*S行by个元素;步骤14,将步骤12取出的元素与步骤13取出的元素做矩阵乘运算;步骤15,在输出时每次输出一行bx个元素,重复k次。还包括:步骤21,在GPU上的二级存储开辟4个暂存空间smA、smB、smAx、smBx;步骤22,从GPU上的一级存储读取暂存空间smA大小的矩阵到暂存空间smA,读取暂存空间smB大小的矩阵到暂存空间smB;步骤23,每次从暂存空间smA加载一列元素到寄存器,从暂存空间smB加载一行元素到寄存器,做矩阵乘运算;步骤24,在做矩阵乘运算的同时,从GPU上的一级存储读取下一个暂存空间smA与暂存空间smB的一行到暂存空间smAx与暂存空间smBx;步骤25,做完暂存空间smA与暂存空间smB的矩阵乘以后,将暂存空间smA与暂存空间smAx地址互换,将暂存空间smB与暂存空间smBx地址互换。设置GPU处理器上的运算单元的大小为8。采用STS.128指令。本发明还提出一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化系统,包括优化模块,用于将<N,C*R*S>大小的矩阵与<C*R*S,K>大小的矩阵相乘,获得<N,K>大小的输出元素,对N维度用bn做分块,对K维度用bk作分块,获得GPU的block维度为<<<P*Q,N/bx,K/by>>>,其中N为批处理图像数目,K为输出图像深度,C为输入图像深度,R为卷积核高度,S为卷积核宽度,P为输出图像高度,Q为输出图像宽度。所述优化模块包括:步骤11,首先根据C*R*S与pad的信息,计算出在输入图像上对应取元素的起始地址,存储到GPU上的二级存储;步骤12,读取index信息,在输入图像上每次连续取S行bx个元素,取完R列以后,重复C次;步骤13,在filter取C*R*S行by个元素;步骤14,将步骤12取出的元素与步骤13取出的元素做矩阵乘运算;步骤15,在输出时每次输出一行bx个元素,重复k次。所述优化模块还包括:步骤21,在GPU上的二级存储开辟4个暂存空间smA、smB、smAx、smBx;步骤22,从GPU上的一级存储读取暂存空间smA大小的矩阵到暂存空间smA,读取暂存空间smB大小的矩阵到暂存空间smB;步骤23,每次从暂存空间smA加载一列元素到寄存器,从暂存空间smB加载一行元素到寄存器,做矩阵乘运算;步骤24,在做矩阵乘运算的同时,从GPU上的一级存储读取下一个暂存空间smA与暂存空间smB的一行到暂存空间smAx与暂存空间smBx;步骤25,做完暂存空间smA与暂存空间smB的矩阵乘以后,将暂存空间smA与暂存空间smAx地址互换,将暂存空间smB与暂存空间smBx地址互换。设置GPU处理器上的运算单元的大小为8。采用STS.128指令。由以上方案可知,本发明的优点在于:本发明相比传统的卷积过程简化了步骤,减少了调用次数,增加了数据局部性;避免额外延迟并可选取高效的向量指令,如STS.128,LDG.128减少bank冲突和增加带宽;可以达到75%的峰值性能,超过目前最优的cudnn实现20%-40%。附图说明图1为传统卷积图;图2为Caffe中调用矩阵乘的实现图;图3为处理batch数据的流程图;图4为减少冗余访存的卷积矩阵乘图;图5为使用向量内存指令的示意图。具体实施方式利用卷积可以实现对图像模糊处理,边缘检测,产生轧花效果的图像,我们规定下列符号表示:P输出图像高度Q输出图像宽度pad输入图像补0H输入图像高度W输入图像宽度stride步长C输入图像深度K输出图像深度N批处理图像数目input输入图像output输出图像filter卷积核可以得到如下公式:其中Ni:第i个batch,Ki:第j个深度,Hk:第k个高度,Wv:第v个宽度,r:filter上第r个高度偏移,s:filter上第s个宽度偏移因此传统卷积的过程如图1所示:我们发现传统的卷积算法每次计算的单元偏移量大,计算访存比低,导致其整体效率低。以下为传统GPU卷积算法,包括直接卷积实现[Caffe]中调用Cublas的矩阵乘将卷积过程转化为矩阵乘实现,其流程如图2所示:然而这种方法由于要多次调用矩阵乘函数,导致了冗余的访存,并且计算和访存不能重叠,效率低下,本发明简化了GPU上卷积的流程,利用GPU计算的并行性和自行设计的矩阵乘kernel,只需要一次调用就能处理一个batch的数据,如图3。本发明用图4说明具体怎样将卷积转化为矩阵乘的GPU形式,如图4所示:从公式中我们可以看出,output(输出图像)的每个元素是由input(输入图像)和filter(卷积核)的C*R*S个元素乘加得到的,并且在N,K维度互相独立,因此我们可以将这个过程转化为矩阵相乘的过程,即一个<N,C*R*S>大小的矩阵和一个<C*R*S,K>大小的矩阵相乘,得到<N,K>大小的输出元素,对N维度我们用bx做分块,对K维度我们用by作分块。因而,得到GPU的block(GPU处理器上的运算单元)维度为<<<P*Q,N/bx,K/by>>>,其中PQ=P*Q输出图片的大小。算法流程如下:步骤11,首先根据C,R,S和pad的信息,计算出在input上对应取元素的起始地址,存到sharedmemory(GPU上的二级存储)上。步骤12,读取index信息,在input上每次连续取S行bx个元素,取完R列以后,重复C次。步骤13,在filter取C,R,S行by个元素。步骤14,对取出的input和filter做矩阵乘运算。步骤15,在输出时我们每次输出一行bx个元素,重复k次。GPU上利用双缓冲矩阵乘算法如下步骤21,在sharedmemory上开辟4个暂存空间smA,smB,smAx和smBx;步骤22,从globalmemory(GPU上的一级存储)读取smA大小的矩阵到smA,读取smB大小的矩阵到smB;步骤23,每次从smA加载一列到寄存器,从smB加载一行到寄存器,做矩阵乘运算;步骤24,在做运算的同时,从globalmemory读取下一个smA和smB的一行到smAx和smBx;步骤25,做完smA和smB的矩阵乘以后,将smA和smAx地址互换,将smB和smBx地址互换。矩阵乘内核是卷积中指令最多的部分,因此优化好它的性能就可以提升整个卷积过程的性能。在指令选取的过程中,我们主要需要考虑到指令延迟,指令通量,寄存器使用,和发射模式的问题。以下为本发明中寄存器数目:理论上来说,计算中用来储矩阵的寄存器存越多,效率越高,因为这样可以减少内存读取,增加计算访存比,但是,寄存器使用多了以后,会导致activeblocks(GPU处理器上可并发的处理单元数目)变少,因而导致sharedmemory上的带宽成为瓶颈“Zhang,Yao,andJ.D.Owens."AquantitativeperformanceanalysismodelforGPUarchitectures."8.1(2011):382-393”,因此我们需要在尽量使用较多寄存器的情况下,增加activeblocks的数目。由于我们需要使用至少18个寄存器来计算input和filter的偏移,并且需要register_block(寄存器矩阵的边长)*4+register_block^2个寄存器来加载双缓冲和矩阵,在256个线程的情况下,我们最大可以使得register_block=13,但是registe_block需要满足偶数对齐来使用向量加载指令,因而我们可选的register_block={2,4,6,8,10,12},当register_block={4,6,8}的时候,我们可以利用两个activeblocks,因此我们选取blocksize=8来隐藏额外的计算和访存延迟。以下为本发明中FFMA(乘加指令)双发射使用FFMA1-2-2-1发射的模式在KeplerGPU上具有最高的性能,我们采取了相同的方式,但是由于我们的寄存器矩阵只有8x8,会导致可用的空闲指令插槽减少,延迟增加,在实际效果中,由于多个activewarps的存在,可以隐藏部分延迟,同样达到较高的性能。以下为本发明中STS.128(sharedmemory128位存储指令)我们使用STS.128指令因为其相比STS.64指令和STS.32指令的通量更高,并且使用的指令更少,此外,如图5,假设字长为32比特,通过分析发现STS.128可以通过一次操作存储128*8个数据(256线程),导致一个warp内4路bankconflict。使用STS.32需要四次操作存储,使用STS.64需要两次操作,虽然STS.64和STS.32造成的bankconflict较小,但是说需要的指令较多,在指令插槽较小的情况下,会增加整体的指令延迟。因此我们采取只需要一次调用的STS.128指令。以下为本发明中LDS.64(sharedmemory64位读取指令)我们使用LDS.64指令因为他的通量更高,并且在64比特字长的配置下不存在sharedmemorybankconflict。以下为本发明中LDG.128(globalmemory128位读取指令)我们使用LDG.128指令,虽然LDG.128要求地址是128的整数倍,在深度学习中N,K,C等参数通常都满足条件。即使不满足,我们也可以通过补0的方式来达到这个效果,所以我们可以用通量更高的LDG.128指令。本发明还提出一种利用NVIDIAKeplerGPU汇编指令加速的卷积优化系统,包括优化模块,用于将<N,C*R*S>大小的矩阵与<C*R*S,K>大小的矩阵相乘,获得<N,K>大小的输出元素,对N维度用bn做分块,对K维度用bK作分块,获得GPU的block维度为<<<P*Q,N/bx,K/by>>>,其中N为批处理图像数目,K为输出图像深度,C为输入图像深度,R为卷积核高度,S为卷积核宽度,P为输出图像高度,Q为输出图像宽度。所述优化模块包括:步骤11,首先根据C*R*S与pad的信息,计算出在输入图像上对应取元素的起始地址,存储到GPU上的二级存储;步骤12,读取index信息,在输入图像上每次连续取S行bx个元素,取完R列以后,重复C次;步骤13,在filter取C*R*S行by个元素;步骤14,将步骤12取出的元素与步骤13取出的元素做矩阵乘运算;步骤15,在输出时每次输出一行bx个元素,重复k次。所述优化模块还包括:步骤21,在GPU上的二级存储开辟4个暂存空间smA、smB、smAx、smBx;步骤22,从GPU上的一级存储读取暂存空间smA大小的矩阵到暂存空间smA,读取暂存空间smB大小的矩阵到暂存空间smB;步骤23,每次从暂存空间smA加载一列元素到寄存器,从暂存空间smB加载一行元素到寄存器,做矩阵乘运算;步骤24,在做矩阵乘运算的同时,从GPU上的一级存储读取下一个暂存空间smA与暂存空间smB的一行到暂存空间smAx与暂存空间smBx;步骤25,做完暂存空间smA与暂存空间smB的矩阵乘以后,将暂存空间smA与暂存空间smAx地址互换,将暂存空间smB与暂存空间smBx地址互换。设置GPU处理器上的运算单元的大小为8。本发明系统采用STS.128指令。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1