一种局部加权极限学习机模型的工业过程软测量建模方法与流程
本发明属于工业过程预测和控制领域,尤其涉及一种局部加权极限学习机的软测量建模方法。
背景技术:
在传统工业过程中,存在许多对于提高产品质量和保证安全有着至关重要作用过的参数如反应速率、产品成分含量等,但是很多往往难以或者无法直接用传感器加以测量。采用需要大量投资的在线分析仪表进行检测,往往有较大的滞后而使得调节不够及时,从而使产品质量难以得到保证。我们称这些对于工业过程具有重要作用的变量为主导变量,其他的一些已与测量的变量我们称之为辅助变量。软测量实质事通过建立工业过程变量之间的数学模型,实现通过辅助变量预测主导变量的技术方法。在近年来,软测量在工业过程中应用了许多神经网络算法,但是由于神经网络算法仍存在收敛速度较慢,容易陷入局部最优解和泛化性能较差等缺点。
为了克服神经网络算法存在的上述问题,极限学习机作为一种单隐层随机神经网络,能够克服传统神经网络算法反迭代产生的收敛速度慢,陷入局部最优解问题。但是由于其模型的随机性和隐层节点数目往往大于其他神经网络牺牲了泛化性能。为解决这一问题,提出了局部加权极限学习机模型,利用即时学习的思想,通过局部加权的方法,改善了极限学习机模型作为一种非线性方法应用于工业过程极限学习机泛化能力较差的缺点,针对工业过程数据动态性的问题,改善了模型建立和预测的性能。
技术实现要素:
本发明的目的在于针对现有技术的不足,提出一种局部加权极限学习机的软测量建模方法。
本发明的目的是通过以下技术方案来实现的:一种基于局部加权极限学习机的软测量模型的建立,主要包括以下几个步骤。
(1)利用集散控制下系统以及离线监测方法,工业生产过程的数据按时间排列的训练样本集Xtr∈RN×n和Ytrain∈RN×m和测试样本集Xte∈RK×n和Ytest∈RN×m。其中N为训练样本长度,n为训练样本维度,K为测试样本集长度。测试样本集为将这些数据存入历史数据库。并且对训练样本集和测试样本按照训练样本集进行前处理和归一化使训练样本集其均值为0且方差为1。
(2)将测试样本Xtest依次取行作为查询样本qi(i=1,2,…,K),及对应测试样本真实值yi(i=1,2,…,K)。之后按每个查询样本分别进行局部加权极限学习机建模。
(3)对查询样本和训练集进行去查询样本均值。这部分去均值的值要在建模并得到建模结果后再在最终结果上还原去查询均值的数据偏差。
(4)依据查询样本和历史样本(训练集样本)的距离d确定权重参数w,对历史样本加权,得到新的训练样本Xw的到局部加权化的样本空间。
(5)对局部加权化的样本空间进行极限学习机建模,得到软测量结果。
(6)重复进行所有的查询样本向量的建模和软测量结果后得到了整个测试样本的软测量结果。
(7)采用以上得到的基于局部加权极限学习机方法对工业过程的数据进行建模,实现过程的软测量。
本发明的有益效果是:本发明采用即时学习思想,使用局部加权方法建立局部模型,改善极限学习机作为一种高速度高精度非线性方法在工业过程中由于样本空间有限产生的泛化性能不足的问题。极限学习机拥有良好的建模速度和回归精度,但往往在工业过程中对样本空间不足的情况下泛化性能非常敏感,通过局部加权方法建立局部模型,可以有效的增强算法的泛化性能,而且在结合过程中局部加权方法也能在一定程度上解决极限学习机没有降噪过程的问题,而且可以降低及极限学习机在实际过程中的不稳定性。得到了高速度高精度的工业过程非线性特点的软测量器。
附图说明
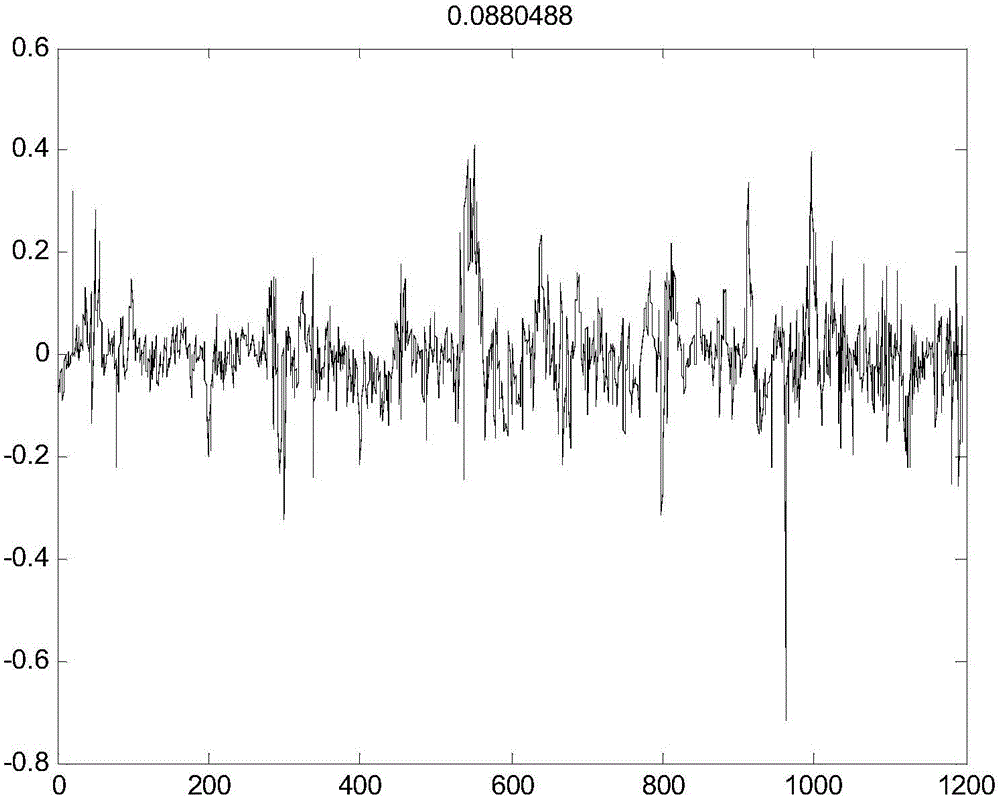
图1是极限学习机脱丁烷塔软测量误差图;
图2是局部加权极限学习机脱丁烷塔软测量误差图。
具体实施方式
本发明是针对工业过程非线性问题,使用即时学习思想通过空间上的局部加权方法简化非线性性的问题,再结合极限学习机算法作为一种非线性算法解决过程非线性问题。局部加权方法可以提升模型的泛化能力,并在一定程度上可以降低噪声该绕和降低极限学习机不稳定性。本方法既能够实现局部加权方法对工业过程动态性的提取和建模,也能体现出极限学习机作为一种非线性回归算法精度高、速度快的优势。
下面结合附图和具体实例对本发明进行详细说明。
本发明采用的技术方案主要步骤如下:
第一步 利用集散控制下系统以及离线监测方法,工业生产过程的数据组成建模用的训练样本集和测试样本集。其中,训练样本集包括Xtr∈RN×n和Ytrain∈RN×m,其中,N为训练样本长度,n为训练样本维度。测试样本集为Xte∈RK×n和Ytest∈RN×m将这些数据存入历史数据库,其中,K为测试样本长度,n为训练样本维度。并且对训练样本集和测试样本按照训练样本集进行前处理和归一化使训练样本集其均值为0且方差为1。
第二步 将测试样本Xtest依次取行作为查询样本,即为(q1,q2,…qi…qK),其中qi为查询样本,n维行向量。分别对应测试样本真实值yi(i=1,2,…,K)。从第一行(i=1)到最后一行分别进行局部加权极限学习机建模。
第三步 当查询样本为qi(i=1,2,…,K)时,对查询样本和训练集进行去查询样本均值。这部分去均值的值要在建模并得到建模结果后再在最终结果上还原去查询均值的数据偏差。
第四步 将训练样本集中Xtrain分解为行量形式,将中各个xj作为历史样本(j=1,2,…,N),即可对各个历史样本和查询样本qi的相似度或点的距离进行度量然后可以对相似样本制定权重其中为设定的局部加权参数。得到所有权重W=[w1,w2,...wN]。将输入神经网络的输入值更换为之后使用极限学习机进行建模。
第五步 极限学习机是一种单隐层随机神经元网络,随机生成C个隐神经元节点g(ai,bi)的所有参数(a1,b1)(a2,b2)…(aC,bC)生成好后,依照单层神经网络的输出公式此公式也可写成:
Hβ=T,其中β为神经元输出权重矩阵,T为神经网络输出结果,
为追求使得误差|T-Y|2最小,可得到权重矩阵计算公式β=H+T。得到的神经网络的权重β加上之前随机生成的节点参数ai,bi就是整个极限学习机的神经网络参数。
第六步 重复以上步骤,每次得到一个查询样本局部加权极限学习的预测值,重复进行所有的查询样本向量的建模和软测量结果后得到了整个测试样本的软测量结果。
第七步 采用以上得到的基于局部加权极限学习机方法对工业过程的数据进行建模,实现过程的软测量。
以下结合一个具体的脱丁烷塔例子来说明本发明的有效性。针对该过程,一共采集了2394个数据,其中1197个数据用来建模,并对其对应的丁烷含量值进行离线分析和标记。另外采集的1197个数据样本用来验证软测量模型的有效性。在该过程中,一共选取了7个过程变量对该过程的丁烷含量进行软测量建模,这7个过程变量分别为塔顶温度、塔顶压力、回流流量、下一级流量、灵敏板温度、塔底温度和塔底压力。接下来结合该具体过程对本发明的实施步骤进行详细地阐述:
1.数据前处理,对2394个建模样本中的过程变量和丁烷含量进行预处理和归一化,使得各个过程变量和关键变量的均值为零,方差为1,得到新的建模数据矩阵。
2.基于局部加权极限学习机的软测量建模
将选取的过程过程变量组成的数据矩阵作为软测量模型的输入,丁烷含量数据矩阵作为软测量模型的输出,按照实施步骤中给出的详细方法,对每个测试样本点建立相关的局部加权极限学习机的软测量模型。
3.对全部样本集的数据进行建模和预测
为了测试新方法的有效性,我们对2394个测试样本均进行局部建模和软测量预测,得到软测量结果后进行比对和研究。
4.丁烷含量的软测量建模预测比较
对2394个验证样本进行在线软测量,获得相应的在线估计值。应用极限学习机方法针对2394个验证样本的在线软测量,平均误差为0.130686。应用本发明局部加权的极限学习机软测量模型对相同样本进行的软测量,平均误差为0.0890488。可以看出局部加权极限学习机降低了预测的误差,提升了软侧脸模型的精度。
上述实施例又来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明最初的人和修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!