一种侧抑制的随机分形搜索模板匹配方法与流程
本发明属于图像处理技术领域,尤其涉及一种侧抑制的随机分形搜索模板匹配方法。
背景技术:
模板匹配是指在目标图像中寻找与给定模板相同或相似区域的过程,是计算机视觉基础方法之一,并且在面部识别,肺结节检测,笔迹识别和道路检测等多个领域等到了广泛的应用。模板匹配技术涉及将模板翻译成原始图像中的每个可能的位置,以及评估模板和该位置处的原图像之间的匹配。模板匹配方法主要分为两类:基于灰度方法的匹配和基于特征方法的匹配。基于灰度方法的匹配是基于灰度值,通过不同准则检测模板与目标图像部分相似性。基于特征方法的匹配通过提取两幅或多幅图像的颜色、纹理、形状等特征,并进行描述,然后根据描述参数匹配。通过和基于特征方法匹配的比较,基于灰度方法的匹配能够提供更好的性能,并且有更好的抑制噪声的能力。在近些年,研究者已经转变他们的研究兴趣朝向智能算法的应用,例如人工蜂群算法(Artificial bee colony,ABC),和它的变体(internal-feedback artificial bee colony,IFABC)(balance-evolution artificial bee colony,BEABC),物质状态搜索算法(States of matter search algorithm,SMS),和帝国主义竞争算法(imperialist competitive algorithm,ICA)已经被提出为模板匹配问题。虽然这些算法旨在减少全局优化搜索的计算量,但它们都不能完全保证推导出次优匹配结果。值得注意的是大多数群智能算法普遍适应于凸函数或接近凸函数的优化。然而,模板匹配领域包含许多有限的可行的匹配位置。这样一个离散的函数是不光滑的,但事实上它是极端病态的。换句话说,沿着这个域的解的表面可能出现大幅度的摆动,它严重制约了智能算法的优势。随机分形搜索算法(Stochastic fractal search algorithm,SFS)是由H.Salimi提出的一种新的全局优化算法,它源于对随机分形的模拟。由于SFS算法具有快的收敛速度和高的搜索精度,受到了越来越多的关注。SFS算法已经成功的用于框架结构优化问题,目标识别,精确轨道优化,分布式数据库查询优化等。因此,在基于灰度的模板匹配中为了更好地适应匹配过程中可行域搜索空间的离散性和振荡,同时,为避免在搜索最优匹配解的过程中陷入局部最优而导致整个群体出现搜索停滞,采用SFS算法搜索匹配的最优解。在7个测试图像上将SFS算法与其他优化算法进行对比,实验结果表明SFS算法能够更好地解决模板匹配问题。
综上所述,搜索最优匹配解时所带来的技术问题是匹配过程中可行域搜索空间的离散性和振荡,从而使搜索算法易陷入局部最优而导致整个群体出现搜索停滞。
技术实现要素:
本发明的目的在于提供一种侧抑制的随机分形搜索模板匹配方法,旨在解决在搜索最优匹配解的过程中陷入局部最优而导致整个群体出现搜索停滞,匹配过程中可行域搜索空间的离散性和振荡,从而使搜索算法易陷入局部最优而导致整个群体出现搜索停滞的问题。
本发明是这样实现的,一种侧抑制的随机分形搜索模板匹配方法,所述侧抑制的随机分形搜索模板匹配方法包括以下步骤:
步骤一,图像预处理,导入原图像和模板图像(均为RGB形式),用rgb2gray将它们转化为灰度图像;运用侧抑制机制对图像进行预处理,该机制能有效进行背景抑制和目标增强,从而减少图像噪声,提高信噪比。
步骤二,LI-SFS参数初始化,初始化种群的规模N,问题的维度D,最大的迭代次数MaxFEs,D表示图像的维度等于2;
步骤三,最大的扩散次数设置为1;
步骤四,应用高斯游走方法解决模板匹配问题;
步骤五,更新搜索个体的位置;在经过两次更新过程之后,获得最优个体。
进一步,所述高斯游走过程如下:
GW1=Gaussian(μBP,σ)+(ε×BP-ε′×Pi);
GW2=Gaussian(μP,σ);
ε和ε'是[0,1]之间的随机数,BP是最优粒子的位置;Pi是第i个粒子点。μBP,μP,σ是高斯参数,μBP等于BP,μP等于Pi;标准偏差如下:
优化的是一个D维的问题,则每个粒子个体是一个D维的向量;在初始化阶段,随机初始化每个粒子;每个粒子个体的维度是D=2;第j个粒子的位置Pj的初始化过程如下:
Pj=LB+ε×(UB-LB);
LB和UB分别是问题约束向量的下界和上界;初始化之后,计算每个粒子点的适应度值,目的在于获得最好的粒子点的位置BP;依据每个个体的适应度值排序所有粒子点;每个粒子点i通过下式分配一个概率:
rank(Pi)是粒子点Pi的排序,N是种群的规模;对于种群中的每个粒子点Pi,如果Pai<ε,个体Pi的第j个分量用下式进行更新,否则保持不变:
Pi(j)=Pr(j)-ε×(Pt(j)-Pi(j));
Pi'是Pi更新后的位置,Pr和Pt是种群中随机挑选的粒子点,ε是在[0,1]之间的随机数。
根据获得的所有粒子点进行排序,如果Pai<ε,根据下式更新Pi'的位置,否则不更新;
Pt'和Pr'是从第一个步骤中挑选的随机点,由高斯分布产生;如果新的粒子点Pi″的适应度值优于Pi',则用Pi'替换Pi″。
进一步,所述应用侧抑制机制根据公式预处理图像包括:
侧抑制网络的竞争系数是:
由于视觉神经细胞位于相同的输入平面,并且竞争系数接近于0,侧抑制系数模板满足:
α0+8α1+16α2=0;
选择α0=1,α1=-0.075,α2=-0.025构成以下矩阵作为模量:
通过结合系数模板U和R(m,n),获得图像新的灰度值;最后,根据下式提取图像的边缘:
T是用户根据实际情况自定义的阈值,F(m,n)是最终获得的像素(m,n)的灰度值。
进一步,所述侧抑制的随机分形搜索模板匹配方法的适应度值函数如下:
fitness是模板图像和在原图中开始点是像素(m,n)的图案之间的相似度;(m+i,n+j)和(i,j)分别代表原图像和模板图像中像素的坐标;F(m+i,n+j)和Ft(i,j)是处理过的像素(m+i,n+j)和(i,j)的灰度值;M×N是原图像的尺寸,P×Q是模板图像的尺寸,在原图像中进行匹配的坐标的范围是1≤m≤M-P+1和1≤n≤N-Q+1。
本发明的另一目的在于提供一种利用所述侧抑制的随机分形搜索模板匹配方法的面部识别系统。
本发明的另一目的在于提供一种利用所述侧抑制的随机分形搜索模板匹配方法的肺结节检测系统。
本发明的另一目的在于提供一种利用所述侧抑制的随机分形搜索模板匹配方法的笔迹识别系统。
本发明的另一目的在于提供一种利用所述侧抑制的随机分形搜索模板匹配方法的道路检测系统。
本发明提供的侧抑制的随机分形搜索模板匹配方法,随机分形搜索算法是一个新的元启发式算法,它是受到随机分形的启发。此外,侧抑制对图像边缘提取和图像增强有好的效果;侧抑制用于图像的预处理过程。本发明与其它基于侧抑制的算法进行对比,实验结果表明在模板匹配问题中,本发明有更好的效果和鲁棒性。在SFS算法进行模板匹配之前,侧抑制(lateral inhibition,LI)方法用于预处理原图像和模板图像;混合的方法被称为LI-SFS;侧抑制是在鲎的腹眼进行电生理实验时发现的;对在杂乱的背景下去探测目标有很大的帮助,能够增强感觉信息的对比和减少低频率噪声。因此,在基于灰度的模板匹配中为了更好地适应匹配过程中可行域搜索空间的离散性和振荡,同时,为避免在搜索最优匹配解的过程中陷入局部最优而导致整个群体出现搜索停滞,采用SFS算法搜索匹配的最优解。在7个测试图像上将SFS算法与其他优化算法进行对比,实验结果表明SFS算法能够更好地解决模板匹配问题。
附图说明
图1是本发明实施例提供的侧抑制的随机分形搜索模板匹配方法流程图。
图2是本发明实施例提供的LI-SFS模板匹配流程图。
图3-图9是本发明实施例提供的不同图像的收敛曲线图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
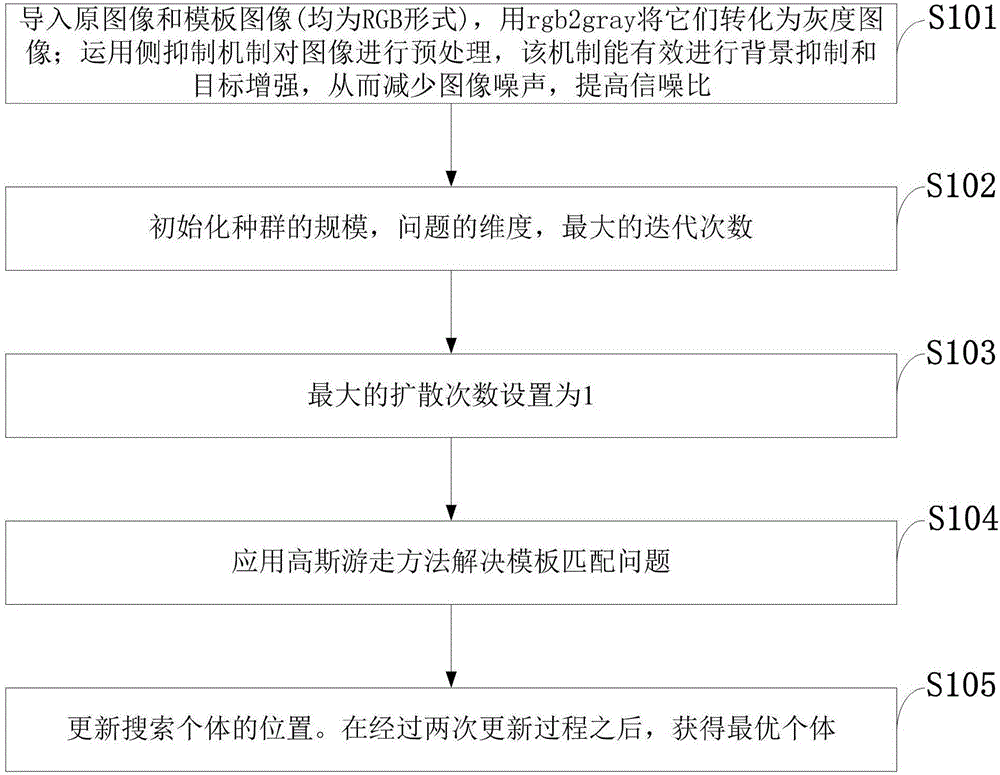
如图1所示,本发明实施例提供的侧抑制的随机分形搜索模板匹配方法包括以下步骤:
S101:导入原图像和模板图像(均为RGB形式),用rgb2gray将它们转化为灰度图像;运用侧抑制机制对图像进行预处理,该机制能有效进行背景抑制和目标增强,从而减少图像噪声,提高信噪比;
S102:初始化种群的规模,问题的维度,最大的迭代次数;
S103:最大的扩散次数设置为1;
S104:应用高斯游走方法解决模板匹配问题;
S105:更新搜索个体的位置。在经过两次更新过程之后,获得最优个体。
下面结合具体实施例对本发明的应用原理作进一步的描述。
1 SFS算法
SFS算法是由H.Salimi提出的一个新的元启发优化算法,它是受到随机分形的启发。SFS算法有两个主要的过程:扩散过程和更新过程。在第一个过程中,每个粒子为确保开采的性能围绕当前的位置进行扩散。随着这个过程的执行,算法实现全局最优化的机会大大增加,同时避免算法陷入局部最优。对SFS算法,认为它是一个静态的扩散过程,即只有从扩散过程中产生的最好的粒子被考虑。此外,SFS算法用一些随机更新过程去增强算法的探测能力。为了产生新的粒子,高斯游走的统计方法被应用去产生一个全局最优解。在扩散过程中一系列的高斯游走过程如下:
GW1=Gaussian(μBP,σ)+(ε×BP-ε'×Pi) (1)
GW2=Gaussian(μP,σ) (2)
ε和ε'是[0,1]之间的随机数,BP是最优粒子的位置。Pi是第i个粒子点。μBP,μP,σ是高斯参数,μBP等于BP,μP等于Pi。标准偏差如下:
假设优化的是一个D维的问题,则每个粒子个体是一个D维的向量。在初始化阶段,随机初始化每个粒子。每个粒子个体的维度是D=2。第j个粒子的位置Pj的初始化过程如下:
Pj=LB+ε×(UB-LB) (4)
LB和UB分别是问题约束向量的下界和上界。初始化之后,计算每个粒子点的适应度值,目的在于获得最好的粒子点的位置BP。依照扩散过程中的开采性能,所有的粒子点围绕它们当前的位置对问题空间进行开采。为了更好的增加算法的探测能力,两个统计的步骤被执行。第一个统计方法应用于每个个体向量中,而第二个方法作用在所有粒子点上。首先,在第一个统计步骤中,依据每个个体的适应度值排序所有粒子点。每个粒子点i通过式(5)分配一个概率:
rank(Pi)是粒子点Pi的排序,N是种群的规模。根据式(5)可知,个体排序越高,被选择的概率就越大。对于种群中的每个粒子点Pi,如果Pai<ε,个体Pi的第j个分量用式(6)进行更新,否则保持不变。
Pi'(j)=Pr(j)-ε×(Pt(j)-Pi(j)) (6)
Pi'是Pi更新后的位置,Pr和Pt是种群中随机挑选的粒子点,ε是在[0,1]之间的随机数。
第一个更新统计步骤作用在所有粒子点的分量上,而第二个更新步骤应用于一个粒子点的位置上,这个粒子点改变需考虑种群中其它粒子点的位置。通过这种方法,算法探测能力得到了提高,种群的多样性得到了满足。在执行第二个步骤之前,根据第一个更新步骤获得的所有粒子点根据式(5)进行排序。和第一个统计步骤类似,如果Pai<ε,根据式(7)和(8)更新Pi'的位置,否则不更新。
Pt'和Pr'是从第一个步骤中挑选的随机点,由高斯分布产生。如果新的粒子点Pi″的适应度值优于Pi',则用Pi'替换Pi″。
随机分形搜索算法伪代码如下:
2侧抑制机制
Hartline等人发现鲎的腹眼中的每一个小眼可以看做是一个感受器,感受器周围邻近的感受器对其有抑制性作用,并且这种抑制性影响存在空间总和效应。同时,距某一感受器较近的感受器对它的抑制作用要比远一些的感受器的作用强。侧抑制在图像处理中主要有以下功能:(1)可以检测到图像的边缘,突出边框,增强反差;(2)高通滤波器,将很大的输入变化范围压缩到网络本身的动态范围之内。(3)对屈光系统所引起的成像模糊进行补偿,使模糊图像变得清晰;(4)可以对图像的细微间断进行拟合,具有明显的聚类作用。应用这一机制对模板图像和原图像进行预处理,目的在于提高空间分辨率,增加模板匹配的有效性和准确性。
经典的侧抑制模型如下所示:
为了将此机制应用于图像处理,将模型修改为二维的灰度形式。图像中像素(m,n)的灰度值表达式为:
ai,j是像素(i,j)到中间像素的侧抑制系数,I0(m,n)表示像素(m,n)的原灰度值,R(m,n)是像素(m,n)通过侧抑制处理之后的灰度值,M×N表示可接受领域的面积。
文中,采用接受领域的面积是5×5。侧抑制网络的竞争系数是:
由于视觉神经细胞位于相同的输入平面,并且竞争系数接近于0,侧抑制系数模板满足:
α0+8α1+16α2=0 (12)
选择α0=1,α1=-0.075,α2=-0.025构成以下矩阵作为模量:
通过结合系数模板U和R(m,n),可以获得图像新的灰度值。最后,根据式(14)提取图像的边缘:
T是用户根据实际情况自定义的阈值,F(m,n)是最终获得的像素(m,n)的灰度值。
3SFS算法和侧抑制方法
3.1LI-SFS的适应度值函数
本发明用LI-SFS算法执行搜索的任务。基于灰度互关联的模板匹配有强的抑制噪声的能力和计算简单的性能,但它是非常耗时的。根据文献[Zhang Z,Duan H(2014)A hybrid Particle Chemical Reaction Optimization for biological image matching based on lateral inhibition.Optik-International Journal for Light and Electron Optics 125(19):5757-5763,Wang X,Duan H,Luo D(2013)Cauchy biogeography-based optimization based on lateral inhibition for image matching.Optik-International Journal for Light and Electron Optics 124(22):5447-5453]的选择准则,模板匹配的适应度值如下所示:
fitness是模板图像和在原图中开始点是像素(m,n)的图案之间的相似度。所以fitness的最大值表示模板匹配问题的最好解。这种相似度测量方法能够减少计算时间且容易编程实现。(m+i,n+j)和(i,j)分别代表原图像和模板图像中像素的坐标。F(m+i,n+j)和Ft(i,j)是由式(14)处理过的像素(m+i,n+j)和(i,j)的灰度值。如果M×N是原图像的尺寸,P×Q是模板图像的尺寸,在原图像中进行匹配的坐标的范围是1≤m≤M-P+1和1≤n≤N-Q+1。因此,在实验中定义low1=1,low2=1,up1=M-P+1,up2=N-Q+1。
3.2 LI-SFS算法
LI-SFS算法融合了SFS算法的有效性和侧抑制机制的精确性。LI-SFS算法的主要步骤如下:
步骤1:图像预处理
导入原图像和模板图像(均为RGB形式),用rgb2gray将它们转化为灰度图像;运用侧抑制机制对图像进行预处理,该机制能有效进行背景抑制和目标增强,从而减少图像噪声,提高信噪比。
步骤2:LI-SFS参数初始化
初始化种群的规模N,问题的维度D,最大的迭代次数MaxFEs,文中,D表示图像的维度等于2。
步骤3:扩散过程
在SFS算法中,最大的扩散次数设置为1。
步骤4:高斯游走方法
应用第一个高斯游走方法解决模板匹配问题。
步骤5:更新过程
更新搜索个体的位置。在经过两次更新过程之后,获得最优个体。
LI-SFS算法模板匹配流程图如图2所示:
下面结合实验对本发明的应用效果作详细的描述。
实验结果及对比分析
为了调查算法的性能,将SFS算法与其它4种算法对比,分别是IFABC[Li B,Gong,L G,Li Y(2014)A novel artificial bee colony algorithm based on internal-feedback strategy for image template matching.The Scientific World Journal,Volume 2014(2014),Article ID 906861,14pages],BEABC[Li B(2016)An Evolutionary Approach for Image Retrieval Based on Lateral Inhibition.Optik-International Journal for Light and Electron Optics,doi:10.1016/j.ijleo.2016.02.0562],SMS[Cuevas E,Echavarría A,Zaldívar D,Pérez-Cisneros M(2013)A novel evolutionary algorithm inspired by the states of matter for template matching.Expert Systems with Applications 40(16):6359-6373],ICA[Huang L,Duan H,Wang Y(2014)Hybrid bio-inspired lateral inhibition and imperialist competitive algorithm for complicated image matching.Optik-International Journal for Light and Electron Optics 125(1):414-418]。该实验的运行环境为:Windows 7;CPU:Inter Core i5-4590;主频:4×3.30GHZ;内存:4GB;集成开发环境:Matlab R2012a。所有测试图像均来自Google
实验中,种群的规模设置为100,最大的迭代次数设置为300。
各对比算法的参数设置如下:
(1)LI-IFABC
α=0.1,Limit=10
(2)LI-BEABC
Limit=10
(3)LI-SMS
气体ρ∈[0.8,1],β=0.8,α=0.8,H=0.9;液体ρ∈[0.3,0.6]β=0.4,α=0.2,H=0.2;固体ρ∈[0,0.1],β=0.1,α=0,H=0.
(4)LI-ICA
国家个数NumOfCountries=100,帝国主义国家个数NumOfImper=10,殖民地个数NumOfColony=90.
(5)LI-SFS
最大扩散次数MDN=1
图像边缘提取的阈值设置为T=110。实验的设计目的在于把模板图像成功的匹配到原图像中。固定在原图像中的模板图像的坐标决定匹配是否成功。实验结果展现在表1中,它们是50次独立实验的平均值。最优的结果用加粗的字体表示。分析比较考虑四个性能指标:平均值(Avg),平均迭代收敛次数,正确率,和平均的CPU时间。所有的性能指标结果是50次独立运行的平均值,目的在于确保统计的一致性。
为更加客观的评价LI-SFS算法与对比算法在每个测试事例上的性能差异程度,应进行统计检验[Derrac J,García S,Molina D,Herrera F(2011)A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms.Swarm and Evolutionary Computation 1(1):3-18]。采用Wilcoxon秩和检验方法[Gibbons JD,Chakraborti S(2011)Nonparametric statistical inference.Springer Berlin Heidelberg,pp 977-979,Hollander M,Wolfe DA,Chicken E(2013)Nonparametric statistical methods.John Wiley and Sons]对匹配结果的最优值数据进行统计分析,显著水平为0.05。LI-SFS算法和其它算法在所有测试实例上的p值结果见表2。表2中,N/A表示“不适用”,意思是没有进行统计的测试,因为两个算法在独立试验中都成功的找到了匹配的最优值。通常,p<0.05可以认为是反对无效假设的有力证据。
表1LI-SFS算法和其它算法的比较优化结果
表2LI-SFS算法和其它算法对比获得的p值结果(p≥0.05被划线标注)
表1显示所有图像的测试结果。从表1可以看出,对于图像,就平均值,平均迭代次数,正确率而言,LI-SFS算法优于其他算法。LI-SFS算法的平均迭代次数是67,而LI-IFABC是106,LI-BEABC是94,LI-SMS是291,LI-ICA是133,显然,LI-SFS拥有最快的收敛速度。从图3可以看出,对于平均值和正确率,LI-BEABC和LI-SFS都能获得最好的值。从以上分析,可以得出在解决模板匹配问题时,LI-SFS算法性能更优。
此外,LI-SFS相比其他算法通常消耗更少的时间。这是因为LI-SFS算法既没引入额外的策略,也没有改变普通算法的框架。
根据表2中的p值,对于图像,相比其他算法,LI-SFS有显著提高。
侧抑制能够加强图像的细节,提高匹配的成功率。从匹配的结果,可以清晰地看出LI-SFS算法能够成功地找到固定在原图像中的模板图像的精确位置。
图3-图9显示对所有图像执行50次独立运行后得到的所有算法的平均收敛曲线。从图4和图6-图9可以看出,LI-SFS拥有最快的收敛速度。通过仔细地观察图3和图5,LI-ICA有一个快速的收敛速度朝向已知的最大值,但是分别在第50次和第60次迭代之后,LI-SFS优于LI-ICA;随着程序的执行,LI-SFS越来越接近最大值,然而,LI-ICA出现早熟,陷入局部极大值中。
经过综合的分析,SFS算法优越的探测和避免局部最大的性能能够在不同的情况下有效地,精确地解决复杂的模板匹配问题。
模板匹配在模式识别,图像分析,和计算机视觉中是一个基本而重要的问题。模板匹配的主要问题是确定一个有效的方法描述图像的特征和测量两个图像之间的相似度。本发明的创新在于应用SFS算法处理基于LI的模板匹配问题。将SFS算法与其它智能算法进行比较,实验结果清晰地显示出SFS算法的有效性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!