一种基于变量名混淆程度的脚本启发式检测方法及系统与流程
本发明涉及计算机网络安全领域,特别涉及一种基于变量名混淆程度的脚本启发式检测方法及系统。
背景技术:
近年来,恶意脚本呈爆炸趋势增加,其中大量脚本使用了种类繁多的混淆手段,以避免反病毒引擎的查杀,增加了分析人员的时间成本和反病毒引擎的检测难度。因此对于混淆脚本的检测能力,成为了对抗恶意脚本的一项关键能力。
传统的脚本检测方式是,检测程序模拟脚本的解释执行,得到其可能的执行路径。这种方法需要针对每种脚本需要开发专门的虚拟执行引擎,实现较为复杂,具有很高的开发和维护成本;并且在检测过程中,还可能消耗大量存储空间与计算资源,通常运行效率也不高。
技术实现要素:
本发明就是要解决以上问题,提出一种基于变量名称混淆程度的脚本启发式检测方法及系统,根据变量名称的混淆程度,高效快速判断恶意脚本。
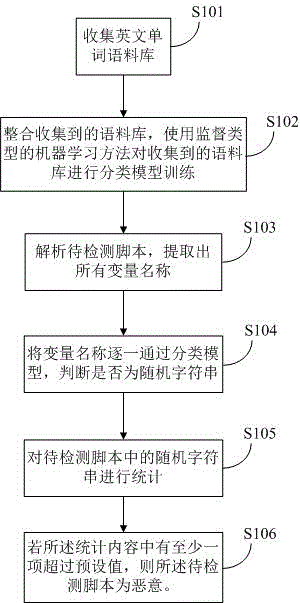
一种基于变量名混淆程度的脚本启发式检测方法,包括:
收集英文单词语料库;
整合收集到的语料库,使用监督类型的机器学习方法对收集到的语料库进行分类模型训练;
解析待检测脚本,提取出所有变量名称;
将变量名称逐一通过分类模型,判断是否为随机字符串;
对待检测脚本中的随机字符串进行统计;所述统计内容至少包括随机字符串数量及平均长度;
若所述统计内容中有至少一项超过预设值,则所述待检测脚本为恶意。
所述的方法中,所述监督类型的机器学习方法为马尔科夫链法。
所述的方法中,马尔科夫链法对收集到的语料库进行分类模型训练方式具体为:
对语料库中的所有单词进行分割,产生多个由两个字母组成的片段,生成状态转移矩阵,对片段进行频率统计;
选取常规单词,以上述相同方式分割,利用上述生成的状态转移矩阵,计算常规单词的出现频率均值,作为常规单词频率;
选取随机非单词字符串,以上述相同方式分割,利用上述生成的状态转移矩阵,计算随机非单词字符串的出现频率均值,作为随机字符串频率;上述常规单词频率应大于随机字符串频率;
根据常规单词频率及随机字符串频率计算分类频率阈值。
所述的方法中,将变量名称逐一通过分类模型,判断是否为随机字符串,具体为:将变量名传入分类模型,所述变量名将按照上述方式分割为片段,利用上述生成的状态转移矩阵,计算变量名的出现频率,并与分类频率阈值比较,若大于分类频率阈值,则所述变量名为正常,若小于分类频率阈值,则所述变量名为随机字符串。
一种基于变量名混淆程度的脚本启发式检测系统中,包括:
语料库收集模块,用于收集英文单词语料库;
模型训练模块,用于整合收集到的语料库,使用监督类型的机器学习方法对收集到的语料库进行分类模型训练;
脚本解析模块,用于解析待检测脚本,提取出所有变量名称;
判断模块,用于将变量名称逐一通过分类模型,判断是否为随机字符串;
统计模块,用于对待检测脚本中的随机字符串进行统计;所述统计内容至少包括随机字符串数量及平均长度;若所述统计内容中有至少一项超过预设值,则所述待检测脚本为恶意。
所述的系统中,所述监督类型的机器学习方法为马尔科夫链法。
所述的系统中,马尔科夫链法对收集到的语料库进行分类模型训练方式具体为:
对语料库中的所有单词进行分割,产生多个由两个字母组成的片段,生成状态转移矩阵,对片段进行频率统计;
选取常规单词,以上述相同方式分割,利用上述生成的状态转移矩阵,计算常规单词的出现频率均值,作为常规单词频率;
选取随机非单词字符串,以上述相同方式分割,利用上述生成的状态转移矩阵,计算随机非单词字符串的出现频率均值,作为随机字符串频率;上述常规单词频率应大于随机字符串频率;
根据常规单词频率及随机字符串频率计算分类频率阈值。
所述的系统中,将变量名称逐一通过分类模型,判断是否为随机字符串,具体为:将变量名传入分类模型,所述变量名将按照上述方式分割为片段,利用上述生成的状态转移矩阵,计算变量名的出现频率,并与分类频率阈值比较,若大于分类频率阈值,则所述变量名为正常,若小于分类频率阈值,则所述变量名为随机字符串。
本发明所提出的方法,解决了脚本检测实现及维护复杂,高资源占用及运行速度慢的问题,使开发和维护更加容易,且资源占用低,运行效率高。
附图说明
为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于变量名称混淆程度的恶意脚本启发式检测方法实施例流程图;
图2位本发明一种基于变量名称混淆程度的恶意脚本启发式检测系统实施例结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明中技术方案作进一步详细的说明。
本发明就是要解决以上问题,提出一种基于变量名称混淆程度的脚本启发式检测方法及系统,根据变量名称的混淆程度,高效快速判断恶意脚本。
实施例一给出一种基于变量名混淆程度的脚本启发式检测方法,如图1所示,包括:
S101:收集英文单词语料库;
S102:整合收集到的语料库,使用监督类型的机器学习方法对收集到的语料库进行分类模型训练;
如马尔科夫链法:利用bigram方式对语料库中的所有单词进行分割,产生多个由两个字母组成的片段,生成状态转移矩阵T,对片段进行频率统计;
选取常规单词,以上述相同方式分割,利用上述生成的状态转移矩阵T,计算常规单词的出现频率均值,作为常规单词频率Pgood;
选取随机非单词字符串,以上述相同方式分割,利用上述生成的状态转移矩阵T,计算随机非单词字符串的出现频率均值,作为随机字符串频率Pbad;上述Pgood>Pbad;
根据常规单词频率及随机字符串频率计算分类频率阈值:Pthreshold=(Pgood>Pbad)/2
S103:解析待检测脚本,提取出所有变量名称;
S104:将变量名称逐一通过分类模型,判断是否为随机字符串;依然以上述方法为例,用bigram方式对变量名进行分割,利用转移矩阵T,计算分割后字符串出现频率P,如果P> Pthreshold,则所述变量为正常,否则所述变量为随机字符串;
S105:对待检测脚本中的随机字符串进行统计;所述统计内容至少包括随机字符串数量及平均长度;
S106:若所述统计内容中有至少一项超过预设值,则所述待检测脚本为恶意。
该方法仅仅是通过马尔科夫链进行举例,在实际应用中,还可以通过其他监督类型的机器学习方法进行模型训练。且模型训练只需要进行一次即可,若语料库发生变化,则可以在进行训练。
一种基于变量名混淆程度的脚本启发式检测系统中,如图2所示,包括:
语料库收集模块201,用于收集英文单词语料库;
模型训练模块202,用于整合收集到的语料库,使用监督类型的机器学习方法对收集到的语料库进行分类模型训练;
脚本解析模块203,用于解析待检测脚本,提取出所有变量名称;
判断模块204,用于将变量名称逐一通过分类模型,判断是否为随机字符串;
统计模块205,用于对待检测脚本中的随机字符串进行统计;所述统计内容至少包括随机字符串数量及平均长度;若所述统计内容中有至少一项超过预设值,则所述待检测脚本为恶意。
所述的系统中,所述监督类型的机器学习方法为马尔科夫链法。
所述的系统中,马尔科夫链法对收集到的语料库进行分类模型训练方式具体为:
对语料库中的所有单词进行分割,产生多个由两个字母组成的片段,生成状态转移矩阵,对片段进行频率统计;
选取常规单词,以上述相同方式分割,利用上述生成的状态转移矩阵,计算常规单词的出现频率均值,作为常规单词频率;
选取随机非单词字符串,以上述相同方式分割,利用上述生成的状态转移矩阵,计算随机非单词字符串的出现频率均值,作为随机字符串频率;上述常规单词频率应大于随机字符串频率;
根据常规单词频率及随机字符串频率计算分类频率阈值。
所述的系统中,将变量名称逐一通过分类模型,判断是否为随机字符串,具体为:将变量名传入分类模型,所述变量名将按照上述方式分割为片段,利用上述生成的状态转移矩阵,计算变量名的出现频率,并与分类频率阈值比较,若大于分类频率阈值,则所述变量名为正常,若小于分类频率阈值,则所述变量名为随机字符串。
本发明所提出的方法,解决了脚本检测实现及维护复杂,高资源占用及运行速度慢的问题,使开发和维护更加容易,且资源占用低,运行效率高。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
虽然通过实施例描绘了本发明,本领域普通技术人员知道,本发明有许多变形和变化而不脱离本发明的精神,希望所附的权利要求包括这些变形和变化而不脱离本发明的精神。
- 还没有人留言评论。精彩留言会获得点赞!