一种基于自动信息筛选学习的企业二级行业分类方法与流程
本发明涉及信息处理领域,特别涉及一种基于自动信息筛选学习的企业二级行业分类方法。
背景技术:
随着社会的进步和市场的繁荣和发展,中国经济一直处于高速的发展轨道上,企业作为社会经济中最重要的活动主体,在经济中扮演着重要的角色,对于企业信息的整理和分析有助于帮助相关决策者了解该企业的经营状况,发现潜在经营风险。企业的二级行业类别较多,如果人工对海量的企业进行分类,将耗费大量的人力。
通常会借助机器学习的手段进行数据挖掘,自动完成行业分类。主流的方法分有两种:一种是使用传统的机器学习方法,首先人工提取特征,再利用经典的分类算法,比如SVM,朴素贝叶斯等分类器完成行业分类。另一种是利用深度学习技术,比如循环神经网络完成自动的特征提取和分类任务。二级行业分类相比一级行业分类,在经营范围的描述上,不同行业之间存在更多的相似性,这导致利用常规方法很难发现这种微小的差异,进而较难作出正确的判断。如果使用传统的机器学习方法,需要做大量的特征工程,比如TF-IDF,N-GRAM等方法提取重要的特征组成高维向量放入不同的分类器算法中进行试验和调参,工作量大而繁重,并且都是凭借人的一些经验和猜想在进行的尝试,很可能花费了很大的精力最终效果却不显著。即便使用深度学习的方法,比如循环神经网络,虽然免去了一些人工的特征提取的工作,但是由于经营范围的描述信息通常很分散,包含了多个行业的内容,单从经营范围无法确定哪些信息对判断行业类别是有效的。比如,XX酿酒有限公司的经营范围描述是“白酒酿造,批发零售五金、日用品、饲料、建筑材料”。该描述中包含了多个行业类别,很难确定哪些内容是需要重点关注的,哪些内容是无用的,应该忽略。针对该类问题,如果人工进行判定,通常会先看一下公司名包含了“酿酒”,会将经营范围的描述重点放在“白酒酿造”,忽略其他无关的描述,最终确定该企业属于“酒、饮料和精制茶制造业”。基于人脑的这种信息处理方式的启发,本发明结合循环神经网络和门限控制的方法,构建了一个能够基于公司名自动进行信息筛选的神经网络,用于企业的二级行业分类。
技术实现要素:
本发明的目的在于克服现有技术中所存在的上述不足,提供一种基于自动信息筛选学习的企业二级行业分类方法,构造行业分类神经网络模型;所述行业分类神经网络模型中结合循环神经网络和门限控制的方法,使用企业名称来对企业经营范围信息进行筛选,以实现对待分类企业二级行业的自动分类判断。
为了实现上述发明目的,本发明提供了以下技术方案:一种基于自动信息筛选学习的企业二级行业分类方法,采用结合循环神经网络和门限控制的方法构造行业分类神经网络模型,根据企业的经营范围信息和企业名称信息,实现对企业的二级行业的自动分类判断。
具体的,所采用行业分类神经网络模型的向前算法公式如下:
hj=GRU1(xj,hj-1)
sj=GRU2(zj,sj-1)
f=σ(W(f)hT+U(f)sT)
y=softmax(b)
其中,GRU1为第一循环神经网络,hj是GRU1在输入序列中第j个词的输入后生成的隐藏层状态向量,xj是输入序列中第j个词的词向量;
GRU2为第二循环神经网络;sj是GRU2在输入序列中第j个词的输入后生成的隐藏层状态向量,zj是输入序列中第j个词的词向量;
f是用于信息筛选的控制门向量,hT是最后一个词输入后生成的隐藏层状态向量,sT是最后一个词输入后生成的隐藏层状态向量,f由hT和sT通过一个全连接的神经网络生成,其网络的参数分别是W(f)和U(f),激活函数是sigmoid函数,由符号σ表示;
b是另一个全连接的神经网络得到的预测向量,该全连接神经网络的输入向量为sT、f和hT,激活函数为tanh,由完成信息筛选,W为sT的参数,U为的参数;
y为通过本神经网络的最终的每个类别的分类概率分布向量,由向量b通过一个softmax层得到。
进一步的本发明方法包含以下实现步骤:
(1)将待分类企业的企业名称和经营范围进行分词处理,建立经营范围的词语库,将分词后的数据作为语料库生成词汇表,并对每一个词建立相应的词典索引,将索引值映射成不同的固定长度的随机向量;
(2)将二级行业分类中的所有类别进行编码,并将编码号转化成对应的向量,一个编码号对应一个向量;
(3)在待分类企业中随机选取一定数量的样本,进行标注;在标注后中样划分为训练样本和开发样本;
(4)将训练样本的二级行业分类向量、企业经营范围的词向量序列和企业名称的词向量序列输入行业分类神经网络模型中,通过神经网络的向前算法和误差反向传播,自动调节神经网络的权重参数,直到模型收敛;
(5)将待分类企业的企业经营范围的词向量序列输入已经训练完毕的所述行业分类神经网络模型的第一循环神经网络中,将对应企业名称的词向量序列输入已经训练完毕的所述行业分类神经网络模型的第二循环神经网络中;通过所述行业分类神经网络预测出待分类企业的二级行业分类结果。
进一步的,所述行业分类神经网络模型的向前传播包含以下实现过程:
①、将待分类企业经营范围的词向量序列输入GRU1,生成表征经营范围的向量;
②、将待分类企业名称的词向量序列输入GRU2,生成表征企业名的向量;
③、将表征经营范围的向量和表征公司名的向量送入全连接的神经网络生成信息筛选门控制向量;
④、通过信息筛选门控制向量过滤表征经营范围的向量生成筛选后的经营范围向量;
⑤、将筛选后的经营范围向量和表征公司名的向量送入全连接的神经网络生成预测向量,再通过softmax层生成二级行业类别的概率分布。
与现有技术相比,本发明的有益效果:本发明提供一种基于自动信息筛选学习的企业二级行业分类方法,本发明利用深度学习技术,使用GRU循环神经网络,自动对文本数据进行特征提取,通过加入门限控制的神经网络,实现了基于公司名对经营范围的自动信息筛选过滤,在很难区分的不同的二级行业分类之间,自动筛选出关键的信息,实现了高效精准的二级行业类别的预测。弥补了单独使用一个循环神经网络的不足,同时也发挥了神经网络的特征自动提取,无需人工干预的优势。
附图说明:
图1为本一种基于自动信息筛选学习的企业二级行业分类方法的实现步骤图。
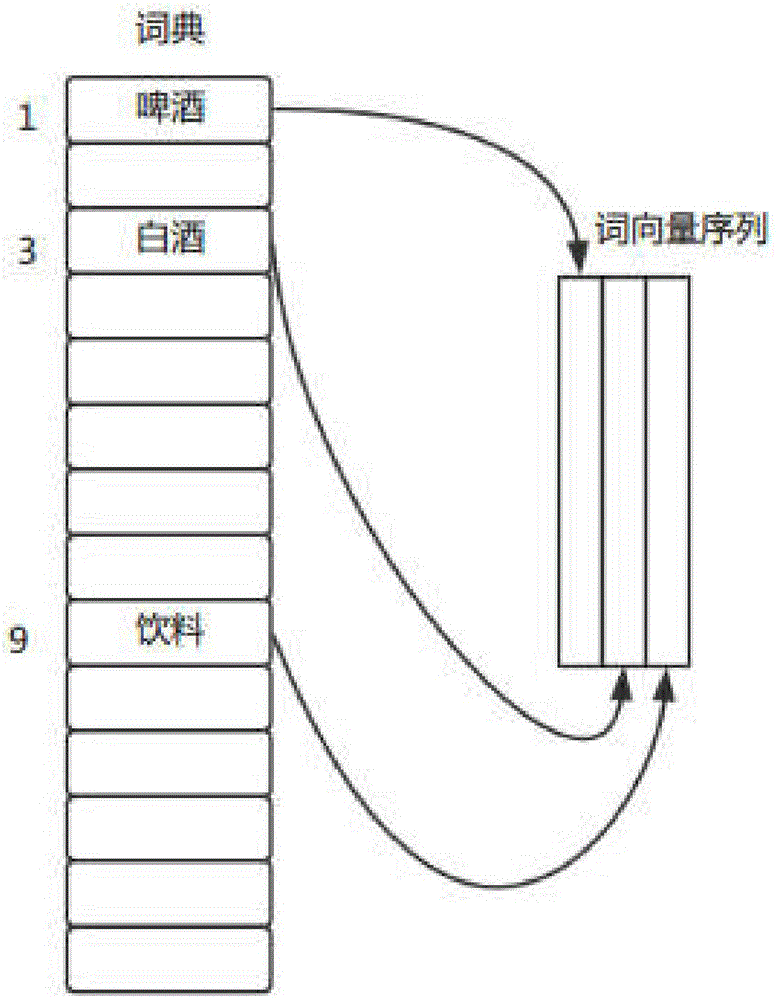
图2为语料库的编号已经向量映射关系示意图。
图3为本发明方法中行业分类神经网络模型的向前算法过程示意图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
一种基于自动信息筛选学习的企业二级行业分类方法,采用结合循环神经网络和门限控制的方法构造行业分类神经网络模型,根据企业的经营范围信息和企业名称信息,实现对企业的二级行业的自动分类判断。
具体的,所采用行业分类神经网络模型的向前算法公式如下:
hj=GRU1(xj,hj-1)
sj=GRU2(zj,sj-1)
f=σ(W(f)hT+U(f)sT)
y=softmax(b)
其中,GRU1和GRU2是两个GRU循环神经网络(GRU1为第一循环神经网络,GRU2为第二循环神经网络),GRU将忘记门和输入门合成了一个单一的更新门,同时还混合了细胞状态和隐藏状态。最终的模型比标准的LSTM模型要简单,效果跟LSTM不相上下。与LSTM一样,GRU用于处理序列数据,比如一段文字描述可以作为由词组成的序列输入到GRU中,该方法在自然语言处理领域中被广泛的运用。
本文的神经网络前向算法中,GRU1的输入是每一个样本的经营范围词向量序列,也就是在步骤3中处理好的经营范围的词序列所对应的词向量序列。xj是输入序列中第j个词的词向量,hj是GRU1在输入序列中第j个词的输入后生成的隐藏层状态向量,hT是最后一个词输入后生成的隐藏层状态向量,表征当前企业的经营范围。同理,GRU2的输入是每一个样本的公司名词向量序列,zj是输入序列中第j个词的词向量,sj是GRU2在输入序列中第j个词的输入后生成的隐藏层状态向量,sT是最后一个词输入后生成的隐藏层状态向量,表征当前企业的公司名。f是用于信息筛选的控制门向量,由hT和sT通过一个全连接的神经网络生成,其网络的参数分别是W(f)和U(f),激活函数是sigmoid函数,由符号σ表示。信息筛选由完成,通过点乘运算将hT中的无用的杂乱信息丢弃,得到有效的信息,再结合公司名向量sT,通过另一个全连接的神经网络得到最后的预测向量b,其神经网络的参数分别为W和U,激活函数是tanh。向量b通过一个softmax层得到最终的每个类别的概率分布向量y。向量y中的每一维的值对应了相应类别的概率,通常选择概率值最大的类别作为最后的预测类别。
进一步的,本发明方法的待分类企业的行业预测包含如图1所示的以下实现步骤:
(1)将待分类企业的企业名称和经营范围进行分词处理,并去除标点符号和停用词等无意义的词;将分词后的数据作为语料库生成词汇表,并对每一个词建立相应的词典索引,将索引值映射成不同的固定长度的随机向量。比如经营范围的描述是“啤酒、白酒饮料、纯净水的生产、销售”,分词处理后为“啤酒 白酒 饮料 纯净水 生产 销售”。将分词后的所有的数据作为语料库生成词汇表,并对每一个词建立相应的词典索引,比如啤酒索引是1,白酒索引是3,饮料的索引是9。最后将所有的词的索引值映射到不同的固定长度的随机向量。也就是说每一个词用都用不同的固定长度的词向量进行表示。如图2所示。公司名和经营范围在分词处理后的词序列所对应的词向量序列将作为神经网络的输入。
(2)将二级行业分类中的所有类别进行编码,并将编码号转化成对应的向量,一个编码号对应一个向量。
收集大量企业公司名和相对应的经营范围描述的数据,随机筛选其中的部分数据m条作为样本。根据经营范围对每条样本进行人工标注,标记它所属的二级行业类别。比如,XXX酒业有限责任公司的经营范围的描述是:“啤酒、白酒饮料、纯净水的生产、销售”。则将该条样本标记为“酒、饮料和精制茶制造业”。“酒、饮料和精制茶制造业”是二级行业分类的其中一个类别,二级行业分类拥有很多类别,比如:农业、林业、畜牧业、煤炭开采和洗选业、石油和天然气开采业、黑色金属矿采选业、有色金属矿采选业、非金属矿采选业、通用设备制造业、专用设备制造业、汽车制造业、酒、饮料和精制茶制造业等。(2)将二级行业分类中的所有类别进行编码,转换成计算机可识别的整数。比如整数1对应的是农业,整数15对应的是酒、饮料和精制茶制造业。再将每个类别编码转换成one-hot向量,向量的维度是总的二级行业分类类别数量,比如,农业的编码是1,向量的第一个维度的元素值为1,其余为0。如“1000000…”。该向量将作为神经网络目标变量的输入。
(3)在待分类企业中随机选取一定数量的样本,进行标注;在标注后中样划分为训练样本和开发样本;通常70%的样本作为训练样本,30%的样本作为开发样本。
(4)将训练样本的二级行业分类向量、企业经营范围的词向量序列和企业名称的词向量序列输入行业分类神经网络模型中,通过神经网络的向前算法和误差反向传播,自动调节神经网络的权重参数,直到模型收敛。
在训练样本中将步骤(2)中处理的表征样本所属类别的one-hot向量和步骤3中处理的公司名和经营范围的词向量序列输入到行业分类神经网络模型中。模型首先会根据公司名和经营范围的词向量序列完成前向运算,然后通过样本的真实类别(步骤(2)中的one-hot向量)进行误差的反向传播,这个过程会自动的去修正神经网络中的权重参数。模型训练过程中,记录每一轮迭代在开发样本和训练样本上的准确率,当训练样本上的准确率不断的提升,开发样本上的准确率没有太大的变化(或者达到设置的准确率阈值)时,可以认为模型已经收敛并停止模型的训练,保存开发样本上准确率最高的一轮迭代结果对应的权重参数作为最终的预测模型。
(5)将待分类企业的企业经营范围的词向量序列输入已经训练完毕的所述行业分类神经网络模型的第一循环神经网络中,将对应企业名称的词向量序列输入已经训练完毕的所述行业分类神经网络模型的第二循环神经网络中;通过所述行业分类神经网络预测出待分类企业的二级行业分类结果。
进一步的,所述行业分类神经网络模型的向前传播包含如图3所示的以下实现过程:
①、将待分类企业经营范围的词向量序列输入GRU1,生成表征经营范围的向量;
②、将待分类企业名称的词向量序列输入GRU2,生成表征企业名的向量;
③、将表征经营范围的向量和表征公司名的向量送入全连接的神经网络生成信息筛选门控制向量;
④、通过信息筛选门控制向量过滤表征经营范围的向量生成筛选后的经营范围向量;
⑤、将筛选后的经营范围向量和表征公司名的向量送入全连接的神经网络生成预测向量,再通过softmax层生成二级行业类别的概率分布。
- 还没有人留言评论。精彩留言会获得点赞!