增强型身份保持的隐私保护方法与流程
本发明涉及数据发布技术领域,具体涉及一种增强型身份保持的隐私保护方法。
背景技术:
随着信息技术的发展,越来越多的个人信息被有效的利用起来。如个人购物信息、社交信息和医疗数据等。当下有很多研究者提出了很多的匿名保护模型,如k-匿名和l-多样性等。但是这些匿名模型通常先删除个体身份属性,然后概化准标识属性来满足匿名要求,这些匿名模型通常假定单一个体在数据表中最多只出现一次。但是在实际情况中,这种前提假设是难以满足的。例如在某个医院发布的病人情况表中,某些病人就会由于同时患有多种不同的疾病,因而会出现多次在发布的表中。并且身份信息的删除也将会忽视了同一个体多个敏感属性之间可能的关联信息,而这种信息在很多研究中有很重要的意义。
为了更好的保护医疗数据中的数据隐私,现有的医疗数据匿名方法有身份保持的(k,l)-匿名和身份保持的(α,β)-匿名等。身份保持的(k,l)-匿名即在保留个体ID的情况下,将医疗数据中的所有数据进行聚类分组,使得每组数据至少要有k个个体和l个敏感属性。身份保持的(α,β)-匿名为在保留个体ID的情况下,将医疗数据中的所有数据进行聚类分组,使得每组数据中,任何一个个体中所包含的元组个数和所有元组个数比例不超过α,任何单一敏感属性出现的次数与分组中的所有元组的个数的比值小于等于β,其中0<α,β<1。比如表1中存在单一个体对应多条记录,通过上述身份保持匿名方法处理后得到发布表如表2所示。
表1单一个体对应多条记录的病人情况表
表2满足身份保持(3,3)-匿名和(0.4,0.6)-匿名的一个发布表
假设具有相同准标识符属性值的所有元组集合成为一个QI分组或等价类分组。其中,如果攻击者发现Mike在第一个QI分组中,则会推测Mike肯定患有Hypertension,因此隐私泄露的概率为100%。
但是从上例可以看出在满足的身份保持(3,3)-匿名和(0.4,0.6)-匿名的情况下,患者的隐私仍然会被泄露,如在分组1即Group-ID=1中,可以推断出所有的患者都患有Hypertension。在现实生活中,用于发布的医疗数据常被用在各种特定用途中,如:数据链接挖掘,患者并发症问题等,这就需要改进原有的匿名方法。
技术实现要素:
本发明所要解决的技术问题是现有身份保持的隐私保护仍存在隐私泄露的的问题,提供一种增强型身份保持的隐私保护方法。
为解决上述问题,本发明是通过以下技术方案实现的:
增强型身份保持的隐私保护方法,包括如下步骤:
步骤1)输入原始的数据集,并对原始数据集中的数据进行重编码,得到重编码后的数据集;
步骤2)生成新的等价类分组Qi,并从数据集中随机选取一个个体p放入新生成的等价类分组Qi中;
步骤3)计算数据集中剩余个体与个体p的距离,并将剩余个体中与个体p的距离最近的个体放入到等价类分组Qi中;
步骤4)对等价类分组Qi中的数据进行匿名约束检测;
如果满足匿名约束条件,则返回步骤2);
如果不满足匿名约束条件,则计算数据集中剩余个体与等价类分组Qi的距离,并将剩余个体中与等价类分组Qi的距离最近的个体放入到等价类分组Qi中,直到等价类分组Qi满足匿名约束条件;
步骤5)将放入等价类分组Qi的个体从数据集中删除;当数据集中剩余个体的个数少于设定值时,将数据集中剩余个体分别放入到与该个体距离最近的等价类分组Qi中或者将数据集中剩余个体抑制;
步骤6)对分组后的数据进行概化处理,然后发布。
上述步骤4)中,在进行匿名约束检测时,所采用的是增强型l-多样性匿名模型或增强型(α,β)匿名模型。
当匿名约束检测所使用的是增强型l-多样性匿名模型时,所需满足的匿名约束条件为等价类分组Qi中的所有个体中敏感属性的最小碰集的值大于等于l。
当匿名约束检测所使用的是增强型(α,β)匿名模型时,所需满足的匿名约束条件为等价类分组Qi中任意单一个体出现的次数与该等价类分组Qi中的所有元组的个数的比值小于等于α,等价类分组Qi中任意单一敏感属性出现的次数与等价类分组Qi中所有个体的个数的比值小于等于β。
与现有技术相比,本发明通过增强型的l-多样性匿名和增强型的(α,β)-匿名对数据的等价类分组进行匿名约束检测;同时,通过改进现有的匿名约束条件;增强型的l-多样性的改进为采用碰集的思想获取敏感属性出现的最大次数,进而与l进行比较;增强型的(α,β)-匿名改进了β的取值,β的分母改为个体的个数,而原有的匿名方法的分母为元组的个数;经过上述处理的数据在发布时,能够在保证满足数据分析的要求同时,更好地保护了患者的信息,有利于数据分析中的并发症、诱因等相关分析。
附图说明
图1为增强型身份保持的隐私保护方法的流程图。
图2为数据匿名处理的流程图。
具体实施方式
针对医疗数据这一具体的数据使用目的,本发明主要从以下几方面改进保护医疗数据:
1)因为要保护医疗数据的同时,要使数据的信息损失率最低。因此在分组之前,进行个体之间的距离计算,将距离最近的个体放在同一等价类分组中。
2)对于增强型的l-多样性匿名模型,l的取值为采用碰集的思想来获取最小碰集的个数的值,使分组内的敏感数据的最小碰集值大于等于l。对于增强型的(α,β)匿名模型,α的取值为单一个体出现的次数与分组中的所有个体的个数的比值,β的取值为单一敏感属性出现的次数与所有个体的个数的比值。
参见图1,一种增强型身份保持的隐私保护方法,包括如下步骤:
1)初始化数据,即去掉显示的标识属性,改用重新编号的标示符表示。
2)随机选取一个个体放入等价类分组中。
3)对这些数据进行个体之间的距离或个体与类之间的距离的计算,将距离最近的个体放在同一等价类分组中。
个体间的距离公式:
个体到类的距离公式:
4)对等价类分组中的数据进行匿名约束检测。
若使用增强型的l-多样性匿名模型,看其是否满足最小碰集的值大于等于l,若不满足就进行找下一条最近的数据,放入到等价类分组中,直到满足匿名约束条件。若满足匿名约束条件,将重新随机选取个体放入新的等价类分组中;
若使用增强型的(α,β)匿名模型,看其任意单一个体出现的次数与分组中的所有元组的个数的比值是否小于等于α,任意单一敏感属性出现的次数与所有个体的个数的比值是否小于等于β,若不满足就进行找下一条最近的数据,放入到等价类分组中,直到满足匿名约束条件。若满足匿名约束条件,将重新随机选取个体放入新的等价类分组中。
5)将放入的等价类分组中的数据将从原始数据中删除,等到剩余数据个数过少时,将其放入与其距离最近的等价类分组中,或者抑制剩余数据。等到原始数据集为空,数据的匿名处理结束。
6)对分组后的数据进行概化处理,然后发布。
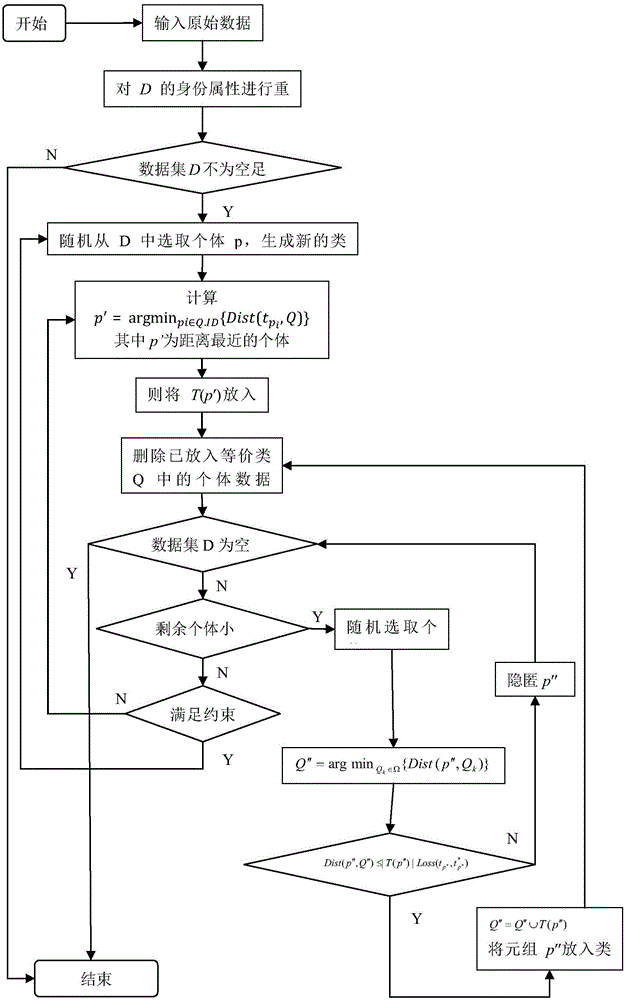
参见图2,下面通过一个具体实例,对本发明进行进一步详细说明:
步骤1:输入原始数据集,并对数据进行进行重编码,得到重编码后的数据集D。因为考虑到本匿名方法,在保证发布的数据在达到匿名水平的同时,能最大限度地保存原始的数据结构信息,因此需要在匿名前先对数据进行重编码,使其保留个体的关联性。
原始数据集如表1所示,这里有11条医疗数据即11条元组,8个人即个个体,ID个数即为个体数。对原始数据进行重编码如表3。
表3对原始数据重编码
步骤2:判断当前的数据集D是否为空。若不为空,且满足约束条件,则转到步骤3。否则执行步骤14。
步骤3:随机从D中选取个体p,生成新的类Q=T(p)。
步骤4:计算其中p′为距离最近的个体。
步骤5:则将T(p′)放入Q。
步骤6:删除已放入等价类分组Q中的个体数据T(p)。
步骤7:判断数据集D是否为空。若不为空执行步骤8,否则执行步骤14。
步骤8:判断剩余个体身份小于l,若小于l执行步骤9,否则执行步骤13。
步骤9:随机选取个体p″。计算
步骤10:判断若满足执行步骤11。否则执行步骤12。
步骤11:Q″=Q″∪T(p″),将元组p″放入类中。然后执行步骤6。
步骤12:隐匿p″。然后执行步骤7。
步骤13:判断是否满足约束条件,若满足执行步骤3,若不满足执行步骤14。
步骤14:结束。
在步骤2和步骤13中,所述约束条件包括两种:一是增强型身份保持的(α,β)-匿名;二是增强型身份保持的l-多样性。
一、对于增强型身份保持的(α,β)-匿名:
首先随机选取个体p生成等价类分组Q,然后根据个体间的距离公式和个体到类的距离公式然后判断是否满足增强型身份保持的(α,β)-匿名约束条件。
令p=argmax{|T(pi)|pi∈Q.ID},s=argmax{|p(si)|si∈Q.As},如果|T(p)|/|Q|≤α,|P(s)|/n≤β,那么Q满足增强型身份保持的(α,β)-匿名。
例如我们随机选取ID为3的个体,然后计算距离该个体最近的个体,可知ID=1的个体是距离ID=3的个体最近,然后判断是否满足匿名约束(α=0.4,β=0.6),可以算出α=0.5,β=1不满足约束条件,然后继续计算与该等价类分组中最近的个体,找到ID=4,然后放入到等价类分组中,然后判断是否满足匿名约束(α=0.4,β=0.6),可以算出α=0.33,β=1不满足约束条件。继续找最近距离的个体,找到ID=6个体,算出仍不满足,找到ID为8的个体算出满足约束条件(α=0.4,β=0.6)。然后重新选出随机数生成新的等价类分组,以此类推,得出匿名表如表4所示。
表4满足增强型匿名约束(α=0.4,β=0.6)的匿名表
二、对于增强型身份保持的l-多样性:
首先随机选取个体p生成等价类分组Q,然后根据个体间的距离公式和个体到类的距离公式然后判断是否满足增强型身份保持的l-多样性的约束条件。
给定QI分组Q,个体集合为PQ={p1,p2,…,pn},令Ψ={S(p1),S(p2),…,S(pn)},H是Ψ的最小碰集,如果|H|≥l,那么Q满足增强型身份保持的l-多样性,其中pi为个体标示,S(pi)为个体所包含的敏感属性的集合。
其中碰集的概念为令Ψ={X1,X2,…,Xt}是集合X上的一个子集簇,如果且i∈{1,2,…,t},则称H是Ψ的一个碰集。如果使得H′是Ψ的碰集,那么称H是Ψ的极小碰集。如果H是基数最小的极小碰集,那么H称是Ψ的最小碰集。
例如我们随机选取ID=8的个体,然后计算距离该个体最近的个体,可知ID=1的个体是距离ID=8的个体最近,然后判断是否满足匿名约束(l>=3),根据碰集公式可以算出l=2不满足约束条件,然后继续计算与该等价类分组中最近的个体,找到ID=4,然后放入到等价类分组中,然后判断是否满足匿名约束(l>=3),可以算出l=2不满足约束条件。继续找最近距离的个体,找到ID=3个体,算出仍不满足,找到ID为6的个体算出满足约束条件l=3。然后重新选出随机数生成新的等价类分组,以此类推,得出匿名表5。
表5满足增强型匿名约束(α=0.4,β=0.6)的匿名表
以下为本发明设计的算法在本例中的医疗数据匿名前后保存医疗信息的情况。原有的身份保持的匿名方法所发布的表6,增强型身份保持的匿名方法所发布的表7。
表6满足身份保持(3,3)-匿名和(0.4,0.6)-匿名
表7满足增强型匿名约束(0.4,0.6)-匿名和(l>=3)的匿名
由此可以看出原有的身份保持的匿名方法所发布的表,假如攻击者知道所攻击的目标就在分组1中,那么攻击者可以100%得到被攻击者患有Hypertension。而增强型的身份保持的匿名方法发布的表就不存在这样的隐私泄露问题。
本发明用到的医疗数据是带有个体标识符的集值数据,攻击者的背景知识可以是已知被攻击者所在的分组。医疗数据在发布前需要进行初步的数据匿名处理,即去掉患者的唯一标识的显示标识属性,如姓名等,改用重新编号的标识符表示。发布的数据QI属性为患者的非敏感属性,如年龄等;ST属性为患者的敏感属性,如所患疾病。发布的数据经过本发明中的匿名方法处理,能够有效的防止攻击者使用背景知识从用户所在的发布数据中准确的获得用户的敏感信息,与此同时,能在较低的信息损失下有效地保护原始数据中的信息。这样不仅能保护患者的敏感信息,也有益于数据分析者分析医疗问题的相关信息。
- 还没有人留言评论。精彩留言会获得点赞!