一种跨语言的主题网站自动发现方法与流程
本发明属于互联网技术领域,尤其涉及一种跨语言的主题网站自动发现方法。
背景技术:
随着互联网应用的推广,网络已经成为人们获取公开信息的最重要的途径,尤其是其全球互联的性质,可以让人们轻松获取世界各地所产生的信息,成为人们信息交互、文化交流的重要途径。但是网络信息的爆炸式增长也给人们获取特定信息带来不便。一方面,如何从海量信息中搜集到真正符合需求的内容是一个难点,即便是借助主流的搜索引擎,其搜索结果中往往也掺杂着大量无关信息,导致搜集有效信息的效率低下。另一方面,语言不通问题限制了人们获取其他语种信息的欲望和能力,外语信息的获取需要借助语言工作者的翻译和转载,导致信息的时效性大大降低。因此,如何准确并迅速的获取有效信息成为信息工作者所面临的重要问题。为了快速获取特定领域的信息,信息工作者通常会关注一些特定网站,并实时留意网站更新的内容。这些网站是与其领域相关性强,信息相关度高,内容较权威的站点,因此信息的有效性和时效性相对较高,是重要信息的主要来源。发现这些特定主题的网站对于信息工作者而言意义重大。然而网络世界繁杂且瞬息万变,每天都有可能有新的网站建立起来,一些有用网站尤其是外语网站很难被发现,如果采用人工搜索其工作量巨大且效率低下。而目前已有的主题网站自动发现方法主要存在两个问题:1,只针对单种语言,没有考虑外语主题网站的发现;2,主题模型仅采用一组关键词,没有考虑主题网站发布的内容随时间的演变,导致主题模型对网站内容描述能力较弱,将新发现网站与目标网站进行对比匹配时效果不好。
综上所述,目前已有的主题网站自动发现方法主要存在只针对单种语言,没有考虑外语主题网站的发现;主题模型仅采用一组关键词,没有考虑主题网站发布的内容随时间的演变,导致主题模型对网站内容描述能力较弱,将新发现网站与目标网站进行对比匹配时效果不好。
技术实现要素:
本发明的目的在于提供一种跨语言的主题网站自动发现方法,旨在解决目前已有的主题网站自动发现方法主要存在只针对单种语言,没有考虑外语主题网站的发现;主题模型仅采用一组关键词,没有考虑主题网站发布的内容随时间的演变,导致主题模型对网站内容描述能力较弱,将新发现网站与目标网站进行对比匹配时效果不好的问题。
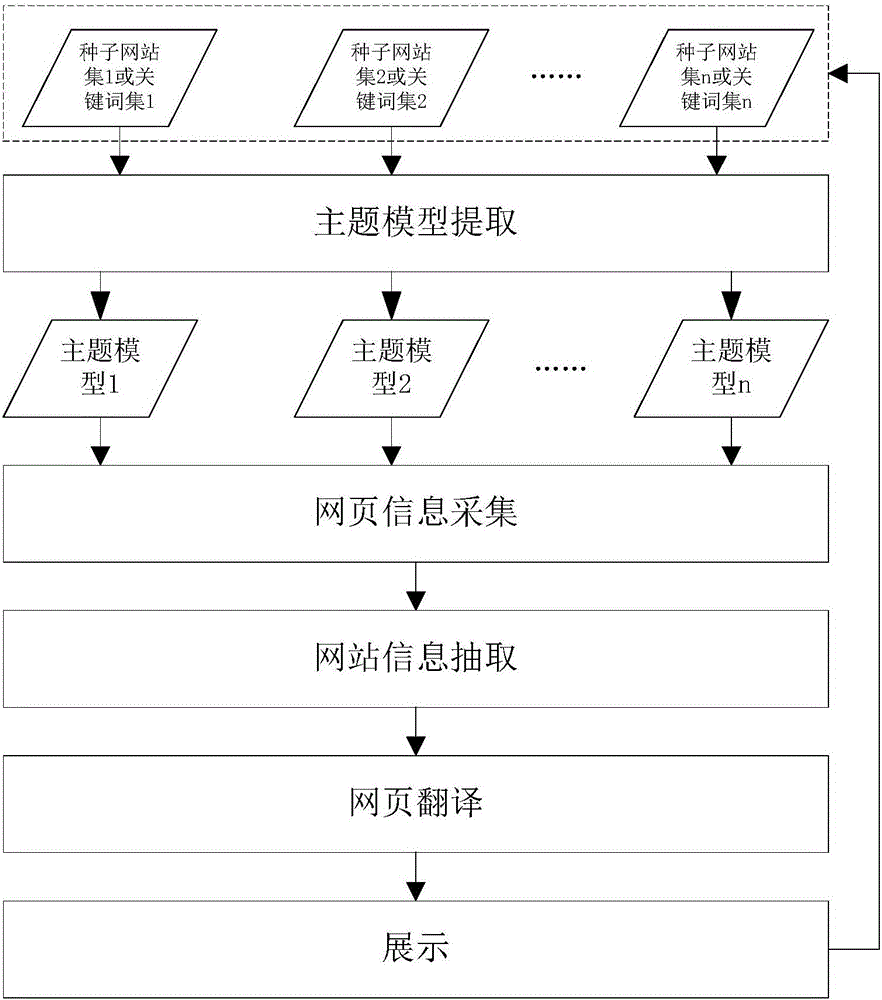
本发明是这样实现的,一种跨语言的主题网站自动发现方法,所述跨语言的主题网站自动发现方法根据种子网站或关键词集生成多语言主题模型,依据主题模型中的关键字进行网页信息采集,通过对相关网页进行聚类分析找出备选主题网站,将主题网站翻译后提供给用户,并根据用户反馈改进系统性能;
具体包括:
主题模型提取:将过去一段时间划分为几个时间段,分别计算每个时间段内网站的关键词,所有时间段的关键词组成网站的主题模型;在对比网站相似度时,分别对比各时间段内网站的相似度,然后根据各时间段的权重计算网站整体相似度,整体相似度大于给定阈值的即认定为主题相关网站;主题模型的定义如下:M=(K,A,L,N,P),其中M为主题模型,K为各时间段关键词向量,K=[K1,K2,……KN],其中Ki为第i个时间段的关键词向量A为各时间段关键词向量相似度的权重,A=[a1,a2,……aN];L为每个时间段关键词的个数,L=[l1,l2,……lN];N为时间段的个数;P为每个时间段的长度,P=[p1,p2,……,pN];其中A、L和P的值由用户结合实际情况进行设置;A的值越接近当前时间的时间段的权重越高;
网页信息采集:网页信息采集模块根据关键字检索相关网页并下载;
网站信息抽取:利用网站信息抽取模块从相关网页中聚合出备选主题网站;提取备选主题网站的主题模型并与种子网站主题模型进行对比,将相似度大于某一阈值的放入新发现主题网站列表;
网页翻译:利用已有机器翻译引擎将新发现主题网站列表中的外语网页翻译为本国语言;
展示及反馈:将翻译后的新发现主题网站中的内容展示给用户;由用户对新发现主题网站进行反馈,即评价是否真的主题网站,根据反馈结果对系统进行优化。
进一步,主题模型提取方法包括:
1)利用网页信息采集模块获取种子网站历史网页;
2)根据P设置N个子数据集,根据网页的发布时间将网页分别放入对应的子数据集;若某网页的发布时间t满足pi-1<t-t0≤pi,t0为当前时间,则将该网页放入第i个子数据集;
3)分别计算每个子数据集的关键词,第i个子数据集选取前li个关键词构成主题模型;
4)根据关键词和各参数值生成网站主题模型M;M=(K,A,L,N,P),其中M为主题模型,K为各时间段关键词向量,K=[K1,K2,……KN],其中Ki为第i个时间段的关键词向量A为各时间段关键词向量相似度的权重,A=[a1,a2,……aN];L为每个时间段关键词的个数,L=[l1,l2,……lN];N为时间段的个数;P为每个时间段的长度,P=[p1,p2,……,pN]。
进一步,如果没有种子站点,由用户直接指定各时间段的关键词生成主题模型;
当进行跨语言的主题网站自动发现时,外语网站主题模型生成方法包括两种根据实际情况进行选择的方法;
方法一为:对本语言主题模型的关键字进行翻译,直接生成外语主题模型;
方法二为:提供外语种子网站,自动提取主题模型。
进一步,网站信息抽取方法具体包括:
A)聚合备选主题网站:将url根据特殊字符进行切分;将切分后的url字段作为特征进行聚类;根据聚类结果生成备选主题网站;
B)生成新发现主题网站列表:提取备选主题网站的主题模型;计算备选主题网站与种子主题网站的相似度;将相似度大于h的网站放入新发现主题网站列表,并根据相似度的值对列表中的网站进行排序。
进一步,计算备选主题网站与种子主题网站的相似度计算方法包括:
采用向量空间余弦值法计算每个时间段内备选主题网站与种子主题网站的相似度;
计算整体相似度其中Si为第i个时间段内的相似度。
进一步,所述由用户对新发现主题网站进行反馈,即评价是否真的主题网站,根据反馈结果对系统进行优化,包括:
将用户肯定的网站加入种子主题网站,通过优化主题模型提升系统性能;
根据反馈优化步骤3中整体相似度阈值h。
本发明提出一种跨语言的主题网站自动发现方法,借助已有机器翻译引擎和网页信息采集系统辅助实现多种语言的主题相关网站自动发现,并设计人机协同机制将自动发现结果反馈给系统,将新发现网站用于主题模型的优化,提升对目标主题网站的描述能力,进而提升对新发现主题网站筛选的精度。
附图说明
图1是本发明实施例提供的跨语言主题网站自动发现方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细描述。
如图1所示,本发明实施例提供的跨语言的主题网站自动发现方法,所述跨语言的主题网站自动发现方法根据种子网站或关键词集生成多语言主题模型,依据主题模型中的关键字进行网页信息采集,通过对相关网页进行聚类分析找出备选主题网站,将主题网站翻译后提供给用户,并根据用户反馈改进系统性能;
具体包括:
1、主题模型提取:
主题模型提取的关键是提取出能够充分体现网站特点的特征,实现网站的可量化计算和对比。主题模型最常用的特征是关键词,通过TF-IDF等方式抽取网站的N个关键词,然后采用向量空间模型(VSM)等方式计算网站间的相似度,相似度大于某一阈值的网站即可认定为主题相关的网站。但是通常来讲,网站信息是经常更新的,同一组关键词虽然能够一定程度上体现网站的整体特点,但是其精度较粗,对候选网站的过滤效果较差。针对这一问题,本专利提出了一种时序主题模型提取方法,其主要思想是将过去一段时间划分为几个时间段,分别计算每个时间段内网站的关键词,所有时间段的关键词组成网站的主题模型。在对比网站相似度时,分别对比各时间段内网站的相似度,然后根据各时间段的权重计算网站整体相似度,整体相似度大于给定阈值的即认定为主题相关网站。
本发明主题模型的定义如下:
M=(K,A,L,N,P)
其中M为主题模型,K为各时间段关键词向量,K=[K1,K2,……KN],其中Ki为第i个时间段的关键词向量A为各时间段关键词向量相似度的权重,A=[a1,a2,……aN]。L为每个时间段关键词的个数,L=[l1,l2,......lN]。N为时间段的个数。P为每个时间段的长度(以月为单位),P=[p1,p2,......,pN]。其中A、L和P的值由用户结合实际情况进行设置。例如设置A的值时,越接近当前时间的时间段的权重应该越高。
主题模型提取流程如下:
1)利用网页信息采集模块获取种子网站历史网页;
2)根据P设置N个子数据集,根据网页的发布时间将网页分别放入对应的子数据集,例如某一网页的发布时间t属于pi,则该网页被放入第i个字数据集;
3)分别计算每个子数据集的关键词,第i个子数据集选取前li个关键词构成主题模型。建议采用词频和位置结合的方法。
4)根据关键词和各参数值生成网站主题模型M。
如果没有种子站点,也可以由用户直接指定各时间段的关键词生成主题模型。
当进行跨语言的主题网站自动发现时,外语网站主题模型生成方法有两种,根据实际情况进行选择。方法一,对本语言主题模型的关键字进行翻译,直接生成外语主题模型;方法二,提供外语种子网站,自动提取主题模型。其中方法二较为通用,适用于所有情况。方法一仅适用于某些各国情况较相似的领域,例如IT、科技等。对于各国情况各不相同的领域,例如军事,更适合采用方法二。
2、网页信息采集
网页信息采集模块根据关键字检索相关网页并下载。
3、网站信息抽取
网站信息抽取模块完成两个功能:1.从相关网页中聚合出备选主题网站;2.提取备选主题网站的主题模型并与种子网站主题模型进行对比,将相似度大于某一阈值的放入新发现主题网站列表。
1)聚合备选主题网站
a)将url根据特殊字符进行切分,例如‘?’、‘/’等;
b)将切分后的url字段作为特征进行聚类;
c)根据聚类结果生成备选主题网站。
2)生成新发现主题网站列表
a)提取备选主题网站的主题模型;
b)计算备选主题网站与种子主题网站的相似度,计算方法如下:
i)采用向量空间余弦值法计算每个时间段内备选主题网站与种子主题网站的相似度;
ii)整体相似度其中Si为第i个时间段内的相似度;
c)将相似度大于h的网站放入新发现主题网站列表,并根据相似度的值对列表中的网站进行排序。
4、网页翻译
利用已有机器翻译引擎将新发现主题网站列表中的外语网页翻译为本国语言。
5、展示及反馈
a)将翻译后的新发现主题网站中的内容展示给用户;
b)由用户对新发现主题网站进行反馈,即评价是否真的主题网站,根据反馈结果对系统进行优化,主要包含两个方面:
i)将用户肯定的网站加入种子主题网站,通过优化主题模型提升系统性能;
ii)根据反馈优化步骤3中整体相似度阈值h。
本发明提出一种跨语言的主题网站自动发现方法,借助已有机器翻译引擎和网页信息采集系统辅助实现多种语言的主题相关网站自动发现,并设计人机协同机制将自动发现结果的准确性反馈给系统,逐步提升系统的性能。
本发明实现了跨语言的主题网站自动发现;
本发明提出了时序主题模型提取方法,提升了主题网站筛选的精度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!