一种金融领域关系型数据库高性能访问方法与流程
本发明涉及数据库高性能访问方法,尤其涉及一种金融领域关系型数据库高性能访问方法。
背景技术:
在金融领域对数据存储有严苛的可靠性和可用性要求,且金融领域的数据是异常敏感,对访问权限控制要求很高的,且在技术系统运维上出于数据安全性和访问效率考虑,通常把应用程序和数据库放在同一局域网内。当前市场上通常采用成熟的关系型数据产品,如SQL Server、Oracle等,而传统对关系型数据库中数据的访问是构造DML类型的SQL语句,通过调用封装好的数据库API接口如JDBC、ODBC等,发送到DBMS解析和执行,得到执行结果。
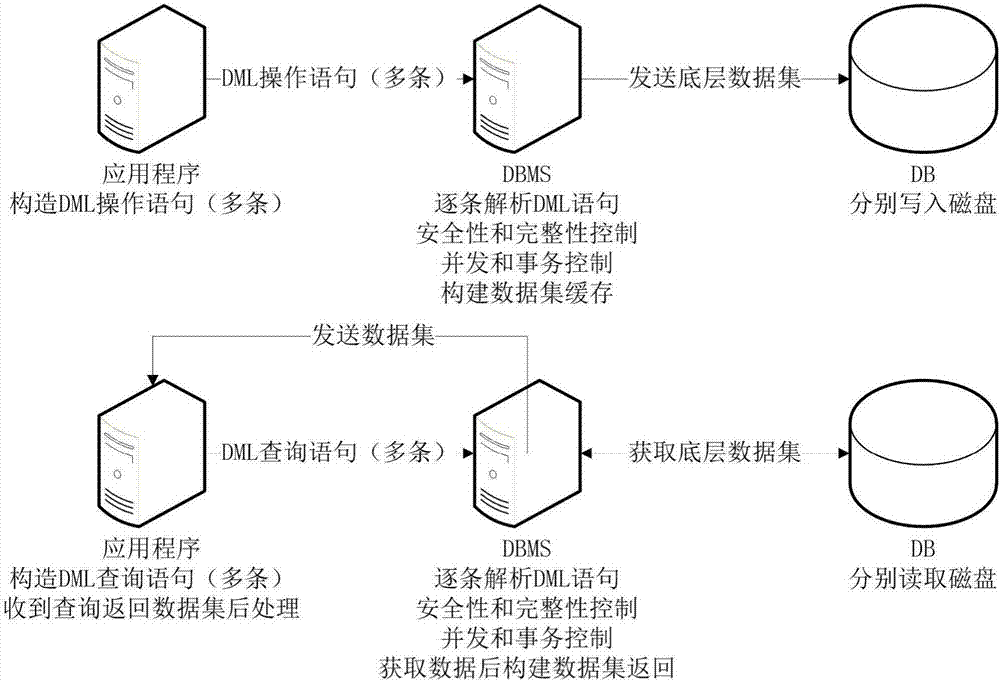
如图2所示,传统数据库访问方式相对灵活,也安全可靠,但即便应用程序和数据库在同一局域网内,数据库访问的效率仍然低下,因为主要的工作是在DBMS完成的,瓶颈也在是DBMS,而局域网优质的网络带宽(应用程序和DBMS之间)却经常处于空闲状态,除了在查询返回结果集较大的情况下可能占用部分上行网络链路外,由于DML类型的SQL语句组成的消息包体积小,下行网络链路几乎没有任何负载。另据反复测试验证即便应用程序、DBMS、数据库位于相同操作系统平台上,应用程序以长连接方式向数据库中的表插入数据记录其TPS最高难以超过1500,修改表数据记录的TPS则更低,而期间如果结合具体业务场景再附加上查询的负载,DBMS的效率更是会持续下降。考虑到当前证券交易领域广泛采用量化/程序化交易方式,传统数据库访问方式的性能已经不能满足要求,从而限制了证券业务进一步的发展和规模的扩大,因此迫切需要找到能有效提高数据库访问效率的方法。
技术实现要素:
为了解决现有技术中的问题,本发明提供了一种金融领域关系型数据库高性能访问方法。
本发明提供了一种金融领域关系型数据库高性能访问方法,其包括以下步骤:
S1、写入数据;
S101、应用程序计算好字段的长度,构造一条DML语句,以内存为缓存镜像,在内存中模拟数据表,填充到数据镜像,应用程序将构造的一条DML语句和数据镜像发送到数据库管理系统;
S102、数据库管理系统解析应用程序构造的一条DML语句,安全性和完整性控制,并发和事务控制,数据库管理系统向数据库所在的磁盘发送底层数据集;
S103、计算好地址和偏移量之后,将底层数据集一次性写入数据库所在的磁盘;
S2、读取数据;
S201、应用程序构造一条DML查询语句并发送给数据库管理系统,在内存中模拟数据表,提供数据镜像填充地址;
S202、数据库管理系统解析应用程序所发送的一条DML查询语句,安全性和完整性控制,并发和事务控制,一次性读取数据库所在的磁盘,获取底层数据集后填充数据镜像;
S203、数据库管理系统向应用程序发送数据镜像。
作为本发明的进一步改进,在Windows下换用原生ODBC连接数据库。
作为本发明的进一步改进,数据的检查和转换在内存中处理完成之后再提交到数据库管理系统。
本发明的有益效果是:通过上述方案,有效的提高了数据库的访问效率。
附图说明
图1是本发明一种金融领域关系型数据库高性能访问方法的访问示意图。
图2是现有技术中传统数据库的访问示意图。
具体实施方式
下面结合附图说明及具体实施方式对本发明进一步说明。
如图1所示,一种金融领域关系型数据库高性能访问方法,其包括以下步骤:
S1、写入数据;
S101、应用程序计算好字段的长度,构造一条DML语句,以内存为缓存镜像,在内存中模拟数据表,填充到数据镜像,应用程序将构造的一条DML语句和数据镜像发送到数据库管理系统;
S102、数据库管理系统(DBMS)解析应用程序构造的一条DML语句,安全性和完整性控制,并发和事务控制,数据库管理系统向数据库所在的磁盘发送底层数据集;
S103、计算好地址和偏移量之后,将底层数据集一次性写入数据库所在的磁盘;
S2、读取数据;
S201、应用程序构造一条DML查询语句并发送给数据库管理系统,在内存中模拟数据表,提供数据镜像填充地址;
S202、数据库管理系统解析应用程序所发送的一条DML查询语句,安全性和完整性控制,并发和事务控制,一次性读取数据库所在的磁盘,获取底层数据集后填充数据镜像;
S203、数据库管理系统向应用程序发送数据镜像。
本发明提供的一种金融领域关系型数据库高性能访问方法,在Windows下换用更有效率的原生ODBC(开放数据库连接)连接数据库,因为封装过的数据库API往往更通用但效率更低;由于在计算机内存里处理数据远比DBMS解析数据要快,尽量把数据检查和转换在内存中处理完成后再提交到DBMS,鉴于证券交易领域的特殊性,券商端系统对交易所接口处理只有插入和读取,没有修改和删除操作的特点,计算好字段的长度,以内存为缓存镜像完全把数据表模拟出来,计算好地址和偏移量再一次性更新到数据库所在磁盘上;将数据处理完成后再提交DBMS,与之前的提交DML操作语句相比,涉及较大数据量的网络传输,但刚好可以利用长期处于空闲状态的局域网优质网络带宽,特别是下行链路带宽,在内存中完成数据处理且在高速网络上传输数据的处理时延两者累加,而吞吐量取小,最终得到的这两个指标值都比提交语句到DBMS处理要好上超过一个数量级;对数据库查询操作对上行链路带宽本来也有占用,但这里不再使用数据库API定义的数据集,而是通过绑定数据库对应表上的字段类型,在内存中为其预先开辟空间,简化了DBMS构造数据集的工作,且相当于通过网络通信将数据拷贝到应用程序内存数据结构,也方便了应用程序后续的处理;这种方式让DBMS;考虑到批量处理完毕数据再一次性提交比单条处理完毕后单条提交有更好的性能,实现按线程处理所分配时间实现多线程批量提交。
本发明提供的一种金融领域关系型数据库高性能访问方法,经相同的环境下实验,该访问方式比传统关系型数据库访问在性能方面能提高十倍。考虑DBMS是瓶颈,充分利用空闲的优质网络带宽,且SQL语句在DBMS只解析一次。即便原先是批量提交SQL语句,也是一条条在DBMS中执行的,本方法为批量提交数据。事先构造内存参数集作为数据表映射。对于插入操作,计算数据集空间,取参数集第一条记录精确绑定对应的所有参数/列类型和长度,整备好数据,尽可能接近内存拷贝的效果;对于查询操作,根据数据表各列的数据类型和长度预留数据集空间,查询结果将以内存数据集的形式返回,即反向的内存拷贝。
本发明提供的一种金融领域关系型数据库高性能访问方法,适合金融领域量化交易/程序化交易等对访问关系型数据库有高性能、高可用、高可靠需求应用场景,本发明对所运行的操作系统平台没有要求,但建议尽量使用原生态的ODBC,并将应用程序与所要操作的数据库部署于同一操作系统或位于局域网内能达到更佳效果。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!