一种基于预过滤的大规模图中三角形计算方法与流程
本发明属于图算法领域,尤其涉及大规模图中的三角形计算方法。
背景技术:
在抽象化数据的过程中,图结构是一个非常有效的数据结构。它在众多领域中有着重要应用,例如它可以用来表示互联网、社交网络、道路网络等等。随着图的规模变得越来越大,图上的大量结构挖掘问题亟待解决,引起众多研究者的关注。其中一个重要的基础问题就是三角形计算,即寻找图中由三个顶点组成的三元组△(u,v,w),使得任意两个点对(u,v),(v,w)和(w,u)之间各存在一条边。三角形计算问题是图算法中的一个基本操作,在图上的很多计算问题中起着重要作用。例如,它可用来实现对社区发现中具有重要意义的k-truss算法,还可以用来计算图的基本属性包括聚类系数(clustering coefficient)等。
随着现代社会中图的规模越来越大,三角形计算问题面临着很多新的挑战。如何从如此大规模的数据中快速计算出所有的三角形是目前的应用瓶颈。通常,我们需要借助分布式的计算平台,才能在较短的时间内处理规模较大的图。现有的三角形计算方法大都依赖于MapReduce计算平台。MapReduce本身源自于函数式语言,主要通过"Map(映射)"和"Reduce(化简)"这两个步骤来并行处理大规模的数据集。首先,Map函数以键值对<Key,Value>的形式读入数据,并且对于每一条数据进行指定的操作,并创建多个新的列表来保存Map的处理结果,可高度并行。当Map工作完成后,系统会接着对新生成的多个列表进行清理(Shuffle)和排序。最后,会对这些新创建的列表进行Reduce操作,即对一个列表中的元素根据由map函数设定的Key值进行适当的合并。MapReduce不仅能用于处理大规模数据,而且能自动进行并行化、负载均衡和灾备管理等。此外,MapReduce的伸缩性非常好,即随着服务器数目的增加,计算能力具有显著提高。尽管如此,现有的基于MapReduce平台的三角形计算方法仍然无法高效的处理大规模图(例如包含十亿以上顶点和边的图)。其主要原因在于生成三角形之前,现有的方法需要输出所有的可能构成三角形的楔形结构∨(u,v,w),使得u和v之间存一条边,且v和w之间存在一条边。这种楔形结构的数目通常非常庞大(常为三角形数目的几倍甚至几十倍),造成大量的中间结果在shuffle阶段产生,因而阻碍了现有三角形计算方法在大规模图上的应用,且造成很高的计算开销。
技术实现要素:
本发明针对现有技术的不足,提供一种基于预过滤的大规模图中三角形计算方法。
本发明的技术方案为一种基于预过滤的大规模图中三角形计算方法,包含以下步骤:
一种基于预过滤的大规模图中三角形计算方法,其特征在于,包含以下步骤:
步骤1、生成一个空间有效的用来存储图中所有的边的布隆过滤器,能够过滤掉不能组成三角形的楔形结构,减少中间结果的输出,具体是:首先获得图G=(V,E)中边的总个数|E|;定义将布隆过滤器B划分为P片,标记为B1,B2,…,BP,根据已知的边数来计算每个布隆过滤器分片中应该包含的边数目数Ci;然后依据Ci,在每一台机器上,输入相应数量的边,并生成布隆过滤器的分片Bi;最后获取所有机器上的布隆滤波器,合并其为完整的布隆过滤器B;
步骤2、生成所有的楔形结构W,并且载入布隆过滤器B,用来对生成的楔形结构W进行预过滤;具体是:首先将整个图G载入,以获取G中由有序边组成的集合E’;针对每个顶点u,将它具有较大顶点ID的邻居顶点加入到集合N+(u)中;同时将布隆过滤器的每个分片B[i]依次载入分布式缓存中;最后,对于每个顶点u,取出其中的任意两个邻居顶点v,w∈N+(u),利用布隆过滤器B检查顶点v和w之间是否存在一条边;如果存在,将楔形结构∨(v,u,w)输出到集合W’中,完成预过滤;
步骤3、对于W’中的所有楔形结构∨(v,u,w),做进一步的检查,判断边(v,w)是否在图的边集E中真实存在,然后输出所有的三角形;具体是:首先读入步骤2中输出的楔形结构∨(v,u,w)∈W’以及图G的边集E,将二者进行统一形式的输出;即对于任意的楔形结构∨(v,u,w),将其输出为三元组((v,w),u),对于任意的边(v,w)∈E,加入空顶点$,将输出为三元组((v,w),$);最后,将所有由(v,w)引导的三元组合并成统一的列表((v,w),x),其中x∈S∪{$}且S={u|∨(v,u,w)∈W’};最后,基于输出结果,对于任意顶点对(v,w),先检查((v,w),$)是否存在,若存在,则遍历所有的顶点u∈S,输出三角形△(v,u,w);否则,放弃所有由(v,w)引导的楔形结构∨(v,u,w)(其中u∈S)。
在上述的基于预过滤的大规模图中三角形计算方法,步骤1中,基于MapReduce以分布式计算的方式,生成一个空间有效的分布式布隆过滤器,用于存储图中所有的边,具体是:
步骤1.1、通过Map函数,读入图G=(V,E)中所有的边,对于每条边,将其ID较小的节点输出;假设将布隆过滤器B划分为P片,标记为B1,B2,…,BP,计算每个布隆过滤器分片中应该包含的边数Ci;
步骤1.2、在Reduce函数中,对于每一个u,收集所有与它邻接的边(u,v),组成列表List(v),然后把在列表中的每个边(u,v)加入到布隆滤波器分片B[hash(u)]中;这样就生成了所有的布隆过滤器分片B1,B2,…,BP;
步骤1.3、最终,将每一个布隆过滤器分片B[i]输出到MapReduce的HDFS文件上,将布隆过滤器分片组成完整的布隆过滤器B。
在上述的基于预过滤的大规模图中三角形计算方法,
步骤2中,利用MapReduce平台,生成所有的楔形结构W,同时载入布隆过滤器B到MapReduce的分布式缓存中,用来对生成的楔形结构W进行预过滤;
步骤2.1、通过Map函数,将整个图G中的所有边E载入,对于任意的一个边(u,v)∈E,比较顶点u和v的ID(图中的所有顶点ID按degree大小升序排列),若顶点u的ID小于顶点v的ID,将边(u,v)利用Emit函数输出,进而获得图G中由有序边组成的集合E’;对于每个顶点u,将它具有较大顶点ID的邻居加入到集合N+(u)中;同时将布隆过滤器的每个分片B[i]依次载入MapReduce分布式缓存中;
步骤2.2、在Reduce函数中,读取Map函数的输入结果;对于每个顶点u,取出其中的任意两个邻居顶点v,w∈N+(u),并利用布隆过滤器B检查顶点v和w之间是否存在一条边;如果存在,将楔形结构∨(v,u,w)利用Emit函数输出到集合W’中,完成预过滤;若果不存在,则放弃词楔形结构。
本发明具有如下优点:利用布隆过滤器的空间有效性,采用预过滤的方法,减少楔形结构的输出,进而减少中间结果,能有效地提高大规模图中三角形的计算效率。
附图说明:
图1是本发明实施例的基于预过滤的三角形计算方法流程图。
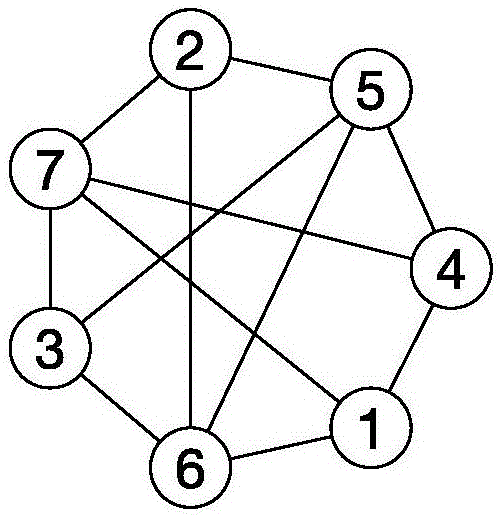
图2是本发明实施例的样本图。
图3是本发明实施例的样本图中包含的所有楔形结构。
图4是本发明实施例的预过滤示意图。
图5是本发明实施例的样本图的三角形输出结果。
具体实施方式
本发明主要基于布隆过滤器,结合布隆过滤器空间有效且能够判断集合中元素存在的特性,提出一种基于布隆过滤器进行预过滤的大规模图中三角形计算方法。本方法充分考虑了三角形产生过程中间结果过大的问题,通过预过滤,极大的减少中间输出结果,进而提高计算效率。通过本发明,我们对大规模图中三角形计算将变得切实可行,且更加高效。
本发明提供的方法能够用计算机软件技术实现流程。参见图1,实施例以MapReduce平台为例对本发明的流程进行一个具体的阐述,如下:
步骤1:首先我们利用MapReduce平台,以分布式计算的方式,生成一个空间有效的分布式布隆过滤器,用来存储图中所有的边。这个布隆过滤器能够帮助我们过滤掉不可能组成三角形的楔形结构,减少中间结果的输出,进而大幅度提高计算效率。首先我们给出在分布式环境下计算布隆过滤器的方法。
实施例在MapReduce平台上的具体实施过程如下:
首先,通过Map函数,读入图G=(V,E)中所有的边,对于每条边,将其ID较小的节点输出。假设将布隆过滤器B划分为P片,标记为B1,B2,…,BP,计算每个布隆过滤器分片中应该包含的边数Ci。
然后,在Reduce函数中,对于每一个u,收集所有与它邻接的边(u,v),组成列表List(v),然后把在列表中的每个边(u,v)加入到布隆滤波器分片B[hash(u)]中。这样就生成了所有的布隆过滤器分片B1,B2,…,BP。
最终,将每一个布隆过滤器分片B[i]输出到MapReduce的HDFS文件上,将布隆过滤器分片组成完整的布隆过滤器B。
步骤2:利用MapReduce平台,生成所有的楔形结构W,同时载入布隆过滤器B到MapReduce的分布式缓存中,用来对生成的楔形结构W进行预过滤。
实施例在MapReduce平台上的具体实施过程如下:
通过Map函数,将整个图G中的所有边E载入,对于任意的一个边(u,v)∈E,比较顶点u和v的ID(图中的所有顶点ID按degree大小升序排列),若顶点u的ID小于顶点v的ID,将边(u,v)利用Emit函数输出,进而获得图G中由有序边组成的集合E’。对于每个顶点u,将它具有较大顶点ID的邻居加入到集合N+(u)中;同时将布隆过滤器的每个分片B[i]依次载入MapReduce分布式缓存中。
在Reduce函数中,读取Map函数的输入结果。对于每个顶点u,取出其中的任意两个邻居顶点v,w∈N+(u),并利用布隆过滤器B检查顶点v和w之间是否存在一条边。如果存在,将楔形结构∨(v,u,w)利用Emit函数输出到集合W’中,完成预过滤;若果不存在,则放弃词楔形结构。
以图2中的样本图G为例,阐述本实施例在样本图上的作用过程。经过上述步骤产生的所有楔形结构如图3所示,包括∨(4,1,6)、∨(4,1,7)、∨(6,1,7)、∨(5,3,6)、∨(5,4,7)、∨(5,2,6)、∨(5,2,7)、∨(6,2,7)、∨(5,3,7)、∨(7,3,6)。通过布隆过滤器进行过滤后,我们得到如图4所示的结果,其中图的上部为没有通过布隆过滤器的6个楔形结构,包括∨(5,4,7)、∨(5,3,7)、∨(5,2,7)、∨(6,1,7)、∨(6,2,7)、∨(6,3,7)。图的下部为通过布隆过滤器的4个楔形结构,包括∨(4,1,6)、∨(4,1,7)、∨(5,2,6)、∨(5,3,6)。
步骤3:在MapReduce平台上,对于W’中的所有楔形结构∨(v,u,w),做进一步的检查,判断边(v,w)是否在图的边集E中真实存在,然后输出所有的三角形。具体过程如下:
首先,在Map函数中,读入步骤2输出的所有楔形结构∨(v,u,w)∈W’以及图G的边集E,将二者进行统一形式的输出。即对于任意的楔形结构∨(v,u,w),利用Emit函数将其输出为键值对<(v,w);u>,对于任意的边(v,w)∈E,加入空顶点$,利用Emi t函数将输出为键值对<(v,w);$>。最后,将所有由(v,w)键值引导的键值对组合成统一的列表<(v,w);x>,其中x∈S∪{$}且S={u|∨(v,u,w)∈W’}。
最后,在Reduce函数中,基于上述输出结果,对于任意顶点对(v,w),首先,检查<(v,w),$>是否存在,若存在,则遍历所有的u∈S,并利用emit函数输出<(v,w);u>,即三角形△(v,u,w);否则,放弃所有由(v,w)引导的楔形结构∨(v,u,w)(其中u∈S)。
我们以图2中的样本图G为例,阐述本实施例在样本图上的作用过程。步骤3以图4中过滤后的楔形结构作为输入,输出的三角形如图5所示,包括△(4,1,7)、△(5,2,6)、△(5,3,6),而楔形结构10各楔形结构∨(4,1,6)因为边(4,6)在图中并未真是存在而被放弃。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!