基于页面分类的内存页面回收方法及系统与流程
本发明涉及计算机操作系统以及虚拟化技术领域,尤其涉及一种基于页面分类的内存页面回收方法及系统。
背景技术:
随着计算机硬件性能的不断提高,如何让软件更加有效的使用现代硬件的强大计算能力一直都是产业界和学术界关注的焦点。硬件虚拟化技术的出现为该问题的解决提供一个全新的解决方案。在硬件虚拟化技术的支撑下,多台虚拟的客户机可以在同一台物理主机上同时运行,这极大的提高了主机的硬件利用效率。然而,多台虚拟机竞争物理主机资源的矛盾又日益的凸显了出来。
内存是计算机系统中最重要的硬件资源之一,如何有效的管理和分配内存一直都是操作系统领域的一个研究方向。在历史的发展中,操作系统对内存的管理经过了实地址空间管理、分段式管理以及分页式管理,并最终在分页机制的支持下实现了虚地址空间管理和页面交换机制——即将内存中的页面交换至磁盘以提升内存可使用的总量。在虚拟化环境下对内存页面的管理是对上述历史发展的沿革,其关键的任务在于两点:1)及时将一台客户机中不再使用的内存进行回收并分配给有内存需求的另一台客户机;2)提高换页机制的效率,即不要对无效页面进行换页操作,例如,将客户机中的空闲页面交换到磁盘上就是一种典型的无效操作,其浪费了大量的系统资源。
KVM是Kernel-based Virtual Machine的简写,其意为基于内核的虚拟机。KVM是专门为Linux内核开发的虚拟化基础设施,通过将KVM模块插入内核就可以使得Linux变成一个虚拟机监控器,并在其上运行虚拟的客户机。当前,在以KVM为基础的虚拟化环境中主要实现了三种对内存的管理机制:
(1)页面交换:物理机有内存压力时进行,根据LRU算法将较长时间未使用的页面交换到磁盘上。物理机的内存压力能及时降低,但有磁盘访问的开销。另外,物理机对客户机内存的实际使用情况并不了解,无法做到高效地管理客户机内存。这种内存管理机制就是传统的操作系统内存管理机制,其并未针对虚拟化环境进行优化。
(2)气球技术(memory ballooning):客户机内安装有驱动程序,由物理机指示该驱动在客户机上控制内存“气球”的大小,在物理机上管理“气球”所对应的内存。内存压力从物理机转移到客户机中,可根据客户机内存使用情况较为高效地回收内存页面。这种机制最主要的问题在于:1)如何确定“气球”的大小,即应该从一台客户机中拿走多少内存;2)由客户机将内存页面写入磁盘的开销要比由主机来执行的开销大。
(3)KSM(Kernel Samepage Merging):即内核相同页面合并,用一个内核线程扫描客户机进程所使用的内存区域,合并相同内容页面,写时复制。该机制的问题在于:1)需要消耗较多的处理器资源且时效性较差;2)不一定能够显著地减轻内存压力,需要根据页面内容的重复程度而定。
技术实现要素:
本发明是针对KVM虚拟化环境提出的。如上所述,当前KVM虚拟化环境中的三种内存管理机制存在着各自的缺点,但归结起来这三种方法所存在的最根本的问题在于:主机系统并不真正了解客户机系统对内存的具体使用情况。
针对上述问题,本发明提供一种基于页面分类的内存页面回收方法及系统,该方法及系统提高了KVM虚拟化系统内存页面回收的效率,从而使得当主机系统处于较大内存压力时的性能得到提升。
针对上述目的,本发明所采用的技术方案为:
一种基于页面分类的内存页面回收方法,其步骤包括:
1)定时循环扫描主机中所有内存页面所对应的“struct page”结构,并根据该“struct page”结构分析内存页面在主机中的页面类型;
2)当内存页面在主机中的页面类型为匿名页面时根据主机内核提供的逆向映射关系判断内存页面是否属于客户机进程,求出属于客户机进程的内存页面在客户机中的“struct page”结构,并根据该“struct page”结构分析内存页面在客户机中的页面类型;
3)根据上述页面分类信息将所有页面链接到相应类型的链表上;
4)读取每种类型页面的数量,按照客户机页面分类的回收顺序模型确定当前时刻的回收策略,并根据该回收策略回收内存页面。
进一步地,在步骤1)之后还包括:根据步骤1)中的“struct page”结构中的mapping成员的值的最低比特位是否置位来判断当前内存页面在主机中是否属于匿名页面,若置位则属于匿名页面。
进一步地,步骤2)中采用自省方法求出属于客户机进程的内存页面在客户机中的“struct page”结构;所述自省方法是指将客户机地址快速转换为主机地址;所述求出属于客户机进程的内存页面在客户机中的“struct page”结构是指将客户机中“struct page”结构的GVA(客户机虚拟地址)转换为HPA(主机物理地址),其转换步骤为:
a)利用公式GPAstruct page=GFN*sizeof(struct page)+gva_to_gpa(VMEMMAP),将GVA转换为GPA(客户机物理地址);
b)利用KVM以及主机的页表所提供的信息将GPA转化为HPA。
进一步地,步骤4)中所述客户机页面分类的回收顺序模型是指以不活跃页面优先于活跃页面、文件缓存页面优先于匿名页面为原则所确立的页面回收顺序,即按照如下的顺序来对内存页面进行回收:客户机空闲页面>=主机不活跃文件缓存页面>=客户机不活跃文件缓存页面>=主机不活跃匿名页面>=客户机不活跃匿名页面>=主机活跃文件缓存页面>=客户机活跃文件缓存页面>=主机活跃匿名页面>=客户机活跃匿名页面。
进一步地,当一个正在执行的进程向主机系统申请内存而该主机系统中的空闲内存小于阈值时,主机系统回收内存页面,其中阈值的大小由确定。
更进一步地,根据内存页面被访问的频率将主机系统中所有被使用的内存页面分为活跃页面集合和不活跃页面集合,当主机系统执行内存页面回收时,其步骤包括:
a)将内存页面从活跃页面集合转移到不活跃页面集合中;
b)从不活跃页面集合中选择最不活跃页面进行回收。
更进一步地,步骤a)中所述将内存页面从活跃页面集合转移到不活跃页面集合中的方法步骤包括:
1)选定所有属于活跃页面集合中的页面,并重新检查活跃页面集合中每个页面在客户机中的页面类型;
2)按照客户机空闲页面>=客户机不活跃文件缓存页面>=客户机活跃文件缓存页面>=客户机不活跃匿名页面>=客户机活跃匿名页面>=主机活跃文件缓存页面>=主机活跃匿名页面的优先级顺序从活跃页面集合中对应的虚拟LRU链表中选择一定数量的页面并将其放入相应类型的不活跃页面集合中。
更进一步地,步骤b)中所述从不活跃页面集合中选择最不活跃页面进行回收的方法步骤包括:
1)按照客户机空闲页面>=客户机不活跃文件缓存页面>=客户机活跃文件缓存页面>=客户机不活跃匿名页面>=客户机活跃匿名页面>=主机不活跃文件缓存页面>=主机不活跃匿名页面的优先级顺序从不活跃页面集合中对应的虚拟LRU链表中选择一定数量的页面;
2)如果选取的页面属于客户机空闲页面,则直接将该页面转化为主机空闲页面;
3)如果选取的页面属于客户机不活跃文件缓存页面,则首先将该页面在客户机中所对应的“struct page”结构中flags成员的PG_update标志位清零,然后再将该页面转换为主机空闲页面;
4)如果是其它类型的页面,则首先将其内存写入磁盘上的SWAP空间(即交换分区)中,然后再将该页面转换为主机空闲页面。
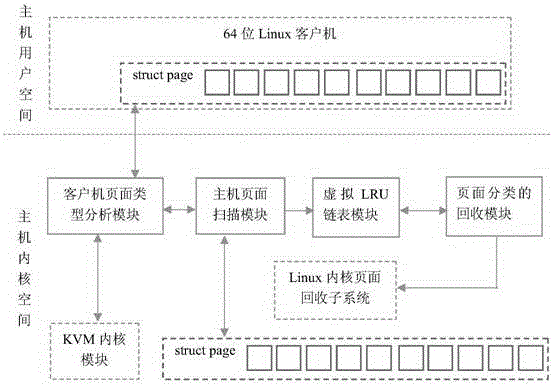
一种基于页面分类的内存页面回收系统,包括主机页面扫描模块、客户机页面类型分析模块、虚拟LRU链表模块和页面分类的回收模块;
所述主机页面扫描模块用于定时循环扫描主机中所有内存页面所对应的“struct page”结构,并根据该“struct page”结构中的相关信息判断该内存页面是否属于客户机进程,如果是则发给客户机页面类型分析模块对该内存页面进行分析并将分析结果发给虚拟LRU链表模块;
所述客户机页面类型分析模块用于对从所述主机页面扫描模块发来的分析请求进行页面分析,之后将分析结果返回给所述主机页面扫描模块;并且该模块利用自省方法求出客户机中的“struct page”结构,并根据该“struct page”结构分析内存页面在客户机中的页面类型;
所述虚拟LRU链表模块用于接收所述主机页面扫描模块发送的页面分类信息,将页面链接到相应的类型链表上;并且当页面分类的回收模块发出请求时,从相应虚拟LRU链表上取出相应的内存页面以供回收;
所述页面分类的回收模块用于从所述虚拟LRU链表模块中读取每种类型页面的数量,按照客户机页面分类的回收顺序模型确定当前时刻的回收策略,并根据该回收策略向虚拟LRU链表模块请求需要回收的类型页面,之后将需要回收的页面传递给Linux内存页面回收子系统。
进一步地,所述页面分类的回收模块还对客户机空闲页面和客户机文件缓存页面进行了专门的优化处理,使得在回收这两种页面时不需要进行磁盘写入。
本发明提供一种基于页面分类的内存页面回收方法及系统,首先使用自省方法(即不需要对客户机进行任何修改)分析出客户机的页面类型,然后提出了一种客户机页面分类的回收顺序模型,最后根据该模型来对系统中的页面进行回收。
本发明的积极效果体现在如下方面:1)由于识别出了客户机中的空闲页面从而避免了将客户机空闲页面写入磁盘中交换空间的无效操作;2)尽可能的避免了将客户机中的文件缓存页面写入磁盘中交换空间,减小了对磁盘交换区的读写所带来的I/O压力;3)提出了一种更加精确的回收顺序模型,从而使得最不活跃的页面被最优先换出,减小了将活跃页面交换到磁盘上所带来的多次换页的问题。也就是说,本发明是对当前KVM虚拟化环境中三种已有的内存管理技术的改进,本发明提高了KVM虚拟化系统内存页面回收的效率,从而使得当系统处于较大内存压力时的性能得到提升。
附图说明
图1为本发明客户机页面分类的回收顺序模型示意图。
图2为本发明基于页面分类的内存页面回收系统总体结构示意图。
图3为本发明基于页面分类的内存页面回收方法流程示意图。
图4为本发明页面类型分析流程示意图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
在Linux系统中,内存页面分为三类:匿名页面(Anonymous Page)、文件缓存页面(File Cache Page)以及空闲页面(Free Page)。其中,根据页面活跃程度的不同又可以把匿名页面分为活跃匿名页面(Active Anonymous Page)与不活跃匿名页面(Inactive Anonymous Page),把文件缓存页面分为活跃文件缓存页面(Active File Cache Page)与不活跃文件缓存页面(Inactive File Cache Page)。在KVM虚拟化环境(插入了KVM模块的Linux系统)中,KVM客户机被主机当中一个进程来进行管理,所以KVM客户机所使用的内存页面全部都被主机认定为匿名页面。然而,客户机中的Linux操作系统将其自身所使用的内存页面同样划分成上述的三类。正是这种主机与客户机对同一页面的不同认识导致了主机对内存页面进行了不当的回收。
本发明提出的正是一种根据客户机页面类型来确定页面回收顺序的方法和系统。本发明首先使用自省的方法(即不需要对客户机进行任何修改)分析出客户机的页面类型;然后提出了一种客户机页面分类的回收顺序模型,如图1所示,原有的页面回收顺序为主机不活跃文件缓存页面>=主机不活跃匿名页面>=主机活跃文件缓存页面>=主机活跃匿名页面,在考虑了客户机的页面类型后,回收的顺序调整为客户机空闲页面>=主机不活跃文件缓存页面>=客户机不活跃文件缓存页面>=主机不活跃匿名页面>=客户机不活跃匿名页面>=主机活跃文件缓存页面>=客户机活跃文件缓存页面>=主机活跃匿名页面>=客户机活跃匿名页面;最后根据该模型来对系统中的页面进行回收。
本发明提供一种基于页面分类的页面回收系统,该系统对于所有的用户均是透明的,系统不需要任何配置,并且随着主机系统的启动而自动启动。该系统总体结构示意图如图2所示,该系统由四大模块组成,分别阐述如下:
(1)主机页面扫描模块:该模块将定时的循环扫描主机中所有内存页面所对应的“struct page”结构,然后根据该结构中的相关信息判断该页面是否属于客户机进程,如果页面被判定属于客户机进程,则通知客户机页面类型分析模块对该页面进行深度分析以得出其在客户机中的具体类型。
(2)客户机页面类型分析模块:该模块接收从主机页面扫描模块发来的分析请求,在对页面分析后将分析结果返回主机页面扫描模块。该模块首先利用KVM内核模块中所提供的信息实现一种在64位环境下将客户机地址快速转换为主机地址的自省方法;然后利用这种方法求出客户机中的“struct page”结构;最后根据客户机中的“struct page”结构分析出页面所属的客户机类型。
(3)虚拟LRU链表模块:该模块实现16条分类虚拟的LRU链表(每条链表链接着同一类型的页面),在接收主机页面扫描模块发送的页面分类信息后,该模块将页面链接到相应的类型链表上。该模块的另一个功能是当页面分类的回收模块发出请求时,从相应虚拟LRU链表上取出相应的页面以供回收。
(4)页面分类的回收模块:该模块首先从虚拟LRU链表模块中读取每种类型页面的数量;然后按照客户机页面分类的回收顺序模型确定当前时刻的回收策略;接着根据策略向虚拟LRU链表模块请求需要回收的类型页面;最后将需要回收的页面传递给Linux内存页面回收子系统以完成最终的回收。另外,该模块针对客户机空闲页面(Guest Free Page)和客户机文件缓存页面(Guest File Cache Page)进行了专门的优化处理,使得在回收这两种页面时不需要进行磁盘写入,从而减小了整个系统的I/O次数,最终大大的提高了系统的效率。
本发明还提供一种在KVM虚拟化环境下基于页面分类的内存页面回收方法,该方法流程示意图如图3所示,其步骤包括:
1)扫描页面。当虚拟化主机环境启动之后,主机系统内核将启动内核扫描线程vmm_scan。该内核扫描线程将周期性的扫描系统中的每一个页面,每扫描完一遍之后扫描线程将休息1秒钟。
2)分析页面类型。当一个内存页面被扫描到之后,系统将对该页面的类型进行分析。在Linux内核中使用“struct page”结构来记录系统中内存页面的使用状态,每一个内存页面都对应这一个“struct page”结构的实例。当系统分析一个页面的类型时,实质上是在分析该内存页面所对应的“struct page”结构中各个成员的状态。
请参考图4,该图为本发明页面类型分析流程示意图。对于本发明方法及系统而言,只需要分析成员“flags”、“mapping”、“_count”和“_mapcount”的状态就可以得到页面的类型。其中“_count”成员记录了引用该页面的对象的个数,所以当“_count”成员的值为零的时候就表明该页面为空闲页面。“_mapcount”成员记录了引用该页面的页表的个数,如果“_count”的值不为零而“_mapcount”的值为零就表明该页面被系统内核所使用,即内核页面。当页面被用户进程所使用时,“mapping”成员记录了页面是被用于匿名页面还是用于文件缓存页面,当“mapping”成员的值的最低比特位置位时,表明该页面为匿名页面。“flags”成员的“PG_active”标志位记录了页面是否是活跃页面(Active Page)。当“mapping”代表匿名页面时,“PG_active=1”表明该页面为活跃匿名页面,“PG_active”不为1表明该页面为不活跃匿名页面;当“mapping”不代表匿名页面(即用于文件缓存页面)时,“PG_active=1”表明该页面为活跃文件缓存页面,“PG_active”不为1表明该页面为不活跃文件缓存页面。
如果要得到对一个页面的完整分类,系统需要分别分析页面在主机中的类型以及在客户机中的类型,最后将这两个结果进行综合从而得出完整的分类结果。在实际的执行过程中,系统将首先读取页面在主机中的“struct page”结构然后分析其类型,当且仅当页面在主机中属于匿名页面时(客户机被主机当成一个进程来管理,而进程所使用的内存都被主机定义为匿名页面),系统才尝试读取页面在客户机中的“struct page”结构并分析其在客户机中的类型。
当系统要读取页面在客户机中的“struct page”结构就必须首先将该结构在客户机中的地址转换为主机中的地址。在一个虚拟化的系统中,一共存在四类地址:主机物理地址(Host Physical Address,简称HPA)、主机虚拟地址(Host Virtual Address,简称HVA)、客户机物理地址(Guest Physical Address,简称GPA)和客户机虚拟地址(Guest Virtual Address,简称GVA)。与这四类地址相关的还有HFN(Host Frame Number主机页帧号)和GFN(Guest Frame Number客户机页帧号)。系统读取页面在客户机中的“struct page”结构其本质就是要将客户机中“struct page”结构的GVA转换为HPA。具体的转换分两个步骤来进行:1)使用公式GPAstruct page=GFN*sizeof(struct page)+gva_to_gpa(VMEMMAP)来将GVA转换为GPA;2)利用KVM以及主机的页表所提供的信息将GPA转化为HPA,从而最终可以读取和分析客户机中的“struct page”结构。
3)建立分类队列。在回收内存页面时,根据回收策略,系统会确定当前时刻需要进行回收的页面类型以及数量。为了在回收时尽可能快的找到需要回收的相应类型的页面,系统在对页面进行类型分析之后将把页面链接到相应页面类型的链表上,即建立分类队列。分类队列模块主要提供如下功能:1)将页面加入到一个对应特定页面类型的队列;2)从一个特定类型的队列中取出一个页面;3)获取某一个队列当前所含有的页面的个数;4)根据一个给定的页面,查询其所属的队列。为了快速判断页面是否在某一个队列中,为分类队列模块设计了位图机制:每一条队列都关联了一个对应主机系统中所有页面的位图。当页面入队列时,队列所关联的位图中的相应比特位将被置位;而当页面出队列时,其相应的比特位将被清零。这样,当需要确定某一个页面是否属于某个队列时,只需要检测其相应的比特位而不需要对整个队列进行遍历,从而大大的加速了查询的过程。此外,由于对页面的回收是一个并发执行的过程,分类队列模块中设计了锁机制,每一个队列都对应了一个互斥锁,当页面被添加到队列或者被从队列中删除的时候都必须进行加锁和解锁的操作,这样就可以保证队列的完整性和有效性。
4)执行回收。对系统中内存页面的回收并不是在任何时候都进行的,系统中设有一个阈值,当且仅当一个执行中进程向系统申请内存而此时系统中的空闲内存小于阈值时回收程序才被执行,其中阈值的大小由确定。在主机系统中(站在主机的角度),对于每一个被进程使用的内存页面,根据其被访问的频率被分为活跃页面集合与不活跃页面集合。当主机系统执行页面回收时,其过程实际分为了两个步骤:1)将页面从活跃页面集合转移到不活跃页面集合中;2)从不活跃页面集合中选择最不活跃页面进行回收。
本系统在执行活跃度转换时将按照如下顺序执行:1)选定所有属于活跃页面集合中的页面,并重新检查活跃页面集合中每个页面在客户机中的页面类型;2)按照客户机空闲页面>=客户机不活跃文件缓存页面>=客户机活跃文件缓存页面>=客户机不活跃匿名页面>=客户机活跃匿名页面>=主机活跃文件缓存页面>=主机活跃匿名页面的优先级顺序从活跃页面集合中对应的虚拟LRU链表中选择一定数量的页面并将其放入相应类型的不活跃页面集合中。
本系统在执行最终页面回收时将按照如下顺序执行:1)按照客户机空闲页面>=客户机不活跃文件缓存页面>=客户机活跃文件缓存页面>=客户机不活跃匿名页面>=客户机活跃匿名页面>=主机不活跃文件缓存页面>=主机不活跃匿名页面的优先级顺序从不活跃页面集合中对应的虚拟LRU链表中选择一定数量的页面;2)如果选取的页面属于客户机空闲页面,则直接将该页面转化为主机空闲页面;3)如果选取的页面属于客户机不活跃文件缓存页面(Guest Inacitve File Page),则首先将该页面在客户机中所对应的“struct page”结构中flags成员的PG_update标志位清零,然后再将该页面转换为主机空闲页面;4)如果是其它类型的页面,则首先将其内存写入磁盘上的SWAP空间(交换分区)中,然后再将该页面转换为主机空闲页面。
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!