一种CPU+多GPU异构模式静态安全分析计算方法与流程
本发明涉及电力系统自动化调度技术领域,尤其涉及一种CPU+多GPU异构模式静态安全分析计算方法。
背景技术:
随着电力系统调度一体化技术的快速发展,电网计算规模日趋扩大。在全网状态估计断面基础上进行静态安全分析计算,计算速度将难以满足需求。一方面,需要进行开断分析的预想事故数目大幅度增大,即使通过直流法筛选,需要详细开断扫描的预想故障数目也将非常可观。另一方面,每个预想事故进行开断潮流模拟计算,计算节点数增大,造成单潮流计算速度缓慢。此外,电网规模的扩大造成需要越限监视的设备数和稳定断面数大幅度增加,计算量持续增大。因此,现代电力系统的迅速发展,对调度系统静态安全分析应用在计算上的性能问题提出了严峻的考验。传统串行算法采用直流法筛选结合基于稀疏矩阵的局部因子分解等手段进行串行工程化处理,过滤非严重故障,有效提高单次开断分析速度,但仍然无法满足工程应用需求。
求解过程发现,静态安全分析预想故障之间相互解耦相互独立,可分解为多个独立的全潮流计算,具有并行化处理先天优势,这种特性逐渐受到研究人员关注,并开始尝试采用并行算法寻求突破。
近年来,计算机领域英伟达公司提出了CUDA(Compute Unified Device Architecture)架构,为GPU(Graphic Processing Unit,图形处理器)发展提供了良好的并行计算框架,能够适用于电力系统具有并行特性的研究领域。同时,在CPU领域,用于共享内存并行系统的OpenMP多线程技术,由编译器自动将循环并行化,能够有效提高多处理器系统应用程序性能。
综上,对于静态安全分析快速扫描应用场景,如何有效使用GPU并行和CPU并行技术,满足工程现场对调度自动化系统静态安全分析应用计算规模及计算效率越来越高的需求,是值得深思探究的研究方向。
技术实现要素:
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种CPU+多GPU异构模式静态安全分析计算方法,针对实际工程应用中大电网静态安全分析快速扫描的需求,在CUDA统一计算框架平台上,根据系统GPU配置情况和计算需求,采用OpenMp多线程技术分配相应线程数,每个线程与单个GPU唯一对应,基于CPU与GPU混合编程开发,构建CPU+多GPU异构计算模式协同配合完成预想故障并行计算,在单个预想故障潮流计算基础上,实现多个开断潮流迭代过程高度同步并行,通过元素级细粒度并行大幅提高静态安全分析预想故障扫描并行处理能力,为互联大电网一体化调度系统在线安全分析预警扫描提供了有力的技术支撑。
为实现上述目的,本发明提供了一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,在CUDA统一计算平台上,采用基于共享内存并行系统的OpenMP多线程技术,综合考虑GPU配置情况及预想故障计算需求,确定CPU线程数目,构建CPU+多GPU异构模式,每块GPU卡内部按照CPU+单GPU模式协同配合完成并行扫描任务,在单个预想故障潮流计算基础上,实现多个开断潮流迭代过程高度同步并行,通过元素级细粒度并行大幅提高静态安全分析预想故障扫描并行处理能力。
上述的一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,包括以下步骤:
1)获取状态估计实时断面,基于牛顿-拉夫逊算法进行基态潮流计算,提供一个可供复用共享的数据断面;
2)根据用户需求,对全网设备进行拓扑扫描,形成预想故障集,针对每个预想故障进行深度拓扑搜索,形成实际开断支路-节点信息;
3)初始化CUDA架构,根据多开断并行计算需求将数据进行打包处理,并分配GPU内存空间;
4)根据GPU配置情况和实际计算量,对开断计算资源进行合理化分配,评估需要启用的GPU数目,采用OpenMP技术生成相应的线程数,以最大程度发挥GPU并行计算能力;
5)在CPU的统筹下,潮流计算迭代过程,包括导纳阵修正雅克比矩阵求解、修正方程求解、状态量更新、支路潮流计算及设备越限校核,全部交由GPU并行完成,所有开断故障迭代高度并行,根据每一步计算任务的并行特性构造相应的内核函数,在细粒度并行层面上完成迭代过程中元素并行计算任务;
6)判断预想故障是否全部扫描完成,如果否,则转入步骤4),对剩余的开断故障重新进行资源分配,如果全部完成,则转入步骤7;
7)结果展示,根据扫描结果,对故障开断造成的设备或断面越限重载信息进行展示,并根据调度系统静态安全分析模块实用化需求进行扫描结果统计。
上述的一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,所述步骤4)具体包括:
(1)根据开断计算需求和GPU配置情况,优化分配开断计算资源,评估单块GPU单次最大扫描开断数:
其中,S_max为GPU卡总内存空间,S为单个潮流计算所需内存大小,M_max为单块GPU卡所能计算的最大开断数;
根据式(1),计算所需启动的GPU卡数目为:
其中,α表示为取整,n为本轮所需启动的GPU卡数,N为系统配置的GPU卡总数,M_cal为本轮静态安全分析所需计算的开断总数,M_max·N为多GPU一次计算开断能力;
根据式(2),按照平均分配原则,每块卡实际计算开断数:
当M_max·N≤M_cal,意味着GPU全部参与计算无法一次完成所有开断计算,则将剩余开断M_cal′重新按照式(2-3)进行新一轮分配,分批多次计算,计算公式为:
M_cal′=M_cal-M_max·N (4)
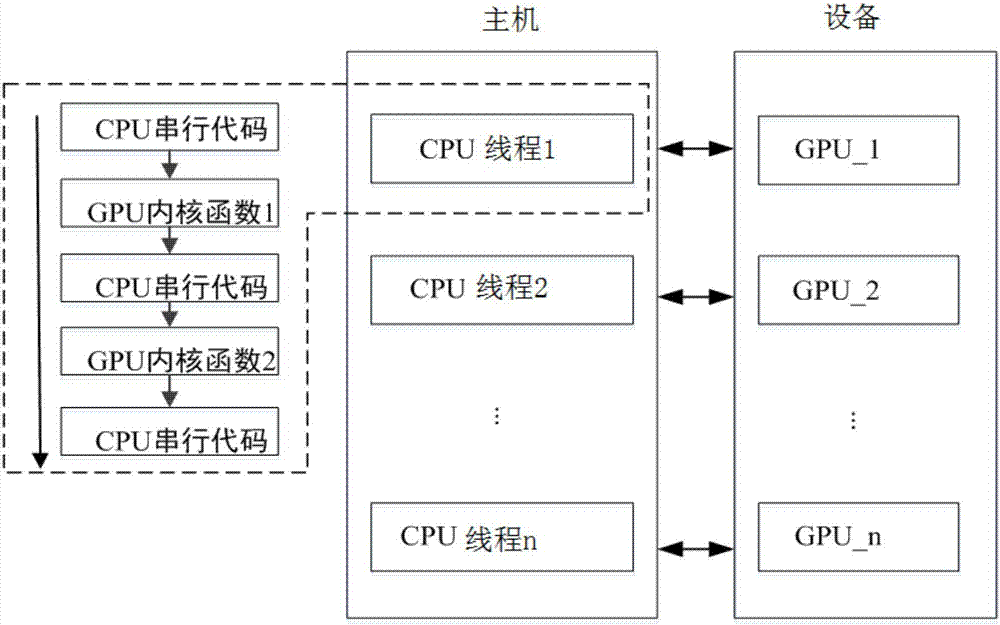
(2)在共享复用的基态断面模型数据基础上,基于OpenMP多线程技术根据实际运行GPU卡数目n分配相应的CPU线程数,每个CPU线程与单个GPU唯一对应,构建CPU+多GPU异构模式,在单个GPU卡内按照CPU+单GPU异构模式进行并行运算。
上述的一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,所述步骤5)包括以下步骤:
(1)在基态导纳阵Y0基础上,根据N-1开断支路-节点信息,定义内核函数fun_kernel_1,对分配至该卡的开断故障同时进行节点导纳阵局部修正工作,并修改节点注入信息,通过导纳阵和节点信息的变化来模拟设备开断;
(2)根据(1)形成开断导纳阵Ym,完成雅克比矩阵元素并行计算任务,为便于调用CUDA内核函数,潮流计算雅克比分块矩阵中各元素采用如下计算公式:
其中,Gii,Bii,Gij,Bij分别为导纳阵非零元,θij为i,j节点相角差,Pi,Qi为i节点注入功率,Vi,Vj分别为i,j节点电压幅值;
分块矩阵各元素均为状态量节点电压相角,导纳阵元素及三角函数的四则基本运算且求解过程互不影响,具有明显的并行特性;
分别定义4个内核函数对应计算分块矩阵中各元素值,单卡内,m个开断故障雅克比H矩阵计算量:
h=m×hnozero (9)
其中,hnozero为H阵非零元数,m为开断数;
在CUDA架构中,GPU具有多个SM流处理器,可提供多个线程调用。h个元素之间没有任何耦合关系,具有高度的元素级细粒度并行特性,按式(5)定义内核函数fun_kernel_2_H完成式向量乘和向量加操作,CPU调用fun_kernel_2_H函数,GPU根据fun_kernel_2_H传入函数参数启用h个GPU多线程,同时完成式(5)并行操作;
(3)根据(1)形成的开断导纳阵Ym和初始节点注入量,按照式(10)
进行节点注入功率残差计算:
其中,Pis,Qis分别为节点i的有功、无功注入量,由上式可以看出,各节点注入量残差均为状态量节点电压相角,导纳阵元素及三角函数的四则基本运算,与其他节点功率残差求解过程互不依赖,定义fun_kernel_3内核函数,启用SM流处理器中多个线程,完成m个开断故障所有计算节点功率不平衡量的并行计算任务,详细并行计算过程与步骤(2)相似;
(4)检查功率残差是否满足收敛判断依据,如果满足,则跳转至(8),如果不满足,则继续转入(5)进行迭代;
首先,定义fun_kernel_4内核函数,GPU对各开断节点功率残差按式(11)进行收敛检查,如果某开断满足收敛条件,则记录该开断收敛;
||ΔPt,ΔQt||<ε t≤T (11)
其中,ε为功率收敛判据,ΔPt,ΔQt分别为迭代t次的功率偏差,T为最大迭代次数;
再次,由于各开断故障收敛迭代步数不一致,设定k≥80%开断故障已收敛,则结束潮流迭代过程,否则所有开断故障继续进行潮流迭代,直至满足k≥80%收敛条件或者达到最大迭代次数,跳转至步骤(8);
(5)对(2)所形成的雅克比矩阵进行LU分解,结合(3)计算的节点功率残差进行线性方程组求解,定义fun_kernel_5内核函数,对线性方程组进行任务级并行求解;
(6)由(5)所得的线性方程组解对初始状态向量按式(12)进行更新
式中,分别为线性方程组第i个潮流方程式状态向量第k次迭代前、迭代后值,为第k次修正值,n为系统节点数,r为PV节点数;
由上式可见,迭代过程中每一个节点向量更新前后仅与该节点增量相关,不依赖于其他任何节点计算值,具有并行天然属性,可通过GPU多线程并行实现节点电压更新任务;
将式(12)定义为一个加运算的内核函数fun_kernel_6,对于M个预想故障并行任务,共需要M×(2(n-1)-r)个线程同步执行fun_kernel_6完成一次状态量更新计算;
(7)跳转至(2)继续迭代;
(8)根据当前收敛的开断故障潮流计算结果,进行支路潮流计算,由于支路潮流仅和支路参数及两侧节点电压值相关,互不依赖,定义fun_kernel_7内核函数,完成支路潮流并行计算。
(9)根据(8)支路潮流计算结果,对各支路或稳定断面进行重载越限校验,并保存当前所有开断故障造成的重载越限结果,定义fun_kernel_8内核函数,完成支路支路或稳定断面重载越限校验并行计算。
本发明的有益效果是:
本发明基于OpenMP技术的CPU+多GPU异构模式静态安全分析方法,在CUDA统一计算框架平台上,能够根据系统GPU配置情况和计算需求,采用OpenMp多线程技术分配相应线程数,构建CPU+多GPU异构计算模式协同配合完成预想故障并行计算,在单个预想故障潮流计算基础上,实现多个开断潮流迭代过程高度同步并行,有效提升静态安全分析预想故障扫描并行处理能力,适用于调度一体化大规模系统对静态安全分析预想故障快速扫描应用场景,对提升大电网静态安全分析扫描计算效率具有非常重要的应用价值。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
图1 CPU+多GPU异构模式计算流程图;
图2 CPU+多GPU异构模式结构示意图;
图3雅克比分块矩阵H元素并行计算示意图。
具体实施方式
本发明的目的在于提出一种适用于静态安全分析的快速并行方法。针对实际工程应用中大电网静态安全分析快速扫描的需求,在CUDA统一计算框架平台上,根据系统GPU配置情况和计算需求,采用OpenMp多线程技术分配相应线程数,每个线程与单个GPU唯一对应,基于CPU与GPU混合编程开发,构建CPU+多GPU异构计算模式协同配合完成预想故障并行计算,在单个预想故障潮流计算基础上,实现多个开断潮流迭代过程高度同步并行,通过元素级细粒度并行大幅提高静态安全分析预想故障扫描并行处理能力,为互联大电网一体化调度系统在线安全分析预警扫描提供了有力的技术支撑。
如图1所示,一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,在CUDA统一计算平台上,采用基于共享内存并行系统的OpenMP多线程技术,综合考虑GPU配置情况及预想故障计算需求,确定CPU线程数目,构建CPU+多GPU异构模式,每块GPU卡内部按照CPU+单GPU模式协同配合完成并行扫描任务,在单个预想故障潮流计算基础上,实现多个开断潮流迭代过程高度同步并行,通过元素级细粒度并行大幅提高静态安全分析预想故障扫描并行处理能力。
上述的一种CPU+多GPU异构模式静态安全分析计算方法,其特征在于,包括以下步骤:
1)获取状态估计实时断面,基于牛顿-拉夫逊算法进行基态潮流计算,提供一个可供复用共享的数据断面;
2)根据用户需求,对全网设备进行拓扑扫描,形成预想故障集,针对每个预想故障进行深度拓扑搜索,形成实际开断支路-节点信息;
3)初始化CUDA架构,根据多开断并行计算需求将数据进行打包处理,并分配GPU内存空间;
4)根据GPU配置情况和实际计算量,对开断计算资源进行合理化分配,评估需要启用的GPU数目,采用OpenMP技术生成相应的线程数,以最大程度发挥GPU并行计算能力,OpenMP技术是一套用于共享内存并行系统多线程程序设计的指导性编译处理方案;
5)在CPU的统筹下,潮流计算迭代过程,包括导纳阵修正雅克比矩阵求解、修正方程求解、状态量更新、支路潮流计算及设备越限校核,全部交由GPU并行完成,所有开断故障迭代高度并行,根据每一步计算任务的并行特性构造相应的内核函数,在细粒度并行层面上完成迭代过程中元素并行计算任务;
6)判断预想故障是否全部扫描完成,如果否,则转入步骤4),对剩余的开断故障重新进行资源分配,如果全部完成,则转入步骤7;
7)结果展示,根据扫描结果,对故障开断造成的设备或断面越限重载信息进行展示,并根据调度系统静态安全分析模块实用化需求进行扫描结果统计。
本实施例中,所述步骤4)具体包括:
(1)根据开断计算需求和GPU配置情况,优化分配开断计算资源,评估单块GPU单次最大扫描开断数:
其中,S_max为GPU卡总内存空间,S为单个潮流计算所需内存大小,M_max为单块GPU卡所能计算的最大开断数;
根据式(1),计算所需启动的GPU卡数目为:
其中,α表示为取整,n为本轮所需启动的GPU卡数,N为系统配置的GPU卡总数,M_cal为本轮静态安全分析所需计算的开断总数,M_max·N为多GPU一次计算开断能力;
根据式(2),按照平均分配原则,每块卡实际计算开断数:
当M_max·N≤M_cal,意味着GPU全部参与计算无法一次完成所有开断计算,则将剩余开断M_cal′重新按照式(2-3)进行新一轮分配,分批多次计算,计算公式为:
M_cal′=M_cal-M_max·N (4)
(2)在共享复用的基态断面模型数据基础上,基于OpenMP多线程技术根据实际运行GPU卡数目n分配相应的CPU线程数,每个CPU线程与单个GPU唯一对应,构建CPU+多GPU异构模式,如图2所示,在单个GPU卡按照CPU+单GPU异构模式进行并行运算。
本实施例中,所述步骤5)包括以下步骤:
(1)在基态导纳阵Y0基础上,根据N-1开断支路-节点信息,定义内核函数fun_kernel_1,对分配至该卡的开断故障同时进行节点导纳阵局部修正工作,并修改节点注入信息,通过导纳阵和节点信息的变化来模拟设备开断;
(2)根据(1)形成开断导纳阵Ym,完成雅克比矩阵元素并行计算任务,为便于调用CUDA内核函数,潮流计算雅克比分块矩阵中各元素采用如下计算公式:
其中,Gii,Bii,Gij,Bij分别为导纳阵非零元,θij为i,j节点相角差,Pi,Qi为i节点注入功率,Vi,Vj分别为i,j节点电压幅值;
分块矩阵各元素均为状态量节点电压相角,导纳阵元素及三角函数的四则基本运算且求解过程互不影响,具有明显的并行特性;
分别定义4个内核函数对应计算分块矩阵中各元素值,单卡内,m个开断故障雅克比H矩阵计算量:
h=m×hnozero (9)
其中,hnozero为H阵非零元数,m为开断数;
在CUDA架构中,GPU具有多个SM流处理器,可提供多个线程调用。h个元素之间没有任何耦合关系,具有高度的元素级细粒度并行特性,按式(5)定义内核函数fun_kernel_2_H完成式向量乘和向量加操作,H阵元素多线程并行计算如图3所示,CPU调用fun_kernel_2_H函数,GPU根据fun_kernel_2_H传入函数参数启用h个GPU多线程,每一个线程对应于H阵中一个非零元,在t0时刻按照式(5)并发执行,共同完成雅克比矩阵元素生成工作;
(3)根据(1)形成的开断导纳阵Ym和初始节点注入量,按照式(10)进行节点注入功率残差计算:
其中,Pis,Qis分别为节点i的有功、无功注入量,由上式可以看出,各节点注入量残差均为状态量节点电压相角,导纳阵元素及三角函数的四则基本运算,与其他节点功率残差求解过程互不依赖,定义fun_kernel_3内核函数,启用SM流处理器中多个线程,完成m个开断故障所有计算节点功率不平衡量的并行计算任务,详细并行计算过程与步骤(2)相似;
(4)检查功率残差是否满足收敛判断依据,如果满足,则跳转至(8),如果不满足,则继续转入(5)进行迭代;
首先,定义fun_kernel_4内核函数,GPU对各开断节点功率残差按式(11)进行收敛检查,如果某开断满足收敛条件,则记录该开断收敛;
||ΔPt,ΔQt||<ε t≤T (11)
其中,ε为功率收敛判据,ΔPt,ΔQt分别为迭代t次的功率偏差,T为最大迭代次数;
再次,由于各开断故障收敛迭代步数不一致,设定k≥80%开断故障已收敛,则结束潮流迭代过程,否则所有开断故障继续进行潮流迭代,直至满足k≥80%收敛条件或者达到最大迭代次数,跳转至步骤(8);
(5)对(2)所形成的雅克比矩阵进行LU分解,结合(3)计算的节点功率残差进行线性方程组求解,定义fun_kernel_5内核函数,对线性方程组进行任务级并行求解;
(6)由(5)所得的线性方程组解对初始状态向量按式(12)进行更新
式中,分别为线性方程组第i个潮流方程式状态向量第k次迭代前、迭代后值,为第k次修正值,n为系统节点数,r为PV节点数;
由上式可见,迭代过程中每一个节点向量更新前后仅与该节点增量相关,不依赖于其他任何节点计算值,具有并行天然属性,可通过GPU多线程并行实现节点电压更新任务;
将式(12)定义为一个加运算的内核函数fun_kernel_6,对于M个预想故障并行任务,共需要M×(2(n-1)-r)个线程同步执行fun_kernel_6完成一次状态量更新计算;
(7)跳转至(2)继续迭代;
(8)根据当前收敛的开断故障潮流计算结果,进行支路潮流计算,由于支路潮流仅和支路参数及两侧节点电压值相关,互不依赖,定义fun_kernel_7内核函数,完成支路潮流并行计算。
(9)根据(8)支路潮流计算结果,对各支路或稳定断面进行重载越限校验,并保存当前所有开断故障造成的重载越限结果,定义fun_kernel_8内核函数,完成支路支路或稳定断面重载越限校验并行计算。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!