一种基于聚类和余弦相似度的物流推荐方法与流程
本发明属于聚类方法和推荐方法技术领域,特别涉及一种基于聚类和余弦相似度的物流推荐方法。
背景技术:
物流推荐方法对物流领域货物的运输效率的提高有重要的作用和意义,传统的物流只是提供简单的位移,现代物流则提供增值服务,人工的挑选货物或货车已经不能满足物流领域的需求。近年来针对不同的推荐系统的需求,研究者提出了相应的个性化推荐方案,如基于内容推荐,协同过滤,关联规则,效用推荐,组合推荐等。
朱全银等人已有的研究基础包括:朱全银,潘禄,刘文儒,等.Web科技新闻分类抽取算法[J].淮阴工学院学报,2015,24(5):18-24;李翔,朱全银.联合聚类和评分矩阵共享的协同过滤推荐[J].计算机科学与探索,2014,8(6):751-759;Quanyin Zhu,Sunqun Cao.A Novel Classifier-independent Feature Selection Algorithm for Imbalanced Datasets.2009,p:77-82;Quanyin Zhu,Yunyang Yan,Jin Ding,Jin Qian.The Case Study for Price Extracting of Mobile Phone Sell Online.2011,p:282-285;Quanyin Zhu,Suqun Cao,Pei Zhou,Yunyang Yan,Hong Zhou.Integrated Price Forecast based on Dichotomy Backfilling and Disturbance Factor Algorithm.International Review on Computers and Software,2011,Vol.6(6):1089-1093;朱全银等人申请、公开与授权的相关专利:朱全银,胡蓉静,何苏群,周培等.一种基于线性插补与自适应滑动窗口的商品价格预测方法.中国专利:ZL 2011 1 0423015.5,2015.07.01;朱全银,曹苏群,严云洋,胡蓉静等,一种基于二分数据修补与扰乱因子的商品价格预测方法.中国专利:ZL 2011 1 0422274.6,2013.01.02;朱全银,尹永华,严云洋,曹苏群等,一种基于神经网络的多品种商品价格预测的数据预处理方法.中国专利:ZL 2012 1 0325368.6;李翔,朱全银,胡荣林,周泓.一种基于谱聚类的冷链物流配载智能推荐方法.中国专利公开号:CN105654267A,2016.06.08;曹苏群,朱全银,左晓明,高尚兵等人,一种用于模式分类的特征选择方法.中国专利公开号:CN 103425994 A,2013.12.04;朱全银,严云洋,李翔,张永军等人,一种用于文本分类和图像深度挖掘的科技情报获取与推送方法.中国专利公开号:CN 104035997 A,2014.09.10;朱全银,辛诚,李翔,许康等人,一种基于K means和LDA双向验证的网络行为习惯聚类方法.中国专利公开号:CN 106202480 A,2016.12.07。
AP聚类方法:
Affinity Propagation聚类简称AP,是一种在2007年发表在Science上的新的聚类方法。
AP方法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。AP方法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的样本,同时将其余的数据点分配到相应的聚类中。
SDbw聚类效果衡量方法:
SDbw是一种基于密度的指标,它通过对比类内的紧密度和类间的密度来评估聚类的有效性,当该指标达到最小时的聚类是最优聚类,而且聚类结果与方法无关。
K-means聚类方法:
K-means聚类方法是硬聚类方法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。该方法采用误差平方和准则函数作为聚类准则函数。
余弦相似度:
余弦相似度,又称为余弦相似性。通过计算两个向量的夹角余弦值来评估他们的相似度。
传统的方法在用于物流推荐时需要在整个数据集上搜索目标用户的最近邻居,随着电子商务系统规模越来越大,用户数量和项目数量的急剧增加,在整个数据集上搜索目标用户的最近邻居非常耗时,越来越难以满足推荐系统的实时性要求。因此,需要找到一种在不影响推荐效果的前提下,提高推荐算法运行效率的方法。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种通过对货车和货物的数据处理然后聚类,再将货主和车主的信息处理,给货主推荐运输车辆,给车主推荐运输货物,最终达到提高物流运输效率目的的基于聚类和余弦相似度的物流推荐方法。
技术方案:为解决上述技术问题,本发明提供一种基于聚类和余弦相似度的物流推荐方法,包括如下步骤:
步骤一:对货物数据集和货车数据集进行预处理,并使用AP聚类方法、SDbw聚类衡量方法和K-means聚类方法确定货物数据集和货车数据集的聚类个数最佳K值;
步骤二:根据步骤一中确定的最佳聚类个数,对货物数据集和货车数据集使用K-means聚类,并分别使用货物数据集和货车数据集聚类得到的结果训练出两个分类器;
步骤三:需要货车推荐的货主输入货物信息,货物信息经过归一化处理,使用步骤二中货车数据集训练出的分类器分类,需要货物推荐的车主输入车辆信息,车辆信息经过归一化处理,使用步骤二中车辆数据集训练出的分类器分类;
步骤四:使用余弦相似度方法计算步骤三中货主或车主经过归一化处理的数据与分类器分得的类中所有元素的相似度对货物数据集或货车数据集根据相似度从高到低排列,向用户推荐。
进一步的,所述步骤一中使用AP聚类方法、SDbw聚类衡量方法和K-means聚类方法确定货物数据集和货车数据集的聚类个数最佳K值的步骤如下:
步骤1.1:定义货车和货物数据集、对货车和货物数据集进行预处理;
步骤1.2:对货车和货物数据集使用AP聚类方法,得到类别数量;
步骤1.3:对货车和货物数据集使用K-means聚类方法,设定K值从2到步骤1.2得到的数值,使用SDbw聚类衡量方法衡量聚类效果,得到货车和货物数据的聚类最佳K值。
进一步的,所述步骤二中分别使用货物数据集和货车数据集聚类得到的结果训练出两个分类器的步骤如下:
步骤2.1:使用朴素贝叶斯分类器训练模型ModelA,训练数据为使用K-means聚类方法对货车数据聚类的结果,K值为步骤2确定的货车数据最佳聚类K值;
步骤2.2:使用朴素贝叶斯分类器训练模型ModelB,训练数据为使用K-means聚类方法对货物数据聚类的结果,K值为步骤2确定的货物数据最佳聚类K值。
进一步的,所述步骤三中分别使用货车数据集训练出的分类器和车辆数据集训练出的分类器进行分类的步骤如下:
步骤3.1:需要货车推荐的货主输入货物信息,将货物信息归一化处理后,使用分类器ModelA对货物信息分类,得到分类标签;
步骤3.2:需要货物推荐的车主输入车辆信息,将车辆信息归一化处理后,使用分类器ModelB对车辆信息分类,得到分类标签。
进一步的,所述步骤四中使用余弦相似度方法计算货主或车主经过归一化处理的数据与分类器分得的类中所有元素的相似度对货物数据集或货车数据集根据相似度从高到低排列,向用户推荐的步骤如下:
步骤4.1:使用余弦相似度方法,计算货主经过处理的信息与车辆数据集中与货物信息具有相同标签的信息的相似度,根据相似度从大到小进行推荐;
步骤4.2:使用余弦相似度方法,计算车主经过处理的信息与货物数据集中与车辆信息具有相同标签的信息的相似度,根据相似度从大到小进行推荐。
再进一步的,所述步骤一中使用AP聚类方法、SDbw聚类衡量方法和K-means聚类方法确定货物数据集和货车数据集的聚类个数最佳K值的详细步骤如下:
步骤101:设货车数据量为N条,货车数据的维度为M,建立货车数据集Crecords={C1,C2,…,CM},Crecords的元素Cm={c1,c2,c3,c4,c5}表示货车m的数据,c1,c2,c3,c4,c5,为Cm的五个维度,m∈[1,M],其中,c1表示车主希望的运输价格,c2表示货车剩余载重,c3表示货车的出发地,c4表示货车的目的地,c5表示货车运送的时间;
步骤102:定义循环变量为t,并赋初值t=1;
步骤103:当t<=M执行步骤204,否则执行步骤207;
步骤104:定义临时变量dis表示出发地和目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间;
步骤105:调用高德api计算Ct中从出发地c3到目的地c4的距离和时间,并分别赋值给dis和time,并用dis和time代替原Ct中的c3和c4;
步骤106:t=t+1,继续执行步骤203;
步骤107:对得到数据集SCrecords进行中心化和标准化处理,得到数据集SCrecords={SC1,SC2,…,SCM};
步骤108:使用PCA降维方法对数据集SCrecords进行降维,得到降维后的数据集Precord={P1,P2,…,PM};
步骤109:对降维后的数据使用AP聚类方法,得到类别标签Labels={L1,L2,…,LM},类别数量赋值给NUM;
步骤110:设定循环变量为n,并赋予初值n=2;
步骤111:当n<=NUM执行步骤212,否则执行步骤215;
步骤112:使用K-means聚类方法对数据集Precord进行聚类,得到货车类别标签Labels={L1,L2,…,LM};
步骤113:使用SDbw聚类衡量方法衡量本次聚类效果,得到的值赋予SDk;
步骤114:n=n+1,继续执行步骤211;
步骤115:设SD2,SD3,…,SDNUM中的最小值为SDmin;
步骤116:min即为货车数据集使用K-means聚类方法的最佳K值;
步骤117:设货物数据量为N条,货物数据的维度为M,建立货物数据集Trecords={T1,T2,…,TM},Trecords的元素Tm={t1,t2,t3,t4,t5}表示车辆m的数据,t1,t2,t3,t4,t5,为Tm的五个维度,m∈[1,M],其中,t1表示货物的运输价格,t2表示货物的重量,t3表示货物的出发地,t4表示货物的目的地,t5表示货物运送的时间;
步骤118:定义循环变量为t,并赋初值t=1;
步骤119:当t<=M执行步骤220,否则执行步骤223;
步骤120:定义临时变量dis表示出发地和目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间;
步骤121:调用高德api计算Tt中从出发地t3到目的地t4的距离和时间,并分别赋值给dis和time,并用dis和time代替原Tt中的t3和t4;
步骤122:t=t+1,继续执行步骤219;
步骤123:对得到数据集Trecords进行中心化和标准化处理,得到数据集STrecords={ST1,ST2,…,STM};
步骤124:使用PCA降维方法对数据集Srecords进行降维,得到降维后的数据集Precord={P1,P2,…,PM};
步骤125:对降维后的数据使用AP聚类方法,得到类别标签Labels={L1,L2,…,LM},类别数量赋值给NUM;
步骤126:设定循环变量为n,并赋予初值n=2;
步骤127:当n<=NUM执行步骤228,否则执行步骤231;
步骤128:使用K-means聚类方法对数据集Precord进行聚类,得到货物类别标签Labels={L1,L2,…,LM};
步骤129:使用SDbw聚类衡量方法衡量本次聚类效果,得到的值赋予SDk;
步骤130:n=n+1,继续执行步骤227;
步骤131:设SD2,SD3,…,SDNUM中的最小值为SDmin;
步骤132:min即为货物数据集使用K-means聚类方法的最佳K值。
再进一步的,所述步骤二中分别使用货物数据集和货车数据集聚类得到的结果训练出两个分类器的详细步骤如下:
步骤201:货车数据集Crecords经过中心化和标准化处理得到数据集SCrecords={SC1,SC2,…,SCM};
步骤202:使用K-means聚类方法对数据集SCrecords={SC1,SC2,…,SCM}进行聚类,K为步骤216得到的最佳K值,得到货车类别标签Labels={L1,L2,…,LM};
步骤203:使用朴素贝叶斯分类器,训练数据集为SCrecords={SC1,SC2,…,SCM},类别标签为Labels={L1,L2,…,LM},得到分类器ModelA;
步骤204:货物数据集Trecords经过中心化和标准化处理得到数据集STrecords={ST1,ST2,…,STM};
步骤205:使用K-means聚类方法对数据集STrecords={ST1,ST2,…,STM}进行聚类,K为步骤232得到的最佳K值,得到货车类别标签Labels={L1,L2,…,LM};
步骤206:使用朴素贝叶斯分类器,训练数据集为STrecords={ST1,ST2,…,STM},类别标签为Labels={L1,L2,…,LM},得到分类器ModelB。
再进一步的,所述步骤三中分别使用货车数据集训练出的分类器和车辆数据集训练出的分类器进行分类的详细步骤如下:
步骤301:推荐内容选择;
步骤302:当选择推荐货物时执行步骤407,否则执行步骤403;
步骤303:输入货物信息Trecord={t1,t2,t3,t4,t5},t1表示货物运输价格,t2表示货物重量,t3表示货物出发地,t4表示货物目的地,t5表示货物发车时间;
步骤304:定义临时变量dis表示出发地到目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间,调用高德api计算从出发地t3到目的地t4的经过的距离和花费的时间,并分别赋值给dis和time,然后用dis和time代替Trecord中的t3和t4;
步骤305:对货物信息Trecord进行中心和和标准化处理,得到数据STrecord={ST1,ST2,ST3,ST4,ST5};
步骤306:使用步骤303得到的分类器ModelA对数据STrecord分类,得到类别标签Tlabel;
步骤307:输入货车信息c1表示车主希望的运输价格,c2表示货车剩余载重,c3表示货车出发地,c4表示货车目的地,c5表示货车发车时间;
步骤308:定义临时变量dis表示出发地到目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间,调用高德api计算从出发地c3到目的地c4的经过的距离和花费的时间,并分别赋值给dis和time,然后用dis和time代替Crecord中的c3和c4;
步骤309:对货车信息Crecord进行中心和和标准化处理,得到数据SCrecord={SC1,SC2,SC3,SC4,SC5};
步骤310:使用步骤306得到的分类器ModelB对数据SCrecord分类,得到类别标签Clabel。
再进一步的,所述步骤四中使用余弦相似度方法计算货主或车主经过归一化处理的数据与分类器分得的类中所有元素的相似度对货物数据集或货车数据集根据相似度从高到低排列,向用户推荐的详细步骤如下:
步骤401:根据步骤305得到的标签,从数据集STrecords={ST1,ST2,…,STM}中抽取类别标签为Tlabel的数据组成新的数据集TTrecord={TT1,TT2,…,TTN};
步骤402:设定循环变量为n,并赋予初值n=1;
步骤403:当n<=N执行步骤504,否则执行506;
步骤404:使用余弦相似度方法,计算货车信息SCrecord={SC1,SC2,SC3,SC4,SC5}和货物数据集TTrecord={TT1,TT2,…,TTN}中的TTn相似度,并将值赋给SIMn;
步骤405:n=n+1继续执行步骤503;
步骤406:对数据集TTrecord={TT1,TT2,…,TTN}根据相似度值SIM从大大小进行排序;
步骤407:将经过排序的TTrecord从前往后推荐给车主;
步骤408:根据步骤302得到的标签,数据集SCrecords={SC1,SC2,…,SCM}中抽取类别标签为Clabel的数据组成新的数据集SSrecords={SS1,SS2,…,SSN};
步骤409:设定循环变量为n,并赋予初值n=1;
步骤410:当n<=N执行步骤511,否则执行步骤513;
步骤411:使用余弦相似度方法,计算货物信息STrecord={ST1,ST2,ST3,ST4,ST5}和货车数据集SSrecords={SS1,SS2,…,SSN}中的Ssn相似度,并将值赋给SIMn;
步骤412:n=n+1继续执行步骤510;
步骤413:对数据集SSrecords={SS1,SS2,…,SSN}根据相似度值SIM从大大小进行排序;
步骤414:将经过排序的SSrecords从前往后推荐给货主。
与现有技术相比,本发明的优点在于:
本发明相比现有的推荐方法本发明创造性的提出了一种将货车数据和货物数据通过AP聚类方法、SDbw聚类衡量方法和K-means聚类方法结合,得到了数据集的最佳聚类K值,再将数据根据K值聚类,训练分类器,然后将用户输入的信息分类,最终进行推荐的方法,本方法弥补了现有的推荐方法在整个数据集上搜索目标用户的最近邻居非常耗时的局限性,有效地提高了推荐方法的实时响应速度。
附图说明
图1为本发明的总体流程图;
图2为图1中确定货车数据集最佳K值的流程图;
图3为图1中确定货物数据集最佳K值的流程图;
图4为图1中训练货车分类模型的流程图;
图5为图1中训练货物分类模型的流程图;
图6为图1中用户输入信息分类方法的流程图;
图7为图1中货物推荐方法的流程图;
图8为图1中货车推荐方法的流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。
如图1所示,本发明包括如下步骤:
步骤101:对货物数据集和货车数据集进行预处理,并使用AP聚类方法、SDbw聚类衡量方法和K-means聚类方法确定货物数据集和货车数据集的最佳K值;
步骤102:根据计算出的最佳K值对货物数据集和货车数据集聚类,并使用朴素贝叶斯分类器根据货物数据集聚类得到的结果和货车数据集聚类得到的结果训练出两个分类器;
步骤103:需要货车推荐的货主输入货物信息,货物信息经过归一化处理,使用货车数据集训练出的分类器分类,需要货物推荐的车主输入车辆信息,车辆信息经过归一化处理,使用车辆数据集训练出的分类器分类;
步骤104:使用余弦相似度方法计算货主或车主经过归一化处理的数据与分类器分得的类中所有元素的相似度对货物数据集或货车数据集根据相似度从高到低排列,向用户推荐。
如附图2附图3,计算出最佳K值方法步骤101从步骤201到步骤232:
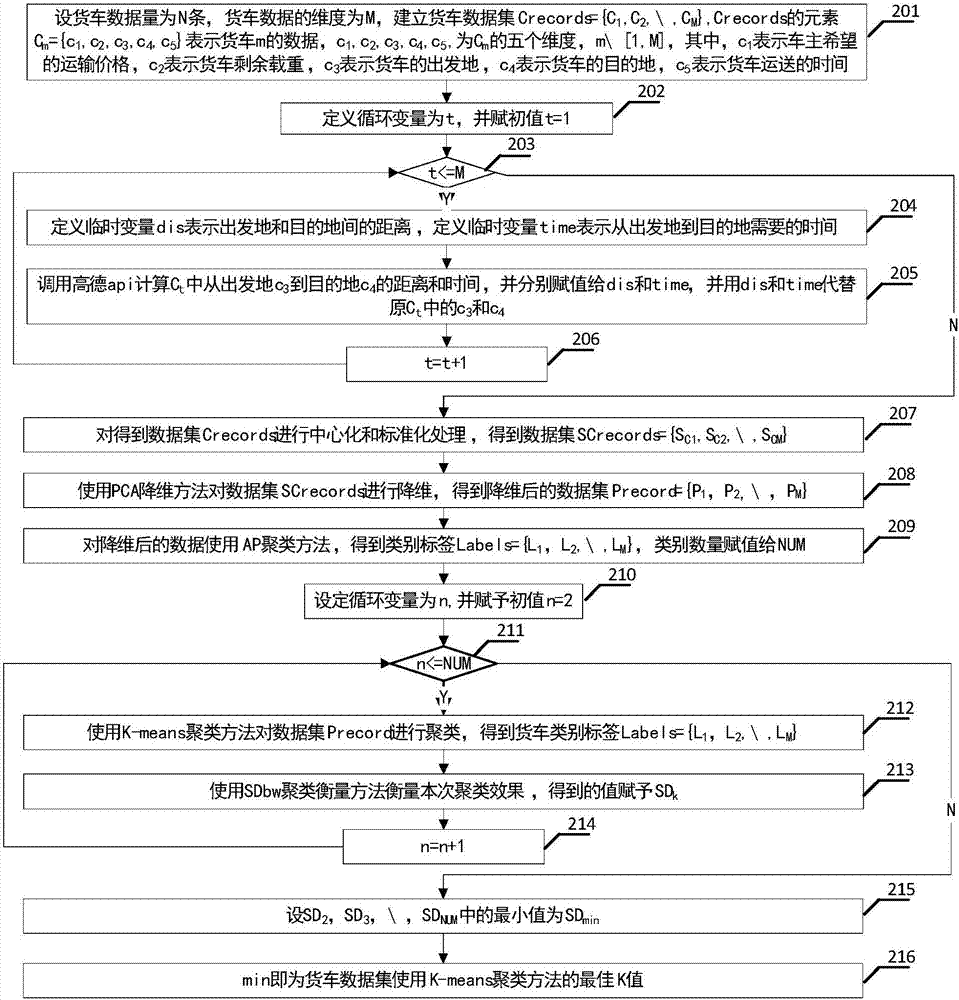
步骤201:设货车数据量为N条,货车数据的维度为M,建立货车数据集Crecords={C1,C2,…,CM},Crecords的元素Cm={c1,c2,c3,c4,c5}表示货车m的数据,c1,c2,c3,c4,c5,为Cm的五个维度,m∈[1,M],其中,c1表示车主希望的运输价格,c2表示货车剩余载重,c3表示货车的出发地,c4表示货车的目的地,c5表示货车运送的时间;
步骤202:定义循环变量为t,并赋初值t=1;
步骤203:当t<=M执行步骤204,否则执行步骤207;
步骤204:定义临时变量dis表示出发地和目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间;
步骤205:调用高德api计算Ct中从出发地c3到目的地c4的距离和时间,并分别赋值给dis和time,并用dis和time代替原Ct中的c3和c4;
步骤206:t=t+1,继续执行步骤203;
步骤207:对得到数据集SCrecords进行中心化和标准化处理,得到数据集SCrecords={SC1,SC2,…,SCM};
步骤208:使用PCA降维方法对数据集SCrecords进行降维,得到降维后的数据集Precord={P1,P2,…,PM};
步骤209:对降维后的数据使用AP聚类方法,得到类别标签Labels={L1,L2,…,LM},类别数量赋值给NUM;
步骤210:设定循环变量为n,并赋予初值n=2;
步骤211:当n<=NUM执行步骤212,否则执行步骤215;
步骤212:使用K-means聚类方法对数据集Precord进行聚类,得到货车类别标签Labels={L1,L2,…,LM};
步骤213:使用SDbw聚类衡量方法衡量本次聚类效果,得到的值赋予SDk;
步骤214:n=n+1,继续执行步骤211;
步骤215:设SD2,SD3,…,SDNUM中的最小值为SDmin;
步骤216:min即为货车数据集使用K-means聚类方法的最佳K值;
步骤217:设货物数据量为N条,货物数据的维度为M,建立货物数据集Trecords={T1,T2,…,TM},Trecords的元素Tm={t1,t2,t3,t4,t5}表示车辆m的数据,t1,t2,t3,t4,t5,为Tm的五个维度,m∈[1,M],其中,t1表示货物的运输价格,t2表示货物的重量,t3表示货物的出发地,t4表示货物的目的地,t5表示货物运送的时间;
步骤218:定义循环变量为t,并赋初值t=1;
步骤219:当t<=M执行步骤220,否则执行步骤223;
步骤220:定义临时变量dis表示出发地和目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间;
步骤221:调用高德api计算Tt中从出发地t3到目的地t4的距离和时间,并分别赋值给dis和time,并用dis和time代替原Tt中的t3和t4;
步骤222:t=t+1,继续执行步骤219;
步骤223:对得到数据集Trecords进行中心化和标准化处理,得到数据集STrecords={ST1,ST2,…,STM};
步骤224:使用PCA降维方法对数据集Srecords进行降维,得到降维后的数据集Precord={P1,P2,…,PM};
步骤225:对降维后的数据使用AP聚类方法,得到类别标签Labels={L1,L2,…,LM},类别数量赋值给NUM;
步骤226:设定循环变量为n,并赋予初值n=2;
步骤227:当n<=NUM执行步骤228,否则执行步骤231;
步骤228:使用K-means聚类方法对数据集Precord进行聚类,得到货物类别标签Labels={L1,L2,…,LM};
步骤229:使用SDbw聚类衡量方法衡量本次聚类效果,得到的值赋予SDk;
步骤230:n=n+1,继续执行步骤227;
步骤231:设SD2,SD3,…,SDNUM中的最小值为SDmin;
步骤232:min即为货物数据集使用K-means聚类方法的最佳K值;
如附图4附图5,根据最佳K值聚类并使用聚类结果训练分类器步骤102从步骤301到步骤306:
步骤301:货车数据集Crecords经过中心化和标准化处理得到数据集SCrecords={SC1,SC2,…,SCM};
步骤302:使用K-means聚类方法对数据集SCrecords={SC1,SC2,…,SCM}进行聚类,K为步骤216得到的最佳K值,得到货车类别标签Labels={L1,L2,…,LM};
步骤303:使用朴素贝叶斯分类器,训练数据集为SCrecords={SC1,SC2,…,SCM},类别标签为Labels={L1,L2,…,LM},得到分类器ModelA;
步骤304:货物数据集Trecords经过中心化和标准化处理得到数据集STrecords={ST1,ST2,…,STM};
步骤305:使用K-means聚类方法对数据集STrecords={ST1,ST2,…,STM}进行聚类,K为步骤232得到的最佳K值,得到货车类别标签Labels={L1,L2,…,LM};
步骤306:使用朴素贝叶斯分类器,训练数据集为STrecords={ST1,ST2,…,STM},类别标签为Labels={L1,L2,…,LM},得到分类器ModelB;
如附图6,将输入的货物或货车数据分类流程步骤103从步骤401到步骤410:
步骤401:推荐内容选择;
步骤402:当选择推荐货物时执行步骤407,否则执行步骤403;
步骤403:输入货物信息Trecord={t1,t2,t3,t4,t5},t1表示货物运输价格,t2表示货物重量,t3表示货物出发地,t4表示货物目的地,t5表示货物发车时间;
步骤404:定义临时变量dis表示出发地到目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间,调用高德api计算从出发地t3到目的地t4的经过的距离和花费的时间,并分别赋值给dis和time,然后用dis和time代替Trecord中的t3和t4;
步骤405:对货物信息Trecord进行中心和和标准化处理,得到数据STrecord={ST1,ST2,ST3,ST4,ST5};
步骤406:使用步骤303得到的分类器ModelA对数据STrecord分类,得到类别标签Tlabel;
步骤407:输入货车信息c1表示车主希望的运输价格,c2表示货车剩余载重,c3表示货车出发地,c4表示货车目的地,c5表示货车发车时间;
步骤408:定义临时变量dis表示出发地到目的地间的距离,定义临时变量time表示从出发地到目的地需要的时间,调用高德api计算从出发地c3到目的地c4的经过的距离和花费的时间,并分别赋值给dis和time,然后用dis和time代替Crecord中的c3和c4;
步骤409:对货车信息Crecord进行中心和和标准化处理,得到数据SCrecord={SC1,SC2,SC3,SC4,SC5};
步骤410:使用步骤306得到的分类器ModelB对数据SCrecord分类,得到类别标签Clabel;
如附图7附图8,根据分类得到结果计算余弦聚类并推荐步骤104从步骤501到步骤514:
步骤501:根据步骤305得到的标签,从数据集STrecords={ST1,ST2,…,STM}中抽取类别标签为Tlabel的数据组成新的数据集TTrecord={TT1,TT2,…,TTN};
步骤502:设定循环变量为n,并赋予初值n=1;
步骤503:当n<=N执行步骤504,否则执行506;
步骤504:使用余弦相似度方法,计算货车信息SCrecord={SC1,SC2,SC3,SC4,SC5}和货物数据集TTrecord={TT1,TT2,…,TTN}中的TTn相似度,并将值赋给SIMn;
步骤505:n=n+1继续执行步骤503;
步骤506:对数据集TTrecord={TT1,TT2,…,TTN}根据相似度值SIM从大大小进行排序;
步骤507:将经过排序的TTrecord从前往后推荐给车主;
步骤508:根据步骤302得到的标签,数据集SCrecords={SC1,SC2,…,SCM}中抽取类别标签为Clabel的数据组成新的数据集SSrecords={SS1,SS2,…,SSN};
步骤509:设定循环变量为n,并赋予初值n=1;
步骤510:当n<=N执行步骤511,否则执行步骤513;
步骤511:使用余弦相似度方法,计算货物信息STrecord={ST1,ST2,ST3,ST4,ST5}和货车数据集SSrecords={SS1,SS2,…,SSN}中的Ssn相似度,并将值赋给SIMn;
步骤512:n=n+1继续执行步骤510;
步骤513:对数据集SSrecords={SS1,SS2,…,SSN}根据相似度值SIM从大大小进行排序;
步骤514:将经过排序的SSrecords从前往后推荐给货主。
为了更好的说明本方法的有效性,通过对14998条物流数据进行聚类,得到数据集的最佳K值为3,设定K为3再使用K-means聚类方法对数据集聚类,得到待推荐数据集,采用余弦相似度计算得到最佳的前一百条推荐数据,再和传统的余弦相似度得到的前一百条推荐数据相比相似度达到95%,十次实验中,本方法最高提升效率为84.9%,最低提升效率为26.5%,平均提升效率为59.5%。
本发明可与计算机系统结合,从而自动完成物流领域中货物和货车的双向推荐。
本发明创造性的提出了一种将货车数据和货物数据通过AP聚类方法、SDbw聚类衡量方法和K-means聚类方法结合,得到了数据集的最佳聚类K值,再将数据根据K值聚类,训练分类器,然后将用户输入的信息分类,最终进行推荐的方法。
本发明提出的一种基于聚类和余弦相似度的物流推荐方法不但可以用于物流领域的货物货车推荐,也可以用于其他消费类商品的推荐。
以上所述仅为本发明的实施例子而已,并不用于限制本发明。凡在本发明的原则之内,所作的等同替换,均应包含在本发明的保护范围之内。本发明未作详细阐述的内容属于本专业领域技术人员公知的已有技术。
- 还没有人留言评论。精彩留言会获得点赞!