高可靠性的大数据日志采集与传输方法与流程
本发明涉及数据采集领域,具体而言涉及一种高可靠性的大数据日志采集与传输技术。
背景技术:
数据应用中,数据采集是一个非常重要的环节。而在互联网时代,大量的信息都存储在日志文件中,对用户数据挖掘、系统维护、系统改造都有重大意义。
但很多公司的系统分布在不同的物理地点,且每个节点都单独记录日志。因此若需要针对各地数据进行全面综合大数据分析,需要将各地零碎的日志采集至一套大数据平台中。现有技术已经使用flume+kafka+storm构建实时日志分析系统。Flume用于采集数据源、并以管道流方式,提供很多的默认实现,让用户通过参数部署,及扩展API。Kafka是一个可持久化的分布式的消息队列。Kafka是一个非常通用的系统。可以有许多生产者和很多的消费。Storm还是一个分布式的、容错的实时计算系统,由BackType开发,广泛用于进行实时日志处理,实时统计、实时风控、实时推荐等场景中。HDFS是分布式文件系统,HDFS采用单一主控机+多台工作机的模式,由一台主控机(Master)存储系统全部元数据,并实现数据的分布、复制、备份决策。
本发明通过开源工具kafka、storm、flume以及HDFS搭建了一套大数据日志采集平台,并通过设计数据传输校验流程,保证在日志传输过程中,不会因为网络中断或临时堵塞,或传输程序因为异常中断而导致日志数据传输丢失。
该发明可以广泛应用到通信、银行、财务、国防、资讯等众多领域。
技术实现要素:
本发明目的在于,提出一种高可靠性的大数据日志采集与传输方法,能够保证日志数据可以可靠采集。保证在日志传输过程中,不会因为网络中断或临时堵塞,或传输程序因为异常中断而导致日志数据传输丢失。
为达成上述目的,本发明所采用的技术方案:1、高可靠性的大数据日志采集与传输方法,其特征是步骤如下,
步骤1设计日志采集架构。设计可以实现并有利于日志采集的平台架构:
设有基于能够采集日志和校验日志的系统架构;flume部署至多个数据源上,flume用于采集数据源的日志数据并发送;Kafka作为数据传输模块,(一般)部署在网络中心节点(即可以快速连通各个数据源的服务器);storm和HDFS部署在最终数据汇总的大数据集群上;设有数据库,用于存储日志文件校验的信息,数据库可以部署在一台独立的服务器上或部署在大数据集群上;
日志校验的交互流程和算法步骤:通过数据源发送校验码的方式使大数据集群根据校验码触发校验;
通过文本校验的交互流程和算法步骤:通过解析获取校验码中数据源日志文件的行数与大数据集群中已获得的实际行数对比,判断文件是否应该重传;
步骤2数据恢复的流程和算法;保障数据因程序中断或网络中断而重新恢复的流程和算法。
进一步的,步骤2中,
1)flume读取目前日志文件;读取时会记录当前读取日志文件的偏移量;当因为断电或服务中断,下次启动时会接着上次读取的位置读取文件;
2)当数据源所在服务器会定时发送日志文件的校验信息至大数据集群上;
3)当大数据集群的storm接收到消息校验,会对存储在HDFS上的日志文件进行校验并将校验信息记录至数据库;若校验成功,则发送文件校验成功消息至数据源;若校验不成功,则发送文件重传请求至至数据源;
4)当数据源的flume接收到文件校验成功消息时,记录文件发送成功;当接收到文件重传请求时,重新发送日志文件。
进一步的,步骤3大数据集群对文件校验流程:
1)当接收到源节点flume发送的校验消息;
2)大数据集群中的storm根据校验消息读取HDFS上已上传的文件并计算文件上的实际行数;
3)将实际行数与校验信息中的校验行数对比,若不一致则发送重新上传请求;若成功,则发送文件成功消息。
其中,流程和算法设计是本发明的核心步骤。
本发明具有以下有益效果:
1)本发明可以帮助大数据平台更可靠的采集数据。
2)本发明可以让大数据分析更可靠。
3)本发明可以让大数据平台进行实时分析尤其是保证日志数据可以可靠采集。保证在日志传输过程中,不会因为网络中断或临时堵塞,或传输程序因为异常中断而导致日志数据传输丢失。
附图说明
图1系统架构图。
图2数据结构图。
图3文件校验流程图。
具体实施方式
本实施例中,本发明通过设计日志采集平台采集日志,如图1所示。
其中flume部署至各个数据源上,数据源可以是多个。flume用于采集数据源的日志数据并发送。Kafka作为数据传输模块,一般部署在网络中心节点(即可以快速连通各个数据源的服务器)。storm和HDFS部署在最终数据汇总的大数据集群上。数据库用于存储日志文件校验的信息,可以部署在一台独立的服务器上也可以部署在大数据集群上。
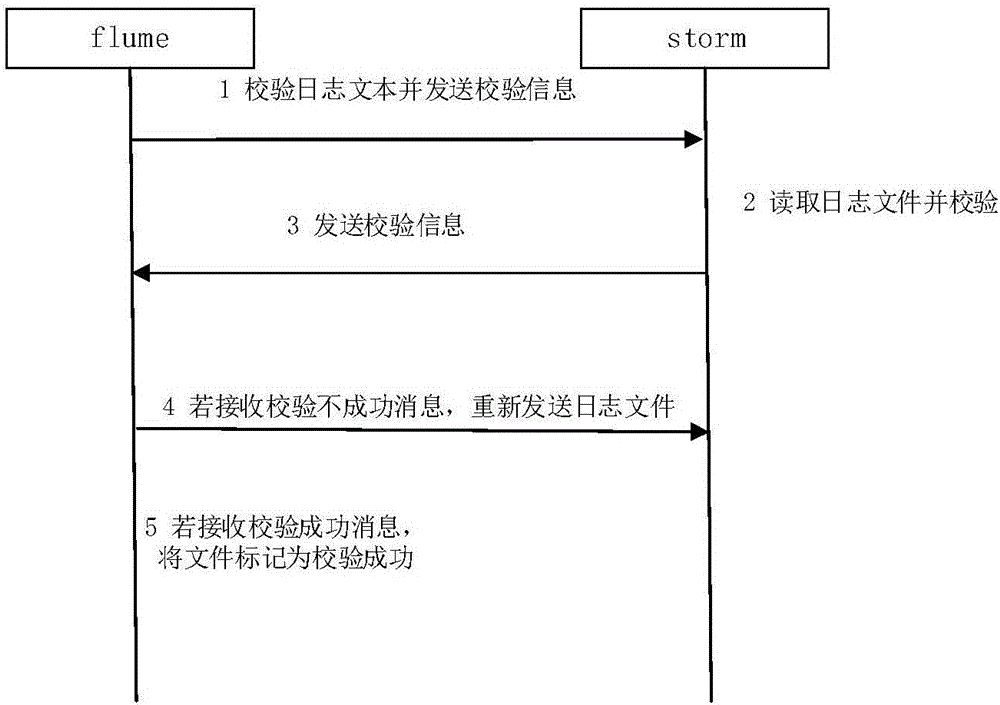
在本实施例中,本发明设计了数据恢复流程如图2所示。
1)flume读取目前日志文件。读取时会记录当前读取日志文件的偏移量。当因为断电或服务中断,下次启动时会接着上次读取的位置读取文件。
2)当数据源所在服务器会定时发送日志文件的校验信息至大数据集群上。校验信息格式如下:
Key:yyyy-MM-dd HH:mm:ss_dataChecked!
Value:文件全路径1,最大行数1,业务标识1||文件全路径2,最大行数2,业务标识2…
Key值只有一个字段长度,内容为构造校验时间字符串;
Value为文件全路径信息,最大行数,业务标识,多个文件以“||”分割。
3)当大数据集群的storm接收到消息校验,会对存储在HDFS上的日志文件进行校验并将校验信息记录至数据库。若校验成功,则发送文件校验成功消息至数据源。若校验不成功,则发送文件重传请求至至数据源。
文件校验成功消息样例如下:
Key:文件全路径,业务标识,类型(为2)
Value:2016-11-15 14:13:22_datachecked success!
文件重传消息样例如下:
Key:文件全路径,业务标识,类型(为1)
Value:行号1,开始偏移量1,结束偏移量1||行号2,开始偏移量2,结束偏移量2||行号N,开始偏移量m,结束偏移量p
4)当数据源的flume接收到文件校验成功消息时,记录文件发送成功。当接收到文件重传请求时,重新发送日志文件。
本发明中,大数据集群对文件校验流程如图3。
1)当接收到源节点flume发送的校验消息。
2)大数据集群中的storm根据校验消息读取HDFS上已上传的文件并计算文件上的实际行数。
3)将实际行数与校验信息中的校验行数对比,若不一致则发送重新上传请求。若成功,则发送文件成功消息。
- 还没有人留言评论。精彩留言会获得点赞!