基于贝叶斯集成学习的软测量建模方法与流程
本发明属于工业过程控制领域,尤其涉及一种基于贝叶斯集成学习的软测量建模方法。
背景技术:
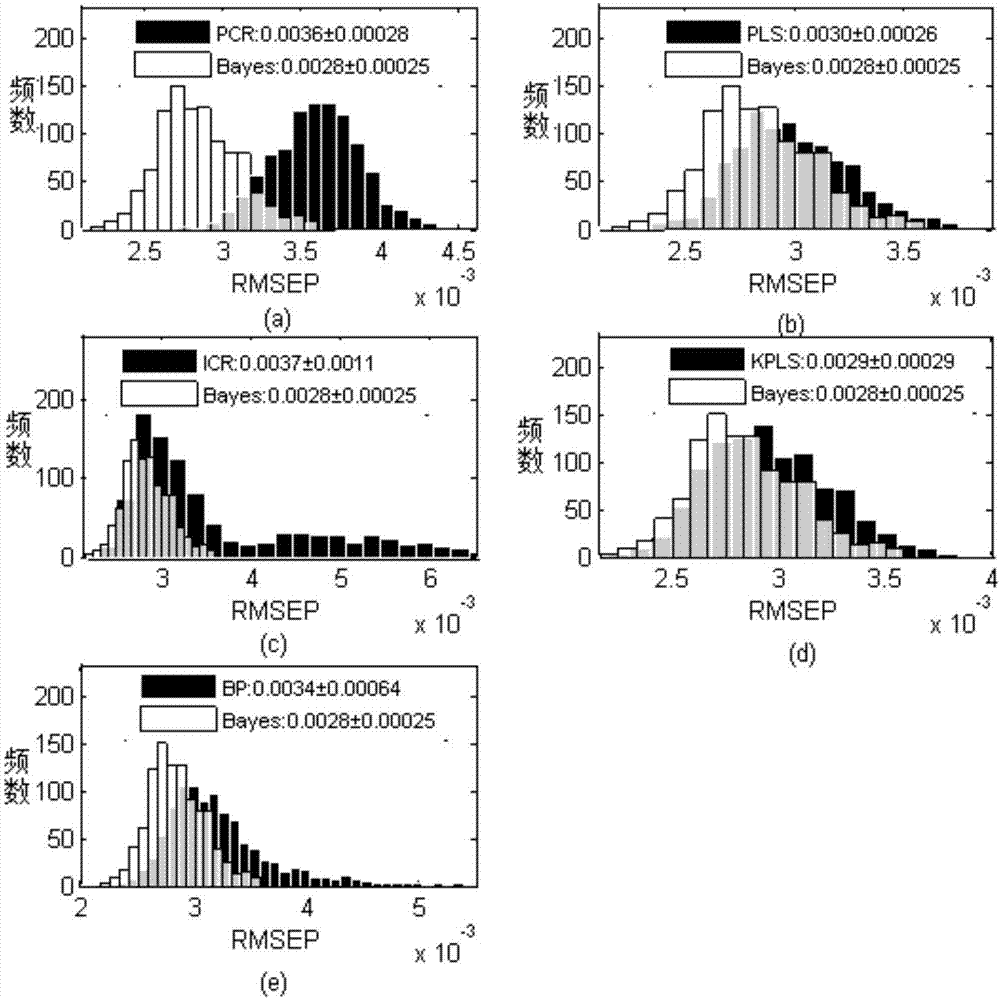
:生产装置的经济效益和产品品质,在当代工业的环境下被越来越严格地要求,这往往决定企业是否能在竞争日益激烈的市场环境下存活。在化工、发酵、生物、冶金、石油、食品等过程工业中,若要实现卡边控制、使生产装置运行于最佳的工作状况、生产更多的优质产品,就需要严格控制许多重要的过程变量。然而,往往很难用在线传感器直接把这些重要的过程变量测出来。有不少方法可以解决这样的测量问题,软测量是目前应用比较普遍的方法。集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。通常来说,在工业过程中,若能够找到或者设计一个足够好的软测量算法,使得该算法在各种环境下都具有很好的泛化误差,那就没有必要使用集成的思想。然而,实际应用中由于噪声、离群点或者不相关变量的存在,构造一个完美的软测量算法不可能实现,至少使它能适应不同的设计条件很难实现。虽然很多学者在单一软测量算法上做了许多改进,不过大部分都基于一定的假设条件,包括数据特征是线性相关的、服从高斯分布、工况平稳等等,但是实际的过程一般都是各种特征的综合体,使用假设条件会有局限性。因此本发明尝试构造一个包含若干软测量算法的集成学习系统,即选择多种软测量算法对工业过程进行检测,在统一的融合框架下,对各软测量算法的预测结果进行集成,以适应不同的过程特性。为了提高整个系统的多样性,选择可以处理线性、非线性、非高斯等不同工业过程的软测量算法,使得算法在应对具有该类特点的数据时,能获得较好的泛化性能,为后续的集成学习提供强的多样性。并采用模型集群分析方法,通过产生大数量训练集群,消除训练集的选择对于模型评价结果的影响,提高数据的多样性。与以往的从一个单一的输出值上进行模型评价的方法不同,模型集群分析方法的输出是一个分布,从而可以从统计学的角度得到更多的结论。技术实现要素:本发明的目的在于针对现有方法的假设局限,提供一种基于贝叶斯集成学习的软测量建模方法。本发明的目的是通过以下技术方案来实现的:一种基于贝叶斯集成学习的软测量建模方法,其特征在于,包括以下步骤:(1)向系统输入n(n为大于0的自然数)个工业过程数据样本,对所有样本进行归一化处理,使得各个变量的均值为0,方差为1。将这些数据存入历史数据库。基于模型集群分析算法的框架进行接下来的步骤(2)至(4)。(2)采用蒙特卡洛算法从原始数据集中抽取a%(50≤a≤80)的样本作为训练样本,剩下的作为测试样本。蒙特卡洛重复N(N为大于0的自然数)次,共生成N个训练集和N个测试集。将这些数据存入历史数据库。(3)选择适用于不同工业过程特性的m个软测量算法作为集成学习的子算法。从数据库中调用N个训练集,并用软测量子模型算法对这些训练集分别建立N个子模型,然后调用数据库中对应的N个测试集进行预测。设每个子模型得到的预测结果为:yi,j(t),i=1,2,…,m,j=1,2,…,N,t=1,2,…,n×(1-a%)设测试集的真实结果为:Yi(t),i=1,2,…,N,t=1,2,…,n×(1-a%)通过下式求得各个子模型算法各自的N个均方根误差RMSEPi,j:将建模数据和各个软测量子模型算法参数存入历史数据库中备用。(4)从数据库中调用建模数据,采用贝叶斯集成算法对m个软测量子模型算法进行集成,得到各个子算法分配的权重,存入历史数据库中备用,具体步骤如下:a)通过下式求得贝叶斯集成算法的系数Zi:设Mi代表第i个子算法模型,贝叶斯先验概率被设为:设S代表测试数据集,贝叶斯似然概率为:贝叶斯后验概率为:b)最后再对每一个子模型的预测值进行加权求和,得到最终的预测值:离线建模完成。计算出贝叶斯集成模型的N个均方根误差,进行统计分析,评价模型优劣。(5)将在线过程数据输入系统,经过m×N个软测量算法模型预测后,根据之前得到的权重,通过贝叶斯集成求得待预测过程数据的最终预测结果分布范围。本发明的有益效果是:本发明针对单个软测量算法在一些条件下能有很好的性能而在另一些条件下就有可能表现不佳的局限性,提出了基于贝叶斯集成学习的软测量建模方法。相比目前的其他软测量方法,本发明不仅提高了软测量模型对不同工业过程特性的适应性,提高了过程变量预测精确度,而且采用了模型集群分析来进行模型评价,从统计学的角度来评价模型的好坏,由此可以看到不同算法的整体预测效果,得到更多的信息。附图说明图1为基于贝叶斯集成学习的软测量建模方法的流程图;图2为各个软测量子模型算法与贝叶斯集成算法的均方根误差分布比较的统计图,其中,(a)为PCR算法与贝叶斯集成算法的均方根误差分布比较的统计图,(b)为PLS算法与贝叶斯集成算法的均方根误差分布比较的统计图,(c)为ICR算法与贝叶斯集成算法的均方根误差分布比较的统计图,(d)为KPLS算法与贝叶斯集成算法的均方根误差分布比较的统计图,(e)为BP算法与贝叶斯集成算法的均方根误差分布比较的统计图;图3为贝叶斯集成算法与各个软测量子模型算法的均方根误差差值分布的统计图,其中,(a)为贝叶斯集成算法与PCR算法的均方根误差差值分布的统计图,(b)为贝叶斯集成算法与PLS算法的均方根误差差值分布的统计图,(c)为贝叶斯集成算法与ICR算法的均方根误差差值分布的统计图,(d)为贝叶斯集成算法与KPLS算法的均方根误差差值分布的统计图,(e)为贝叶斯集成算法与BP算法的均方根误差差值分布的统计图。具体实施方式本发明为了克服单个软测量算法的局限性,在模型集群分析算法的框架下,首先进行离线建模,采用蒙特卡洛算法对原始数据随机采样,生成N个训练集和N个测试集。采用适用于不同工业过程特性的多个软测量算法作为子算法,然后用贝叶斯集成学习方法计算出各个软测量子算法模型分配的权重。在线预测时,经过软测量子算法模型预测后,根据之前计算出的权重,通过贝叶斯集成求得待预测过程数据的最终预测结果分布范围。以下结合一个具体的工业过程的例子来说明本发明的有效性。在合成氨工艺过程中,甲烷脱碳单元会产生氢气,碳元素却仍以CO与CO2的形式存在。高-低温度转换单元的作用就是把CO转换成CO2,而CO2能够被CO2吸收塔吸收,并在尿素合成单元作为原料重新利用。CO变换是先后在过程中按如下反应式进行:变换后气体仅含CO0.29%(干基体积)。变换反应增加了H2,同时产生与CO等量的CO2。该反应在催化剂存在时进行,低温和高蒸汽浓度有利于平衡,而高温有利于反应速度,但高蒸汽浓度将使反应速度明显降低,因大气量会导致缩短(与触媒的)接触时间。高-低温度转换单元共27个变量,如表1所示,其中包括26个常规过程变量和1个质量变量,出口CO含量。参考图1,根据基于贝叶斯集成学习的软测量建模方法的流程图,本发明采用的技术方案的主要步骤分别如下:第一步向系统输入n(n=3000)个工业过程数据样本,对所有样本进行归一化处理,使得各个变量的均值为0,方差为1。将这些数据存入历史数据库。基于模型集群分析算法的框架进行接下来的步骤二至步骤四。模型集群分析方法的步骤是:a)用蒙特卡洛方法从原始数据集中随机生成N(N为大于0的自然数)个子数据集;b)对每一个子数据集都建立一个子模型(分类或者回归);c)对N个子模型的输出进行统计分析。第二步采用蒙特卡洛算法从原始数据集中抽取a%(a=70)的样本作为训练样本,剩下的作为测试样本。蒙特卡洛重复N(N=1000)次,共生成N个训练集和N个测试集。将这些数据存入历史数据库。第三步选择适用于不同工业过程特性的m(m=5)个软测量算法作为集成学习的子算法。选择适用于线性过程的主元分析法PCR、偏最小二乘法PLS,适用于非线性过程的BP神经网络、KPLS核最小二乘法,以及适用于非高斯过程的独立成分分析法ICR作为集成学习的子模型算法。通过反复测试,将PCR、PLS的主元个数选为14,将ICR的独立主元个数选为11,KPLS的核参数选为35,BP神经网络的层数选择单层,节点数选择3。从数据库中调用N个训练集,并用软测量子模型算法对这些训练集分别建立N个子模型,然后调用数据库中对应的N个测试集进行预测。设每个子模型得到的预测结果为:yi,j(t),i=1,2,…,m,j=1,2,…,N,t=1,2,…,n×(1-a%)设测试集的真实结果为:Yi(t),i=1,2,…,N,t=1,2,…,n×(1-a%)通过下式求得各个子模型算法各自的N个均方根误差RMSEPi,j:将建模数据和各个软测量子模型算法参数存入历史数据库中备用。第四步从数据库中调用建模数据,采用贝叶斯集成算法对m个软测量子模型算法进行集成,得到各个子算法分配的权重,存入历史数据库中备用,具体步骤如下:a)通过下式求得贝叶斯集成算法的系数Zi:设Mi代表第i个子算法模型,贝叶斯先验概率被设为:设S代表测试数据集,贝叶斯似然概率为:贝叶斯后验概率为:b)最后再对每一个子模型的预测值进行加权求和,得到最终的预测值:离线建模完成。计算出贝叶斯集成模型的N个均方根误差,进行统计分析,评价模型优劣。如图2所示,将贝叶斯集成算法的均方根误差的分布和各个子模型算法的均方根误差的分布进行统计分析比较。Di,j,i=1,2,…,m+1,j=1,2,…,N,为不同算法之间均方根误差的差值,即:Di,j=RMSEPa,i-RMSEPa,j,i=1,2,…,m+1,j=1,2,…,N,a=1,2,…,m+1,b=1,2,…,m+1将贝叶斯集成算法的均方根误差与各个子模型算法的均方根误差的差值的分布求出,进行如图3所示和如表2所示的统计分析。第五步将在线过程数据输入系统,经过m×N个软测量算法模型预测后,根据之前得到的权重,通过贝叶斯集成求得待预测过程数据的最终预测结果分布范围。图2为各个软测量子模型算法与贝叶斯集成算法的均方根误差分布比较的统计图,(a)为PCR算法与贝叶斯集成算法的均方根误差分布比较的统计图,(b)为PLS算法与贝叶斯集成算法的均方根误差分布比较的统计图,(c)为ICR算法与贝叶斯集成算法的均方根误差分布比较的统计图,(d)为KPLS算法与贝叶斯集成算法的均方根误差分布比较的统计图,(e)为BP算法与贝叶斯集成算法的均方根误差分布比较的统计图。从图2中可以看出,将贝叶斯集成算法的均方根误差的分布和各个子模型算法的均方根误差的分布进行统计分析比较,可知与任意一个子模型算法相比,贝叶斯集成之后的均方根误差的分布最靠左,均方根误差RMSEP的平均值0.0028最小,分布的标准差0.00025也最小,也就是集成之后的预测精度最高。图3为贝叶斯集成算法的均方根误差与各个子模型算法的均方根误差的差值的分布比较图,(a)为贝叶斯集成算法与PCR算法的均方根误差差值分布的统计图,(b)为贝叶斯集成算法与PLS算法的均方根误差差值分布的统计图,(c)为贝叶斯集成算法与ICR算法的均方根误差差值分布的统计图,(d)为贝叶斯集成算法与KPLS算法的均方根误差差值分布的统计图,(e)为贝叶斯集成算法与BP算法的均方根误差差值分布的统计图。由图3可知贝叶斯与任意一个子模型算法的差值绝大部分分布在小于0的范围内,即在绝大部分情况下贝叶斯预测精度比子算法高。表2为D值数值统计的表格,以贝叶斯和偏最小二乘法PLS的差值D举例,D的平均值是-0.00014962,D<0的比率是95.90%,D>0的比率是4.10%,也就是所有的子集中有95.90%的子集,贝叶斯集成算法比PLS预测精度高,另外有4.10%的子集,贝叶斯集成算法比PLS预测精度低。意思就是,如果随机选择训练集和测试集,有95.90%的概率是贝叶斯集成算法比PLS子模型算法预测精度要高的。所以从总体上来讲,贝叶斯集成算法表现比PLS好的概率比较大,也就是贝叶斯集成算法的模型更优。同理,由表格分析可知,贝叶斯集成学习的预测精确度比任意一个子模型算法高的概率比较大。最终可以得到如下的结论:结论一,模型评价的指标在软测量预测中通常用的是均方根误差,但在模型集群分析方法中,预测结果好坏的评价指标是均方根误差的分布。采用了蒙特卡洛随机采样的方法,这能够最大限度地减少训练集样本的选择对于模型评价结果的影响,减少对于被选择出作为训练集的子样本的依赖;并且从统计学的角度来评价模型的好坏,我们可以看到不同算法的整体预测效果,能够得到更多的信息。结论二,贝叶斯集成算法的预测精度比任意一个子模型算法高的概率比较大,因此贝叶斯集成算法总体上比任意一个子模型算法表现好。这是普通的模型评价的方法,比如将唯一的一个均方根误差作为评价指标的交叉验证法,所无法得到的结论。根据本发明的实施例,贝叶斯集成学习算法提高了过程变量预测精确度,采用了模型集群分析来进行模型评价,从统计学的角度来评价模型的好坏,由此可以看到不同算法的整体预测效果,得到更多的信息。表1:输入输出变量说明变量编号标签变量描述1AI04001A04R001入口气体流率2AI04001A-AR04R001入口Ar含量3AI04001A-C004R001入口CO含量4AI04001A-CH404R001入口CH4含量5AI04001A-H204R001入口H2含量6AI04001B04R002入口气体流率7AI04001B-AR04R002入口Ar含量8AI04001B-C0204R002入口CO2含量9AI04001B-CH404R002入口CH4含量10AI04001B-H204R002入口H2含量11AI04001B-N204R002入口N2含量12TI0400104R001上层温度13TI0400204R001中层温度14PC0400304R002出口工艺气压力15TI0400304R001下层温度16TR0400404R001出口工艺气温度17TI0400504E002出口BFW温度18TC0400604E002出口工艺气温度19TI0400804R002上层温度20TI0400904R002中层温度21TI0401004R002下层温度22LC0401104E003液位23PC0401104E003出口工艺气压力24TR0401104R002出口工艺气温度25TI0401204K101进口循环N2温度26TI0401304R002进口工艺气温度27AR0400304R002出口CO含量表2:贝叶斯集成算法与所有子算法的精确度比较D的平均值D<0D>0Bayes-PCR-0.00074750100.00%0.00%Bayes-PLS-0.0001496295.90%4.10%Bayes-ICR-0.0008413896.00%4.00%Bayes-KPLS-0.0001146699.70%0.30%Bayes-BP-0.0005923799.90%0.10%上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1