基于社保数据构建用户画像的方法和用户画像生成器与流程
本发明涉及大数据领域和社会保障领域,涉及一种基于社保数据构建用户画像的方法和用户画像生成器,本发明涉及到的用户为社保个人用户。
背景技术:
用户画像即用户信息标签化,企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,抽象出的用户的商业全貌。用户画像普遍用来完善产品运营、精准营销、信息统计、智能推荐、效果评估、产品和服务私人定制等。
目前社保领域尚没从用户画像的角度来描述社保参保对象并进行社保画像的应用。随着信息化的发展,国家大力促进大数据的发展,运用大数据创新服务模式,为公众提供更为个性化、更具针对性的服务。社会保障事业也得到了长足的发展,社保覆盖迅速扩大,参保人数和资金不断增长,社会保障领域数据增长迅速。国家大力发展一体化建设,社保信息系统省级集中已经取得初步的成果。社会保障领域已经具备了对社保数据进行大数据分析的能力,基于社会保障大数据构建用户画像有了基本的前提。
目前,社会保障领域的大数据应用正在开展,社保用户画像的概念提出不久,鉴于社保数据具有量大、质优、动态、核心的特点,形成社保领域用户画像有着十分有利的基础和广泛地应用前景,同时,社保领域尚没有专业的方法来构造社保用户画像。
技术实现要素:
本发明为了解决上述问题,提出了一种基于社保数据构建用户画像的方法和用户画像生成器,为涉及地区广泛,涉及系统多,数据统筹困难的的人社数据提供可一种较为简便数据整合、转换、计算并构建用户画像的方法和用户画像生成器。
为了实现上述目的,本发明采用如下方案:
一种基于社保数据构建用户画像的方法,包括以下步骤:
获取用户社保数据,所述社保数据为可查询数据;
将所述用户社保数据存储在Hbase数据库中;
对所述用户的社保数据进行过滤,得到社保数据的关键字段,所述关键字段至少用于指示用户的基本信息、参保信息、待遇信息、医疗信息和人事资质信息中的一种;将所述关键字段作为用户基本标签;
采用大数据并行计算方法对所述用户的社保数据进行分析,定义分析类标签的标签值和阈值,标签值根据所述用户社保数据与权重值加权计算得到,阈值用来区分所述用户的不同社保状态,根据标签值与阈值的关系,确定用户的社保状态,并将此时的社保状态作为用户分析类标签;所述社保状态至少用于指示用户的社保缴费状态、健康状态、收入水平、生存状态、生育状态和业务经办行为偏好中的一种;所述业务经办行为偏好包括偏好业务大厅办理、偏好自助终端办理、偏好网上办理和偏好手机终端办理;
生成以基本标签和分析类标签为集合的用户画像。
上述方法还包括:
获取社会保障领域可以执行的所有业务信息;
采用大数据并行计算方法对用户画像和社会保障领域可以执行的所有业务信息进行关联分析,得到用户画像可以做和必须做的业务信息。
所述获取用户的社保数据步骤中还包括:
获取公安部门和民政部门记载的用户信息,用于验证所述用户的社保数据是否正确,并舍弃不正确的社保数据。
将所述用户社保数据中重复数据删除,对所述用户社保数据中不完整数据,采用0值、空字符串或实际社保数据进行补齐。
所述用户的基本信息至少包括性别、年龄段、经常居住地和教育信息中的一种。
所述用户社保数据包括:保险数据、人事人才数据、公共就业数据和劳动关系数据。
采用Sqoop数据工具获取所述用户社保数据。
采用Spark大数据并行计算方法计算用户社保数据。
一种基于社保数据的用户画像生成器,包括:
获取模块,用于获取用户的社保数据,所述社保数据为可查询数据;
存储模块,用于将所述用户社保数据存储在Hbase数据库中;
过滤模块,用于对所述用户的社保数据进行过滤,得到社保数据的关键字段,所述关键字段至少用于指示用户的参保信息、待遇信息、医疗信息和人事资质信息中的一种;将所述关键字段作为用户基本标签;
分析模块,采用大数据并行计算方法对所述用户的社保数据进行分析,定义分析类标签的标签值和阈值,标签值根据所述用户社保数据与权重值加权计算得到,阈值用来区分所述用户的不同社保状态,根据标签值与阈值的关系,确定用户的社保状态,并将此时的社保状态作为用户分析类标签;所述社保状态至少用于指示用户的社保缴费状态、健康状态、收入水平、生存状态、生育状态和业务经办行为偏好中的一种;所述业务经办行为偏好包括偏好业务大厅办理、偏好自助终端办理、偏好网上办理和偏好手机终端办理;
生成模块,用于生成以基本标签和分析类标签为集合的用户画像。
用户画像生成器中,所述社保数据获取模块还包括验证模块,用于获取公安部门和民政部门记载的用户信息,并验证所述用户的社保数据是否正确,并舍弃不正确的社保数据。
用户画像生成器还包括:
社会保障业务信息获取模块,用于获取社会保障领域可以执行的所有业务信息;
关联分析模块,用于采用大数据分布式计算方法对用户画像和社会保障领域可以执行的所有业务信息进行关联分析,得到用户画像可以做和必须做的业务信息。
本发明的有益效果:
(1)本发明提供了社保大数据环境下基于海量社会保障数据构建人社领域用户画像的方法和社保用户画像生成器,为相对地区分布广,涉及系统多,结构较为松散的人社数据提供一种较为简便的数据整合、转换、计算并构建用户画像的方法和用户画像生成器。
(2)该发明以社会保障领域的数据为基础,以Spark等大数据分析处理技术为主要手段,可以较为容易的构建出完整的社保领域的用户画像,可以为社会保障公共服务提供基础信息支撑,有效提高社保服务的精准度,提升用户体验。
(3)采用公安部门和/或民政部门的准确信息对数据整理模块中的数据进行验证和补全提高数据的准确性,完善社保数据信息。
(4)可以应用到为用户推荐社保业务上,清晰明了地展现用户可以做和必须做的社保业务。
附图说明
图1为本发明的用户画像构建方法流程图;
图2为本发明用户画像生成器的模块图。
具体实施方式:
下面结合附图与实施例对本发明作进一步说明。
通过对现有的业务和需求进行分析,确定出用户画像应用的目标人群,目前来说,社保领域用户画像使用对象一般可以分为两类,即社保个体服务对象和社保管理人员,个体对象主要用用户画像进行信息查询,社保管理人员对社保现状进行统计分析。具体的来说社保个体服务对象指在职职工、居民、离退休人员和灵活就业人员,社保管理人员对社保现状进行统计分析。
社保用户画像是基于用户社保数据,收集与分析参保人的个人基本信息、社会保险信息、公共就业信息、劳动关系信息、人事人才信息,社保卡信息,档案信息等,抽象出的社保领域服务对象个体全貌,社保领域使用用户画像,主要用来提升社保业务服务水平、协助政策的制定、优化业务办理,针对个人提供个性化的服务,对社保领域用户的各方面的状况如经济水平、健康状况、社会关系等进行详细的评价,并根据用户的信息进行大数据的分析,应用于社保领域。
用户社保数据包括:社保数据、人事人才数据、公共就业数据和劳动关系数据。
用户社保数据从另一方面还包括现有数据和增量数据,增量数据指距此次获取用户画像之后,用户通过办理社保业务新增的数据,获取增量数据。增量数据的获取是基于Oracle Streams技术对Redo日志进行分析,并得到XML格式的增量数据。
社保数据、人事人才数据、公共就业数据和劳动关系数据的数据格式与结构互不相同,这里使用大数据的数据传输工具如Sqoop(开源的数据转换工具)将各种数据转移到适合大数据计算的分布式数据库中。
用户的社保数据包括不完整的数据、错误的数据和重复的数据。对于不完整的数据主要是空值数据,如该字段字段类型为数值,实际数据中为null值,可以根据字段特征补充为0.00,空字符串或者根据业务信息补充实际值,补充实际值需要业务经办人员协助。
对于错误的数据,如某用户籍贯为济南市历下区,但是获取的数据显示该用户籍贯为历城区。错误信息需要公安、民政等方面的数据进行验证。
重复的数据为重复信息,如数据库中有两条完全一致的信息,此时需要删除重复的数据。
根据画像目标进行数据收集与分析。根据画像的目标,构建画像所需要的原始数据进行统一的收集,将数据收集到适合做大数据运算的分布式数据库中,如Hbase,HDFS,Hive等,收集的数据包含社保内部数据和社保外部收据。使用大数据技术将原始的数据储存到分布式存储数据库中,以社保内部数据为基础数据,社保外部数据为基础数据进行补充和校验,用来提高数据质量。用户画像的纬度信息不是越多越好,只需要找到与画像强相关的信息,同业务场景强相关的信息,同客户目标强相关信息的即可。社保内部数据包含社会保险、劳动关系、公共就业、人事人才四个领域内的人员基本信息、业务经办数据,流水数据、档案数据等。外部补充数据来自于公安、民政、工商、移动运营商、国土机构等人力资源和社会保障外部门,用于对人力资源和社会保障内部数据进行正确性、一致性校验,用来提高数据质量。
对所述用户的社保数据进行过滤,得到社保数据的关键字段,所述关键字段至少用于指示用户的基本信息、参保信息、待遇信息、医疗信息和人事资质信息中的一种;将所述关键字段作为用户基本标签;
采用大数据并行计算方法(如Spark,开源的Hadoop并行计算框架)对所述用户的社保数据进行分析,定义分析类标签的标签值和阈值,标签值根据所述用户社保数据与权重值计算得到,具体的计算公式为:
Vi=Li1Ci1+Li2Ci2+Li3Ci3+…+LijCij (1)
其中V为标签值,L为原始数据,C为数据权重,每个标签由多个原始数据通过与权重加权计算获得,i为第i个标签,j为变量的数目,Ci1到Cij和为1。
阈值用来区分所述用户的不同社保状态,根据标签值与阈值的关系,确定用户的社保状态,并将此时的社保状态作为用户分析类标签;所述社保状态至少用于指示用户的社保缴费状态、健康状态、收入水平、生存状态、生育状态和业务经办行为偏好中的一种;所述业务经办行为偏好包括偏好业务大厅办理、偏好自助终端办理、偏好网上办理和偏好手机终端办理;
具体的,Spark计算过程包括:根据不同的标签以及数据源信息,定义相应的计算任务,每一个计算任务中都包含对数据的初始化、计算和整合操作;根据Spark作业定义模块中关于作业的定义,将作业定义发送到Spark任务调度中间件进行调度执行;Spark任务调度中间件,用于接收Spark作业定义消息,发起Spark任务调度,调度Spark计算任务池中的计算任务进行初始化、计算和整合;Spark计算任务池,包含若干个计算任务,每一个计算任务对应用户画像标签计算不同的计算模块,该模块包含全部的Spark计算任务;
经过基本标签和分析类标签的获取,我们就生成了以基本标签和分析类标签为集合的用户画像
在得到了用户画像的基础上,我们还可以获取社会保障领域可以执行的所有业务信息;
采用大数据并行计算方法(如Spark,开源的Hadoop并行计算框架)对用户画像和社会保障领域可以执行的所有业务信息进行关联分析,得到用户画像可以做和必须做的业务信息。例如:如居民缴费业务,需要满足居民、未退休这两个条件,若画像的标签满足这两个条件,则推荐该业务。
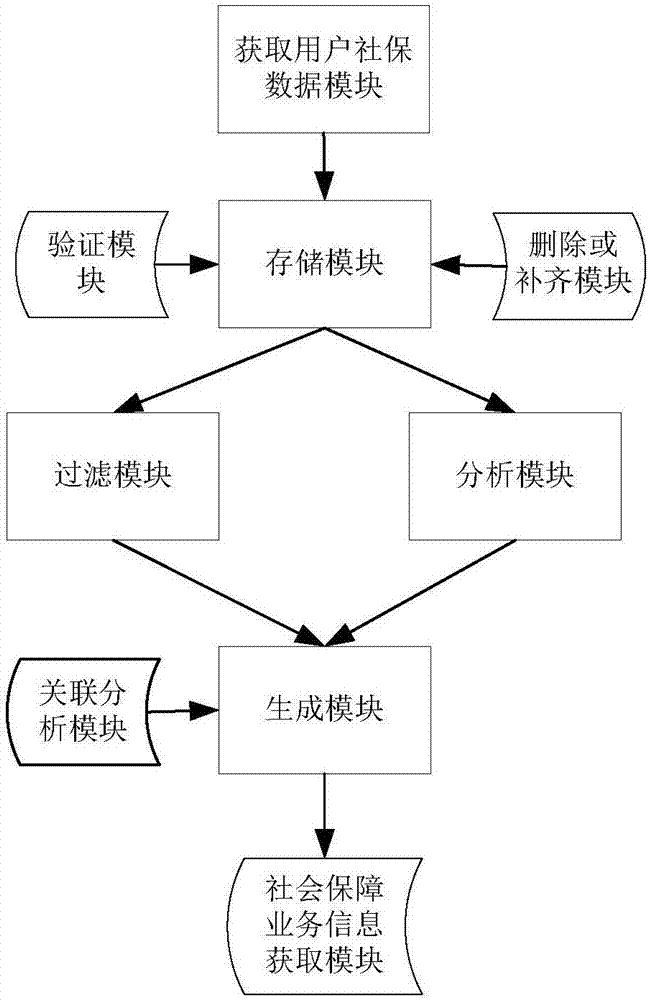
图2给出了用户画像生成器的模块图,包括
社保数据获取模块,用于获取用户的社保数据,所述社保数据为可查询数据;
存储模块,用于将所述用户社保数据存储在Hbase数据库中;
过滤模块,用于对所述用户的社保数据进行过滤,得到社保数据的关键字段,所述关键字段至少用于指示用户的参保信息、待遇信息、医疗信息和人事资质信息中的一种;将所述关键字段作为用户基本标签;
分析模块,用于采用大数据并行计算方法对所述用户的社保数据进行分析,定义分析类标签的标签值和阈值,标签值根据所述用户社保数据与权重值计算得到,阈值用来区分所述用户的不同社保状态,根据标签值与阈值的关系,确定用户的社保状态,并将此时的社保状态作为用户分析类标签;所述社保状态至少用于指示用户的社保缴费状态、健康状态、收入水平、生存状态、生育状态和业务经办行为偏好中的一种;所述业务经办行为偏好包括偏好业务大厅办理、偏好自助终端办理、偏好网上办理和偏好手机终端办理;
生成模块,用于生成以基本标签和分析类标签为集合的用户画像。
所述社保数据获取模块还包括验证模块,用于获取公安部门和民政部门记载的用户信息,并验证所述用户的社保数据是否正确,并舍弃不正确的社保数据。
所述社保数据获取模块还包括删除或补齐模块,用于将所述用户社保数据中重复数据删除,对所述用户社保数据中不完整数据,采用0值、空字符串或实际社保数据进行补齐。
所述用户画像生成器还包括:
社会保障业务信息获取模块,用于获取社会保障领域可以执行的所有业务信息;
关联分析模块,用于采用大数据分布式计算方法对用户画像和社会保障领域可以执行的所有业务信息进行关联分析,得到用户画像可以做和必须做的业务信息。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!