云环境中模型驱动的Hadoop部署方法与流程
本发明涉及软件工程领域,特别涉及一种云环境中模型驱动的hadoop部署方法。
背景技术:
当今社会,每天有大量的数据流通量生成,且全球90%的数据是在过去两年内产生的,海量数据处理技术已广泛地应用到社会生产的各个领域,这也意味着大数据时代的真正到来。
hadoop作为一种大数据分布式处理的开源软件框架,它能够以可靠、高效、可扩展的方式处理海量数据。此外,随着hadoop生态系统的快速发展及其大量子项目开发的相继完工,其已被广泛地应用于各种场景下大数据的处理和存储。如今,hadoop已经成为大数据处理最重要的软件工具之一。随着hadoop越来越广泛地部署在云中,管理员需要根据具体需求,以不同的方式对hadoop进行部署和配置,因此给hadoop部署带来了两个方面的挑战:
(1)硬件资源的多样性:hadoop集群可能部署在不同类型的基础设施上,包括物理服务器、虚拟机和docker容器等,这种异构性给集群节点的管理带来了难度和复杂度。
(2)软件资源的多样性:hadoop生态系统包含多种不同类型的计算和存储框架,例如,hdfs、mapreduce、hbase、yarn、spark等。不同类型的框架均有特定的部署和配置方法,此外,一些框架间还存在着依赖或约束关系。
目前,存在一些管理工具可以帮助用户部署hadoop集群,例如clouderamanager和apacheambari。此外,开源容器引擎docker通过对应用组件的封装、分发、部署、运行等生命周期的管理,达到应用组件级别的“一次封装,随处运行”,降低了hadoop部署和运维的难度。上述的部署工具与技术虽然对hadoop集群的部署与管理提供了解决方案,但是研究重点大多在于环境的配置与参数的设置,通常提供的是一种固定的部署模式,没有考虑到云平台的多样化的基础设施以及扩展性问题,不能根据服务类型、节点资源和场景特性来满足用户特定的hadoop部署需求。
技术实现要素:
本发明旨在至少解决上述技术问题之一。
为此,本发明的目的在于提出一种云环境中模型驱动的hadoop部署方法,能够对云环境中多样化软硬件资源的进行管理与部署。
为了实现上述目的,本发明的实施例公开了一种云环境中模型驱动的hadoop部署方法,包括以下步骤:s1:提供hadoop需求模型和hadoop部署模型,其中,所述hadoop需求模型用于用于根据系统需求生成相应的管理视图,所述hadoop部署模型用于描述所述管理试图的节点配置信息、运行状态和软件进行部署;s2:根据预设转换规则实现所述hadoop需求模型和所述hadoop部署模型之间的模型转换,其中,所述预设转换规则包括节点转换模型和集群服务转换模型,所述节点转换模型用于实现所述hadoop需求模型的节点和所述hadoop部署模型的节点之间的模型转换,所述集群服务转换模型用于实现所述hadoop需求模型的集群服务和所述hadoop部署模型的集群服务之间的模型转换;s3:使用同步引擎监测所述hadoop需求模型和所述hadoop部署模型中的信息变化情况,并在所述hadoop需求模型和/或所述hadoop部署模型中的信息发生变化时进行信息同步。
进一步地,所述hadoop需求模型包括:集群节点模块,所述集群节点模块设置有基础设施资源,所述基础设施资源包括节点配置列表、节点列表和容器映像列表中对应的资源和属性;集群服务模块,所述集群服务模块设置有服务列表,所述服务列表中包括多种服务和每种服务的属性。
进一步地,所述hadoop部署模型包括:集群节点单元,所述集群节点单元存储有虚拟机配置列表、虚拟机列表和虚拟机映像列表;集群服务单元,所述集群服务单元用于提供集群服务。
进一步地,所述节点转换模型通过所述hadoop需求模型的节点和所述hadoop部署模型的节点之间的元素映射关系来实现模型转换,所述元素映射关系包括helper标签和mapper标签,所述helper标签用于描述类和类之间元素的映射关系,所述helper标签用于描述类和类之间属性的映射关系。
进一步地,所述集群服务转换模型通过约束模型和预设转换算法进行集群服务的自动转换,所述约束模型用于限定多个模型元素之间的关联关系,所述预设转换算法根据所述hadoop需求模型和所述约束模型生成服务部署方案。
进一步地,所述预设部署算法包括以下步骤:根据所述hadoop需求模型中服务列表下的服务单元,得到需要部署的服务集合;根据约束模型中服务单元之间的依赖关系,对服务集合中的服务进行补充和排序,得到实际需要部署的服务有序集合;根据所述服务有序集合,按照逆序的方式依次读取每一个服务并计算服务的部署方案;根据服务部署单元的节点集合,依次进行服务的部署。
进一步地,采用sm@rt工具构造所述hadoop部署模型。
根据本发明实施例的云环境中模型驱动的hadoop部署方法,将运行时体系结构模型引入到hadoop部署过程中,通过模型提出、模型转换和模型同步三步来实现满足用户特定的hadoop部署需求。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明实施例的云环境中模型驱动的hadoop部署方法的流程图;
图2是本发明一个实施例的hadoop需求元模型的示意图;
图3是本发明一个实施例的hadoop部署元模型的示意图;
图4是本发明一个实施例的模型元素间映射关系的示意图;
图5是本发明一个实施例的约束模型元模型的示意图;
图6是本发明一个实施例的约束模型的示意图;
图7是本发明一个实施例的hadoop集群服务部署的操作进行时参数改变说明图;
图8是本发明一个实施例的hadoop部署模型与运行系统的双向同步的示意图;
图9是本发明具体实施例中hadoop需求模型的示意图;
图10是本发明具体实施例中hadoop部署模型的示意图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
参照下面的描述和附图,将清楚本发明的实施例的这些和其他方面。在这些描述和附图中,具体公开了本发明的实施例中的一些特定实施方式,来表示实施本发明的实施例的原理的一些方式,但是应当理解,本发明的实施例的范围不受此限制。相反,本发明的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
以下结合附图描述本发明。
图1是本发明实施例的云环境中模型驱动的hadoop部署方法的示意图。如图1所示,本发明实施例的云环境中模型驱动的hadoop部署方法包括以下步骤:
s1:提供hadoop需求模型和hadoop部署模型。其中,hadoop需求模型用于用于根据系统需求生成相应的管理视图,hadoop部署模型用于描述管理试图的节点配置信息、运行状态和软件进行部署;
在本发明一个实施例中,hadoop需求模型包括:
集群节点模块,集群节点模块设置有基础设施资源,基础设施资源包括节点配置列表、节点列表和容器映像列表中对应的资源和属性;集群服务模块,集群服务模块设置有服务列表,服务列表中包括多种服务和每种服务的属性。
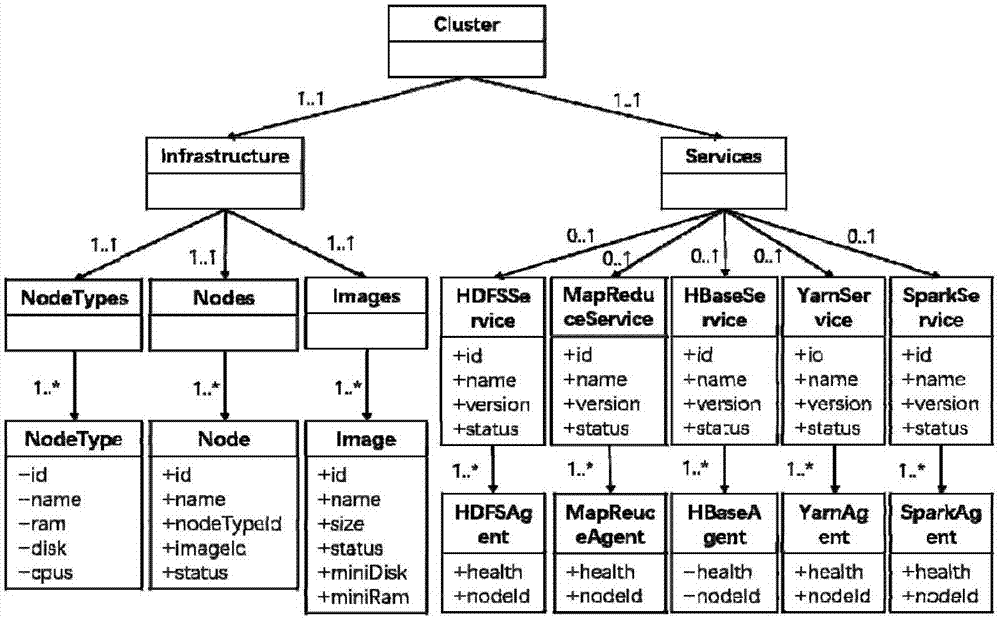
具体地,在hadoop集群的部署过程中,hadoop需求模型为管理员提供了节点资源与集群服务的统一的管理视图。如图2所示,需求元模型由集群节点和集群服务两部分组成。
在集群节点部分,infrastructure表示基础设施资源,包含一个nodetypes元素、一个nodes元素和一个images元素。nodetypes元素为节点配置列表,表示可使用的配置文件的集合,而每一个nodetype元素表示一个节点配置,包含id、name、ram、disk、cpus等属性,依次表示标识符、名称、磁盘、存储器、cpu数量等信息;nodes元素表示节点列表,表示节点配置的集合,而每一个node元素表示一个节点,包括id、name、nodetype、imgeid、status等属性,依次表示节点的标识符、节点的名称、节点类型、容器映像、节点状态等信息;images为容器映像列表,表示可使用的容器映像文件的集合,而每一个image元素表示一个容器映像,包含id、name、size、status、minidisk、miniram等属性,表示镜像的标识符、镜像的名称、镜像大小、镜像状态、磁盘、存储等信息。
在集群服务部分,services元素表示hadoop所提供的服务列表,包含hdfsservice、mapreduceservice、hbaseservice、yarnservice、sparkservice等元素,分别表示hdfs、mapreduce、hbase、yarn和spark等服务。以hdfsservice、mapreduceservice、hbaseservice为例进行阐述:hdfsservice表示集群的hdfs服务,该服务由集群中多个节点提供,每个节点均部署相应的hdfs软件模块,即hdfsagent;hbaseservice表示集群的hbase服务,该服务由集群中多个节点提供,每个节点均部署相应的hbase软件模块,即hbaseagent;mapreduceservice则表示集群的mapreduce服务,该服务由集群中多个节点提供,每个节点均部署相应的mapreduce软件模块,即mapreduceagent。上述所有的服务都包含id、name、version和status属性,分别表示标识符、名称、版本和当前运行状态,而其软件部署模块(即agent)则包含health和nodeid属性,表示健康状况和软件部署模块所在的节点位置等信息。
在本发明一个实施例中,hadoop部署模型包括:集群节点单元,集群节点单元存储有虚拟机配置列表、虚拟机列表和虚拟机映像列表;集群服务单元,集群服务单元用于提供集群服务。
具体地,在hadoop集群部署过程中,部署模型为管理员提供了系统部署的管理视图,描述了集群节点配置、运行状态以及其上的软件部署单元,并与运行系统双向同步。如图3所示,部署元模型也包括集群节点和集群服务两部分。
在集群节点部分,以cloudstack为例,project表示一个项目,包含一个vmtypes元素、一个vms元素和一个images元素。vmtypes元素为虚拟机配置列表,表示可使用的配置文件的集合,每一个vmtype元素表示一个虚拟机配置,包含id、name、description、guestcpus、memorymb、imagespacegb等属性,依次表示标识符、名称、虚拟机描述、cpu数量、内存、镜像空间大小等信息;vms元素表示虚拟机列表,表示虚拟机配置的集合,每一个vm元素表示一个虚拟机,包含id、name、imageid、vmtypeid、cpuutiliz、memoryutiliz等属性,表示标识符、名称、虚拟机映像、虚拟机类型、cpu使用率、内存使用率等信息等信息;images为虚拟机映像列表,表示可使用的虚拟机映像文件的集合,每一个image元素表示一个虚拟机映像,包含id、name、vsize、description等属性,表示标识符、名称、镜像大小、镜像描述等信息。
在集群服务部分,services元素表示hadoop所提供的服务列表,包含hdfsservice、mapreduceservice、hbaseservice、yarnservice、sparkservice等元素,分别表示hdfs、mapreduce、hbase、yarn和spark等服务,每种服务包含服务单元、角色单元、部署单元等三种主要模型元素。服务单元表示hadoop所提供的具体服务;角色单元表示具体hadoop服务所包含的不同角色;部署单元表示不同角色所拥有的正在运行的软件模块。以hdfsservice、mapreduceservice、hbaseservice为例进行阐述。hdfs服务单元包含三种类型的角色单元,即namenode,secondarynamenode和datanode;其中,角色单元namenode表示hdfs的管理中心,用于管理文件系统的命名空间、集群配置信息和存储块的复制,有且仅有一个部署单元du_nn;角色单元secondarynamenode表示namenode的备份节点,用于备份namenode节点保存的元数据,有且仅有一个部署单元du_snn;角色单元datanode表示hdfs的工作节点,用于调度存储和检索数据,可以有多个部署单元du_dn。mapreduce服务单元包含两种类型的角色单元,即jobtracker和tasktracker;其中,角色单元jobtracker表示mapreduce的中心服务节点,用于调度job的每一个子任务task使其运行于tasktracker上,有且仅有一个jobtracker的部署单元du_jt;tasktracker表示子服务节点,用于执行jobtracker分配的任务,可以有多个tasktracker的部署单元du_tt。hbase服务单元包含两种类型的角色单元,即hmaster和hregionserver;其中,hmaster表示hbase的管理调度中心,用于分配与管理hregionserver,有且仅有一个hmaster的部署单元du_hm;hregionserver表示hbase运行在每个工作节点上的服务,用于维护hmaster分配的region与io请求,可以有多个hregionserver的部署单元du_rs。上述不同角色的部署单元都包含vmid和health属性,表示部署单元的运行健康状况和软件模块所在的虚拟机位置等信息。
s2:根据预设转换规则实现hadoop需求模型和hadoop部署模型之间的模型转换。其中,预设转换规则包括节点转换模型和集群服务转换模型,节点转换模型用于实现hadoop需求模型的节点和hadoop部署模型的节点之间的模型转换,集群服务转换模型用于实现hadoop需求模型的集群服务和hadoop部署模型的集群服务之间的模型转换。
在本发明的一个实施例中,节点转换模型通过hadoop需求模型的节点和hadoop部署模型的节点之间的元素映射关系来实现模型转换,元素映射关系包括helper标签和mapper标签,helper标签用于描述类和类之间元素的映射关系,helper标签用于描述类和类之间属性的映射关系。
具体地,在不同应用场景下,部署模型中的集群节点部分存在着较大差异。例如,在cloudstack中,主要的管理单元包括vm、flavor、image,表示虚拟机、配置文件和镜像;而在docker中,主要的管理单元则是container、repository、image,表示容器、仓库和镜像。因此,需要建立需求模型和部署模型节点部分的元素映射关系来实现模型转换。
本发明的实施例设计了一套映射关系的描述规则及模型操作的转换方法,根据给定的模型间的元素映射关系,自动进行需求模型到部署模型的转换。模型间的元素映射关系通过一个xml文件进行描述,描述规则中关键字的定义如下:
(1)helper用于描述类和类之间元素的映射关系。helper标签含有两个属性:value和key,value表示需求模型中将要映射的元素,key表示部署模型中对应的元素。
(2)mapper用于描述类和类之间属性的映射关系。mapper标签也含有key和value两个属性,key表示部署模型应该被映射的元素属性的名称,value表示需求模型中元素对应属性的名称,它们所归属的元素分别由上一层的helper标签定义。
基于上述关键字,就可以按照映射规则对本发明所提出的需求模型和部署模型中的元素的映射关系进行描述。如图4所示,需求模型中的nodetype元素映射到部署模型中的vmtype元素,用一个helper标签来描述,helper标签的key属性和value属性分别为部署模型和需求模型对应元素的名称,即vmtype和nodetype。其中,nodetype的id与vmtype的id对应,name和name对应,ram和memorymb对应,disk和imagespacegb对应,vcpus和guestcpus对应。
通过模型操作可以实现对系统的管理,模型操作包含五种基本类型,即get、set、list、add和remove。任意一个作用于需求模型元素的模型操作,将转换为一个作用于部署模型元素的模型操作。如表1所示,本发明定义了模型操作的转换规则,实现了模型操作的自动转换。例如,需求模型中的a元素映射为部署模型中的b元素,那么,对于a元素的list、add和remove操作将被映射到相应b元素上的相同操作,对于a属性的get或set操作也将被映射到对相应属性的相同操作。
表1模型操作转换的映射规则
在本发明的一个实施例中,集群服务转换模型通过约束模型和预设转换算法进行集群服务的自动转换,约束模型用于限定多个模型元素之间的关联关系,预设转换算法根据hadoop需求模型和约束模型生成服务部署方案。
具体地,在hadoop生态系统中,包含hdfs、mapreduce、hbase、yarn、spark等多种不同类型的计算和存储框架,这些计算或存储框架均有特定的部署和配置方法,且不同的框架之间可能存在依赖或约束关系。例如,部署mapreduce服务需要依赖于hdfs服务。因此,对于不同hadoop集群服务,模型转换方法存在较大差异。本发明通过约束模型描述集群服务的部署规则,并通过一个通用算法实现集群服务的自动转换。
约束模型描述了一种hadoop服务的部署规则。如图5所示,约束模型的元模型包含服务单元、角色单元、部署单元等几种主要的模型元素,并描述了它们之间的关联关系。其中,service表示服务单元,包含name、minnodenum属性,依次表示名称和最小部署节点数;role表示角色单元,包含name、excluname、respriority、deorder等属性,依次表示名称、排他属性、资源优先级和部署顺序;du表示部署单元,包含health等属性,表示服务的健康状况;dependency_s表示服务单元之间的依赖关系,包含name属性,表示所依赖的服务单元的名称;类似地,dependency_du表示部署单元之间的依赖关系,name属性则表示所依赖的部署单元的名称。当服务单元之间存在依赖关系时,部署单元之间不一定存在依赖关系;但是,当部署单元之间存在依赖关系时,服务单元之间必然存在依赖关系。
如图6所示,以hdfs、mapreduce、hbase等服务为例进行阐述。hdfs服务单元包含三种角色单元,即namenode、seconderynamenode和datanode。其中,角色单元namenode有且仅有一个部署单元du_nn,角色单元seconderynamenode有且仅有一个部署单元du_snn,且namenode和seconderynamenode不能部署在同一节点;角色单元datanode可以有多个部署单元du_dn,且datanode可以和namenode或seconderynamenode部署在同一节点;此外,hdfs服务单元对其他服务单元不存在依赖,且部署单元du_nn、du_snn和du_dn对其他部署单元也不存在依赖。mapreduce服务单元包含两种角色单元,即jobtracker和tasktracker;其中,角色单元jobtracker有且仅有一个部署单元du_jt;角色单元tasktracker可以有多个部署单元du_tt,且jobtracker和tasktracker不能部署在同一节点;此外,mapreduce服务单元对hdfs服务单元及存在依赖,部署单元du_jt对部署单元du_nn存在依赖,部署单元du_tt对部署单元du_dn存在依赖。hbase服务单元包含两种角色单元,即hmaster和hregionserver;其中,角色单元hmaster有且仅有一个部署单元du_hm;角色单元hregionserver可以有多个部署单元du_rs,且hmaster和hregionserver不能部署在同一节点;此外,hbase服务单元对hdfs服务单元及存在依赖,部署单元du_hm对部署单元du_nn存在依赖,部署单元du_rs对部署单元du_dn存在依赖。
在本发明的一个实施例中,预设部署算法包括以下步骤:根据hadoop需求模型中服务列表下的服务单元,得到需要部署的服务集合;根据约束模型中服务单元之间的依赖关系,对服务集合中的服务进行补充和排序,得到实际需要部署的服务有序集合;根据服务有序集合,按照逆序的方式依次读取每一个服务并计算服务的部署方案;根据服务部署单元的节点集合,依次进行服务的部署。
具体地,本发明的实施例提出了一种通用算法,能够根据给定的需求模型和约束模型,自动生成服务部署方案,算法的基本步骤如下:
1、根据需求模型中服务列表services下的服务单元,得到需要部署的服务集合services{s1,s2,s3,…,si}。
2、根据约束模型中服务单元之间的依赖关系,对服务集合services中的服务进行补充和排序,得到实际需要部署的服务有序集合servicesorder{s1,s2,s3,...,sj};若服务集合中某个服务所依赖的其他服务未出现在服务集合中,则需要进行补充;在有序集合servicesorder中,服务s1不依赖于其他服务,服务s2可依赖于服务s1,服务s3可依赖于服务s1和服务s2,以此类推。
3、根据有序集合servicesorder,按照逆序的方式依次读取每一个服务并计算服务的部署方案:首先,根据需求模型中当前部署的服务的软件部署模块(即agent)中的信息,得到该服务的部署节点列表;其次,根据约束模型得到该服务所包含的角色类型及其部署约束;接着,根据节点信息和角色部署约束计算出每一个角色的部署单元所部署的节点;最后,根据约束模型中角色的部署单元的依赖关系记录其依赖的部署单元的部署节点信息,得到有序集合servicesorder中每一个服务的部署单元的节点集合,即servicesorderdeploy{s1{du1{},du2{},...},s2{du1{},du2{},...},...,sn{du1{},du2{},...}},例如,一个包含hdfs和mapreduce服务的部署方案的部署单元的节点集合为servicesorderdeploy{hdfsservice{du_nn{1},du_snn{2},du_dn{1,2,3}},mapreduceservice{du_jt{1},du_tt{2,3}}}。
4、根据服务部署单元的节点集合servicesorderdeploy,依次进行服务的部署。
s3:使用同步引擎监测hadoop需求模型和hadoop部署模型中的信息变化情况,并在hadoop需求模型和/或hadoop部署模型中的信息发生变化时进行信息同步。
在本发明的一个是实施例中,采用sm@rt工具构造hadoop部署模型。
具体地,运行时模型用一组可管理的单元来表示系统的整体架构,将隐藏在系统内部的结构、状态、配置等运行时信息显示化地描述为标准的、面向管理者视角的结构化视图。
本发明采用sm@rt工具构造hadoop部署模型。给定系统的元模型和访问模型,其中,元模型描述了受管系统的信息,访问模型描述了管理接口的调用方法,基于以上输入,目标系统运行时体系结构能够由sm@rt工具自动生成,而它与系统间的双向一致性也能够得到保证。
如图7所示,本发明提供了一组关于hadoop集群服务部署的操作,概述了对不同类型模型元素的操作并对模型操作进行了分类,对于每种操作,本发明具体化了操作名称需要的参数和操作所提供的改变。
sm@rt支持hadoop部署模型与运行系统的双向同步。如图8所示,当同步引擎检测到hadoop部署模型中某个服务的角色单元增加了一个部署单元时,自动地在运行系统中添加一个虚拟机进行部署;当管理员在运行系统中删除这个虚拟机时,同步引擎也能够自动检测到这个变化,并调用管理接口终止相应的部署单元。
为了是本领域技术人员进一步理解本发明,将通过以下实施例进行详细说明。
为了验证本发明所提出方法的可行性和有效性,实现了一个自动部署和配置hadoop的实例,提供了一个用户定制的hadoop服务的解决方案,包括部署mapreduce服务和hbase服务。
实验在cloudstack上部署hadoop集群,利用cloudstack中的5个虚拟机部署mapreduce和hbase服务。其中,mapreduce服务部署在host-1、host-2、host-3三个虚拟机上;hbase服务部署在host-1、host-4、host-5三个虚拟机上。此外,不同的虚拟机分配了不同的cpu、内存、存储等资源,具体的配置细节与部署情况见表2。
表2节点部署情况
用户只需要定义hadoop集群的需求模型,本发明提出的方法就能够实现需求模型到部署模型的自动转换,并最终完成集群部署。
如图9所示,需求模型包括集群节点部分和集群服务部分。
在集群节点部分,nodetypes表示节点类型列表,包括三种节点类型,分别为“cpu:4,memory:8,storage:400”、“cpu:2、memory:8、storage:400”和“cpu:2、memory:4、storage:800”;nodes表示节点列表,包括5个节点,其中,id为1的node的节点类型对应id为nt1的nodetype,id为2和3的node的节点类型对应id为nt2的nodetype,id为4和5的node的节点类型对应id为nt3的nodetype。
在集群服务部分,mapreduce和hbase服务分别部署在其对应的3个节点上。
需求模型到部署模型的转换分为两部分,分别是集群节点的模型转换和集群服务的模型转换。
在集群节点部分,需求模型中的nodetype元素和node元素分别映射到部署模型中的vmtype元素和vm元素。因此,部署模型中也存在三种虚拟机类型(即vmtype)和5个虚拟机(即vm),如图10所示。
在集群服务部分,根据本发明提出的约束模型和通用算法,模型转换过程如下:
1、根据需求模型中服务列表services下的服务单元,得到需要部署的服务集合services{mapreduceservice,hbaseservice};
2、根据约束模型中mapreduceservice和hbaseservice之间的依赖关系可知,mapreduceservice和hbaseservice之间不存在依赖关系但这两个服务都依赖于hdfsservice,此时,hdfsservice未出现在服务集合中,因此,需要在服务集合services中补充hdfsservice并进行部署排序,得到实际需要部署的服务的有序集合servicesorder{hdfsservice,mapreduceservice,hbaseservice};
3、根据有序集合servicesorder,按照逆序的方式依次读取hbaseservice、mapreduceservice、hdfsservice并计算服务的部署方案:首先,根据需求模型中hbaseservice的软件部署模块(即agent)中的信息,得到hbase服务的部署节点列表,1、4、5号节点;其次,根据约束模型可知hbaseservice包含hmaster和hregionserver两种角色单元,hmaster有且仅有一个部署单元du_hm,hregionserver可以有多个部署单元du_rs,且hmaster和hregionserver不能部署在同一个节点上,此外,部署单元du_hm对hdfs服务的部署单元du_nn存在依赖,部署单元du_rs对hdfs服务的部署单元du_dn存在依赖;接着,根据节点信息可知和角色部署约束计算得到,hmaster和namenode的资源优先级和部署次序都是最高的,因此将这两个角色单元部署在资源丰富的1号节点,而4、5号节点部署角色单元hregionserver和datanode;类似地,在部署mapreduceservice时,通过需求模型和约束模型可以计算得到角色单元jobtracker和namenode部署在1号节点,而2、3号节点部署角色单元tasktracker和datanode;而在部署hdfsservice时,由约束模型可知,hdfsservice不依赖于其他服务,且namenode和seconderynamenode不能部署在同一节点,再根据hbaseservice和mapreduceservice部署节点信息可知,namenode部署在1号节点,seconderynamenode部署在2号节点,datanode部署在1~5号节点;最后,根据约束模型中部署单元的依赖关系记录其依赖的部署单元的部署节点信息,得到有序集合servicesorder中每一个服务的部署单元的节点集合,即servicesorderdeploy{hdfsservice{du_nn{1},du_snn{2},du_dn{1,2,3,4,5}},mapreduceservice{du_jt{1},du_tt{2,3}},hbaseservice{du_hm{1},du_rs{4,5}}}。
4、根据服务部署单元的节点集合servicesorderdeploy,依次进行服务的部署。
如图10所示,由集群节点的模型转换和集群服务的模型转换得到具体的hadoop部署模型。
本发明云环境中模型驱动的hadoop部署方法,针对云环境中多样化的软硬件资源与服务随需性给部署hadoop集群带来的困难,提出了模型驱动的hadoop集群服务部署方法,通过提出hadoop需求模型到部署模型的转换方法、实现部署模型与运行系统的双向同步,为hadoop部署提供了一种快速可扩展的集群服务部署方式,并在实际场景中验证了本发明的可行性和有效性。
另外,本发明实施例的云环境中模型驱动的hadoop部署方法的其它构成以及作用对于本领域的技术人员而言都是已知的,为了减少冗余,不做赘述。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!