一种用于天文软件Gridding的并行计算方法及其装置与流程
本发明涉及内存访问优化技术领域,特别是涉及一种用于天文软件Gridding的并行计算方法及其装置。
背景技术:
Gridding软件是天文学中非常重要的一个软件。以即将建成的世界上最大的天文射电望远镜-平方公里阵列(SKA)项目为例,Gridding的计算量占总计算量的30%左右。
Gridding的计算过程中存在着三层循环,最外侧循环的索引为dind,该dind用于索引天文样本数组中的天文样本数据,中间循环的索引为suppv,最内侧循环的索引为suppu。在最外侧的循环中依据天文样本数据计算gind及cind的值,其中samples数组中存放需要处理的天文样本数据。
由于samples[dind].iu,samples[dind].iv是由随机数生成的,导致不同的天文样本数据,其数值可能是相同的,故对于不同的循环索引dind(或者说对于不同的天文样本数据),其计算得到的gind的值可能是相同的,而每个gind元素唯一对应一个内存地址,若依据天文学数据(或dind)进行数据块划分的话,不同的数据块虽然包含不同的天文样本数据,但可能包含相同的gind元素,这种情况下,当不同的线程分别依据各个数据块内的gind元素进行卷积计算时,可能会出现一个内存地址同时被多个线程存取的情况,进而导致内存读写不一致,造成计算失效。
因此,如何提供一种能够避免内存访问冲突的用于天文软件Gridding的并行计算方法及其装置是本领域技术人员目前需要解决的问题。
技术实现要素:
本发明的目的是提供一种用于天文软件Gridding的并行计算方法及其装置,能够尽可能避免计算过程中各个线程对内存的访问冲突,提高Gridding程序的并行处理能力以及内存访问效率。
为解决上述技术问题,本发明提供了一种用于天文软件Gridding的并行计算方法,包括:
分别将天文样本数组中的每个天文样本数据对应的gind值映射到标准二维网格的格点处作为数据点,得到映射图;
分别沿所述映射图的横纵坐标方向以预设步长进行数据划分,得到多个以所述预设步长作为长和宽的内存网格;
分别为每个线程分配一个所述内存网格,每个所述线程的起始索引dind的索引范围为所述线程分配的内存网格所对应的部分天文样本数据;
各个所述线程分别将自身的起始索引dind当前对应的样本数据在自身分配的内存网格中所对应的数据点作为起始数据点,并依据所述起始数据点以及自身分配的内存网格中的数据点进行卷积计算,得到计算结果并写入内存。
优选地,各个所述线程依据所述起始数据点以及自身分配的内存网格中的数据点进行卷积计算的过程具体为:
各个所述线程自所述起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向进行suppu卷积计算,沿纵坐标的方向进行suppv卷积计算。
优选地,还包括:
将所述映射图内的各个所述数据点依据预设方向进行排序,得到每个所述数据点的序号;
相应的,各个所述线程依据所述起始数据点以及自身分配的内存网格中的数据点进行卷积计算的过程具体为:
各个所述线程自所述起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向依据序号从小到大的顺序依次进行suppu卷积计算,沿纵坐标的方向依据序号从小到大的顺序依次进行suppv卷积计算。
为解决上述技术问题,本发明还提供了一种用于天文软件Gridding的并行计算装置,包括:
映射模块,用于分别将天文样本数组中的每个天文样本数据对应的gind值映射到标准二维网格的格点处作为数据点,得到映射图;
划分模块,用于分别沿所述映射图的横纵坐标方向以预设步长进行数据划分,得到多个以所述预设步长作为长和宽的内存网格;
线程分配模块,用于分别为每个线程分配一个所述内存网格,每个所述线程的起始索引dind的索引范围为所述线程分配的内存网格所对应的部分天文样本数据;
各个所述线程,分别用于将自身的起始索引dind当前对应的样本数据在自身分配的内存网格中所对应的数据点作为起始数据点,并依据所述起始数据点以及自身分配的内存网格中的数据点进行卷积计算,得到计算结果并写入内存。
优选地,还包括:
排序模块,用于将所述映射图内的各个所述数据点依据预设方向进行排序,得到每个所述数据点的序号;
相应的,每个所述线程具体用于:
自所述起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向依据序号从小到大的顺序依次进行suppu卷积计算,沿纵坐标的方向依据序号从小到大的顺序依次进行suppv卷积计算。
优选地,还包括:
分别一一对应于各个所述线程的多个临时缓冲区,所述临时缓冲区用于存储自身对应的线程进行卷积计算过程中,实际索引的数据点超出自身分配的内存网格的范围时得到的计算结果;当全部所述线程完成计算后,将存储的计算结果写入内存并叠加至最终的计算结果内。
本发明提供了一种用于天文软件Gridding的并行计算方法及其装置,将每个天文样本数据的gind值映射到标准二维网格上,得到映射图,此时映射图内包括多个数据点,每个数据点对应一个gind值并唯一对应一个内存地址,且每个gind值对应一个或多个天文样本数据;之后将映射图的横纵坐标方向均按照预设步长进行划分,得到多个内存网格块,各个内存网格内包含的数据点几乎不会出现重合,故可以理解每个内存网格分别对应不同地址的内存块,然后为每个线程分配一个内存网格作为处理对象,此时,各个线程计算过程中访问的内存地址互不干扰。可见,本发明依据gind值进行数据划分,尽可能避免了内存的访问冲突,提高了Gridding程序的并行处理能力以及内存访问效率。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对现有技术和实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种用于天文软件Gridding的并行计算方法的过程的流程图;
图2为本发明提供的一种用于天文软件Gridding的并行计算装置的结构示意图。
具体实施方式
本发明的核心是提供一种用于天文软件Gridding的并行计算方法及其装置,能够尽可能避免计算过程中各个线程对内存的访问冲突,提高Gridding程序的并行处理能力以及内存访问效率。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种用于天文软件Gridding的并行计算方法,参见图1所示,图1为本发明提供的一种用于天文软件Gridding的并行计算方法的过程的流程图;该方法包括:
步骤s101:分别将天文样本数组中的每个天文样本数据对应的gind值映射到标准二维网格的格点处作为数据点,得到映射图;
步骤s102:分别沿映射图的横纵坐标方向以预设步长进行数据划分,得到多个以预设步长作为长和宽的内存网格;
步骤s103:分别为每个线程分配一个内存网格,每个线程的起始索引dind的索引范围为线程分配的内存网格所对应的部分天文样本数据;
步骤s104:各个线程分别将自身的起始索引dind当前对应的样本数据在自身分配的内存网格中所对应的数据点作为起始数据点,并依据起始数据点以及自身分配的内存网格中的数据点进行卷积计算,得到计算结果并写入内存。
其中,步骤s104中,各个线程依据起始数据点以及自身分配的内存网格中的数据点进行卷积计算的过程具体为:
各个线程自起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向进行suppu卷积计算,沿纵坐标的方向进行suppv卷积计算。
由图1可知,Gridding的suppu与suppv循环实际上是对天文样本数组计算卷积,卷积内核函数为数组C[cind+suppu],计算的尺寸(即总的循环计算次数)为sSize*sSize。
另外,这里的的预设步长为gSize/nT,即每一个线程分得的任务量为gSize/nT,其中nT为线程的总个数,对于第id个线程,其suppv计算的范围为[id*gSize/nT,(id+1)*gSize/nT-1],其suppv计算的范围为[id*gSize/nT,(id+1)*gSize/nT-1]。
作为优选地,该方法还包括:
将映射图内的各个数据点依据预设方向进行排序,得到每个数据点的序号;
相应的,各个线程依据起始数据点以及自身分配的内存网格中的数据点进行卷积计算的过程具体为:
各个线程自起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向依据序号从小到大的顺序依次进行suppu卷积计算,沿纵坐标的方向依据序号从小到大的顺序依次进行suppv卷积计算。
可以理解的是,排序后,每个线程对应的内存网格内部的gind索引(数据点)具有了次序,由于排序接近的数据点的地址也接近,因此排序后线程依据次序进行访问能够避免线程在进行数据访问时具有较大的内存跳跃。例如,假设内存网格内包括排序[13,8,15]位置的数据点需要进行访问,正常情况下,若按照[13,8,15]的顺序进行访问,13至8,内存访问跳跃的步长为5,由8至15,内存访问跳跃的步长为7,这样遍历这三个数据点导致的内存跳跃步长为12;而排序后访问次序为[8,13,15],内存跳跃步长为7。由此可见,排序后有效的降低了内存访问的跳跃性,提高了内存访问的效率。
另外,这里的排序可以是在内存网格划分前先排序,也可以是在内存网格划分完成后再进行排序,具体采用哪种方式本发明不作具体限定。并且,这里的排序是按照一定的方向进行排序的,例如可以按照标准二维网格的横坐标方向或纵坐标方向,当然,本发明对此也不做具体限定。
为方便理解,以下为上述方法的一种具体实现方式:
上述部分首先计算天文样本数组的索引沿suppu及suppv方向的最小及最大值。其中沿suppu方向的最小值以iu_min标识,最大值以iu_max标识;沿suppv方向的最小值以iv_min标识,最大值以iv_max标识。随后基于该最小最大值对映射图进行二维划分。
临时缓冲区仅针对线程内对应的局部卷积结果数组进行添加。每个线程内的局部卷积结果数组在开辟时均采用了以下代码:
iu_grid_size[id]=iu_len_id+support*2;
iv_grid_size[id]=iv_len_id+support*2;
grid_nt[id]=(Value*)malloc(iu_grid_size[id]*iv_grid_size[id]*sizeof(Value));
其中,iu_grid_size[id]及iv_grid_size[id]是线程标识为id的iu,及iv方向的局部卷积结果数组的维度。该局部卷积结果数组以grid_nt表示。其中每个维度均额外分配了support*2的临时空间。
第二部分为计算核心的OpenMP并行化,其过程为:在开始计算之前,启动OpenMP线程;随后各个线程照上述得到各自的内存网格,由于每个内存网格对应一个数据块,滞后各线程针对各自的数据块包含的天文样本数据进行计算。内核的计算共包含3层循环,伪代码如下,各个线程内的计算由bs开始,be结束:
由第二部分可以看到,在循环开始前,对每一个线程的数据均采用quicksort_s函数进行了排序,以此提升内存访问的效率。
第三部分为线程间数据的合并:
为避免计算过程中各线程更新局部卷积结果数组时导致的写冲突问题,每个线程均开辟了自己的临时缓冲区。当各个线程内的计算结果后,需要将这些临时缓冲区内的数据叠加至局部卷积结果数组中。由第三部分可以看到,叠加操作仅针对局部卷积结果数组进行,共四层循环。
本发明提供了一种用于天文软件Gridding的并行计算方法,将每个天文样本数据的gind值映射到标准二维网格上,得到映射图,此时映射图内包括多个数据点,每个数据点对应一个gind值并唯一对应一个内存地址,且每个gind值对应一个或多个天文样本数据;之后将映射图的横纵坐标方向均按照预设步长进行划分,得到多个内存网格块,各个内存网格内包含的数据点几乎不会出现重合,故可以理解每个内存网格分别对应不同地址的内存块,然后为每个线程分配一个内存网格作为处理对象,此时,各个线程计算过程中访问的内存地址互不干扰。可见,本发明依据gind值进行数据划分,尽可能避免了内存的访问冲突,提高了Gridding程序的并行处理能力以及内存访问效率。
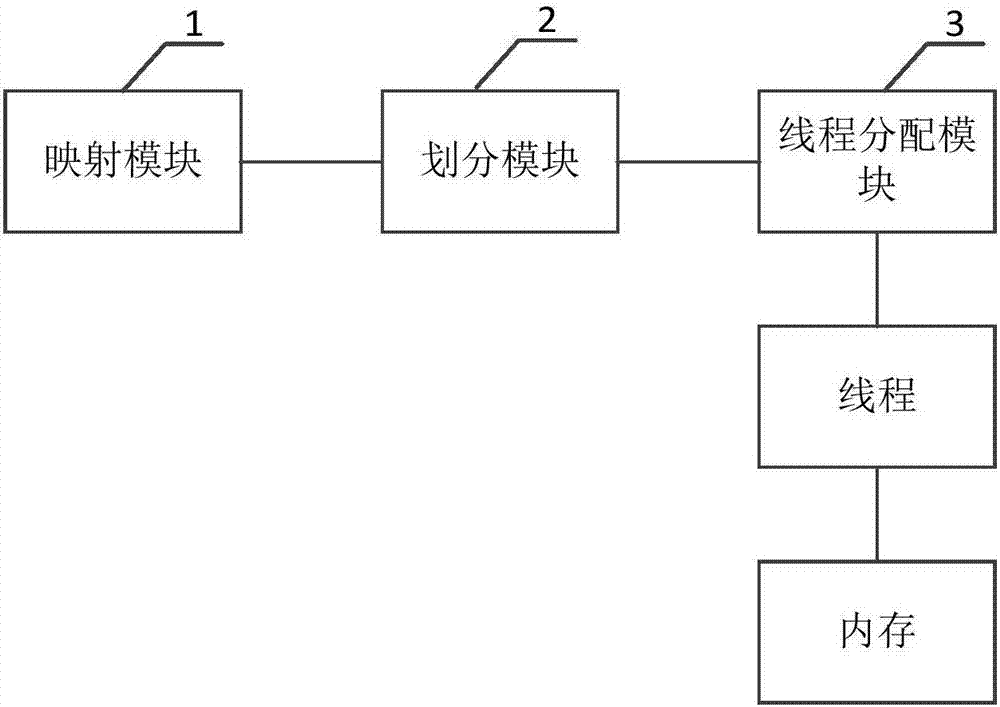
本发明还提供了一种用于天文软件Gridding的并行计算装置,参见图2所示,图2为本发明提供的一种用于天文软件Gridding的并行计算装置的结构示意图。该装置包括:
映射模块1,用于分别将天文样本数组中的每个天文样本数据对应的gind值映射到标准二维网格的格点处作为数据点,得到映射图;
划分模块2,用于分别沿映射图的横纵坐标方向以预设步长进行数据划分,得到多个以预设步长作为长和宽的内存网格;
线程分配模块3,用于分别为每个线程分配一个内存网格,每个线程的起始索引dind的索引范围为线程分配的内存网格所对应的部分天文样本数据;
各个线程,分别用于将自身的起始索引dind当前对应的样本数据在自身分配的内存网格中所对应的数据点作为起始数据点,并依据起始数据点以及自身分配的内存网格中的数据点进行卷积计算,得到计算结果并写入内存。
作为优选地,该装置还包括:
排序模块,用于将映射图内的各个数据点依据预设方向进行排序,得到每个数据点的序号;
相应的,每个线程具体用于:
自起始数据点开始,依据自身分配的内存网格中的数据点,沿横坐标的方向依据序号从小到大的顺序依次进行suppu卷积计算,沿纵坐标的方向依据序号从小到大的顺序依次进行suppv卷积计算。
作为优选地,该装置还包括:
分别一一对应于各个线程的多个临时缓冲区,临时缓冲区用于存储自身对应的线程进行卷积计算过程中,实际索引的数据点超出自身分配的内存网格的范围时得到的计算结果;当全部线程完成计算后,将存储的计算结果写入内存并叠加至最终的计算结果内。
可以理解的是,一个线程在进行卷积计算时,会依据自身分配的内存网格中的一个数据点作为起始,然后向某个方向的数据点进行卷积操作,这个过程中,该线程可能会索引超出自身分配的内存网格的数据点进行卷积,即该线程可能会访问其他线程分配的内存网格,这种情况下,该线程在得到计算结果后写入内存时,会与其他线程发送内存写冲突,为避免这种情况出现,需要为每个线程分配一个临时缓冲区,将自身索引越界时得到的计算结果进行缓存,当各个线程全部完成计算后,将结果进行叠加,整合为一个完整计算结果后,再写入内存中,从而保证计算结果的正确性。
本发明提供了一种用于天文软件Gridding的并行计算装置,将每个天文样本数据的gind值映射到标准二维网格上,得到映射图,此时映射图内包括多个数据点,每个数据点对应一个gind值并唯一对应一个内存地址,且每个gind值对应一个或多个天文样本数据;之后将映射图的横纵坐标方向均按照预设步长进行划分,得到多个内存网格块,各个内存网格内包含的数据点几乎不会出现重合,故可以理解每个内存网格分别对应不同地址的内存块,然后为每个线程分配一个内存网格作为处理对象,此时,各个线程计算过程中访问的内存地址互不干扰。可见,本发明依据gind值进行数据划分,尽可能避免了内存的访问冲突,提高了Gridding程序的并行处理能力以及内存访问效率。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
还需要说明的是,在本说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!