一种基于临近点法的聚类个数自动确定谱聚类方法与流程
本发明属于谱聚类算法领域,具体涉及一种基于临近点法的聚类个数自动确定谱聚类方法。
背景技术:
聚类就是将物理或者抽象的对象中相似性较高的对象聚集在同一个类中,相似性较低的对象分配在不同类中,从而使得同一个聚类形成的簇中的所有对象之间具有较高相似性,而不同簇的对象之间的相似性较低。聚类分析技术在基因表达分析和图像处理等领域都有着十分广泛的应用。聚类算法是处理图像分割的主要方法之一,已经被广泛应用在图像分割中。而在过去的数十年中,谱聚类算法在图像分割和数据聚类中也表现出明显的优势。
在谱图理论基础上建立的一种称之为谱聚类的算法,与传统的聚类算法相比较起来,它具有能在任意形状的样本空间上聚类的优点,是将数据映射到特征空间中进行聚类的算法。有些算法,例如k-mean聚类,是聚类分析中最经典的算法,算法较为简单,能够用于多种类型数据的聚类。但当数据集为非凸的时候,k-means算法往往会陷入局部最优解,聚类效果欠佳。而谱聚类则能够克服k-means聚类等一些经典方法存在的某些缺陷。
最早的谱聚类算法是由ng、bach和jordan等人提出的多路谱聚类方法。而在接下来的发展过程中出现的具有代表性的谱聚类算法还有meila提出的多路归一化割谱聚类方法和elhamifar等提出的稀疏子空间谱聚类。在谱聚类的发展过程中也出现了许多问题,很多人也针对这些问题提出了相应的改进算法,但都不够完善。例如,赵峰等人利用模糊c-means聚类得到的划分矩阵提出了模糊相似度度量,这个算法能很好的处理现实中不确定性的问题,但是算法计算复杂度相当高,此时计算机对于大型相似度矩阵很难进行存储和分解;fowlkeset等人提出了
总的来说,目前的典型的谱聚类算法存在以下几个问题。首先,谱聚类算法存储相似度矩阵的空间复杂度为o(n2),尤其在处理图像的时候,图像本身的数据量很大,算法对于大型相似度矩阵很难存储和分解,即空间复杂度过高;其次,谱聚类算法对高斯核函数中的尺度参数非常敏感,但是难以选取合适的尺度参数来很好的反应复杂数据集的空间分布特点;最后,典型谱聚类算法需要人工输入聚类个数。
技术实现要素:
为了克服现有谱聚类算法存在的空间复杂度过高,难以选取合适的尺度参数来很好的反应复杂数据集的空间分布特点,需要人工输入聚类个数的不足,针对这些问题,本发明提出了一种在临近点法基础上,自动选取聚类个数并能够根据数据分布估计每个数据点的局部尺度参数的谱聚类方法,有效降低了空间复杂度,选取合适的尺度参数来很好的反应复杂数据集的空间分布特点,不需要人工输入聚类个数。
本发明解决其技术问题所采用的技术方案是:
一种基于临近点法的聚类个数自动确定谱聚类方法,包括以下步骤:
1)数据初始化,过程如下:
1.1)对数据集的所有维进行了归一化处理,输入数据集,对数据集的每一维x1,…,xn∈rm做归一化处理,即处理后第i个数据的第j维数值为:
yi(j)=(xi(j)-min(x(j)))/(max(x(j))-min(x(j)))(1)
式(4)中,其中n表示数据个数,m表示数据维数,x(j)表示所有数据点的第j维,xi(j)表示第i个数据的第j维的数值;
2)基于临近点法的稀疏相似度矩阵的计算,过程如下:
2.1)首先将获得的数据进行区域分块操作,将所有数据划分到block个区间内,即每个区间内有
2.2)计算第j区间的区间距离矩阵distj=[d(j-1)*m+1;d(j-1)*m+2;…;dj*m],其中第i个数据与所有点的距离形成点距离矩阵的表示形式为di=[||yi-y1||,||yi-y2||,…,||yi-yn||],||yi-yj||表示数据点i和数据点j之间的距离值;
2.3)依据得到的区间距离矩阵找出第j个区间内每个数据点对应的临近点,保留与临近点之间的距离值,删除其余距离值,从而得到区间稀疏距离矩阵;
2.4)通过临近点法将数据点所对应的局部尺度参数σi定义为该点的t个临近点与数据点之间的距离平均值,如下所示:
式(2)中,d(xi,xj)表示数据点i与临近点中第j个点之间的距离;
2.5)由于在稀疏相似度矩阵中只保留数据点与临近点之间的相似值,所以在计算相似值时两个数据点对应的局部尺度参数相近,即相似值计算公式可以改写为:
依据公式(3),计算出区间稀疏距离矩阵所对应的区间稀疏相似度矩阵;
2.6)如果迭代完成,即j=block,则执行步骤2.7);否则j=j+1,并执行步骤2.2);
2.7)所得到的所有区间稀疏相似度矩阵整合得到稀疏相似度矩阵。
3)自动确定聚类中心个数,过程如下:
3.1)给定参数percent,通过区间距离矩阵计算各个数据点的密度值,得到密度矩阵
ρi=∑f(dij)(4)
其中,m矩阵是由距离矩阵中最小的percent×n个距离值组成,percent表示邻居点个数占总数据点距离个数的比例,dij表示点i和点j之间的距离;
3.2)计算每个数据点的距离值,得到距离矩阵
δi=min(dij)(ρj≥ρi)(6)
对于ρ值最大的点,存在
δi=max(δj)(i≠j)(7)
否则将该点判断为非候选点,该点局部密度为密度比它大的临近点中距离最近点的距离;
3.3)根据步骤3.1)和3.2)得到的密度矩阵
3.4)本方法引入变量γ,对于任意一个数据点i,其γ定义为:
γi=ρi×δi(8)
根据γ的概率分布情况,对于该γ的分布进行曲线的拟合,发现其图形的拟合曲线形状类似于一条正态分布曲线;
3.5)由ρ-δ关系图上的离散数据点进行一元线性拟合,得到拟合曲线yδ=kxρ+b0,计算各个数据点的残差值εδi=yδi-δi,绘制残差直方图εδi-h,分别用钟型曲线进行正态拟合,得到方差值σδ,利用λσ原则确定处在置信区间外的点个数。
4)特征分解,求取特征向量组,过程如下:
4.1)首先需要计算出度矩阵d和拉普拉斯矩阵l。度矩阵是一个对角阵,它的对角线上的元素dii由相似度矩阵的第i行元素相加求和得到的。度矩阵d的计算公式如下:
然后根据度矩阵d和相似度矩阵s计算得到拉普拉斯矩阵l,拉普拉斯矩阵计算公式如下:
4.2)将拉普拉斯矩阵进行特征分解,在选取最优特征向量组合的时候,选择直接选取法,直接从依据特征值从大到小排序后的序列中选取前k个特征值所对应的特征向量,选出的这k个特征向量是所有特征向量中最重要的特征向量;
4.2)将k个最大特征值所对应的特征向量组成矩阵v,v=[v1,v2,…,vk],输出特征向量组v。
5)标准化特征向量组,并聚类,过程如下:
对所选取的特征向量组v进行标准化处理,得到矩阵u:
此时u矩阵中每行数据表示原始数据在拉普拉斯空间中的映射位置,接着对u矩阵所表示的所有数据在特征空间中的映射的元素进行k-means聚类。
6)最优临近点选取,过程如下:
6.1)设计了一个fitness函数作为评价指标。fitness函数由两部分构成:全局的簇内距离和全局的簇间距离。根据聚类效果的好坏的最本质定义:簇内距离越小越好,簇间距离越大越好,令
对于一个给定的临近点个数,fitness函数值越大,则说明聚类效果越好。
6.2)设置临近点个数选取的初始值t0和临近点选取最大值;
6.3)如果临近点个数迭代至最大值时,输出所有迭代临近点个数中最大fitness函数值所对应的临近点个数,以及对应的聚类结果;否则更新临近点个数,将程序转至步骤2.3)再次进行聚类。
进一步,所述步骤2.4)中,通过临近点法将数据点所对应的局部尺度参数的取值定义为该点的临近点与数据点之间距离的平均值。利用所获得的局部尺度参数代替高斯核函数的单个尺度参数,能准确分离出稀疏背景簇内包含的紧密簇,提高聚类的准确度。
如步骤3.2)、3.3)和3.5)所述,该方法能够依据数据点密度和距离的关系,利用两者关系进行残差分析,得到在置信区间外的拟合产生的奇异点个数,即为聚类中心个数,而且在计算确定聚类中心点个数时所需的数据点密度和距离的时候,使用局部距离矩阵代替整体距离矩阵,降低了算法的空间复杂度,并能准确的确定聚类个数。
在所述步骤6.1)中,通过设计一个fitness函数,通过迭代比较所有范围内临近点对应的全局的簇间距离和全局的簇内距离之比,来反应该临近点个数所对应的聚类效果,实现临近点个数的参数自适应。
本发明的技术构思为:基于临近点法的聚类个数自动确定谱聚类算法,能够根据数据分布估计每个数据点的局部尺度参数,自动确定聚类中心的个数,降低了聚类过程的参数敏感性问题。该算法对于一个数据集的处理,首先进行预处理,为了防止一些数据集的某些维远远大于该数据集的其他维,而导致其他维的重要性可能被减弱甚至被忽略的问题,我们对数据集的所有维进行了归一化处理;接着通过临近点法计算出区间稀疏距离矩阵以及定义为临近点距离均值的局部尺度参数,通过区间稀疏距离矩阵和相似度值计算公式计算出区间稀疏相似度矩阵,并整理成整体稀疏相似度矩阵;然后调用ccfd算法,先确定数据点的局部密度和具有更高局部密度的其他点的最小距离,利用两者关系进行残差分析,得到在置信区间外的拟合产生的奇异点个数,即为聚类中心个数;接着依据公式计算出度矩阵d和拉普拉斯矩阵l,并对拉普拉斯矩阵l进行特征分解,在选取最优特征向量组合的时候,选择直接选取方法,取出合适的特征向量组;最后对数据集在特征空间中的映射特征向量组中的所有元素进行标准化处理,后进行k-means聚类,得到聚类结果;计算fitness函数值,不断迭代,选取最高fitness函数值所对应的最优临近点个数的聚类结果进行输出。
本发明的有益效果主要表现在:根据数据分布估计每个数据点的局部尺度参数,能够自动确定聚类中心的个数,并且实现了临近点个数的参数自适应。在真实数据集的实验结果表明,该算法具有良好的适用性,提高了聚类的质量,使得聚类的结果更加准确。
附图说明
图1是稀疏相似度矩阵计算流程图。
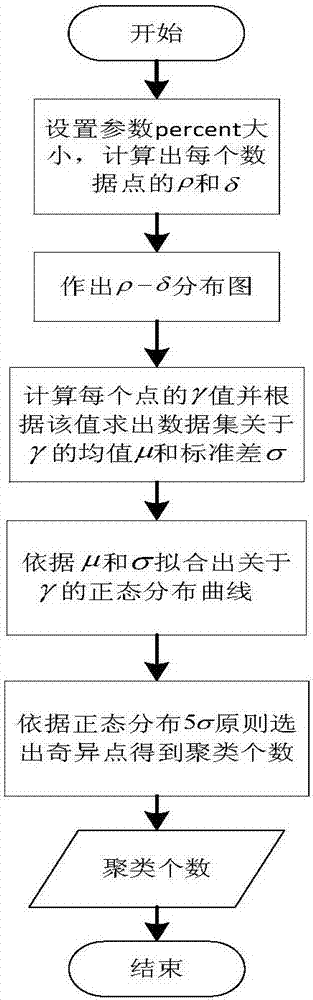
图2是ccfd方法流程图。
图3是样本数据分布与ρ-δ分布图的映射关系,其中(a)是样本数据分布图,(b)是ρ-δ分布图。
图4是选取特征向量组流程图
图5是fitness函数迭代确定最佳临近点个数流程图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图5,一种基于临近点法的聚类个数自动确定谱聚类方法,包括以下步骤:
1)数据预处理,对实际数据集进行分析我们可以看出来,一些数据集的某些维远远大于该数据集的其他维,而且这些维数值的差值较大,这导致其他维的重要性可能被减弱甚至被忽略。在没有获得数据集的每一维重要性的信息情况下,我们对数据集的所有维进行了归一化处理,具体过程如下:
输入数据集,对数据集的每一维x1,…,xn∈rm做归一化处理,即第i个数据处理后的第j维数值为:
yi(j)=(xi(j)-min(x(j)))/(max(x(j))-min(x(j)))(1)
式(4)中,其中n表示数据个数,m表示数据维数,x(j)表示所有数据点的第j维,xi(j)表示第i个数据的第j维的数值。
2)基于临近点法的稀疏相似度矩阵的计算,算法流程图如图(1)所示,具体过程如下:
2.1)首先将获得的数据进行区域分块操作,将所有数据划分到block个区间内,即每个区间内有
2.2)计算第j区间的区间距离矩阵distj=[d(j-1)*m+1;d(j-1)*m+2;…;dj*m]其中第i个数据与所有点的距离形成点距离矩阵的表示形式为di=[||yi-y1||,||yi-y2||,…,||yi-yn||],||yi-yj||表示数据点i和数据点j之间的距离值;
2.3)临近点法的主要思想:如果一个样本在空间中的最相似的几个样本中的大多数属于某一个类别,则该样本也属于这个类别。使用临近点法计算相似度矩阵主要是保留临近点之间的相似度值,而舍去距离较远点之间的相似度值。这样能增大类内的相似度,而减小类间的相似度,增强聚类效果。
使用临近点法依据得到的区间距离矩阵找出第j个区间内每个数据点对应的临近点,保留与临近点之间的距离值,删除其余距离值,从而得到区间稀疏距离矩阵;
2.4)通过临近点法将数据点所对应的局部尺度参数σi的取值定义为该点t个临近点与数据点之间距离的平均值,如公式(2)所示:
式(2)中,d(xi,xj)表示数据点i与该点所有t个临近点中第j个点之间的距离,利用每个数据点的局部尺度参数代替高斯核函数的单个尺度参数,能准确分离出稀疏背景簇内包含的紧密簇;
2.5)由于在稀疏相似度矩阵中只存在数据点与临近点之间的相似值,所以在计算相似值时两个数据点对应的局部尺度参数相近,即相似值计算公式可以改写为:
依据公式(3),计算出区间稀疏距离矩阵所对应的区间稀疏相似度矩阵;
2.6)如果迭代完成,即j=block,则执行步骤2.7);否则j=j+1,并执行步骤2.2);
2.7)所得到的所有区间稀疏相似度矩阵整合得到稀疏相似度矩阵。
3)自动确定聚类中心个数ccfd算法流程图如图2所示,其基本思想如下:
a.簇类中心被较低局部密度的临近点所包围,且和具有更高局部密度的其他数据对象有相对较大的距离。
b.噪声点具有相对较小的局部密度和较大的距离。
具体过程如下:
3.1)给定参数percent,通过区间距离矩阵计算各个数据点的密度值,得到密度矩阵
ρi=∑f(dij)(4)
其中,m矩阵是由距离矩阵中最小的percent×n个距离值组成,percent表示邻居点个数占总数据点距离个数的比例,dij表示点i和点j之间的距离。
为了减小算法的空间复杂度,本方法采用一种改进的局部密度计算方法,具体的数据点局部密度计算方法步骤如下:
3.1.1)初始化一个两维的矩阵m,设定矩阵m的第二维存储percent×n个距离值,矩阵m的第一维存储该距离值所属数据点标号,矩阵m用于存储整个距离矩阵中最小的percent×n个距离值,其中j=1,区间个数为block;
3.1.2)依据上一步,计算出第j区间的区间距离矩阵,将第j区间的区间距离矩阵的所有距离值存入m矩阵的第二中,并在第一维中标记出每个点所属数据点;
3.1.3)判断矩阵m中距离值个数,如果个数大于percent×n个,则保留距离值最小的percent×n个;
3.1.4)如果迭代完成,即j=block,则执行步骤3.2.5);否则j=j+1,并执行步骤3.2.2);
3.1.5)依据保留在矩阵m中数据点标号的个数来定义数据点的局部密度,得到密度矩阵
3.2)计算每个数据点的距离值,得到距离矩阵
δi=min(dij)(ρj≥ρi)(6)
对于ρ值最大的点,存在
δi=max(δj)(i≠j)(7)
否则将该点判断为非候选点,该点局部密度为密度比它大的临近点中距离最近的点距离;
为了减小算法的空间复杂度,本方法采用一种改进的距离值计算方法,具体的数据点距离值计算方法步骤如下:
3.2.1)首先将步骤2.2)所得到的区间距离矩阵整理成完整的距离矩阵;
3.2.2)依据密度矩阵和临近点法,得到数据点的临近点密度;
3.2.3)如果临近点中没有点的密度大于该点密度,则将该点判断为候选点;否则该点为非候选点,其距离值为密度大于该点的临近点中距离最小的点;
3.2.4)依据公式(6)和公式(7)计算候选点的距离值;
3.2.5)整合所有数据点的距离值,输出该距离值矩阵。
3.3)根据步骤3.1)和3.2)得到的密度矩阵
例如样本数据集dataset1,其二维空间内数据分布,如图3(a)所示。计算样本数据集中每个数据点i的局部密度ρi和到密度更高点的最小距离ρi,绘制出ρ-δ分布图,如图3(b)所示。数据分布与数据对象ρ-δ分布存在映射关系,如图3所示。其中,a1、a2、a3是图3(a)中的三个聚类中心,他们在图3(a)的ρ-δ分布图中表现出了较大的ρ值和δ值;对于其他点,称其为边界点,它们均属于某一个类簇,表现出较小的ρ值和δ值。
3.4)本方法引入变量γ,对于任意一个数据点i,其γ定义为:
γi=ρi×δi(8)
根据γ的概率分布情况,对于该γ的分布进行曲线的拟合,发现其图形的拟合曲线形状类似于一条正态分布曲线;
3.5)由ρ-δ关系图上的离散数据点进行一元线性拟合,得到拟合曲线yδ=kxρ+b0,计算各个数据点的残差值εδi=yδi-δi,绘制残差直方图εδi-h,分别用钟型曲线进行正态拟合,得到均值μ和方差值σ,利用λσ原则确定处在置信区间外的奇异点个数。具体方法如下:
设置边界值wide=μ+λσ,将数据集中所有点的γ值与wide进行比较。对于数据点i,若γ>wide,则标记i为奇异点。依据这种思路比较所有数据点的γ值,从而得出聚类个数k。
4)特征分解,求取合适的特征向量组,流程图如图4所示,具体过程如下:
4.1)首先需要计算出度矩阵d和拉普拉斯矩阵l。度矩阵是一个对角阵,它的对角线上的元素dii由相似度矩阵的第i行元素相加求和得到的。度矩阵d计算公式如下:
然后根据度矩阵d和相似度矩阵s计算得到拉普拉斯矩阵l,拉普拉斯矩阵计算公式如下:
4.2)将拉普拉斯矩阵进行特征分解。在选取最优特征向量组合的时候,选择直接选取方法,是直接从依据特征值大小从大到小排序后的序列中选取前k个特征向量,选出的这k个特征向量是所有特征向量中最重要的特征向量;
4.2)将k个最大特征值所对应的特征向量组成矩阵v,v=[v1,v2,…,vk],输出特征向量组v。
5)标准化特征向量组,并聚类,具体过程如下:
5.1)对所选取的特征向量组v进行标准化处理,得到矩阵u:
此时u矩阵中每行数据表示原始数据在拉普拉斯空间中的映射位置
5.2)随机设置k个不同点为初始中心点,初始qold为无穷大,并设置聚类迭代阈值threshold;
5.3)将所有数据点分配到离该点最近的聚类中心所对应的类中,并计算点到所属聚类中心点距离;
5.4)更新聚类中心点为现有聚类中心边上的一点;
5.5)计算所有点到所属聚类的中心点距离总和,记为qnew;
5.6)判断threshold是否大于|qnew-qold|/qold,如果大于,则输出现有中心点所有数据点的类标信息;否则范围步骤5.3)。
6)最优临近点个数选取,流程图如图5所示,具体过程如下:
6.1)设计了一个fitness函数作为评价指标。fitness函数由两部分构成:全局的簇内距离和全局的簇间距离。根据聚类效果的好坏的最本质定义:簇内距离越小越好,簇间距离越大越好,令
对于一个给定的临近点个数,fitness函数值越大,则说明聚类效果越好。
6.2)设置临近点个数选取的初始值t0和临近点选取最大值;
6.3)如果临近点个数迭代至最大值时,输出所有迭代临近点个数中最大fitness函数值所对应的临近点个数,以及对应的聚类结果;否则更新临近点个数,转至步骤2.3)再次进行聚类。
- 还没有人留言评论。精彩留言会获得点赞!