一种基于文本匹配的信息处理方法及装置与流程
本发明涉及信息处理领域,具体涉及一种基于文本匹配的信息处理方法及装置。
背景技术:
现有的招聘求职网站仅仅是互联网PC终端的APP化,还是局限于普通的招聘求职网站,有的多一些延深的视频功能或者支付功能,但是根据求职者和供职者之间的信息匹配功能尚不健全,从而导致了求职者难以找到最为适宜的供职者,而供职者也难以找到最为适宜的人力资源,从而导致了人才的浪费和招聘效率的低下。
技术实现要素:
为了解决上述技术问题,本发明提供一种基于文本匹配的信息处理方法及装置。
本发明是以如下技术方案实现的:
一种基于文本匹配的信息处理方法,包括:
获取第一用户的信息并将所述第一用户的信息录入数据库,所述第一用户的信息包括第一用户的个人基本信息以及量表信息;
获取第二用户的信息并将所述第二用户的信息录入数据库,所述第二用户的信息包括第二用户的基本信息、空缺岗位信息以及空缺岗位期望匹配度;
对于选定的第二用户,将每一个第一用户的信息和所述选定的第二用户的信息进行文本匹配以获取匹配度;
若匹配度大于所述第二用户的期望匹配度,则对应的第一用户被选定;
将选定的第一用户的信息呈现给所述第二用户。
进一步地,还包括:
对于选定的第一用户,将每一个第二用户的信息和所述选定的第一用户的信息进行文本匹配以获取匹配度;
若所述匹配度大于所述第二用户的期望匹配度,则所述第二用户被选定;
将选定的第二用户的信息呈现给所述第一用户。
进一步地,所述文本匹配包括:
提取第一用户的信息的关键词;
提取第二用户的信息的关键词;
根据预先存储的词频表计算提取的每个关键词在数据库中的各文本中的权重;所述词频表根据各个词语在数据库中的各文本中的出现频率周期性更新;
根据计算得到的每个关键词在数据库中的各文本中的权重,计算所述第一用户的信息和所述第二用户的信息的匹配度。
进一步地,所述词频表根据预设的匹配规则进行设定,若所述匹配规则被改变,所述词频表也被改变。
进一步地,还包括:
按照匹配度的高低,由高到低地将选定的第二用户的信息呈现给所述第一用户。
进一步地,按照匹配度的高低,由高到低地将选定的第一用户的信息呈现给所述第二用户。
进一步地,还包括:
若第一用户和第二用户双方互相选择,则开启第一用户和第二用户之间的即时通信窗口。
一种基于文本匹配的信息处理装置,包括:
第一数据获取模块,用于获取第一用户的信息并将所述第一用户的信息录入数据库,所述第一用户的信息包括第一用户的个人基本信息以及量表信息;
第二数据获取模块,用于获取第二用户的信息并将所述第二用户的信息录入数据库,所述第二用户的信息包括第二用户的基本信息、空缺岗位信息以及空缺岗位期望匹配度;
第一匹配模块,用于对于选定的第二用户,将每一个第一用户的信息和所述选定的第二用户的信息进行文本匹配以获取匹配度;
第一选定模块,用于若匹配度大于所述第二用户的期望匹配度,则对应的第一用户被选定;
第一呈现模块,用于将选定的第一用户的信息呈现给所述第二用户。
第二匹配模块,用于对于选定的第一用户,将每一个第二用户的信息和所述选定的第一用户的信息进行文本匹配以获取匹配度;
第二选定模块,用于若所述匹配度大于所述第二用户的期望匹配度,则所述第二用户被选定;
第二呈现模块,用于将选定的第二用户的信息呈现给所述第一用户;
进一步地,第一匹配模块和第二匹配模块均包括:
关键词提取单元,用于提取第一用户的信息的关键词和第二用户的信息的关键词;
权重提取单元,用于根据预先存储的词频表计算提取的每个关键词在数据库中的各文本中的权重;所述词频表根据各个词语在数据库中的各文本中的出现频率周期性更新;
匹配度计算单元,用于根据计算得到的每个关键词在数据库中的各文本中的权重,计算所述第一用户的信息和所述第二用户的信息的匹配度。
进一步地,还包括:
排序单元,用于按照匹配度高低对第一用户或第二用户进行排序。
本发明的有益效果是:
本发明提供了一种基于文本匹配的信息处理方法及装置,可以用于实现求职资料和招聘资料的自动文本匹配,从而构建一个面向求职者和供职者的双向平台。具体地,通过将求职资料和招聘资料进行分词和量化,能够为双方均呈现出简洁直白匹配度高的信息,从而提升招聘效率,减少人才浪费。
附图说明
图1是发明的一种基于文本匹配的信息处理方法流程图。
图2是本发明的文本匹配方法流程图。
图3是本发明一种基于文本匹配的信息处理装置框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
实施例1:
一种基于文本匹配的信息处理方法,包括:
步骤101,获取第一用户的信息并将所述第一用户的信息录入数据库,所述第一用户的信息包括第一用户的个人基本信息以及量表信息。
具体地,对于招聘软件而言,所述第一用户可以为求职者,所述第一用户的信息包括求职者的个人信息以及量表信息。
比如,所述量表信息可以是人格测量表;职业兴趣测量表和/或胜任力模型量表。
所述求职者的个人信息可以包括个人基本信息,具体可以包括姓名、年龄、性别、健康状况、身高、体重,学历、毕业院校、职业证书等;还可以包括工作经历,具体可以包括单位,职位,时间,成就等;还可以包括求职意向,具体可以包括行业、地区、职位、薪酬水平以及其它特殊要求。
步骤102,获取第二用户的信息并将所述第二用户的信息录入数据库,所述第二用户的信息包括第二用户的基本信息、空缺岗位信息以及空缺岗位期望匹配度。
具体地,对于招聘软件而言,所述第二用户可以为供职者,所述第二用户的信息包括供职者的基本信息、空缺岗位信息以及空缺岗位期望匹配度。具体地,空缺岗位信息与空缺岗位期望匹配度一一对应,即一个空缺岗位信息对应一个空缺岗位期望匹配度。
所述供职者的基本信息可以包括企业基本信息,比如公司名称、地区、性质、规模等;所述空缺岗位信息可以包括空缺岗位名称、工作职责关键词、岗位胜任力模型、提供薪酬范围、特殊要求等。
步骤103,对于选定的第二用户,将每一个第一用户的信息和所述选定的第二用户的信息进行文本匹配以获取匹配度。
步骤104,若匹配度大于所述第二用户的期望匹配度,则对应的第一用户被选定。
步骤105,将选定的第一用户的信息呈现给所述第二用户。
具体地,可以按照匹配度的高低,由高到低地将选定的第一用户的信息呈现给所述第二用户。即将适合于第二用户(供职者)提供的岗位的第一用户(求职者)呈现给第二用户(供职者)。具体的呈现方式可以通过电脑网页、手机app界面等呈现。呈现内容可以包括序号、第一用户的姓名以及第一用户的匹配度。若第二用户(供职者)选定一个第一用户(求职者),还可以进一步浏览所述第一用户(求职者)的详细信息,比如个人简历。
进一步地,还包括:
步骤106,对于选定的第一用户,将每一个第二用户的信息和所述选定的第一用户的信息进行文本匹配以获取匹配度;
步骤107,若所述匹配度大于所述第二用户的期望匹配度,则所述第二用户被选定;
步骤108,将选定的第二用户的信息呈现给所述第一用户。
具体地步骤103-105与步骤106-108之间没有明确的先后关系。
具体地,可以按照匹配度的高低,由高到低地将选定的第二用户的信息呈现给所述第一用户。即将适合于第一用户(求职者)应聘的岗位的第二用户(供职者)呈现给第一用户(求职者)。具体的呈现方式可以通过电脑网页、手机app界面等呈现。呈现内容可以包括序号、第二用户的名称以及提供的岗位,以及所述岗位的匹配度。若第一用户(求职者)选定一个第二用户(供职者),还可以进一步浏览所第二用户(供职者)的详细信息,比如企业信息。
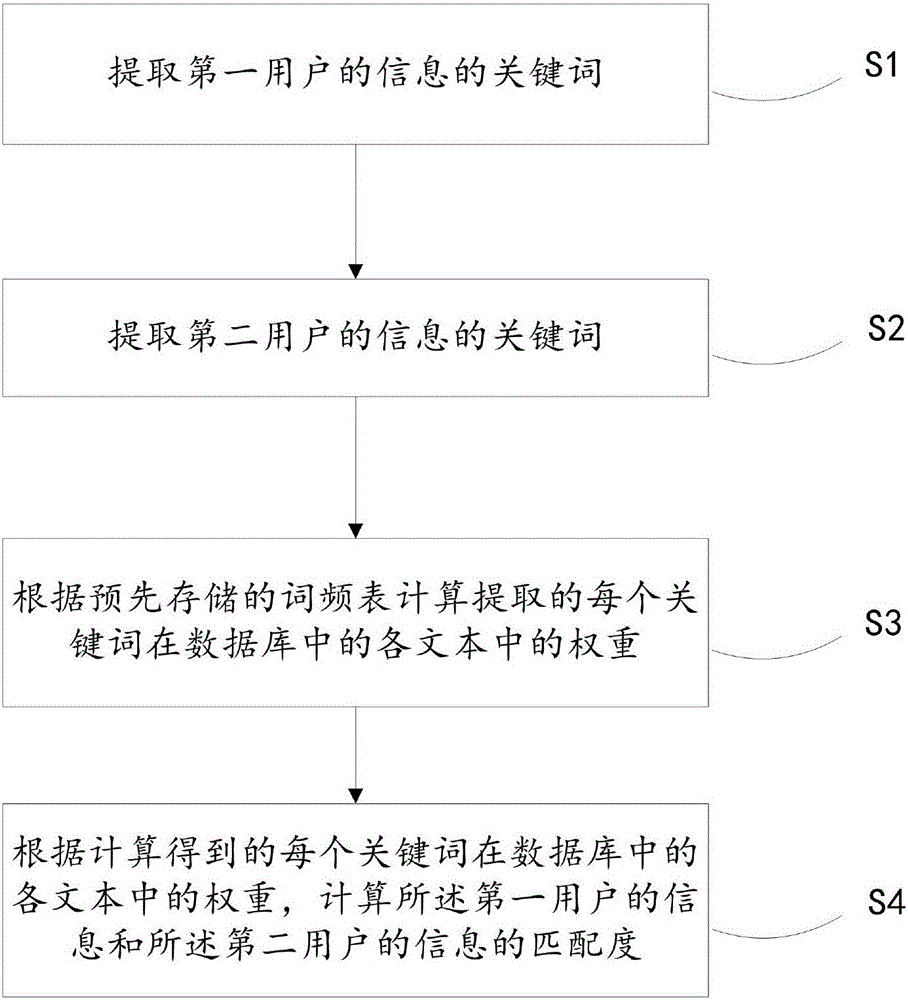
进一步地,如图2所示,文本匹配方法包括:
S1,提取第一用户的信息的关键词;
S2,提取第二用户的信息的关键词;
S3,根据预先存储的词频表计算提取的每个关键词在数据库中的各文本中的权重;所述词频表根据各个词语在数据库中的各文本中的出现频率周期性更新;
S4,根据计算得到的每个关键词在数据库中的各文本中的权重,计算所述第一用户的信息和所述第二用户的信息的匹配度。
进一步地,所述词频表根据预设的匹配规则进行设定,若所述匹配规则被改变,所述词频表也被改变。
进一步地,若第一用户(求职者)和第二用户(供职者)双方互相选择,则开启第一用户和第二用户之间的即时通信窗口。第一用户(求职者)和第二用户(供职者)之间可以进行文本对话和视频面试,还可以在所述即时通信窗口展示第二用户(供职者)出具的劳动合同以及第一用户(求职者)对合同的反馈意见,以及建议入职前的培训充电和补充其他资料等功能,从而简单高效地解决招聘求职问题。
实施例2:
一种基于文本匹配的信息处理装置,如图3所示,包括:
第一数据获取模块201,用于获取第一用户的信息并将所述第一用户的信息录入数据库,所述第一用户的信息包括第一用户的个人基本信息以及量表信息;
第二数据获取模块202,用于获取第二用户的信息并将所述第二用户的信息录入数据库,所述第二用户的信息包括第二用户的基本信息、空缺岗位信息以及空缺岗位期望匹配度;
第一匹配模块203,用于对于选定的第二用户,将每一个第一用户的信息和所述选定的第二用户的信息进行文本匹配以获取匹配度;
第一选定模块204,用于若匹配度大于所述第二用户的期望匹配度,则对应的第一用户被选定;
第一呈现模块205,用于将选定的第一用户的信息呈现给所述第二用户;
第二匹配模块206,用于对于选定的第一用户,将每一个第二用户的信息和所述选定的第一用户的信息进行文本匹配以获取匹配度;
第二选定模块207,用于若所述匹配度大于所述第二用户的期望匹配度,则所述第二用户被选定;
第二呈现模块208,用于将选定的第二用户的信息呈现给所述第一用户。
进一步地,第一匹配模块203和第二匹配模块206均包括:
关键词提取单元,用于提取第一用户的信息的关键词和第二用户的信息的关键词;
权重提取单元,用于根据预先存储的词频表计算提取的每个关键词在数据库中的各文本中的权重;所述词频表根据各个词语在数据库中的各文本中的出现频率周期性更新;
匹配度计算单元,用于根据计算得到的每个关键词在数据库中的各文本中的权重,计算所述第一用户的信息和所述第二用户的信息的匹配度。
进一步地,还包括:
排序单元209,用于按照匹配度高低对第一用户或第二用户进行排序。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!