一种采用基于局部感受野的极速学习机的室内场景识别方法与流程
本发明涉及一种采用基于局部感受野的极速学习机(LRF-ELM)来处理室内场景分类问题的方法,属于移动机器人的室内场景识别方法领域。
背景技术:
室内场景识别作为当前的研究热点,对人们的日常生活产生着深远的影响。其应用价值主要在于视频监控、智能家居、机器人的日常生产作业和危险环境的救援等。
随着现代传感器、控制和人工智能技术的发展,科研人员对基于计算机视觉和基于深度感知两大方面的场景识别方法开展了广泛的研究。浙江大学的发明专利“一种基于混合摄像机的室内场景定位方法”用混合摄像机拍摄的当前帧的深度图和彩色图以及训练好的回归森林,计算出当前摄像机对应的世界坐标,完成室内场景定位,但其效果受光线影响较大。
技术实现要素:
本发明的目的是克服传统技术的不足之处,提出一种快速有效的室内场景定位方法,在基于局部感受野的极速学习机的基础上实现基于2-D雷达信息的室内场景定位,提高了室内场景识别的效率及准确率。
本发明提出的一种利用基于局部感受野的极速学习机的室内场景定位方法,包括以下步骤:
(1)采集作为训练样本的场景的雷达信息,设训练样本的个数为N,则得到训练样本数据集Str的表达式为:
Str={Str1,Str2,…,StrN}
其中Str1,Str2,…,StrN分别表示训练样本数据集Str中第一个训练样本、第二个超声训练样本、…第N个训练样本。不同场景中,所采集的训练样本个数大致相同;
(2)对需要进行识别的测试样本场景进行雷达信息的采集。设测试样本的个数为M,则得到超声测试样本数据集Ste的表达式为:
Ste={Ste1,Ste2,…,SteM}
其中Ste1,Ste2,…,SteM分别表示测试样本数据集Ste中第一个测试样本、第二个测试样本、…第M个测试样本。不同场景中,所采集的训练样本个数大致相同。M和N分别为训练样本的个数和测试样本的个数,一般情况下M≤N;
(3)对雷达测距训练集Str的样本信息进行特征提取,具体处理过程如下:
(3-1)记训练样本集Str中的任意一个训练样本为SI,1≤I≤N,SI是一个由雷达扫描一周获得的雷达数据所构成的一维特征向量,即SI=[SI.1,SI.2,…,SI.l],其中SI.1,SI.2,…,SI.l表示一次扫描中l个采样点的雷达数据,将这组雷达数据其转化为极坐标图像;
(3-2)将极坐标图像提取到直角坐标系中,且将极坐标图像的圆心作为矩形图像的中心,对轮廓内部分进行红色填充;
(3-3)对(3-2)中得到的以白色为背景的矩形红色填充图进行二值化处理,使其成为黑白图像,获取图像数据,得到新的训练集的样本SI',完成对训练集样本的特征提取;
进而得到新的训练样本集Str':
Str'={Str1',Str2',…,Strk',…,StrN'};
其中,Str1',Str2',…,Strk',…,StrN'分别表示经求二值化图像数据后得到的测试训练集Str'中的第一个训练样本、第二个训练样本、…、第k个训练样本、…、第N个训练样本,N为训练样本数;
(3-4)给训练集Str'中来自不同类型房间的样本设定不同的标签,并组成标签矩阵T;
(4)对雷达测距测试集Ste的样本信息进行特征提取,具体处理过程如下:
(4-1)记测试样本集Ste中的任意一个训练样本为SJ,1≤J≤M,SJ是一个由雷达扫描一周获得的雷达数据所构成的一维特征向量,即SJ=[SJ.1,SJ.2,…,SJ.l],其中SJ.1,SJ.2,…,SJ.l表示一次扫描中l个采样点的雷达数据,将这组雷达数据其转化为极坐标图像;
(4-2)将极坐标图像提取到直角坐标系中,且将极坐标图像的圆心作为矩形图像的中心,对轮廓内部分进行红色填充;
(4-3)对(4-2)中得到的以白色为背景的矩形红色填充图进行二值化处理,使其成为黑白图像,获取图像数据,得到新的训练集的样本SJ',完成对训练集样本的特征提取;
进而得到新的测试样本集Ste':
Ste'={Ste1',Ste2',…,Stek',…,SteM'};
其中,Ste1',Ste2',…,Stek',…,SteM'分别表示经求二值化图像数据后得到的测试集Ste'中的第一个测试样本、第二个测试样本、…、第k个测试样本、…、第M个测试样本,M为测试样本数;
(4-4)以(3-4)中的方式给测试集Ste'中来自不同类型房间的样本设定不同的标签,并组成标签矩阵T';
(5)将训练集Str'及相应的标签矩阵T、测试集Ste'及相应的标签矩阵T'作为基于局部感受野的极速学习机的输入,并设置卷积层、池化层等相应参数;
(5-1)随机生成输入权重Wi=[wi1,,,win]T和隐层单元的偏置bi=[bi1,…bin]T,对初始权重进行正交化,得到新的输入权重设训练集样本输入大小为(d×d),感受野大小为(r×r),第k个特征图的卷积节点(i,j)的值ci,j,k由下式计算:
(5-2)对特征图进行平方根池化,池化大小e表示池化中心到边的距离,hp,q,k表示第k个池化图中的组合节点(p,q),计算如下:
(5-3)简单地连接所有组合节点的值形成一个行向量,并把N个训练集输入样例的行向量放在一起,得到组合层矩阵H,通过下式计算输出权重β:
当N>K·(d-r+1)2,
当N≤K·(d-r+1)2,
(5-4)输入权重不变,对测试集Ste'的样本进行与(5-1)及(5-2)中相同的卷积与池化过程,得到组合层H',设算法对测试集样本的标签预测为Y,计算可得:
Y=H'*β
将预测标签Y与测试集的给定标签T'进行对比,得出场景识别的正确率。
本发明提出的基于2-D雷达信息,采用基于局部感受野的极速学习机的室内场景识别方法,大大缩短了运算时间,提高了室内场景识别的效率。而且本发明方法简单可靠,具有很强的实用性。
附图说明
图1是本发明所用算法流程图。
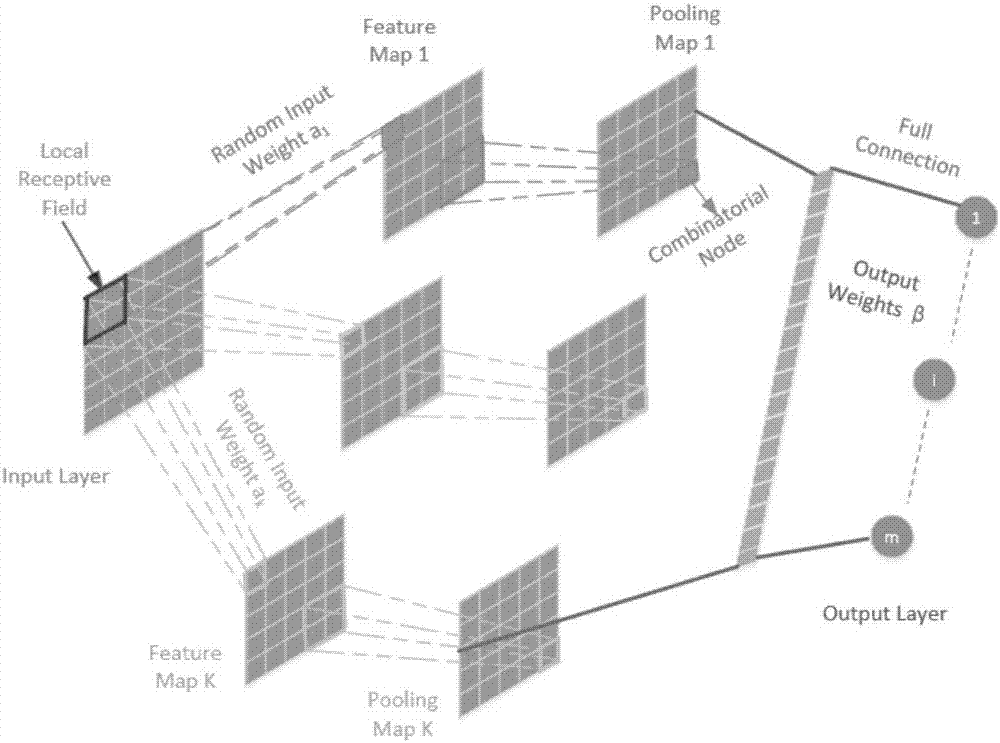
图2是本发明中所用算法基于局部感受野的极速学习机(LRF-ELM)的原理图。
图3是对训练集和测试集进行特征提取过程中,二值化图像信息提取的过程图。
具体实施方式
本发明提出的一种基于2-D雷达信息,采用基于局部感受野的极速学习机的室内场景识别方法,具体实施例进一步详细说明如下。
(1)在移动机器人上安装雷达传感器,采集作为训练样本的场景的雷达信息,设训练样本的个数为N,则得到训练样本数据集Str的表达式为:
Str={Str1,Str2,…,StrN}
其中Str1,Str2,…,StrN分别表示训练样本数据集Str中第一个训练样本、第二个超声训练样本、…第N个训练样本。不同场景中,所采集的训练样本个数大致相同。
(2)对需要进行识别的测试样本场景进行雷达信息的采集。设测试样本的个数为M,则得到超声测试样本数据集Ste的表达式为:
Ste={Ste1,Ste2,…,SteM}
其中Ste1,Ste2,…,SteM分别表示测试样本数据集Ste中第一个测试样本、第二个测试样本、…第M个测试样本。不同场景中,所采集的训练样本个数大致相同。M和N分别为训练样本的个数和测试样本的个数,一般情况下M≤N。
(3)对雷达测距样本信息进行特征提取,具体处理过程如下:
(3-1)记训练样本集Str中的任意一个训练样本为SI,1≤I≤N,SI是一个由雷达扫描一周获得的雷达数据所构成的一维特征向量,即SI=[SI.1,SI.2,…,SI.l],其中SI.1,SI.2,…,SI.l表示一次扫描中l个采样点的雷达数据,将这组雷达数据其转化为极坐标图像;
(3-2)将极坐标图像提取到直角坐标系中,且将极坐标图像的圆心作为矩形图像的中心,对轮廓内部分进行红色填充;
(3-3)对(3-2)中得到的以白色为背景的矩形红色填充图进行二值化处理,使其成为黑白图像,获取图像数据,得到新的训练集的样本SI',完成对训练集样本的特征提取。
进而得到新的训练样本集Str':
Str'={Str1',Str2',…,Strk',…,StrN'}
其中,Str1',Str2',…,Strk',…,StrN'分别表示经求二值化图像数据后得到的测试训练集Str'中的第一个训练样本、第二个训练样本、…、第k个训练样本、…、第N个训练样本,N为训练样本数;
(3-4)给训练集Str'中来自不同类型房间的样本设定不同的标签,如走廊是1,浴室是2,卧室是3等,并组成标签矩阵T。
(4-1)记测试样本集Ste中的任意一个训练样本为SJ,1≤J≤M,SJ是一个由雷达扫描一周获得的雷达数据所构成的一维特征向量,即SJ=[SJ.1,SJ.2,…,SJ.l],其中SJ.1,SJ.2,…,SJ.l表示一次扫描中l个采样点的雷达数据,将这组雷达数据其转化为极坐标图像;
(4-2)将极坐标图像提取到直角坐标系中,且将极坐标图像的圆心作为矩形图像的中心,对轮廓内部分进行红色填充;
(4-3)对(4-2)中得到的以白色为背景的矩形红色填充图进行二值化处理,使其成为黑白图像,获取图像数据,得到新的训练集的样本SJ',完成对训练集样本的特征提取。
进而得到新的测试样本集Ste':
Ste'={Ste1',Ste2',…,Stek',…,SteM'}
其中,Ste1',Ste2',…,Stek',…,SteM'分别表示经求二值化图像数据后得到的测试集Ste'中的第一个测试样本、第二个测试样本、…、第k个测试样本、…、第M个测试样本,M为测试样本数;
(4-4)以(3-4)中的方式给测试集Ste'中来自不同类型房间的样本设定不同的标签,并组成标签矩阵T'。
(5)将训练集Str'及相应的标签矩阵T、测试集Ste'及相应的标签矩阵T'作为基于局部感受野的极速学习机的输入,并设置卷积层、池化层等相应参数。
(5-1)随机生成输入权重Wi=[wi1,,,win]T和隐层单元的偏置bi=[bi1,…bin]T,对初始权重进行正交化,得到新的输入权重设训练集样本输入大小为(d×d),感受野大小为(r×r),第k个特征图的卷积节点(i,j)的值ci,j,k由下式计算:
(5-2)对特征图进行平方根池化,池化大小e表示池化中心到边的距离,hp,q,k表示第k个池化图中的组合节点(p,q),计算如下:
(5-3)简单地连接所有组合节点的值形成一个行向量,并把N个训练集输入样例的行向量放在一起,得到组合层矩阵H,通过下式计算输出权重β:
当N>K·(d-r+1)2,
当N≤K·(d-r+1)2,
(5-4)输入权重不变,对测试集Ste'的样本进行与(5-1)及(5-2)中相同的卷积与池化过程,得到组合层H',设算法对测试集样本的标签预测为Y,计算可得:
Y=H'*β
最后,将预测标签Y与测试集的给定标签T'进行对比,得出本次场景识别的正确率。
- 还没有人留言评论。精彩留言会获得点赞!