基于优化簇相关矩阵的聚类融合方法与流程
本发明属于数据挖掘领域,具体涉及的是一种利用聚类成员内外簇之间的关系和簇的稳定度对二进制簇相关矩阵进行优化的聚类融合方法。
背景技术:
近几十年来,随着信息时代科技的快速发展,数据存储技术和数据采集技术也得到了飞速地进步。由此使得各类数据海量积累,出现了“信息爆炸而知识匮乏”的现象。如何从海量数据中提取出有用的知识目前面临着巨大的挑战。对于数据挖掘一词,目前还没有一个完整的定义,我们推崇的定义是韩家炜(韩家炜,坎伯.数据挖掘概念与技术(原书第2版)(计算机科学丛书)[m].机械工业出版社,2008.)给出的数据挖掘概念:“数据挖掘是从存放在数据库、数据仓库或其他信息库中的大量数据中发现有趣知识的过程”。
聚类分析是数据挖掘领域的一个重要分支,能够发现数据内在的分布情况。所谓聚类分析就是将数据对象分组成为多个类或簇,使得在同一簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大(朱国红.基于特征点选择的聚类算法研究与应用[d].山东大学,2010.)。事实上,任何一个单一的聚类算法都不能达到普遍适用的效果。为了提高聚类性能,聚类融合技术的提出较大地改变了这种现状。它是为了解决无监督的聚类分析中可能因为样本的特殊数据分布与聚类假设不匹配,导致聚类结果不理想的问题。聚类融合的基本思想是:将多个对一组对象进行聚类成员的不同结果进行合并,而不使用对象原有的特征(阳琳贇,王文渊.聚类融合方法综述[j].计算机应用研究,2005,22(12):8-10.)。
聚类融合在对不同的聚类成员进行合并之前需要创建关系矩阵。基于矩阵的方法的基本思想是把每一次聚类的结果看成是数据重新组织的新模式,在这个基础之上,数据对象之间的近似度可以由新的特征模式之间的近似度代替(朱萌.基于模糊矩阵的聚类融合[d].南京理工大学,2008.)。矩阵是依附于共识函数存在的,不同的共识函数需要创建不同的矩阵。二进制簇相关矩阵是目前关于矩阵的最好表现形式之一,其空间复杂度为o(n×h)(h是聚类成员中簇的数量之和)明显低于相似性矩阵的o(n2)。但是一般的二进制簇相关矩阵是稀疏且离散的,非0即1,明显影响聚类融合的准确性。
技术实现要素:
本发明所要解决的技术问题是基于优化簇相关矩阵的聚类融合方法。通过综合考虑聚类成员内簇与簇的关系、聚类成员外簇与簇的关系、簇的稳定度等因素,将数据出现在簇的概率转换成簇与簇之间的关系,加入簇的稳定度因子,构造优化簇相关矩阵。对优化簇相关矩阵应用多路谱聚类算法(李新叶,余晓晔.适用于复杂结构的多路谱聚类算法的改进[j].北京工业大学学报,2013,39(3):425-429.)进行聚类得到最终聚类结果。本发明能够有效利用聚类成员的特征,提高聚类融合的准确度和精度。
本发明的技术方案如下:
基于优化簇相关矩阵的聚类融合方法,包括以下步骤:
步骤1),用k-means算法对有n个d维特征数据的集合xnd进行m次聚类,最终得到m个有差异的聚类成员;
步骤2),考虑步骤1)得到的m个聚类成员,计算聚类成员间簇与簇的关系rter和聚类成员内簇与簇的关系rtra,创建簇相关矩阵ca,计算簇的稳定度s。
步骤3),根据步骤2)得到的簇相关矩阵ca和簇的稳定度s,考虑数据xt落在簇cmi的概率,根据公式ra(xt,cmi)=ca(xt,cmi)×s(cmi)构造优化簇相关矩阵ra。
步骤4),根据步骤3)得到的优化簇相关矩阵ra,对ra应用多路谱聚类算法:根据优化簇相关矩阵ra,求出对角矩阵d、拉普拉斯矩阵l、l的特征值和与其相对应的特征向量;使用前t个最大特征值对应的特征向量构造新的数据集合unt,并建立与原始数据集合的对应关系;然后用k-means对unt进行聚类。
进一步的,本发明的基于优化簇相关矩阵的聚类融合方法,步骤1)用k-means算法每次选取不同的初始聚类中心或设置不同的k值参数,对有n个d维特征数据的集合xnd进行m次聚类,最终得到聚类成员集合π={π1,π2,…πm}。
进一步的,本发明的基于优化簇相关矩阵的聚类融合方法,步骤2)根据步骤1)得到的聚类成员集合,计算聚类成员间簇与簇的关系
进一步的,本发明的基于优化簇相关矩阵的聚类融合方法,步骤3)根据步骤2)得到的簇相关矩阵ca和簇的稳定度s,考虑数据xt落在簇cmi的概率(即数据xt所在簇cmj与簇cmi的关系rtra(cmi,cmj)以及簇cmi的稳定度),根据公式ra(xt,cmi)=ca(xt,cmi)×s(cmi)构造优化簇相关矩阵ra。
进一步的,本发明的基于优化簇相关矩阵的聚类融合方法,步骤4)对根据步骤3)得到的优化矩阵ra应用多路谱聚类算法:根据步骤3)得到的优化矩阵ra建立对角矩阵d(d对角线上的值di=∑jra(i,j)(i≠j))和拉普拉斯矩阵l=d-1/2rad-1/2;求出拉普拉斯矩阵l的特征值和与其相对应的特征向量;使用前t个最大特征值对应的特征向量构造新的数据集合unt,即看作原始数据集合x的t维特征,建立该数据集合与原始数据集合的对应关系;最后用k-means对进行数据集合unt聚类得到最终的聚类结果。
有益效果
本发明针对一般二进制簇相关矩阵的优化能够消除原始矩阵的离散性和稀疏性,同时提高聚类融合的准确和精度。该方法基于聚类成员内簇与簇关系和聚类成员间簇与簇的关系,用数据所在簇与其它簇的关系代表数据出现在其它簇的概率,同时引入了簇的稳定度,对一般二进制簇相关矩阵进行优化,在很大程度上利用了聚类成员的特征。该方法相较于原来的聚类融合,提高了聚类的精准度。
附图说明
图1是基于优化簇相关矩阵的聚类融合方法的流程图;
图2是基于优化簇相关矩阵的聚类融合方法中多路谱聚类算法的流程图。
具体实施方式
下面结合附图对技术方案的实施作进一步的详细描述:
结合流程图及实施案例对本发明所述的基于优化簇相关矩阵的聚类融合方法作进一步的详细描述。
本实施案例通过对一般二进制簇相关矩阵进行优化的方法对聚类融合算法进行改进,进而提高算法的精确度。如图1所示,本方法包含如下步骤:
步骤10,用k-means算法每次选取不同的初始聚类中心或设置不同的k值参数,对有n个d维特征数据的集合xnd进行m次聚类,最终得到聚类成员集合π={π1,π2,…πm}。
步骤20,根据步骤10得到的聚类成员集合,计算聚类成员间簇与簇的关系
步骤30,根据步骤20得到的簇相关矩阵ca和簇的稳定度s,考虑数据xt落在簇cmi的概率(即数据xt所在簇cmj与簇cmi的关系rtra(cmi,cmj)以及簇cmi的稳定度),根据公式ra(xt,cmi)=ca(xt,cmi)×s(cmi)构造优化簇相关矩阵ra。
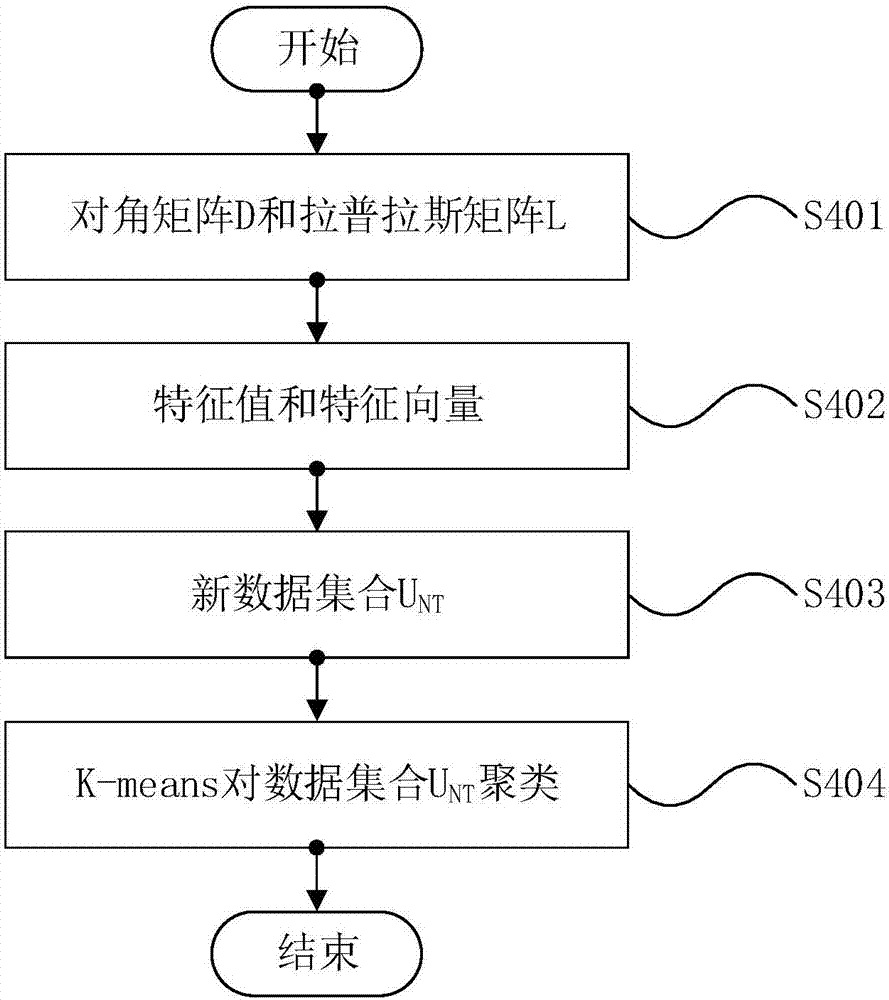
步骤40,根据步骤30得到的优化簇相关矩阵ra,对矩阵ra应用多路谱聚类算法。如图2所示,多路谱聚类算法包含以下步骤:
步骤401,根据步骤30得到的优化簇相关矩阵ra,计算其对角矩阵d,该对角矩阵对角线的值为
步骤402,根据步骤401得到的拉普拉斯矩阵l,求该拉普拉斯矩阵的特征值和对应的特征向量。
步骤403,根据步骤402得到的特征值和特征向量,选择前t个最大的特征值,将其对应的特征向量看成一列构成新的数据集合unt。
步骤404,根据步骤403得到的数据矩阵unt,将矩阵的每行看作一条数据,用k-means对其聚类得到聚类结果,将结果对应到原始的数据集合xnd得到最终聚类结果。
以上所述的具体实施方案,对本发明的目的、技术方案和有益效果进行了进一步的详细说明,所应理解的是,以上所述仅为本发明的具体实施方案而已,并非用以限定本发明的范围,任何本领域的技术人员,在不脱离本发明的构思和原则的前提下所做出的等同变化与修改,均应属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!