基于卷积神经网络和随机森林的手写数字识别方法与流程
本发明涉及模式识别和机器学习领域,具体涉及一种结合卷积神经网络和随机森林的手写数字识别方法。
背景技术:
手写数字识别包含在字符识别技术中,是模式识别的一种。处理一些数据信息的关键技术就是手写数字识别,比如财务报表、邮政编码、各种票据等等。手写数字识别的改进和研究不仅具有重大的现实意义和应用价值,还有着极其关键的理论价值。
卷积神经网络(convolutionalneuralnetwork,cnn)是深度学习算法的一种,广泛应用在图像识别领域。cnn通过一层一层的学习,可以自动从输入图像中提取特征,在面对不同的图像识别任务时都有很好的效果,被认为是通用图像识别系统的代表之一。但是cnn在训练的过程中需要采用bp算法来调整参数,这个过程会消耗大量时间。随机权值的网络在近几年的研究中被证明同样可以取得很好的效果。
随机森林(randomforests,rf)是leobreiman在2001年发表的论文中提出的一种新的机器学习算法,在分类和回归上具有很高的精度,训练速度快并且不容易出现过拟合的问题,在抗噪方面也表现良好,现有的基于随机森林的分类器都依赖手工选取的特征,然而手工选取是非常费力而且需要专业知识的方法,能否选好很大程度上取决于经验和运气。
技术实现要素:
基于以上问题,本发明提出一种基于卷积神经网络和随机森林的手写数字识别方法,用随机权值的cnn提取数字图像的特征,然后交给rf完成分类。这样使得模型在提取特征的过程中大大减少了时间,既克服了cnn训练时间过长的问题,又解决了在rf在人工选取特征的缺陷。
本发明的技术方案如下:一种基于卷积神经网络和随机森林的手写体数字识别方法,具体步骤如下:
步骤1,采集手写数字图像生成训练集和测试集;
步骤2,构造并初始化卷积神经网络:该网络包括:输入层、两个卷积层、两个降采样层和一个全连接层,其中:输入层的数据是手写数字图像,是28*28像素点构成的矩阵,卷积层c1有10个特征图,降采样层s2同样有10个特征图,卷积层c3则有20个特征图,s4层对c3层特征图基础上进行降采样得到20张特征图,此时得到特征数据;
步骤3,训练随机森林分类器,随机森林是一种统计学习理论,它利用bootstrap重抽样方法从原始样本中抽取多个样本,然后对每个bootstrap样本进行决策树建模,然后组成多棵决策树进行预测,最终投票得出预测结果。具体过程如下:
步骤3.1:从样本集中用bootstrap采样选出n个样本;
步骤3.2:从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立cart决策树;
步骤3.3:重复以上两步m次,即建立了m棵cart决策树,这m棵cart决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
步骤4:手写数字的识别,从卷积神经网络中得到特征数据之后,将特征数据输入到训练好的随机森林分类器中从而得到手写数字识别结果。
通过以上内容可知,本申请提供的是一种基于卷积神经网络和随机森林的手写体数字识别方法,首先手写数字图像的数据集,分为训练集和测试集,然后设计网络的层数、特征图的数目和卷积核的大小等等,之后用随机化权值的卷积神经网络提取数字图像的特征,最后输入到随机森林分类器中完成分类。本申请通过卷积神经网络提取手写数字图像的特征,避免了显示的特征提取,直接将图片作为网络的输入;避免了深度学习训练时间长的缺点,训练时间短;同时识别精度也比较高。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种手写体数字识别方法的流程图。
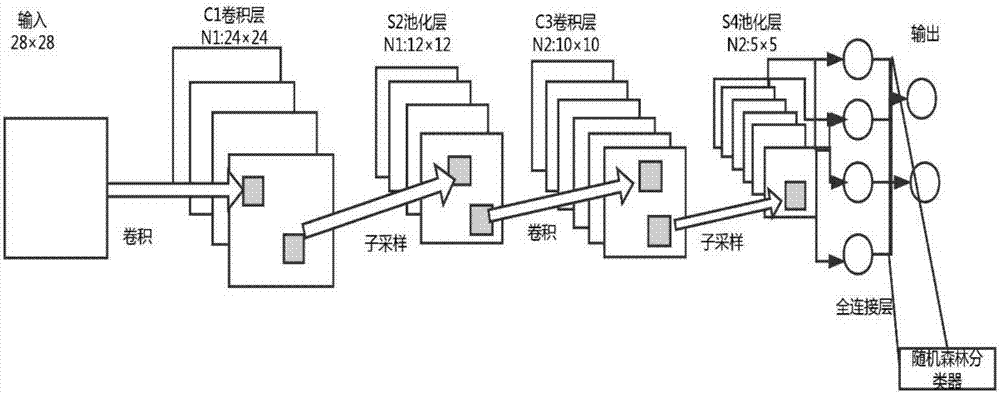
图2为本申请所使用的卷积神经网络结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
实施例1
如图1所示,本实施例包括以下步骤:
步骤1,采集手写数字图像生成训练集和测试集;
步骤2,构建卷积神经网络:
本实施例中采用的卷积神经网络是深度学习广泛应用的一个模型,尤其在图片领域非常高效,它是一个多层的神经网络,可以完成特征的自动提取和分类。输入层的图像通过若干个可训练的卷积核和偏置进行卷及特征提取之后会在c1得到相应的特征图,然后经过池化之后,加上权值和偏置之后输入到sigmoid函数再次得到特征图,c3层和s4层特征图的提取与c1层和s2层类似,最终这些特征图连接为一个向量输入到传统的神经网络中,得到输出进而完成分类。
步骤2.1:构造如图2所示的多层神经网络,包括输入层,两个卷积层,两个降采样层和一个全连接层,c层为卷积层,c层中的神经元通过局部感受野(一个卷积核,比如5*5大小)与上层相连接,并通过卷积计算提取该局部的特征,使用单调递增的sigmoid函数作为激活函数;s层为降采样层,用池化的方法进行二次特征提取。这种c层和s层交替出现的结构使网络对输入样本有较高的畸变容忍能力;
步骤2.2:卷积神经网络的输入为28*28的灰度图,卷积层c1卷积核大小为5*5,有10张特征图,降采样层s2有10张特征图,卷积层c3由s2的10张特征图经卷积而后得到20张特征图,因为特征图的数量较少,为了得到更全面的特征,组合方式采用全连接的方式,降采样层s4有20张特征图,全连接层将s4的20张特征图排列,设置500个节点;
步骤2.3:随机初始化卷积神经网络的权值,将样本(x,y)输入到网络中,其中x是样本的数据,y是标签,经过逐层计算得到样本的特征。
步骤3,训练随机森林分类器,随机森林算法是由leobreiman提出,其实质是一个包含k个决策树的分类器,这些决策树的形成采用了随机的方法,因此也叫随机决策树,树与树之间是没有关联的。它采用bootstrap重抽样方法从原始样本中抽取n个样本;对每个样本从所有属性中选择k个属性,选择最佳属性作为节点建立cart决策树;重复m次建立m棵cart决策树,这m棵cart形成随机森林,通过投票得到最终投票结果。
步骤3.1:从样本集中用bootstrap采样选出n个样本;
步骤3.2:从所有属性中随机选择k个属性,选择最佳分裂属性作为节点建立cart决策树,其中最佳分裂指数是根据gini指数来选择的:假设集合t中包含n个类别的记录,其中gini指数就是根据式
对于所有的属性都要遍历所有可能的分裂方式,然后选择具有最小指数的分裂作为分裂标准。然后每棵树任意生长,不进行剪枝。
步骤3.3:重复以上两步m次,即建立了m棵cart决策树,这m棵cart决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
步骤4,手写数字识别:将卷积神经网络提取得到的测试特征数据输入训练好的随机森林分类器,最终得到测试结果。
- 还没有人留言评论。精彩留言会获得点赞!