一种基于KNL平台的代数系统求解方法及系统与流程
本发明涉及高性能计算领域,特别涉及一种基于KNL平台的代数系统求解方法及系统。
背景技术:
随着科技的进步,线性方程组的求解问题在20世纪中叶随着计算机的发展大型线性方程租的求解才成为可能。求解线性方程组的数值方法大体上可分为直接法和迭代法两种。迭代法适合求解规模较大的稀疏线性方程组,采取逐次逼近的方法,按照一定的计算格式,构造一个向量的无穷序列,其极限才是线性方程组的精确解,有限次计算得到的是近似解。但是无论哪种迭代方式基本上由矩阵向量乘、向量相加(减)、数乘以向量以及向量内积等四种运算构成。
KNL(Knights Landing)是英特尔公司推出的第二代至强融核芯片,用于高性能并行计算的众核处理器。KNL芯片可以单独做中央主处理器,其采用了Silvermont架构的改进定制版和14nm新工艺,核心数量多达64-72个,每个核心最多可开启4个线程,最多拥有288个线程,双精度浮点性能超过3TFlops,单精度则超过6TFlops。
现有技术中,有限差分、有限元、边界元、无网格方法等一系列的数值计算方法相继诞生。这些数值计算方法具有一个相同之处:将实际问题导出的数学物理模型通过特定的方式离散成一个线性代数方程组。不同领域的问题或运用不同数值方法求解的问题得到矩阵的形态或特性往往是不相同的,针对不同形态或特性的矩阵选取不同的求解方法,因此,这些数学物理问题总会转化成一个线性代数系统的求解问题。然而,随着问题规模的增大,现有硬件设备和方法,在面对复杂的线性方程组求解问题时,需要耗费大量时间,难以进一步提高计算速度,因此,线性方程组的求解成为工程生产和科研中的一大瓶颈。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于KNL平台的代数系统求解方法及系统,以提高对线性方程组的计算速度。其具体方案如下:
一种基于KNL平台的代数系统求解方法,包括:
主进程读取线性方程组,按照预设的划分方法,将所述线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,其中,L为正整数;
所述主进程将L组计算矩阵分配到N个从进程中,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数;
所述主进程接收每个从进程计算出的最终结果;
其中,每个从进程对接收到的计算矩阵进行任一次迭代计算的过程,包括:从进程对接收到的计算矩阵进行计算,得到第一计算结果,并将所述第一计算结果反馈给所述主进程,所述主进程接收所述从进程的第一计算结果,并将所述从进程的第一计算结果发送给其他从进程。
优选的,所述按照预设的划分方法,所述将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块的过程,包括:
将所述线性方程组的系数矩阵和常数矩阵,分别按行划分成L块,每块系数矩阵与每块常数矩阵相互一一对应。
优选的,所述从进程对接收到的计算矩阵进行计算的过程,包括:
所述从进程利用矩阵向量乘函数、向量数乘函数、向量内积函数和向量相加函数对接收到的所述计算矩阵进行计算。
优选的,各进程间通信方式为集合通信。
优选的,还包括:所述主进程将L组计算矩阵分配到N个从进程和主进程中。
优选的,所述所述主进程将L组计算矩阵分配到N个从进程中的过程,包括:
所述主进程将L组计算矩阵平均分配到N个从进程中。
一种基于KNL平台的代数系统求解系统,包括:
划分模块,用于主进程读取线性方程组,按照预设的划分方法,将所述线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,其中,L为正整数;
分配模块,用于所述主进程将L组计算矩阵分配到N个从进程中;
计算模块,用于每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数;
收集模块,用于所述主进程接收每个从进程计算出的最终结果;
其中,所述计算模块中对每个从进程对接收到的计算矩阵进行任一次迭代计算的过程,包括:从进程对接收到的计算矩阵进行计算,得到第一计算结果,并将所述第一计算结果反馈给所述主进程,所述主进程接收所述从进程的第一计算结果,并将所述从进程的第一计算结果发送给其他从进程。
优选的,所述划分模块,具体用于将所述线性方程组的系数矩阵和常数矩阵,分别按行划分成L块,每块系数矩阵与每块常数矩阵相互一一对应。
优选的,所述计算模块,包括:
计算单元,用于所述从进程利用矩阵向量乘函数、向量数乘函数、向量内积函数和向量相加函数对接收到的所述计算矩阵进行计算。
优选的,所述分配模块,具体用于所述主进程将L组计算矩阵平均分配到N个从进程中。
本发明中,基于KNL平台的代数系统求解方法,包括:主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,其中,L为正整数;主进程将L组计算矩阵分配到N个从进程中,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数;主进程接收每个从进程计算出的最终结果;其中,每个从进程对接收到的计算矩阵进行任一次迭代计算的过程,包括:从进程对接收到的计算矩阵进行计算,得到第一计算结果,并将第一计算结果反馈给主进程,主进程接收从进程的第一计算结果,并将从进程的第一计算结果发送给其他从进程。可见,本发明基于KNL平台通过主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,并将L组计算矩阵分配到N个从进程中,保障了多进程并行运算,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果,利用多进程运算优势,将线性方程组分块并行计算,提高了计算速度,实现了对线性方程组的快速运算。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种基于KNL平台的代数系统求解方法流程示意图;
图2为本发明实施例提供的另一种基于KNL平台的代数系统求解方法流程示意图;
图3为本发明实施例提供的一种基于KNL平台的代数系统求解系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于KNL平台的代数系统求解方法,参见图1所示,该方法包括:
步骤S11:主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,其中,L为正整数。
具体,KNL平台接收到需要计算的线性方程组,KNL平台中的主进程读取线性方程组的信息,例如,系数矩阵和常数矩阵的行列数,矩阵中的每个数值等信息,按照用户预先设定的划分方法,将线性方程组的系数矩阵和常数矩阵划分为多块,且系数矩阵块与常数矩阵块一一对应,得到L组计算矩阵,可以理解的是,一组计算矩阵中包括一对系数矩阵块与常数矩阵块。
其中,用户预先设定的划分方法可以包括按行划分、按列划分或按块划分,依据相应的划分方法,建立起系数矩阵块与常数矩阵块的对应关系,例如,按行划分时,系数矩阵的第一行与常数矩阵第一行对应,作为第一组计算矩阵;按块划分时,系数矩阵的第一块与常数矩阵第一块对应,作为第一组计算矩阵。
需要说明的是,主进程的选择可以默认为KNL平台中的第一个进程,也可以由用户进行指定。
步骤S12:主进程将L组计算矩阵分配到N个从进程中,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数。
具体的,主进程将L组计算矩阵分配到N个从进程中,可以理解的是,当计算矩阵较少时,可以开启等同于计算矩阵数量的从进程,由于从进程开启数量可调,同时为避免系统资源的浪费,因此不会出现从进程数量大于计算矩阵数量的情况,但由于对线性方程组划分方法不同或线性方程组规模过大,而进程总数受限于硬件条件,因此,有可能出现计算矩阵数量大于从进程数量的情况。
其中,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果,由于,系数矩阵和常数矩阵分为了L组计算矩阵,每个进程一次运算只能得到一个当前计算矩阵中系数矩阵和常数矩阵相应的解,即局部解,而无法得到全局解,因此,每个进程需要对接收到的计算矩阵进行多次迭代计算,从而得到最终结果;每个从进程对接收到的计算矩阵进行任一次迭代计算的过程,包括:从进程对接收到的计算矩阵进行计算,得到第一计算结果,并将第一计算结果反馈给主进程,主进程接收从进程的第一计算结果,并将从进程的第一计算结果发送给其他从进程,即,将每个从进程的第一计算结果共享到所有从进程中;从进程间共享第一计算结果后,将利用第一计算结果和计算矩阵再次计算,得到新的计算结果,并重新作为第一计算结果,进行共享,直到计算出所有的解,得到最终结果。
步骤S13:主进程接收每个从进程计算出的最终结果。
可见,本发明实施例基于KNL平台通过主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,并将L组计算矩阵分配到N个从进程中,保障了多进程并行运算,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果,利用多进程运算优势,将线性方程组分块并行计算,提高了计算速度,实现了对线性方程组的快速运算。
本发明实施例公开了一种具体的基于KNL平台的代数系统求解方法,相对于上一实施例,本实施例对技术方案作了进一步的说明和优化。参见图2所示,具体的:
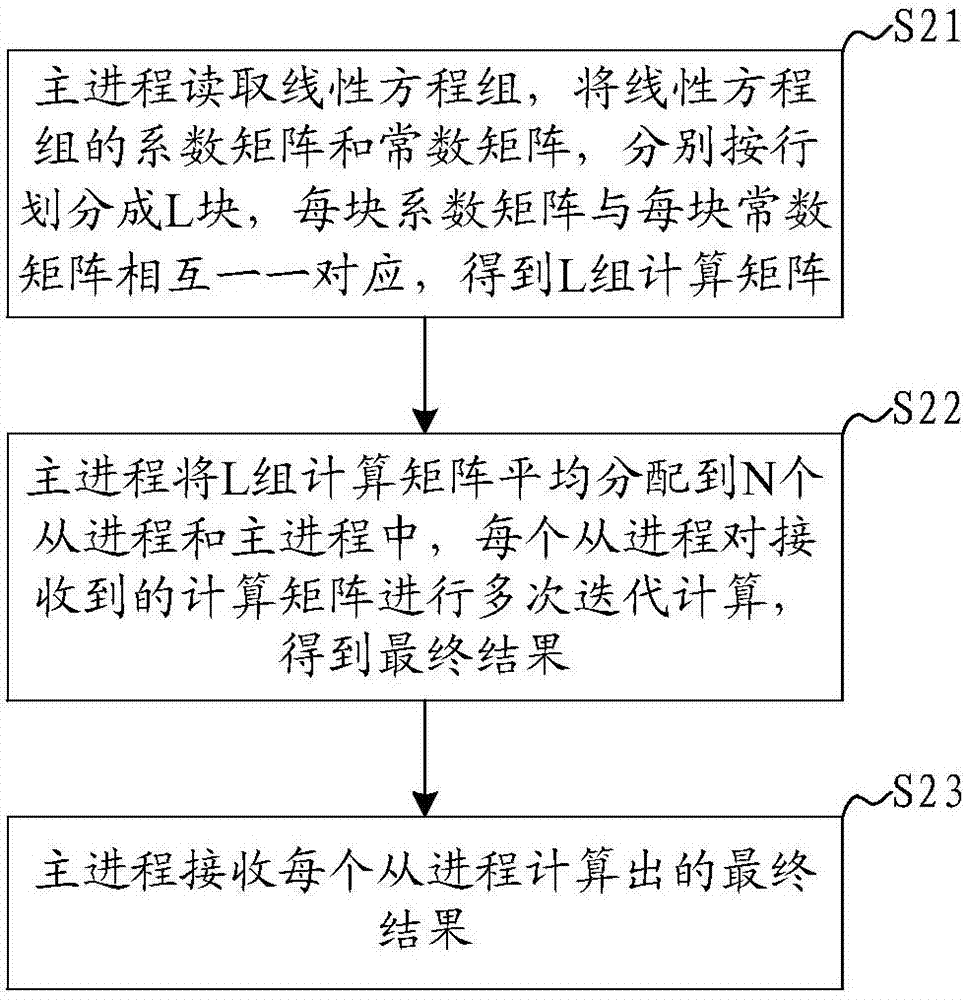
步骤S21:主进程读取线性方程组,将线性方程组的系数矩阵和常数矩阵,分别按行划分成L块,每块系数矩阵与每块常数矩阵相互一一对应,得到L组计算矩阵,其中,L为正整数。
具体的,参见图3所示,将线性方程组的系数矩阵和常数矩阵,分别按行划分成L块,每块系数矩阵与每块常数矩阵相互一一对应,得到L组计算矩阵,例如,线性方程组中系数矩阵和常数矩阵分别为10行的矩阵,将系数矩阵和常数矩阵的第一行至第三行划分为一块,第四行和第五行划分为一块,第六行和第七行分别为两块,第八行至第十行为一块,将系数矩阵和常数矩阵共分为互相对应的5块。
进一步的,线性方程组表达式可以为:Ax=b;
式中,A为系数矩阵,x为解向量矩阵,b为常数矩阵。
例如,开启L个进程P0,P1,…,PL-1,可将系数矩阵A与常数矩阵b按行划分成L块,即A=[A0T,A1T,…,AL-1T]T,b=[b0T,b1T,…,bL-1T]T,式中T表示矩阵。将数据块A0~AL-1及b0~bL-1分别分配给进程P0~PL-1,而矢量x为所有进程共享。因此,每个进程只计算x中的n/L个元素。
需要说明的是,划分线性方程组后,计数矩阵数量可以小于等于KNL的硬件线程数,以避免出现具有竞争关系的进程,以进一步的提高运算速度,例如,硬件线程最多为288,则划分的计数矩阵数量应小于等于288组,如288组。
步骤S22:主进程将L组计算矩阵平均分配到N个从进程和主进程中,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数;
可以理解的是,由于主进程与从进程都是KNL平台中的进程,二者本质上没有区别,同时,为了充分发挥多进程优势和利用系统资源,可以将L组计算矩阵平均分配到N个从进程和主进程中,主进程也可以参加后续计算,同时,也负责对计算结果的收集和分配。
进一步的,从进程可以利用矩阵向量乘函数、向量数乘函数、向量内积函数和向量相加函数对接收到的计算矩阵进行计算,可以通过调用子函数的方式完成以上四种矩阵向量计算,利用“#pragma omp”引语的方式完成内核加速设计。
步骤S23:主进程接收每个从进程计算出的最终结果。
可以理解的是,各进程间通信方式可以为集合通信,通过调用MPI的消息传递库函数实现,包括:MPI_Reduce,MPI_ALLReduce,MPI_Bcast以及MPI_Allgatherv。
进一步的,为了提高计算速度,可以将迭代计算过程中的中间变量,例如,解向量矩阵,保存到MCDRAM高带宽内存中;同时,还可以使KNL平台中包括多个KNL芯片,同时并行的计算线性方程组,进一步的提高计算速度。
相应的,本发明实施例还公开了一种基于KNL平台的代数系统求解系统,参见图3所示,该系统包括:
划分模块11,用于主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,其中,L为正整数;
分配模块12,用于主进程将L组计算矩阵分配到N个从进程中;
计算模块13,用于每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果;其中,N为小于等于L的正整数;
收集模块14,用于主进程接收每个从进程计算出的最终结果;
其中,计算模块13中对每个从进程对接收到的计算矩阵进行任一次迭代计算的过程,包括:从进程对接收到的计算矩阵进行计算,得到第一计算结果,并将第一计算结果反馈给主进程,主进程接收从进程的第一计算结果,并将从进程的第一计算结果发送给其他从进程。
可见,本发明实施例基于KNL平台通过主进程读取线性方程组,按照预设的划分方法,将线性方程组的系数矩阵和常数矩阵分别划分为相互一一对应的L块,得到L组计算矩阵,并将L组计算矩阵分配到N个从进程中,保障了多进程并行运算,每个从进程对接收到的计算矩阵进行多次迭代计算,得到最终结果,利用多进程运算优势,将线性方程组分块并行计算,提高了计算速度,实现了对线性方程组的快速运算。
进一步的,上述划分模块11,具体用于将线性方程组的系数矩阵和常数矩阵,分别按行划分成L块,每块系数矩阵与每块常数矩阵相互一一对应。
上述计算模块13,包括计算单元;其中,
计算单元,用于从进程利用矩阵向量乘函数、向量数乘函数、向量内积函数和向量相加函数对接收到的计算矩阵进行计算。
上述分配模块12,具体用于主进程将L组计算矩阵平均分配到N个从进程中。
本发明实施例中,上述分配模块12还可以包括分配单元;其中,
分配单元,用于主进程将L组计算矩阵分配到N个从进程和主进程中。
需要说明的是,本发明实施例中,各进程间通信方式可以为集合通信。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上对本发明所提供的一种基于KNL平台的代数系统求解方法及系统进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!