数据更新的方法及装置与流程
本发明涉及信息处理技术领域,尤其涉及一种数据更新的方法及装置。
背景技术:
近年来,随着信息处理技术的发展,大数据被越来越多的应用到了导航系统或城市规划等各个领域。
目前的大数据架构通常是以数据流为导向来进行数据处理的,即,首先从数据源获取数据并将获取到的数据进行存储,然后对数据进行预处理,再根据预处理后的数据进行数据建模、数据分析与数据挖掘,最后实现数据变现。由此可见,数据预处理是大数据结构中整个数据处理过程的基础,其质量与精准度可能会直接影响到后续环节中数据维度建模的指标定义、数据挖掘算法的选择或数据的准确性度量等,是数据处理过程的重要环节之一。
数据预处理的过程中通常会涉及到对数据中的缺失值进行处理,现有技术中,在对数据进行处理时一般会采用人工填写、删除含缺失值的记录数据(即删除法)、使用特殊字符(如null)填充、或者使用统计学上的均值或众数进行缺失值的填补等方法对数据中的缺失值进行处理。但是,当数据量较多或达到一定级别时,人工填写需耗费较多的时间与精力,无法满足数据流实时快速传输与处理的需求;删除含缺失值的记录数据、使用统一的特殊字符或者使用统计学上的均值或众数进行缺失值填充不具有针对性,会导致数据准精确性和有效性降低,由此可见,现有技术无法同时满足缺失值处理的高效率和高精度的要求。
技术实现要素:
有鉴于此,本发明实施例提供一种数据更新的方法及装置,以解决现有技术中的数据处理方法无法同时满足缺失值处理的高效率和高精度的要求的技术问题。
第一方面,本发明实施例提供了一种数据更新的方法,包括:
获取数据样本中缺失属性和非缺失属性的第一出现率信息,所述数据样本包括包含缺失值的第一数据样本和未包含缺失值的第二数据样本,所述缺失属性为所述第一数据样本中缺失值对应的属性;
根据所述第一出现率信息计算所述缺失属性对应的各属性值的第二出现率信息,所述第二出现率信息为缺失属性对应的各属性值在所述第一数据样本中出现的出现率信息;
根据所述第二出现率信息确定与所述第一数据样本对应的填充值,并根据所述填充值更新所述第一数据样本。
第二方面,本发明实施例还提供了一种数据更新的装置,包括:
第一出现率信息获取模块,用于获取数据样本中缺失属性和非缺失属性的第一出现率信息,所述数据样本包括包含缺失值的第一数据样本和未包含缺失值的第二数据样本,所述缺失属性为所述第一数据样本中缺失值对应的属性;
第二出现率信息计算模块,用于根据所述第一出现率信息计算所述缺失属性对应的各属性值的第二出现率信息,所述第二出现率信息为缺失属性对应的各属性值在所述第一数据样本中出现的出现率信息;
数据样本更新模块,用于根据所述第二出现率信息确定与所述第一数据样本对应的填充值,并根据所述填充值更新所述第一数据样本。
本发明实施例提供的数据更新的技术方案,获取数据样本中缺失属性和非缺失属性的第一出现率信息,根据所获取的第一出现率信息计算缺失属性对应的各属性值在包含缺失值的数据样本中出现的第二出现率信息,根据该第二出现率信息确定与包含缺失值的数据样本中的缺失值对应的填充值,并根据该填充值更新包含缺失值的数据样本。本发明实施例通过采用上述技术方案,根据缺失属性对应的各属性值在包含缺失值的数据样本中的出现率信息确定与包含缺失值的数据样本中的缺失值相对应的填充值,可以提高填充值的正确性与数据信息的有效性,提高缺失值的处理速度,减少处理缺失值所需的时间,进而提高后续数据处理流程的准确性与整个数据处理过程的平均速度。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明实施例一提供的一种数据更新的方法的流程示意图;
图2为本发明实施例二提供的一种数据更新的方法的流程示意图;
图3为本发明实施例三提供的一种数据更新的装置的结构框图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。
实施例一
本发明实施例一提供一种数据更新的方法。该方法可由数据更新的装置执行,其中,该装置可由硬件和/或软件实现,一般可集成在数据处理平台中。图1是本发明实施例一提供的数据更新的方法的流程示意图,如图1所示,该方法包括:
s110、获取数据样本中缺失属性和非缺失属性的第一出现率信息,所述数据样本包括包含缺失值的第一数据样本和未包含缺失值的第二数据样本,所述缺失属性为所述第一数据样本中缺失值对应的属性。
本实施例中,缺失属性为包含缺失值的数据样本中缺失值对应的属性,相应的,非缺失属性为包含缺失值的数据样本中非缺失值对应的属性。其中,数据样本可以是实体类数据样本。包含缺失值的数据样本和不包含缺失值的数据样本的具体定义可以根据处理方式的不同灵活设定,例如,可以将任意一个或多个属性值缺失的数据样本均定义为包含缺失值的数据样本,相应的,将不包含缺失值的数据样本定义为所有属性值均不缺失的数据样本;也可以在对数据样本某一个属性中包含的缺失值进行处理时,只将该属性的属性值缺失的数据样本定义为包含缺失值的数据样本,相应的,将不包含缺失值的数据样本定义为该属性的属性值不缺失的数据样本或所有属性值均不缺失的数据样本。
本实施例中,在对数据样本中包含的缺失值进行处理时,可以以横向或纵向的顺序进行处理,即,可以以数据样本为单位进行处理,也可以以属性为单位进行处理,此处不作限制。在对数据样本中的缺失值进行处理时,可以将缺失值对应属性相同且非缺失属性的属性值也相同的数据样本归为一组,在进行缺失值处理时同时对该组数据样本中的缺失值进行处理。其中,非缺失属性可以是除缺失属性之外的其他所有属性,也可以是缺失属性的相关属性。
考虑到计算的简便性,优选的,所述非缺失属性为缺失属性的相关属性。相应的,在对某一数据样本某一个属性中包含的缺失值进行处理时,可以只将该数据样本定义为包含缺失值的数据样本(即第一数据样本),将相关属性的属性值均不缺失的数据样本定义为不包含缺失值的数据样本(即第二数据样本)。其中,某一缺失属性的相关属性可以由开发商或运营商根据需要灵活设定,也可以根据数据样本各相关属性与该缺失属性的关联度信息确定,关联度信息可以通过统计该缺失属性对应属性值发生变化时其他属性的属性值发生变化的概率获得。
缺失属性和非缺失属性的第一出现率信息可以是缺失属性对应的各属性值在数据样本中的出现率信息、缺失属性对应的各属性值在第二数据样本中的出现率信息、非缺失属性各属性值在数据样本中的出现率信息、非缺失属性各属性值在第二数据样本中的出现率信息或者非缺失属性各属性值在以缺失属性为条件时的条件概率信息,此处不作限制。考虑到各出现率信息的实用性与计算的简洁性,优选的,所述第一出现率信息包括缺失属性对应的各属性值在第二数据样本中的第一子出现率信息以及所述第一数据样本中各非缺失属性的属性值在第二数据样本中以缺失属性对应的属性值为条件的第二子出现率信息;或者,所述第一出现率信息包括所述缺失属性对应的各属性值在第二数据样本中的第一子出现率信息、所述第一数据样本中各非缺失属性的属性值在第二数据样本中以缺失属性对应的属性值为条件的第二子出现率信息以及所述第一数据样本非缺失属性的属性值对应的权重值信息。其中,第一数据样本某一非缺失属性的属性值对应的权重值信息可以由开发商或运营商根据需要灵活设定,也可以根据该属性值在第二数据样本中的出现率信息确定,此处不作限制。考虑到设置的简洁性,优选的,可以将第一数据样本非缺失属性的的属性值在第二数据样本中的出现率信息作为该第一数据样本非缺失属性的属性值对应的权重值信息。
本实施例中,在对某一第一数据样本中的缺失值进行处理时,可以实时计算获取该第一数据样本中缺失属性和非缺失属性的第一出现率信息,也可以预先计算数据样本所有属性的第一出现率信息并将其存储在与数据处理平台相对应的数据库中,在对某一第一数据样本中的缺失值进行处理时,直接从数据库中调用与该第一数据样本的缺失值相对应的缺失属性和非缺失属性的第一出现率信息即可,此处不作限制。为了避免在对不同第一数据样本进行处理时需对各属性的第一出现率信息进行重复计算的情况,优选的,可以预先计算并存储数据样本各属性的第一出现率信息。
s120、根据所述第一出现率信息计算所述缺失属性对应的各属性值的第二出现率信息,所述第二出现率信息为缺失属性对应的各属性值在所述第一数据样本中出现的出现率信息。
本实施例中,第二出现率信息的计算方法可以根据需要进行灵活设定,例如,第一数据样本缺失属性对应的某一属性值的第二出现率信息可以为该第一数据样本非缺失属性值以该缺失属性对应的属性值为条件的条件概率信息与该缺失属性对应的属性值在第二数据样本中的出现率信息之积同该第一数据样本各非缺失属性值在第二数据样本中的出现率信息的比值,即该缺失值对应的属性值的第二出现率信息
以非缺失属性为相关属性为例,假设缺失属性为婚姻状况属性,其对应的属性值分别为未婚、已婚和离异(在第二数据样本中的出现率分别为0.3,0.6和0.1),缺失属性对应的相关属性为性别和是否买房,某第一数据样本的相关属性值分别为男性和买房,在缺失属性对应的属性值分别为未婚、已婚和离异的第二数据样本中男性的数据样本出现率分别为0.4、0.7和0.5,在缺失属性对应的属性值分别为未婚、已婚和离异的第二数据样本中是否买房属性的属性值为买房的数据样本的出现率分别为0.3、0.7和0.5,那么,在该第一数据样本中,缺失属性对应的属性值为未婚的概率为:p(未婚|r)=p(未婚)p(男性|未婚)p(买房|未婚)=0.3×0.4×0.3=0.036,同理,缺失属性对应的属性值为已婚的概率为:p(已婚|r)=0.294,缺失属性对应的属性值为已婚的概率为:p(离异|r)=0.025。
本实施例中,第一数据样本缺失属性对应的某一属性值的第二出现率信息也可以为该第一数据样本非缺失属性值以该缺失属性对应的属性值为条件的条件概率信息、该缺失属性对应的属性值在第二数据样本中的出现率信息与第一数据样本非缺失属性的属性值对应的权重值信息之积同该第一数据样本各非缺失属性值在第二数据样本中的出现率信息的比值,即该缺失值对应的属性值的第二出现率信息
以非缺失属性为相关属性为例,假设缺失属性为婚姻状况属性,其对应的属性值分别为未婚、已婚和离异(在第二数据样本中的出现率分别为0.3,0.6和0.1),缺失属性对应的相关属性为性别和是否买房,某第一数据样本的相关属性值分别为男性和买房(其对应的权重值信息分别为0.6和0.7),在缺失属性对应的属性值分别为未婚、已婚和离异的第二数据样本中男性的数据样本出现率分别为0.4、0.7和0.5,在缺失属性对应的属性值分别为未婚、已婚和离异的第二数据样本中是否买房属性值为买房的数据样本的出现率分别为0.3、0.7和0.5,则在该第一数据样本中,缺失属性对应的属性值为未婚的概率为:
p(未婚|r)=p(未婚)w(男性)p(男性|未婚)w(买房)p(买房|未婚),
=0.3×0.6×0.4×0.7×0.3=0.1512
同理,缺失属性对应的属性值为已婚的概率为:p(已婚|r)=0.12348,缺失属性对应的属性值为已婚的概率为:p(离异|r)=0.0105。
s130、根据所述第二出现率信息确定与所述第一数据样本对应的填充值,并根据所述填充值更新所述第一数据样本。
本实施例中,在对某一第一数据样本或某一组非缺失属性值完全相同的第一数据样本中的缺失值进行处理时,可以选取与该第一数据样本或该组第一数据样本中的第二出现率信息最大的缺失属性对应的属性值作为填充值,并将该填充值填充到该第一数据样本或该组第一数据样本的缺失属性位置处以实现对该第一数据样本或该组第一数据样本的更新。例如,假设某第一数据样本的缺失属性为婚姻状况属性,其对应的属性值分别为未婚、已婚和离异,且各缺失属性对应的属性值的第二出现率信息分别为:p(未婚|r)=0.036,p(已婚|r)=0.294,p(离异|r)=0.025,p(已婚|r)>p(未婚|r)>p(离异|r),则该第一数据样本婚姻状况属性的填充值为“已婚”。
本发明实施例一提供的数据更新的方法,获取数据样本中缺失属性和非缺失属性的第一出现率信息,根据所获取的第一出现率信息计算缺失属性对应的各属性值在包含缺失值的数据样本中出现的第二出现率信息,根据该第二出现率信息确定与包含缺失值的数据样本中的缺失值对应的填充值,并根据该填充值更新包含缺失值的数据样本。本发明实施例通过采用上述技术方案,根据缺失属性对应的各属性值在包含缺失值的数据样本中的出现率信息确定与包含缺失值的数据样本中的缺失值相对应的填充值,可以提高填充值的正确性与数据信息的有效性,提高缺失值的处理速度,减少处理缺失值所需的时间,进而提高后续数据处理流程的准确性与整个数据处理过程的平均速度。
在上述实施例的基础上,在所述获取数据样本中缺失属性和非缺失属性的第一出现率信息之前,还包括:对第二数据样本进行训练以确定数据样本中缺失属性和非缺失属性的第一出现率信息。本实施例中,可以根据数据样本中的第二数据样本直接计算确定数据样本中缺失属性和非缺失属性的第一出现率信息;也可以将数据样本中的第二数据样本分为训练样本和测试样本,对训练样本进行训练得到缺失属性和非缺失属性的第一出现率信息,并采用测试样本对训练得到的第一出现率信息进行测试以确定训练得到的第一出现率信息的准确性,此处不作限制。优选的,可以将第二数据样本分为训练样本和测试样本,通过训练样本得到数据样本中缺失属性和非缺失属性的第一出现率信息,通过测试样本对所得到的第一出现率信息进行测试以确定所得到的第一出现率信息的准确性,并在第一出现率信息的准确性不符合设定条件时重新对第二数据样本进行训练,从而保证所得到的第一出现率信息的准确性,进一步提高所得到的缺失属性对应的填充值的准确性。
实施例二
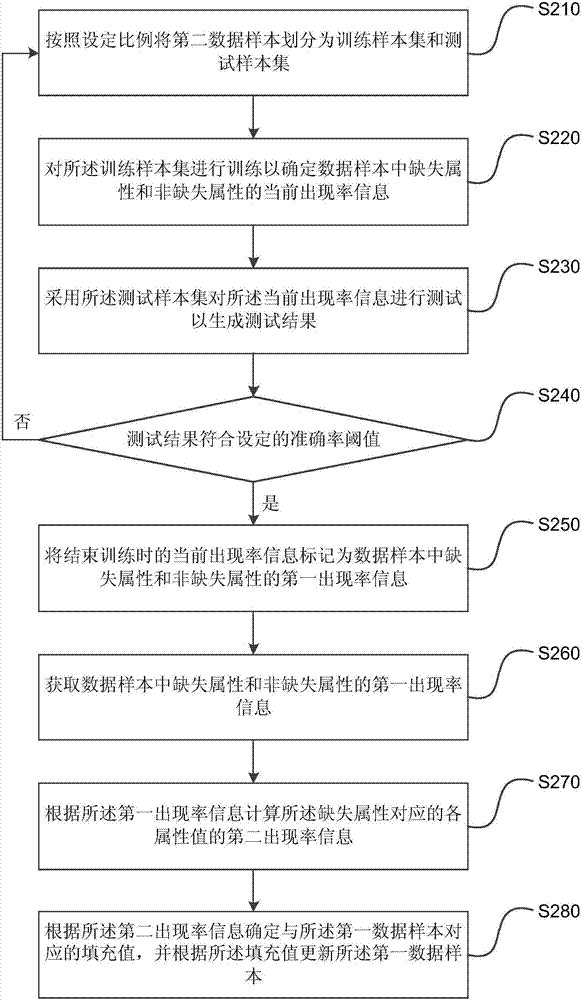
图2为本发明实施例二提供的一种数据更新的方法的流程示意图。本实施例在上述实施例的基础上进行优化,进一步地,所述对第二数据样本进行训练以确定数据样本中缺失属性和非缺失属性的第一出现率信息,包括:按照设定比例将第二数据样本划分为训练样本集和测试样本集;对所述训练样本集进行训练以确定数据样本中缺失属性和非缺失属性的当前出现率信息;采用所述测试样本集对所述当前出现率信息进行测试以生成测试结果;如果所述测试结果符合设定的准确率阈值,则结束训练操作;否则,则重新划分训练样本集和测试样本集,并对重新划分后的训练样本集进行训练直至所述测试结果符合设定的准确率阈值为止;将结束训练时的当前出现率信息标记为数据样本中缺失属性和非缺失属性的第一出现率信息。
相应的,如图2所示,本实施例提供的数据更新的方法包括:
s210、按照设定比例将第二数据样本划分为训练样本集和测试样本集。
本实施例中,划分训练样本集和测试样本集的设定比例可以根据非缺失属性的数量或第一数据样本的数量等因素灵活设定,例如,可以将设定比例设置为1:1,即,将50%的第二数据样本作为训练样本添加至训练样本集中,将剩余50%的第二数据样本作为测试样本添加至测试样本集中。在此,需要指出的是,当数据样本数量较少或者第一数据样本在数据样本中所占比例较大时,可以适当增大第二数据样本中训练样本集所占的比例,如可以将第二数据样本中训练样本与测试样本的比例调节为6:4、7:3或8:2等比例系数,此处不作限制。
在将第二数据样本划分为训练样本集和测试样本集时,可以随机选取设定比例的第二数据样本作为训练样本添加至训练样本集中,并将剩余的第二数据样本作为测试样本添加至测试样本集中;也可以按照一定的顺序从前向后、从后向前或按照每间隔一个或几个选取一个、每间隔一个选取一个或几个的顺序选择设定比例系数的第二数据样本作为训练样本添加至训练样本集中,并将剩余的第二数据样本作为测试样本添加至测试样本集中。
s220、对所述训练样本集进行训练以确定数据样本中缺失属性和非缺失属性的当前出现率信息。
本实施例中,可以根据缺失属性对应的各属性值在训练样本中出现的比例、缺失属性取不同的属性值时各非缺失属性值出现的比例,和/或,各非缺失属性值在训练样本中出现的比例确定缺失属性和非缺失属性的第一出现率信息。其中,如果缺失属性对应的属性值为连续型数值,可以先将缺失属性的属性值进行离散化处理,如将年龄属性离散化为20-25、25-30、30-35和35-40等离散区间,然后再计算离散处理后的各缺失属性对应的属性值(20-25、25-30、30-35和35-40等)在训练样本中出现的比例。如果非缺失属性对应的属性值为连续型数值,则可以首先根据训练样本得到非缺失属性的均值η和方差σ,从而得到非缺失属性的正太分布公式
示例性的,在计算缺失属性和非缺失属性的第一出现率信息时,假设缺失属性为婚姻状况(属性值分别为未婚、已婚和离异),非缺失属性为性别(属性值分别为男性和女性),在5000个训练样本中,性别为男性的训练样本共有2650个,性别为女性的训练样本共有2350个,婚姻状况为未婚的训练样本共有2000个(其中男性为1100个,女性为900个),婚姻状况为已婚的训练样本共有2700个(其中男性为1400个,女性为1300个),婚姻状况为离异的训练样本共有300个,其中男性为150个,女性为150个),则缺失属性对应的属性值“未婚”在训练样本中出现的比例p(未婚)=2000/5000=0.4,同理,缺失属性对应的属性值“已婚”和“离异”在训练样本中出现的比例p(已婚)=2700/5000=0.54,p(离异)=300/5000=0.06;在缺失属性对应的属性值为未婚的训练样本中,“男性”和“女性”出现的比例p(男性|未婚)=1100/2000=0.55,p(女性|未婚)=900/2000=0.45,同理,在缺失属性对应的属性值为已婚的训练样本中,“男性”和“女性”出现的比例p(男性|已婚)=1400/2700≈0.52,p(女性|已婚)=1300/2700≈0.48,在缺失属性对应的属性值为以的训练样本中,“男性”和“女性”出现的比例p(男性|离异)=p(女性|离异)=150/300=0.5。
在此,需要指出的是,在计算训练样本集中缺失属性取不同的属性值时各非缺失属性值出现的比例时,如果出现某一非缺失属性值rk在某一缺失属性对应的属性值yi的条件下出现的比例p(rk|yi)为0,即缺失属性对应的某一属性值yi下某个非缺失属性值rk并没有出现的情况,则需要对其进行校准,以防止数据样本准确性的降低。在此,校准所采用的规则可以根据需要灵活设定,例如,可以使用拉普拉斯(laplace)进行校准,即当出现p(rk|yi)=0的情况时,将该比例的分子增加设定值,分母增加该设置值与非缺失属性的数量乘积,并将分子分母增加不同数值后的比例作为该非缺失属性值rk以缺失属性对应的属性值yi为条件时出现的比例,其中,所增加的设定值可以根据需要设定为1、2、5或其他的数值。例如,假设设定值为1,缺失属性为婚姻状况属性,非缺失属性共有5个,其中,性别属性为5个非缺失属性中的一个,在训练样本中共有40个婚姻状况为已婚的训练样本,该40个训练样本的性别属性值均为男性,则此时,婚姻状况为已婚的训练样本中女性出现的概率
s230、采用所述测试样本集对所述当前出现率信息进行测试以生成测试结果。
示例性的,在采用某一测试样本对某一属性作为缺失属性时的当前出现率信息进行测试时,可以根据对训练样本进行训练所得到的当前出现率信息计算该测试样本该缺失属性对应的各属性值的第二出现率信息,并根据所得到的第二出现率信息确定该测试样本该缺失属性对应的属性值,然后判断根据第二出现率信息确定的属性值与该测试样本中该缺失属性对应的真实属性值是否相同,若相同,则判定当前出现率信息对该测试样本来说是准确的,否则,则判定当前出现率信息对该测试样本来说是不准确的,依此类推,直至测试样本集中的所有测试样本均以测试完成,并生成测试结果。在此,需要指出的是,可以将各测试样本的填充值是否准确作为测试结果,也可以将根据各测试样本填充值是否准确确定的填充值的准确率信息作为测试结果,此处不作限制。考虑到后续计算的简洁性,优选的,测试结果可以是填充值的准确率信息。
s240、如果所述测试结果符合设定的准确率阈值,则结束训练操作;否则,则重新划分训练样本集和测试样本集,并对重新划分后的训练样本集进行训练直至所述测试结果符合设定的准确率阈值为止。
本实施例中,设定的准确率阈值可以根据需要灵活设定,例如,可以将准确率阈值设置为95%、98%或100%等数值。示例性的,假设准确率阈值为98%,此时,如果测试结果大于或等于98%,则结束训练操作;如果测试结果小于98%,则重新划分训练样本集合测试样本集,并对重新划分后的训练样本集重新进行训练以重新确定当前出现率信息。在此,需要指出的是,在重新划分训练样本集和测试样本集时,可以按照上次使用的设定比例重新划分训练样本集和测试样本集;也可以重新设定划分训练样本集和测试样本集的设定比例,并按照重新设定的设定比例重新划分训练样本集和测试样本集,此处不作限制。
s250、将结束训练时的当前出现率信息标记为数据样本中缺失属性和非缺失属性的第一出现率信息。
示例性的,在结束训练时,可以将当前出现率信息进行标记、删除此次训练之前的训练得到的出现率信息或将当前出现率信息存储到设定的存储位置,从而达到将结束训练时的当前出现率信息标记为数据样本中缺失属性和非缺失属性的第一出现率信息的目的。
s260、获取数据样本中缺失属性和非缺失属性的第一出现率信息,所述数据样本包括包含缺失值的第一数据样本和未包含缺失值的第二数据样本,所述缺失属性为所述第一数据样本中缺失值对应的属性。
s270、根据所述第一出现率信息计算所述缺失属性对应的各属性值的第二出现率信息,所述第二出现率信息为缺失属性对应的各属性值在所述第一数据样本中出现的出现率信息。
s280、根据所述第二出现率信息确定与所述第一数据样本对应的填充值,并根据所述填充值更新所述第一数据样本。
本发明实施例二提供的数据更新的方法,按照设定比例将第二数据样本划分为训练样本集和测试样本集,对训练样本集进行训练以确定数据样本缺失属性和非缺失属性的当前出现率信息,采用测试样本集对所得到的当前出现率信息进行测试以生成测试结果,如果测试结果符合设定的准确率阈值,则将该当前出现率信息标记为数据样本中缺失属性和非缺失属性的第一出现率信息,并根据该第一出现率信息确定填充值对第一数据样本的缺失值进行填充;否则,则重新划分训练样本和测试样本,直至此时结果符合设定的准确率阈值为止。本实施例通过采用上述技术方案,通过训练确定缺失属性和非缺失属性的第一出现率信息,可以保证所得到的第一出现率信息的准确性,从而进一步提高填充值的正确性与数据信息的有效性,提高缺失值的处理速度,减少处理缺失值所需的时间。
实施例三
本发明实施例三提供一种数据更新的装置。该装置可以由硬件和/或软件实现,一般可集成在数据处理平台中,可通过执行数据更新的方法对数据进行处理。图3所示为本发明实施例三提供的数据更新的装置的结构框图,如图3所示,该装置包括:
第一出现率信息获取模块310,用于获取数据样本中缺失属性和非缺失属性的第一出现率信息,所述数据样本包括包含缺失值的第一数据样本和未包含缺失值的第二数据样本,所述缺失属性为所述第一数据样本中缺失值对应的属性;
第二出现率信息计算模块320,用于根据所述第一出现率信息计算所述缺失属性对应的各属性值的第二出现率信息,所述第二出现率信息为缺失属性对应的各属性值在所述第一数据样本中出现的出现率信息;
数据样本更新模块330,用于根据所述第二出现率信息确定与所述第一数据样本对应的填充值,并根据所述填充值更新所述第一数据样本。
本发明实施例三提供的数据更新的装置,通过第一出现率信息获取模块获取数据样本中缺失属性和非缺失属性的第一出现率信息,通过第二出现率信息计算模块根据所获取的第一出现率信息计算缺失属性对应的各属性值在包含缺失值的数据样本中出现的第二出现率信息,通过数据样本更新模块根据该第二出现率信息确定与包含缺失值的数据样本中的缺失值对应的填充值,并根据该填充值更新包含缺失值的数据样本。本实施例通过采用上述技术方案,根据缺失属性对应的各属性值在包含缺失值的数据样本中的出现率信息确定与包含缺失值的数据样本中的缺失值相对应的填充值,可以提高填充值的正确性与数据信息的有效性,提高缺失值的处理速度,减少处理缺失值所需的时间,进而提高后续数据处理流程的准确性与整个数据处理过程的平均速度。
在上述实施例的基础上,所述第一出现率信息包括缺失属性对应的各属性值在第二数据样本中的第一子出现率信息以及所述第一数据样本中各非缺失属性的属性值在第二数据样本中以缺失属性对应的属性值为条件的第二子出现率信息;所述第二出现率信息计算模块320用于:根据公式
在上述实施例的基础上,所述第一出现率信息包括所述缺失属性对应的各属性值在第二数据样本中的第一子出现率信息、所述第一数据样本中各非缺失属性的属性值在第二数据样本中以缺失属性对应的属性值为条件的第二子出现率信息以及所述第一数据样本非缺失属性的属性值对应的权重值信息;所述第二出现率信息计算模块320用于:根据公式
在上述实施例的基础上,本实施例提供的数据更新的装置还可以包括:第一出现率信息确定模块,用于在所述获取数据样本中缺失属性和非缺失属性的第一出现率信息之前,对第二数据样本进行训练以确定数据样本中缺失属性和非缺失属性的第一出现率信息。
在上述实施例的基础上,所述第一出现率信息确定模块包括:数据样本划分单元,用于按照设定比例将第二数据样本划分为训练样本集和测试样本集;当前出现率信息确定单元,用于对所述训练样本集进行训练以确定数据样本中缺失属性和非缺失属性的当前出现率信息;出现率信息测试单元,用于采用所述测试样本集对所述当前出现率信息进行测试以生成测试结果;循环调用单元,用于如果所述测试结果符合设定的准确率阈值,则结束训练操作;否则,则重新划分训练样本集和测试样本集,并对重新划分后的训练样本集进行训练直至所述测试结果符合设定的准确率阈值为止;第一出现率信息标记单元,用于将结束训练时的当前出现率信息标记为数据样本中缺失属性和非缺失属性的第一出现率信息。
在上述实施例的基础上,所述非缺失属性为缺失属性的相关属性。
本实施例提供的数据更新的装置可执行本发明任意实施例所提供的数据更新的方法,具备执行数据更新的方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例所提供的数据更新的方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!