一种基于Hadoop架构数据分析图表展示的方法及系统与流程
本发明涉及分布式计算技术领域,尤其涉及一种基于hadoop架构数据分析图表展示的方法及系统。
背景技术:
传统的关系型数据库中的表通常由一个或多个字段组成,每个字段都预先定义了其可存储数据的格式及约束等,这类的数据就是结构化数据。相应地,非结构化数据就是指那些没有一个预定义的数据模型或不适于存储在关系型数据库中的数据,这些数据没有额外的描述信息,因此无法推断这些信息的真实意义。
现今身处于数据大爆炸的世界,如搜索引擎类公司的网络爬虫爬行而来的web页面或社交类站点产生的用户访问日志都属半结构化或非结构化数据,传统的关系型数据库管理系统对这类数据的存储及处理能力有限,大型数据集或数据的分析能力很快成为各大行业机构竞争力的关键基础,成为生产力、行业成长和创新发展新趋势的基石。
技术实现要素:
本发明要解决的技术问题是提供一种基于hadoop架构数据分析图表展示的方法及系统,实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于hadoop架构数据分析图表展示的方法,包括:进行原始数据采集;采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;流式大数据处理框架storm流处理,实时处理解析所述数据管理中的数据流;将所述经storm流处理得到的数据流,导入关系数据库;分析处理所述关系数据库中的数据,并直观展示所述经分析处理后的数据。
其中,所述进行原始数据采集,包括:
采用分布式网络爬虫进行原始数据采集。
其中,所述采用分布式网络爬虫进行原始数据采集,包括:
采用定时定向的信息采集方式进行统一调度,采用分布式网络爬虫进行原始数据采集。
其中,所述采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理,包括:
采用分布式文件系统hdfs作为底层数据存储介质,通过映射函数mapreduce编程模式进行分析,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理。
其中,所述分析处理所述关系数据库中的数据,并直观展示所述经分析处理后的数据,包括:
分析处理所述关系数据库中的数据,并通过商业级数据图表echarts前端技术直观展示所述经分析处理后的数据。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种一种基于hadoop架构数据分析图表展示的系统,包括:采集控制器、分布式计算hadoop平台、数据流处理器、数据库、界面展示器;所述采集控制器,用于进行原始数据采集;所述分布式计算hadoop平台,用于采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;所述数据流处理器,用于流式大数据处理框架storm流处理,实时处理解析所述数据管理中的数据流;所述数据库,用于将所述经storm流处理得到的数据流,导入关系数据库;所述界面展示器,用于分析处理所述关系数据库中的数据,并直观展示所述经分析处理后的数据。
其中,所述采集控制器具体用于:采用分布式网络爬虫进行原始数据采集。
其中,所述采集控制器具体用于:
采用定时定向的信息采集方式进行统一调度,采用分布式网络爬虫进行原始数据采集。
其中,所述分布式计算hadoop平台具体用于:
采用分布式文件系统hdfs作为底层数据存储介质,通过映射函数mapreduce编程模式进行分析,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理。
其中,所述界面展示器具体用于:
分析处理所述关系数据库中的数据,并通过商业级数据图表echarts前端技术直观展示所述经分析处理后的数据。
本发明提供的基于hadoop架构数据分析图表展示的方法,包括:进行原始数据采集;采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流;将该经storm流处理得到的数据流,导入关系数据库;分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据;从而达到实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
本发明提供的基于hadoop架构数据分析图表展示的系统,包括:采集控制器、分布式计算hadoop平台、数据流处理器、数据库、界面展示器;采集控制器,用于进行原始数据采集;分布式计算hadoop平台,用于采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;数据流处理器,用于流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流;数据库,用于将该经storm流处理得到的数据流,导入关系数据库;界面展示器,用于分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据;从而达到实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
附图说明
图1为本发明基于hadoop架构数据分析图表展示的方法的流程示意图;
图2为本发明基于hadoop架构数据分析图表展示的系统的结构示意图。
具体实施方式
本发明提供一种基于hadoop架构数据分析图表展示的方法及系统,应用于分布式计算技术领域,本发明基于hadoop架构数据分析图表展示的方法,包括:进行原始数据采集;采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流;将该经storm流处理得到的数据流,导入关系数据库;分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据;从而达到实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种基于hadoop架构数据分析图表展示的方法。
请参见图1,图1为本发明基于hadoop架构数据分析图表展示的方法的流程示意图,需注意的是,若有实质上相同的结果,本发明的方法并不以图1所示的流程顺序为限,本发明基于hadoop架构数据分析图表展示的方法,包括:
s11:进行原始数据采集。
其中,进行原始数据采集,包括:
采用分布式网络爬虫进行原始数据采集。
其中,采用分布式网络爬虫进行原始数据采集,包括:
采用定时定向的信息采集方式进行统一调度,采用分布式网络爬虫进行原始数据采集。
s12:采用分布式文件系统(hdfs)作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库(hbase)和数据仓库基础构架(hive)进行数据管理。
其中,采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理,包括:
采用分布式文件系统hdfs作为底层数据存储介质,通过映射函数(mapreduce)编程模式进行分析,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理。
s13:流式大数据处理框架(storm)流处理,实时处理解析该数据管理中的数据流。
s14:将该经storm流处理得到的数据流,导入关系数据库。
s15:分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据。
其中,分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据,包括:
分析处理该关系数据库中的数据,并通过商业级数据图表(echarts)前端技术直观展示该经分析处理后的数据。
本发明还提供一种基于hadoop架构数据分析图表展示的系统。
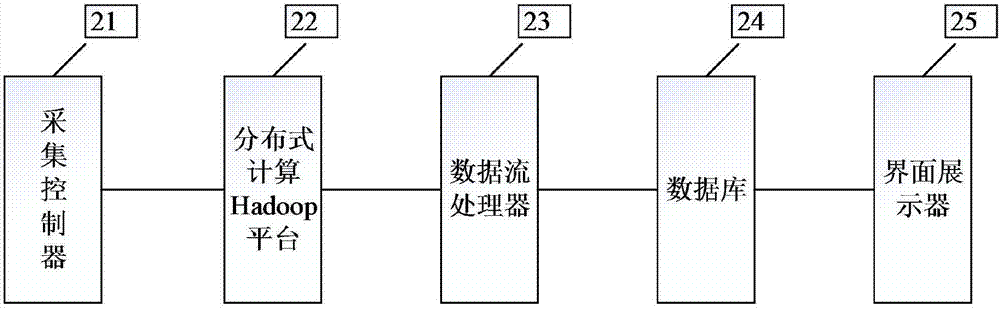
请参见图2,图2为本发明基于hadoop架构数据分析图表展示的系统的结构示意图,本发明基于hadoop架构数据分析图表展示的系统,包括:采集控制器21、分布式计算hadoop平台22、数据流处理器23、数据库24、界面展示器25;
采集控制器21,用于进行原始数据采集。
分布式计算hadoop平台22,用于采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理。
数据流处理器23,用于流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流。
数据库24,用于将该经storm流处理得到的数据流,导入关系数据库。
界面展示器25,用于分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据。
其中,采集控制器21可以具体用于:采用分布式网络爬虫进行原始数据采集。
其中,采集控制器21可以具体用于:
采用定时定向的信息采集方式进行统一调度,采用分布式网络爬虫进行原始数据采集。
其中,分布式计算hadoop平台22可以具体用于:
采用分布式文件系统hdfs作为底层数据存储介质,通过映射函数mapreduce编程模式进行分析,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理。
其中,界面展示器25可以具体用于:
分析处理该关系数据库中的数据,并通过商业级数据图表echarts前端技术直观展示该经分析处理后的数据。
本发明提供的基于hadoop架构数据分析图表展示的方法,包括:进行原始数据采集;采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流;将该经storm流处理得到的数据流,导入关系数据库;分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据;从而达到实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
本发明提供的基于hadoop架构数据分析图表展示的系统,包括:采集控制器21、分布式计算hadoop平台22、数据流处理器23、数据库24、界面展示器25;采集控制器21,用于进行原始数据采集;分布式计算hadoop平台22,用于采用分布式文件系统hdfs作为底层数据存储介质,在其之上构建更高层次的分布式的、面向列的开源数据库hbase和数据仓库基础构架hive进行数据管理;数据流处理器23,用于流式大数据处理框架storm流处理,实时处理解析该数据管理中的数据流;数据库24,用于将该经storm流处理得到的数据流,导入关系数据库;界面展示器25,用于分析处理该关系数据库中的数据,并直观展示该经分析处理后的数据;从而达到实现可以高效管理和分析海量数据,可以对所展现数据进行挖掘、提取、修正或整合,让用户可以有不同的方式解读同样的数据。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或者操作之间存在任何这种实际的关系或者顺序。而且,术语“包含”、“包括”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系统要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个、、、、、、”限定的要素,并不排除在包括所述要素的过程、方法、物品、设备或者装置中还存在另外的相同要素。
对于本发明基于hadoop架构数据分析图表展示的方法及系统,实现的形式是多种多样的。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!