一种基于无监督深度模型与层次属性的行人再识别方法与流程
本发明涉及模式识别技术领域,具体涉及一种基于无监督深度模型与层次属性的行人再识别方法。
背景技术:
随着人们对社会公共安全的日益关注以及视频采集技术和大规模数据存储技术的发展,大量的监控摄像头应用在商场、公园、学校、医院、公司、体育场馆、大型广场、地铁站等人群密集易发生公共安全事件的场所。监控摄像的出现无疑给人们带来了极大便利。监控视频可为公安部门提供诸如商场盗窃、聚众斗殴、银行卡盗窃等重大刑事案件的线索;同时也可为交通协管部门提供大量实时交通路况信息方便其对交通进行监管;对于个人和商户监控也成为其保护财产维护权益的重要手段。然而,普通的视频监控系统往往面临着一个操作人员需要负责多个摄像头的监控视频,从而造成监控工作枯燥无味,且监控效果易受人为因素,如责任心、情感因素等的影响;此外人工已难以应对海量增长的监控视频,因此利用计算机对监控视频中的行人进行再识别的需求应运而生。
行人再识别涉及的主要技术包括特征提取和分类器设计。在特征提取方面,传统方法是对大量有标签的数据进行有监督的模型训练,但考虑到在监控视频中出现的行人众多,对所有行人都提供大量有标签的训练图像是一个不可能完成的任务,因此,只有依靠无监督的模型训练来实现对视频中行人的特征提取。
而在分类器设计方面,传统的hog特征,sift特征等虽然已取得了较好的成绩,但是这些底层特征由于缺乏语义特性,使得行人再识别系统的应用受到了限制。富有语义表达能力的属性作为高于颜色、纹理等低层特征的中层特征,在行人再识别方法中是个不错的选择。但是由于人类的认知具有一个层次过程,也就是先对粗略的特征有感知,而后才对更细化的特征进行感知,在记忆过程中也是如此,能够记住一些大致的特征,却往往遗忘一些细节特征。例如,在对疑犯进行描述时,目击者会遗忘一些详细的外貌信息,只对一些粗粒度信息保留印象。因此,仅仅利用单层的属性来进行再识别大大限制了行人再识别的应用范围。
技术实现要素:
为了克服上述现有技术的缺陷,本发明在深度学习和属性学习的基础上,提出利用cae无监督学习方式训练cnn模型,并引入层次属性的概念,提出一种基于无监督深度模型与层次属性的行人再识别方法。
为了实现上述目的,本发明具体技术方案如下:一种基于无监督深度模型与层次属性的行人再识别方法,包括深度模型训练、行人特征提取、层次属性学习和分类识别四个步骤,其中,深度模型训练还包括如下步骤:
1)对预训练数据集cuhk和微调数据集viper中图像分别进行预处理和分块;
2)将预处理和分块后的viper数据集等分为8份,随机选择其中7份作为训练样本viper_train,另1份作为测试样本viper_test;
3)构建一个深度卷积神经网络(convolutionalneuralnetwork,cnn)模型,模型包含三个隐含层,每个隐含层都由多个卷积自动编码器((convolutionalauto-encode,cae)构成;其中,第一隐含层包括20个cae,第二隐含层包括50个cae,第三隐含层包括100个cae;
4)利用预处理后的cuhk和viper_train对cnn进行模型训练,训练方法采用cae的无监督重构方式,得到训练完毕的cnn模型;
行人特征提取还包括如下步骤:
5)将viper_train输入训练完毕的cnn模型,得到关于每张图像5个分块的共500张特征图,其中,每个分块有100张特征图;
6)对特征图进行转化,将每张特征图的二维矩阵按照每列相接的方式转化为一维特征向量,再将每个分块中100个特征向量相连接成为一个一维分块特征向量;
层次属性学习还包括如下步骤:
7)设计行人层次属性,行人层次属性包括粗粒度属性{a1,a2,…ak,…an}和细粒度属性{a1,a2,…al,…am};其中,n=17,m=16;
8)对viper数据集中的每一个行人图像进行属性标注;
9)为每一个属性分配一个支持向量机(supportvectormachine,svm)作为属性分类器,并利用分块特征向量和相应的属性标注对每一个属性分类器进行训练,得到训练完毕的属性分类器;
分类识别还包括如下步骤:
10)根据属性标注,统计viper_test数据集中每一个行人的属性类别映射概率,得到属性类别映射关系表,其中,属性类别映射关系表中粗粒度属性对应的概率为
11)设定层次属性的权值,粗粒度属性权值用w1表示,细粒度属性权值用w2表示;
12)将viper_test中样本xt输入训练完毕的cnn得到对应的分块特征图,再将每个分块中的所有特征图转化一维分块特征向量,并输入训练完毕的各属性分类器,得到样本具有粗粒度属性ak的后验概率p(ak|xt)和细粒度属性al的后验概率p(al|xt),结合属性类别映射关系表,通过贝叶斯公式得到在粗粒度属性下类别yj关于样本xt的后验概率p1(yj|xt)和在细粒度属性下类别yj关于样本xt的后验概率p2(yj|xt),其中,样本xt为viper_test测试样本{x1,x2,...,xt,...,xp}中的第t张分块行人图像,贝叶斯公式为:
13)计算样本关于类别的最终后验概率,计算公式为:
p(yj|xt)=w1p1(yj|xt)+w2p2(yj|xt);
14)选择最大的概率对应的类别作为样本的识别类别,选择公式为:
进一步地,上述步骤1)中图像预处理和分块还包括如下步骤:
1.1)将cuhk和viper中的行人图像大小统一为128×48像素;
1.2)将统一后的图像根据人体部位分割成具有重叠部分的5个分块,从上到下,第一个分块高度为1到36像素,宽度为1到48像素,包含行人的头部和发型;第二个分块高度为14到73像素,宽度为1到48像素,包含行人的上半身;第三个分块高度为36到103像素,宽度为1到48像素,包含行人上半身的一部分和下半身的一部分;第四分块高度为60到111像素,宽度为1到48像素,包含行人的腿部;第五分块高度为101到128像素,宽度为1到48像素,包含行人的脚部。
1.3)将行人图像的每个分块进行归一化处理。
进一步地,上述步骤3)中,三个隐层的第一隐含层20个cae,对应20个特征平面,卷积核大小为5×5,最大池化窗口大小为2×2;第二隐含层50个cae,对应50个特征平面,卷积核大小为5×5,最大池化窗口大小为2×2;第三隐含层100个cae,对应100个特征平面,卷积核大小为5×4,最大池化窗口大小为2×2。
进一步地,上述步骤4)中,对cnn进行模型训练包括如下步骤:
4.1)将预处理过的cuhk数据集图像对cnn进行预训练;
4.2)将预处理过的viper_train数据集对cnn进行微调。
进一步地,上述步骤7)中,粗粒度属性有17个,包括:“带帽”、“非长发”、“长发”、“长袖”、“短袖”、“无袖”、“穿外套”、“上衣花纹”、“有logo”、“长下装”、“短下装”、“下装花纹”、“背包”、“手拿物”、“凉鞋”、“单鞋”、“靴子”;细粒度属性有16个,包括:“秃头”、“短发”、“盘发”、“齐肩”、“披头”、“马尾”、“非条纹”、“密集条纹”、“稀疏条纹”、“长裤”、“长裙”、“双肩包”、“单肩包”、“手提包”、“手拿物品”、“行李箱”;其中,粗粒度和细粒度属性对应关系如下:粗粒度属性“非长发”对应细粒度属性(“秃头”、“短发”、“盘发”),粗粒度属性“长发”对应细粒度属性(“齐肩”、“披头”、“马尾”),粗粒度属性“上衣花纹”对应细粒度属性(“非条纹”、“密集条纹”、“稀疏条纹”),粗粒度属性“长下装”对应细粒度属性(“长裤”、“长裙”),粗粒度属性“背包”对应细粒度属性(“双肩包”、“单肩包”),粗粒度属性“手拿物”对应细粒度属性(“手提包”、“手拿物品”、“行李箱”)。
本发明的有益效果在于:利用cae的无监督学习方法预训练cnn模型,有效解决了缺乏训练样本的问题;利用cae能够较好地重构图像的特点,有效提高了行人再识别的准确率;通过引入层次属性使得对行人的再识别更加符合人类认知规律,让行人再识别方法富有语义表达能力的同时更加具有实际应用价值。
附图说明
图1是本发明所述的行人再识别方法结构示意图。
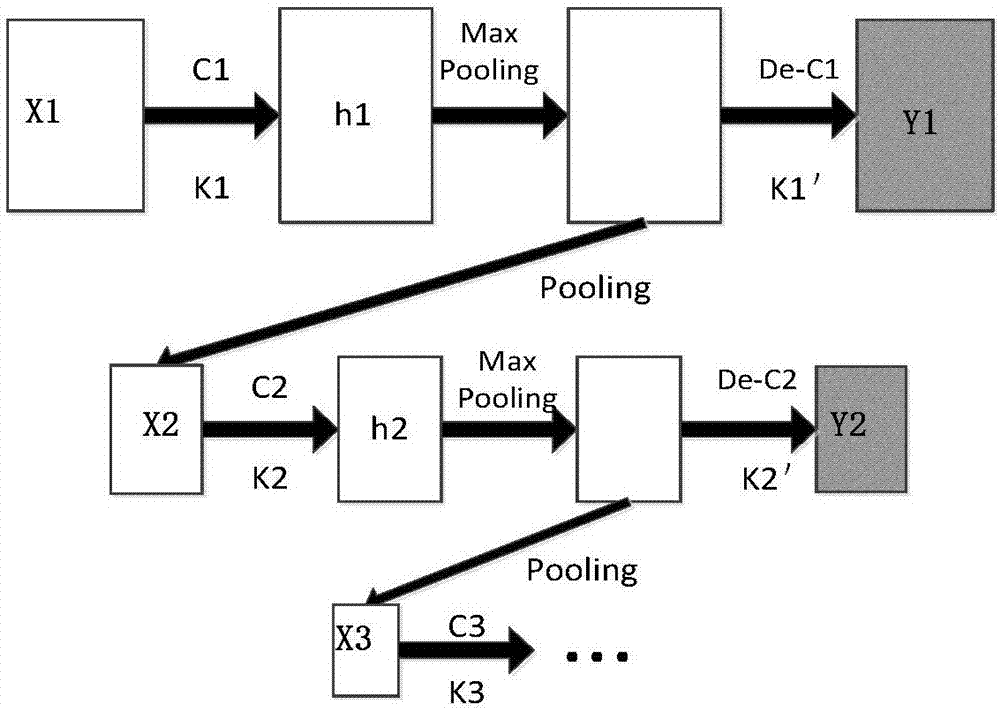
图2是本发明所述cae无监督训练过程示意图。
图3是本发明所述层次属性样例图。
图4是本发明所述属性类别映射关系示例表。
具体实施方式
下面结合附图对本发明作进一步描述。
图1为本发明提出的基于无监督深度模型与层次属性的行人再识别方法结构示意图。分为深度模型训练、行人特征提取、层次属性学习和分类识别四个阶段。
在模型训练阶段,包括如下步骤:
1)对预训练数据库cuhk和微调数据库viper中图像分别进行预处理和分块;其中,图像预处理和分块的方法是:
1.1)将cuhk和viper中的行人图像大小统一为128×48像素;
1.2)将统一后的图像根据人体部位分割成具有重叠部分的5个分块,从上到下,第一个分块高度为1到36像素,宽度为1到48像素,包含行人的头部和发型;第二个分块高度为14到73像素,宽度为1到48像素,包含行人的上半身;第三个分块高度为36到103像素,宽度为1到48像素,包含行人上半身的一部分和下半身的一部分;第四分块高度为60到111像素,宽度为1到48像素,包含行人的腿部;第五分块高度为101到128像素,宽度为1到48像素,包含行人的脚部。
1.3)将行人图像的每个分块进行归一化处理。
2)将预处理和分块后的viper数据集分为训练样本viper_train和测试样本viper_test;具体实施中,将viper数据集中的共1264张行人图像随机等分为8份,每份拥有158张分块行人图像,将其中7份共1106张分块行人图像作为训练样本viper_train,另外1份共158张分块行人图像作为测试样本viper_test。
3)构建一个深度卷积神经网络cnn模型,模型包含三个隐含层,每个隐含层都由多个卷积自动编码器cae构成;本发明实施例中,三个隐层的第一个隐含层包括20个cae,对应20个特征平面,卷积核大小为5×5,最大池化窗口大小为2×2;第二隐含层包括50个cae,对应50个特征平面,卷积核大小为5×5,最大池化窗口大小为2×2;第三隐含层包括100个cae,对应100个特征平面,卷积核大小为5×4,最大池化窗口大小为2×2。
4)利用预处理后的cuhk和viper_train对cnn进行模型训练,训练方法采用cae的无监督重构方式,得到训练完毕的cnn模型;其中,进行模型训练包括如下步骤:
4.1)将预处理过的cuhk数据集图像对cnn进行预训练,本发明具体实施例中,学习率为0.001,迭代次数为1000次;
4.2)将预处理过的viper_train数据集对cnn进行微调,本发明具体实施例中,学习率为0.0001,迭代次数为1000次。
图2所示为是本发明具体实施例cae无监督训练过程,每一层的输入图像x进行卷积操作得到一系列特征图h,经过max-pooling后通过反卷积操作重构原输入图像得到y,x与y的误差作为该隐含层的参数调整依据,权值和偏置的更新通过bp算法获得。max-pooling后的图像将作为下一层的输入,再次进行一轮学习过程,本方法总共需要进行如此的三轮学习过程。
在特征提取阶段,包括如下步骤:
5)将viper_train输入训练完毕的cnn模型,得到关于每张图像5个分块共500张特征图,其中,每个分块有100张特征图;
6)将特征图转化为一维分块特征向量,方法是将每张特征图的二维矩阵按照每列相接的方式转化为一维特征向量,再将每个分块中100个特征向量相连接成为一个一维分块特征向量。
在层次属性学习阶段,包括如下步骤:
7)设计行人层次属性,行人层次属性包括粗粒度属性{a1,a2,…ak,…an}和细粒度属性{a1,a2,…al,…am},n为粗粒度属性个数,m为细粒度属性个数;具体实施中,n=17,m=16,17个粗粒度属性包括:“带帽”、“非长发”、“长发”、“长袖”、“短袖”、“无袖”、“穿外套”、“上衣花纹”、“有logo”、“长下装”、“短下装”、“下装花纹”、“背包”、“手拿物”、“凉鞋”、“单鞋”、“靴子”;16个细粒度属性包括:“秃头”、“短发”、“盘发”、“齐肩”、“披头”、“马尾”、“非条纹”、“密集条纹”、“稀疏条纹”、“长裤”、“长裙”、“双肩包”、“单肩包”、“手提包”、“手拿物品”、“行李箱”;粗粒度和细粒度属性对应关系如图3所示:粗粒度属性“非长发”对应细粒度属性(“秃头”、“短发”、“盘发”),粗粒度属性“长发”对应细粒度属性(“齐肩”、“披头”、“马尾”),粗粒度属性“上衣花纹”对应细粒度属性(“非条纹”、“密集条纹”、“稀疏条纹”),粗粒度属性“长下装”对应细粒度属性(“长裤”、“长裙”),粗粒度属性“背包”对应细粒度属性(“双肩包”、“单肩包”),粗粒度属性“手拿物”对应细粒度属性(“手提包”、“手拿物品”、“行李箱”)。
8)对viper数据集中的每一个行人图像进行属性标注,将行人图像所具有的属性标注为1,不具有的属性标注为0;
9)为每一个属性分配一个支持向量机svm作为属性分类器,并利用分块特征向量和相应的属性标注对每一个属性分类器进行训练,得到训练完毕的属性分类器;
在分类识别阶段,包括如下步骤:
10)根据属性标注,统计viper_test数据集中每一个行人的属性类别映射概率,得到属性类别映射关系表,其中,属性类别映射关系表中粗粒度属性对应的概率为
11)设定层次属性的权值,粗粒度属性权值用w1表示,细粒度属性权值用w2表示;本发明具体实施例中,当缺乏细粒度属性描述时,w1=1,w2=0;当存在细粒度属性描述时,w1=0.6,w2=0.4;
12)将viper_test中样本xt输入训练完毕的cnn得到对应的分块特征图,再将每个分块中的所有特征图转化一维分块特征向量,并输入训练完毕的各属性分类器,得到样本具有粗粒度属性ak的后验概率p(ak|xt)和细粒度属性al的后验概率p(al|xt),结合属性类别映射关系表,通过贝叶斯公式得到在粗粒度属性下类别yj关于样本xt的后验概率p1(yj|xt)和在细粒度属性下类别yj关于样本xt的后验概率p2(yj|xt),其中,样本xt为viper_test测试样本{x1,x2,...,xt,...,xp}中的第t张分块行人图像,贝叶斯公式为:
13)计算样本关于类别的最终后验概率,计算公式为:
p(yj|xt)=w1p1(yj|xt)+w2p2(yj|xt);
14)选择最大概率对应的类别作为样本的识别类别,选择公式为:
- 还没有人留言评论。精彩留言会获得点赞!