一种基于深度学习模型的车牌字符整体识别方法与流程
本发明涉及智能交通系统和数字安防领域,具体涉及一种基于深度学习模型的车牌字符整体识别方法。
背景技术:
车牌识别是智能交通系统(its)领域的基础部分和重要环节,对智能交通系统的其他部分如车标识别、车身颜色分析、车型分析、卡口检测、电子警察,及其他交通事件相关模块的处理好坏有着重要的影响。
传统的车牌识别系统,大致分为车牌检测、车牌定位、字符分割及字符识别等几个子模块。其中车牌号码识别环节,字符分割部分严重依赖前面定位的结果,其所使用的二值化方法对于一些特殊情况如阴阳牌,车牌光线不均衡等效果不佳。字符识别则采用传统浅层分类器的单个字符识别方式,虽在正常条件下还好,但是全天候的稳定性及相似字符的可区分性难以保证。
因此,传统的车牌识别系统存在以下问题:
1、传统方法需要对车牌进行精确定位再分割,依赖性强,容易分割错误;
2、传统方法在光线差、分辨率低、污损、倾斜大等情况的稳定性不好;
3、单个模型难以保证较好的识别指标。
技术实现要素:
本发明针对现有技术存在的问题,提出一种基于深度学习模型的车牌字符整体识别方法。
本发明的一种基于深度学习模型的车牌字符整体识别方法,包括如下步骤:
步骤a:进行车辆检测,获得目标车辆,由目标车辆确定整个车牌检测区域;
步骤b:对所述整个车牌检测区域进行检测获得车牌区域;
步骤c:通过深度神经网络模型对所述车牌区域的车牌号码进行整体识别,所述深度神经网络模型包括依次连接的4个卷积层和2个全连接层,最后一个全连接层包含七个分支,各分支分别对应车牌号码上的汉字、字母、数字或标识。
优选地,所述深度神经网络模型的所述第一分支对应汉字,具有58个输出;所述第二分支对应英文字母,具有26个输出,所述第三至第六分支对应数字和字母,分别具有36个输出,第七分支对应字母、数字和特殊牌标识,具有41个输出。
优选地,所述每个分支的各输出的结果为该输出项的概率,每个分支的各输出的概率之和为1。
优选地,步骤c之后还包括步骤d,采用多个模型集成的方式,综合得到识别结果:
步骤d1:统计相同车牌号码识别结果的数目并计算其可信度平均值;
步骤d2:按照数目多少从大到小排序,如果不同车牌号码的数目相同的,则按其可信度从高到低排序;
步骤d3:选择可信度最高的车牌号码为识别结果。
优选地,步骤f中,采用3个模型集成的方式。
本发明具有如下有益效果:
1、本发明引入深度学习模型,提高车牌识别率;
2、本发明克服传统车牌识别方法需要进行车牌字符分割所带来的依赖性和结果不确定性所导致的误识别问题;
3、本发明车牌识别在各种特殊情况下的鲁棒性。
附图说明
图1为本发明的基于深度学习模型的车牌字符整体识别方法的流程示意图。
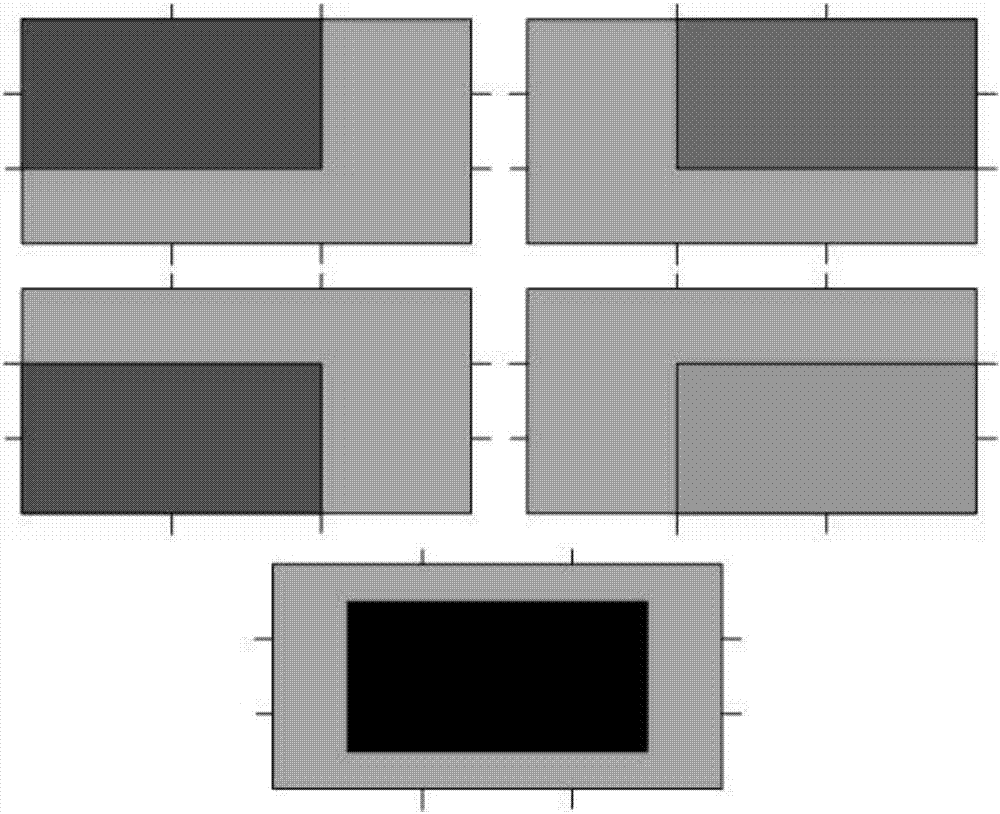
图2为本发明的车牌检测5块子区域划分示意图。
图3为本发明的车牌检测深度网络结构图。
图4为本发明的子块车牌检测结果示意图。
图5为本发明的车牌字符整体识别深度网络结构示意图。
图6为本发明的车牌字符整体识别结果示意图。
具体实施方式
下面通过实施例对本发明作进一步说明,其目的仅在于更好地理解本发明的研究内容而非限制本发明的保护范围。
参考图1,本发明的一种基于深度学习、特别是卷积神经网络的车牌字符整体识别方法,包括如下步骤a~c。
步骤a:进行车辆检测,获得目标车辆,由目标车辆确定整个车牌检测区域。
车辆检测的目的是在整个相机视野领域检测到真正的车辆区域,排除背景区域及干扰的部分,从而减少误检,提高车牌检测的准确率,并且降低后续处理的时间消耗。本发明使用现有的常规车辆检测的方法,例如可以使用运动分析技术,建立背景模型,提取前景,也可以使用车辆检测器进行静态检测,并进行目标关联。或者两者结合,得到真正感兴趣的目标车辆。
步骤b:对所述整个车牌检测区域进行检测获得车牌区域,包括如下子步骤。
步骤b1:将所述车牌检测区域划分成n个小块,各小块之间部分重叠。
传统车牌检测技术,采用滑动窗的方式,在车牌检测区域内遍历各子窗口,寻找边缘丰富、梯度能量变化较大,类似车牌特征的区域,作为车牌候选区域。这样做的缺点是耗时多,检测效率不高。本发明采用基于分块的车牌区域回归技术进行车牌检测。具体做法是,将整个车牌检测区域划分成少数几个小块,一个较佳的实施例为5个小块,小块之间部分重叠。
具体地,车牌检测区域r(w,h)可以由车辆检测区域得到,或者来自人工或程序确定的感兴趣区域,并将其划分成若干小块,分别并行地进行检测,再将结果进行融合。本发明的分块方案采用5块(2×2+1)法,或者9宫格(3×3),更细颗粒度则没有必要,尤以5块法为主。5块划分如图2所示,各子块位置分别为:车牌检测区域的左上、右上、左下、右下、中央即位于车牌检测区域r的正中心,每子块的宽高分别为w*2/3、h*2/3。子块之间彼此重叠,是为了处理车牌目标位于子块边界的情形。
步骤b2:对每个小块使用深度学习模型拟合得到大致的车牌区域,同时获得该区域是真车牌的可信度。
具体地,对每个子块使用适当的深度学习模型,拟合得到大致的车牌区域,深度学习模型同时给出该区域是真车牌的可信度。可信度的数值范围从0~1,0表示真车牌的可信度为0,1表示100%确信为真车牌。
综合考虑效果和效率,本发明采用的深度神经网络模型是如图3所示的卷积神经网络(cnn)。在该卷积神经网络中,包括依次连接的3个卷积层(conv)和3个全连接层(ip),最后一个全连接层包含两个分支,一个分支为预测的车牌矩形的左上角和右下角坐标,使用l2损失,另一个分支为真假车牌的分类,使用softmaxloss损失。每个卷积层后跟一个池化层(maxpool)(图3中未显示池化层)。conv层和ip层的参数见图3中所示,对于卷积层来说,数字表示featuremap(即输入图像)及卷积核的宽高、通道数,对ip层来说,数字表示其神经元数目。
如第一卷积层(如图①→②)的五个参数(30,30,3,3,3),表示该层的输入图像的宽高都为30,并有3个通道(r、g、b),该层卷积操作核大小为3×3。第二卷积层(如图②→③)中的三个参数(10,3,3),表示该层有10个通道(即前一层的featuremap输出为10),该层卷积操作核的大小为3×3。第三卷积层(如图③→④)中的三个参数(20,2,2),表示该层有20个通道,该层卷积操作核的大小为2×2,最后获得通道数为40的层(如④所示)。⑤表示第一全连接层,神经元数目为120,⑥表示第二全连接层,神经元数目为60,⑦表示第三全连接层即最后一个连接层,具有两个分支,一个分支的神经元数目为4,另一个分支的为2。网络中conv层stride(步长)为1,pool层核大小为2×2,stride为2。除最后一个ip层外,每个conv和ip层都使用relu激活函数。
如上所述,通过图3所示的网络即可实现车牌位置拟合和可信度计算功能,即输入一个原图,经过该网络(通过训练得到)计算,在最后的输出层即可得到可信度值和车牌矩形区域左上、右下角坐标。
步骤b3:根据所述车牌区域的位置与可信度的关系,融合得到最终的车牌区域。这样一来,无论检测区域大小是多少,无论尺度和横纵比变化数,由于分块数是固定的,车牌检测的时间复杂度是常数,即o(1)。这里使用深度模型回归车牌的目的,是为了利用深度学习的自我学习的优势,得到在各种情况下稳定的深度特征。
上面提到的车牌检测结果的融合,融合方法包括max,avg等策略。
具体地,本步骤进一步包括:
步骤b31:对结果按真车牌的可信度从大到小进行排序;
步骤b32:对排序结果做二值化操作,即可信度与选定的阈值进行比较,若高于阈值则认为是真车牌,否则认为是假车牌;
步骤b33:在真车牌集合中获得车牌候选区域,如果真车牌集合为空则该目标车辆区域判定为无车牌。其中,通过max策略在真车牌集合中,选择可信度最高的检测结果为车牌候选区域;或者通过avg策略在真车牌集合的车牌检测位置根据其可信度进行加权平均获得车牌候选区域。
在检测到车牌候选区域后还可以进行车牌位置优化步骤,采用深度学习模型对车牌区域进行优化,获得优化后的车牌区域。优化同样采用深度学习模型,可使用一般简单网络即可,此处不特别说明。
通过上述方法对整个车牌检测区域进行检测可以获得车牌候选区域,当然本领域技术人员也可以用其他公知的方法获得车牌候选区域,以提供给下一步的车牌字符整体识别。
下面介绍步骤c:通过深度网络结构对所述车牌区域的车牌号码进行整体识别。
无论是传统车牌识别技术,还是当前基于深度学习的一些车牌识别系统,基本上都要对车牌字符进行分割之后再逐个字符识别,由于受到定位精确性和车牌表面成像质量的影响,字符分割的效果往往难以令人满意,从而大大降低了最终的车牌号码识别率。
基于深度学习模型的整体字符识别技术已经有一些实际应用,如google的工程师应用深度学习模型识别街景中的连续数字,牛津大学的研究者使用cnn网络识别自然场景中的英文字符序列。本发明将深度学习模型的整体字符识别方法应用于智能交通场景,可减轻其对传统字符分割稳定性要求大的特点,也可以利用深度学习强大的特征学习能力,提高包括特殊情形下的车牌号码识别率和鲁棒性。
本发明用于车牌号码识别的深度网络结构如图5所示(类似于图3),较佳的实施例包括依次连接的四个conv层和2个ip层。样本输入大小为64×64,3通道,这里的样本即为上面的步骤获得的车牌区域的图像。conv1核大小5×5,featuremap输出为64,conv2核大小5×5,featuremap输出为128,conv3核大小3×3,featuremap输出为256,conv4核大小3×3,featuremap输出为512,所有conv层stride为1,使用relu激活,每个conv层后跟一个maxpool层,核大小2×2,stride为2。ip1的神经元数目(或称为输出)为4096,使用relu激活,ip2层有7个分支,其神经元数目分别为58,26,36,36,36,36,41,使用softmaxloss损失。
这里ip2采用7个分支,分别对应车牌上的汉字、字母、数字和标识等。例如,第一分支对应汉字,包括沪、皖、赣等31个省份简称以及一些特殊牌“军”、“空”、“海”等共58个输出,第二分支对应英文字母,共26个输出,第三~六分支对应“数字+字母”,因此共36个输出,第七分支对应“字母+数字+特殊牌标识”(特殊牌标识包括挂车标识等),共41个输出。每个分支的各个输出的结果均是该输出项的概率,每个分支的各个输出的概率之和为1,取概率最大的项作为该分支的最终输出。例如,第一分支具有58个输出项,例如“沪”的概率为98%,“皖”的概率为1%,“赣”的概率为1%,其他输出项为0,那么这里最大概率为98%的“沪”,则该第一分支的输出即为“沪”。通过将前述获得的车牌区域图像作为深度神经网络的输入,通过计算,则可整体地识别获得车牌号码。
除了自定义的cnn,一些常用的网络如googlenet、vggnet等也可以应用于本发明方法。
同时,为了进一步提高识别率,本发明的上述步骤c之后还可以包括步骤d,采用多个模型集成的方式,综合得到识别结果,较佳地,可以采用3个模型集成的方式,具体包括:
步骤d1:统计相同车牌号码识别结果的数目并计算其可信度平均值;
步骤d2:按照数目多少从大到小排序,如果不同车牌号码的数目相同的,则按其可信度从高到低排序;
步骤d3:选择可信度最高的车牌号码为识别结果。
例如有5个识别结果,沪a12345,沪a12345,沪a72345,沪a72345,沪a72344,可信度分别为0.998,0.996,0.945,0.941,0.9,则排序结果为:沪a12345,沪a72345,沪a72344,可信度值为:0.997,0.943,0.9,最后取沪a12345为预测结果。
显然,本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求书范。
- 还没有人留言评论。精彩留言会获得点赞!