集群数据同步方法及装置与流程
本发明涉及数据库领域,特别涉及一种集群数据同步方法及装置。
背景技术:
mysql是一个关系型数据库管理系统,galeracluster(集群)是一套基于同步复制的多主mysql集群解决方案。该集群中的节点通过同步实时更新,实现所有节点里的数据一致性。当有节点加入galeracluster的时候目前有两种同步方式,一种是ist(incrementalstatetransfer,增量同步方式),其特点是轻量和快速,另一种是sst,即statesnapshottransfer,sst是全量同步方式,即同步全部数据,其特点是数据量大和缓慢。
当节点加入galeracluster时,会先判断该节点的seqno(sequencenumber,事务序列号)是否存在于galeracluster的gcache文件中,若在galeracluster的gcache文件中存在该seqno则开启ist,将集群中的数据同步到此节点,如果不存在则开启sst,将galeracluster中所有的数据全量同步到此节点。
当新加入的节点与galeracluster数据相差并不是很多,但gcache(集群缓存文件)文件中又没有相应的seqno时,则只能通过sst方式进行全量同步,不仅同步时间会较长,而且会产生阻塞,最终会影响galeracluster正常运行。
因此,如果加入galeracluster中的目标节点,在gcache文件中没有该目标节点的事务序列号seqno的时候,即使该目标节点中只落后了一部分数据,也只能进行全量同步,由于全量同步的数据量较大,导致该目标节点在集群数据同步所需的时间会比较多。
技术实现要素:
为了解决相关技术中存在的集群数据同步时耗时较多的问题,本发明提供了一种集群数据同步方法及装置。
一种集群数据同步方法,所述方法包括:
获取目标节点的事务序列号;
在所述目标集群的数据日志文件中获取所述事务序列号关联的数据位置;
根据所述数据日志文件中的数据位置,将所述数据日志文件中从所述数据位置开始的数据导入所述目标节点;
响应所述数据的导入,将所述目标节点加入所述目标集群。
一种集群数据同步装置,所述装置包括:
事务序列号获取模块,用于获取目标节点的事务序列号;
数据位置获取模块,用于在所述目标集群的数据日志文件中获取所述事务序列号关联的数据位置;
数据导入模块,用于根据所述数据日志文件中的数据位置,将所述数据日志文件中从所述数据位置开始的数据导入所述目标节点;
集群加入模块,用于响应所述数据的导入,将所述目标节点加入所述目标集群。
本发明的实施例提供的技术方案可以包括以下有益效果:
本发明通过获取目标节点的事务序列号,在目标集群的数据日志文件中获取该事务序列号关联的数据位置,根据该数据日志文件中的数据位置,将该数据日志文件中从该数据位置开始的数据导入目标节点,并响应所述数据的导入将数据导入完成后,将该目标节点加入该目标集群。通过事务序列号在目标集群的数据日志文件中获取该事务序列号关联的数据位置,并依据该数据位置,将数据导入该目标节点,最后将目标节点加入到目标集群,实现数据的增量同步,从而有效减少了数据同步所需的时间。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并于说明书一起用于解释本发明的原理。
图1是根据本发明所涉及的实施环境的示意图;
图2是根据一示例性实施例示出的一种集群数据同步方法的流程图;
图3是根据图2对应实施例示出的对步骤s210的细节进行描述的流程图;
图4是根据图2对应实施例示出的对步骤s230的细节进行描述的流程图;
图5是根据图2对应实施例示出的对步骤s250的细节进行描述的流程图;
图6是根据一示例性实施例示出的一种集群数据同步装置的框图;
图7是根据图6对应实施例示出的对事务序列号获取模块的细节进行描述的框图;
图8是根据图6对应实施例示出的对数据位置获取模块的细节进行描述的框图;
图9是根据图6对应实施例示出的对数据导入模块的细节进行描述的框图。
具体实施方式
这里将详细地对示例性实施例执行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
图1是根据本发明所涉及的实施环境的示意图。该实施环境包括:集群110、节点130以及集群中的一个以上的节点,如图1中的节点120、节点121、节点122。
其中,节点120、节点121、节点122是集群中的节点,在加入集群之前,是单独的数据库节点,可以将一个或多个单独的数据库节点组建或加入集群,节点130是数据库节点,节点130也可以通过集群的方式启动。
如图1所示的的实施环境可以是有一个集群110,还存在一个有一部分集群数据的节点130,需要将节点130跟集群110的数据进行增量同步。
集群110与节点130之间的关联方式,包括有线或无线的网络关联方式,以及二者之间往来的数据关联方式,具体的关联方式不受本实施例的限制。
集群110与集群110中的节点之间的关联方式,包括有线或无线的网络关联方式,以及二者之间往来的数据关联方式,具体的关联方式不受本实施例的限制。
节点130与集群110中的节点之间的关联方式,包括有线或无线的网络关联方式,以及二者之间往来的数据关联方式,具体的关联方式不受本实施例的限制。
节点120,节点121,节点122之间的关联方式,包括有线或无线的网络关联方式,以及二者之间往来的数据关联方式,具体的关联方式不受本实施例的限制。
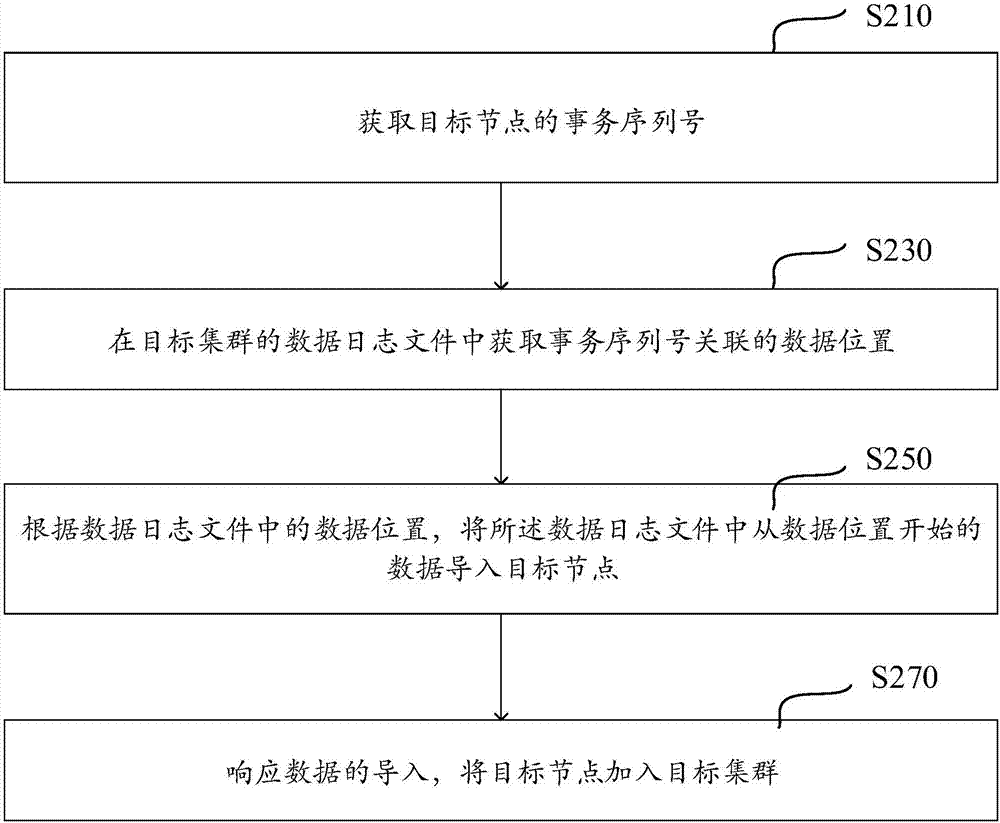
图2是根据一示例性实施例示出的一种集群数据同步方法的流程图。如图2所示,该集群数据同步方法可以包括以下步骤。
在步骤s210中,获取目标节点的事务序列号。
其中,目标节点,是指待同步的数据库节点,并且此时并未加入集群中,即该数据库节点里的数据落后于集群中节点里的数据,如图1中的节点130。事务序列号是指数据库节点执行完最后一个事务时的编号,数据库节点在执行事务的过程中,根据事务执行的完成情况调整事务序列号。该事务序列号可以是根据事务的执行情况自动计数的,例如,每执行完一个事务,事务序列号自动加1。
因为每个节点都会有自己的事务序列号,而且每个序列号在数据日志文件中,都会会通过分布式序列号进行记载,并且,与这个分布式序列号对应的内容包括该事务序列号对应的事务执行完成时所关联的数据位置。该数据位置就是进行数据导入的开始位置。只有获取到该数据位置,才能知道数据从哪里开始导入。
例如,因为容量需求变化或集群故障等原因,节点130从集群110中下线后,此时,从该节点130中获取到的事务序列号就是一个固定的数值,比如50096。在集群110中任何一个节点里的数据日志文件里,会以分布式序列号的方式记载节点130的事务序列号,即在数据日志文件中的,会有分布是序列号为50096的内容。找到该分布式序列号,也就找到了相关联的数据位置。因此,就得到了数据开始导入时的数据位置。
获取目标节点的事务序列号的方式,既可以向目标节点发送事务序列号获取命令,也可以通过集群恢复命令来获取。一般情况下,可以在向目标节点发送事务序列号获取命令后,接收不到返回的事务序列号或者返回的事务序列号为错误标识时,再通过集群恢复命令来获取,该集群恢复命令可以是mysqld_safe--wsrep-recover。
在步骤s230中,在目标集群的数据日志文件中获取事务序列号关联的数据位置。
其中,目标集群,是指处于运行状态中的集群,此时,集群会确保集群中节点里的数据一致性,因此该集群中任何一个节点中的数据是一致的,如图1的集群110。在此情况下,节点120,节点121,节点122的数据是一致的。
数据日志文件,是指根据数据库处理事务而生成的相关文件,一般也称为二进制日志文件,例如binlog文件。数据日志文件的内容中,存在有分布式序列号,例如xid=50096,每一个分布式序列号对应的都是一个事务完成时的事务序列号,而且每一个分布式序列号还对应有一个事务完成时所关联的数据位置,据此即可确定下一个事务开始的位置。
数据的存储一般有开始位置和结束位置,在本方案中,数据位置是指下一个事务的开始位置,即当前事务的结束位置。
在步骤s250中,根据数据日志文件中的数据位置,将所述数据日志文件中从数据位置开始的数据导入目标节点。
根据步骤s230,获取事务序列号关联的数据位置后,从该数据位置开始对数据库进行相应的操作。
其中,本方案中,是将数据日志文件中的数据从该数据位置开始导入到目标节点,即将所述数据日志文件中从数据位置开始的数据导入目标节点。
即,根据数据导入命令,从数据位置开始将数据日志文件的数据依次导入目标节点。例如,获取到事务序列号50096关联的数据位置是399,那么从位置399开始,将数据日志文件中的数据全部导入到目标节点。
进一步的,当一个集群中节点中里的数据日志文件为两个以上时,即存在数个数据日志文件时,可以根据数据日志文件的特点,如生成的时间、生成的文件名称等,将所有的数据日志文件按一定的顺序形成数据日志文件队列。如根据时间顺序或者根据文件名顺序,然后找到事务序列号所在的数据日志文件,再根据步骤s230和s250将数据日志文件中从数据位置开始的数据导入目标节点,在该数据日志文件处理完成后,再将数据日志文件队列排在该数据日志文件后面的所有数据日志文件的数据全部导入目标节点。
例如,节点121中存在213个日志文件,文件名为hs-bin.0001,hs-bin.0002,hs-bin.0003,按此顺序到最后一个日志文件hs-bin.0213。节点130的事务序列号为50096。根据文件名称的特点将这213个数据日志文件形成一个数据日志文件队列,然后在这个数据日志文件队列中的数据日志文件中找到事务序列号50096,比如最后发现该事务序列号50096在hs-bin.0111这个数据日志文件中,再根据步骤s230确定该事务序列号在hs-bin.0111这个数据日志文件中关联的数据位置,最后根据步骤s250将hs-bin.0111这个数据日志文件中的数据从该关联的数据位置开始导入节点130中。导入完成后,再将数据日志文件中排在hs-bin.0111这个数据日志文件以后的数据日志文件,即文件名为hs-bin.0112,hs-bin.0113,hs-bin.0114按此顺序依次到hs-bin.0213的数据全部导入节点130中。
通过由此可以确定事务序列号在hs-bin.0111这个数据日志文件中。当然还可以采用其它的方法或者算法等来确定该事务序列号50096存在hs-bin.0111这个数据日志文件中。
在步骤s270中,响应数据的导入,将目标节点加入所述目标集群。
对步骤s250导入的数据进行响应,直到数据导入完成。如图所示,节点130在数据导入完成后,此时即完成了数据的同步,即可将该节点130加入集群110中。
利用如上所述的过程,获取目标节点的事务序列号,通过该事务序列号获取到与该事务序列号关联的数据位置,从该数据位置开始将数据导入该目标节点,响应数据导入,直到数据导入结束后将该目标节点加入目标集群中。即当集群节点中的集群缓存文件(例如,gcache文件)中不存在该事务序列号的情况下,无需进行数据全量同步,只需增量同步即可。由此,便实现了将目标节点与目标集群中的数据快速同步,从而有效减少了数据同步所需的时间。
图3是根据图2对应实施例示出的对步骤s210的细节进行描述的流程图。该步骤s210,如图3所示,可以包括以下步骤。
在步骤s211中,向目标节点发送事务序列号获取命令。
其中,事务序列号获取命令可以是获取集群状态文件中(如grastate.dat文件)的事务序列号命令。
在步骤s213中,接收目标节点响应事务序列号获取命令而返回的事务序列号。
目标节点收到事务序列号获取命令后,会执行该命令并进行响应,将执行该命令获取的事务序列号返回给向该目标节点发送事务序列号获取命令的一方。
图4是根据图2对应实施例示出的对步骤s230的细节进行描述的流程图。该步骤s230,如图4所示,可以包括以下步骤。
在步骤s231中,获取目标集群的数据日志文件中的分布式序列号。
其中,数据日志文件中包括多项内容,有数据日志文件名称,开始位置,事务类型,集群节点编号,结束位置,备注信息等。
数据库每执行一个事务,数据日志文件中就会产生一个分布式序列号。因此,每个数据日志文件中,可能存在多个分布式序列号。通过向数据日志文件发送分布式序列号查询命令,即可获取该目标集群的数据日志文件中的分布式序列号。
当事务执行完成时,会生成相应的事务序列号,并且根据执行该事务的节点,生成相应的数据日志文件。该数据日志文件的内容可以包括该执行该事务的节点编号,分布式序列号,并且分布式序列号跟该事务序列号是相同的。
在步骤s233中,针对每一分布式序列号,将分布式序列号与所述事务序列号进行对比,如果一致,则将分布式序列号对应的数据位置确定为事务序列号关联的数据位置。
将步骤s231获取的分布式序列号逐一与事务序列号进行对比,如果出现一致时,即可将分布式序列号对应的数据位置确定为事务序列号关联的数据位置,即代表找到了该事务序列号关联的数据位置。
进一步的,当一个集群中节点里的数据日志文件为两个以上,即存在多个数据日志文件时。首先每个数据日志文件生成的时间会不同,即先生成的数据日志文件时间要早于后生成的数据日志文件,其次,每个数据日志文件生成的名字也会不同,一般都是按数字编号的顺序命名,再者每个数据日志文件的大小也有可能会不同。
即一个集群中节点里存在多个数据日志文件时,可以根据这些数据日志文件本身的特点,通过文件名或者时间的方式,形成数据日志文件队列,再根据队里中的数据日志文件中的分布式序列号来确定事务序列号所在的数据日志文件,然后在该数据日志文件中通过分布式序列号找到该事务序列号关联的位置。
由此,在多个数据日志文件的情况下,可以根据如上特点,将所有的数据日志文件按一定的顺序形成数据日志文件队列。如根据时间顺序或者根据文件名顺序,通过遍历该数据日志文件队列的数据日志文件得到每个数据日志文件的第一个分布式序列号,然后根据这些分布式序列号得到事务序列号所在的数据日志文件。在找到该日志文件后,再通过步骤s231和s233最终找到该事务序列号关联的数据位置。
例如,节点121中存在213个日志文件,文件名为hs-bin.0001,hs-bin.0002,hs-bin.0003,按此顺序到最后一个日志文件hs-bin.0213。节点130的事务序列号为50096,hs-bin.0001的第一个分布式序列号1,hs-bin.0002的第一个分布式序列号315,hs-bin.0003的第一个分布式序列号768,然后hs-bin.0111的第一个分布式序列号49999,hs-bin.0112的第一个分布式序列号50398,hs-bin.0213的第一个分布式序列号110398。因为49999<50096<50398,由此可以确定事务序列号在hs-bin.0111这个数据日志文件中。当然还可以采用其它的方法或者算法等来确定该事务序列号50096存在hs-bin.0111这个数据日志文件中。然后通过步骤s231获取hs-bin.0111这个数据日志文件中的分布式序列号,根据s233将这些分布式序列号逐一与事务序列号进行对比,并最终找到该事务序列号关联的数据位置。
图5是根据图2对应实施例示出的对步骤s250的细节进行描述的流程图。该步骤s250,如图5所示,可以包括以下步骤。
在步骤s251中,将目标节点启动为新集群。
其中,该新集群相比目标集群而言,存在一些区别,如集群的名称,配置等会有区别。将目标节点启动为新集群后,对于目标集群与新集群中的数据同步而言,兼容性和稳定性更高。
进一步的,还可以将目标节点中数据库的对外服务权限关闭。为了减少集群中节点中,产生新的实时数据,从而影响对数据同步,可以关闭目标节点的对外服务权限,这样在离线状态下,进行数据增量同步,相当如做了隔离处理,减少了数据的干扰,从而更加提升了兼容性和稳定性。
在步骤s253中,将数据日志文件中从数据位置开始的数据,导入新集群中的目标节点。
即将目标集群中节点里的数据日志文件里的数据,导入到新集群中的目标节点中,其中,数据导入的时候,以数据位置为起始位置。
其中,新集群是指相比集群110而言存在名称等信息不同的集群,即,节点130采用集群110以外的集群名称或配置信息通过集群方式启动。数据库的对外服务权限是对外执行数据事务处理的权限,关闭此权限说明停止数据库事务的处理,即关闭对外服务权限后不会产生新的数据事务,数据库中的数据不再发生变化。通过这两项操作有利于减少数据同步时出现错误,相应的减少了集群数据同步所需的时间。
下述为本发明装置实施例,可以用于执行本发明上述集群数据同步方法实施例。对于本发明装置实施例中未披露的细节,请参照本发明集群数据同步方法实施例。
图6是根据一示例性实施例示出的一种集群数据同步装置的框图。该集群数据同步装置可以用于图1所示的实施环境中,执行图2所示的集群数据同步方法的全部或部分步骤。如图6所示,该集群数据同步装置300包括但不限于:事务序列号获取模块310、数据位置获取模块330、数据导入模块350和集群加入模块370。
事务序列号获取模块310,用于获取目标节点的事务序列号。
数据位置获取模块330,用于在目标集群的数据日志文件中获取事务序列号关联的数据位置。
数据导入模块350,用于根据数据日志文件中的数据位置,将数据日志文件中从数据位置开始的数据导入目标节点。
集群加入模块370,用于响应数据的导入,将目标节点加入目标集群。
图7是根据图6对应实施例示出的对事务序列号获取模块的细节进行描述的框图。如图7所示,该事务序列号获取模块310包括但不限于:发送单元311和接收单元313。
发送单元311,用于向目标节点发送事务序列号获取命令。
接收单元313,用于接收目标节点响应事务序列号获取命令而返回的事务序列号。
图8是根据图6对应实施例示出的对数据位置获取模块的细节进行描述的框图。如图8所示,该数据位置获取模块330包括但不限于:获取单元331和对比单元333。
获取单元331,用于获取目标集群的数据日志文件中的分布式序列号。
对比单元333,用于针对每一分布式序列号,将分布式序列号与事务序列号进行对比,如果一致,则将分布式序列号对应的数据位置确定为事务序列号关联的数据位置。
图9是根据图6对应实施例示出的对数据导入模块的细节进行描述的框图。如图9所示,该数据导入模块350包括但不限于:启动单元351和导入单元353。
启动单元351,用于将目标节点启动为新集群。
导入单元353,用于将数据日志文件中从数据位置开始的数据,导入新集群中的目标节点。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围执行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!