一种外包空间数据库中反最远邻居验证方法与流程
本发明属于时空数据管理和基于位置服务的结合领域,是一种适合在外包空间数据库中客户端基于位置服务进行查询与验证的算法。
背景技术:
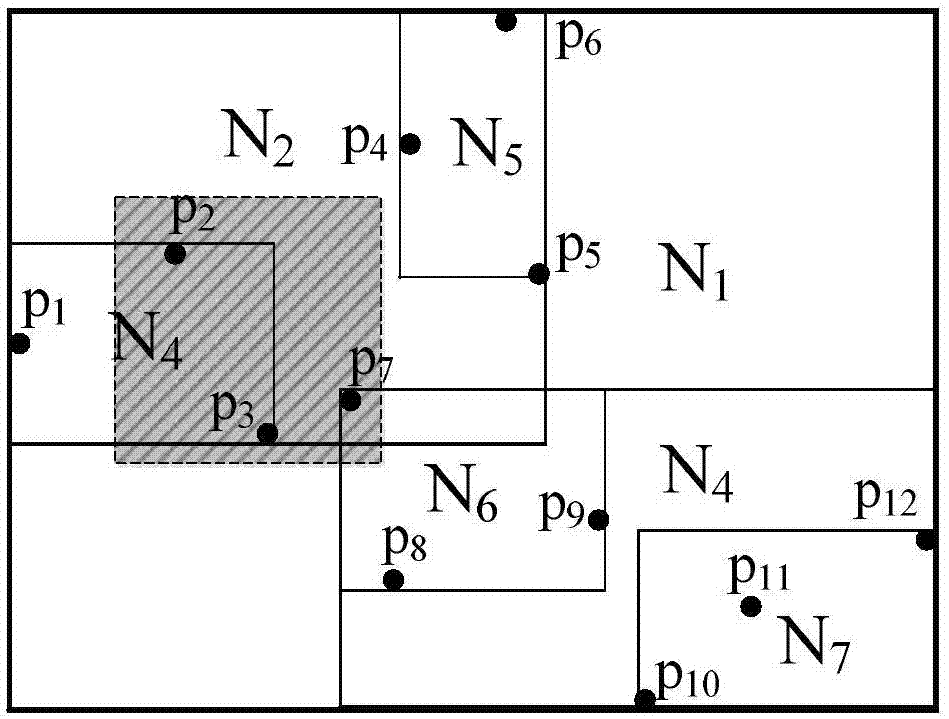
:现如今,人类对于基于位置服务(lbs)的需求越来越强烈,如地图导航,寻找离自己最近的k个咖啡店等(即:最近邻查询knn);司机发出一条寻找最近的k个加油站的请求,而加油站利用监测系统,反向筛选出k个最近邻的司机,若该司机能成为k个之一,该加油站将提前准备为其提供更优质服务(即:反最近邻查询rknn);在军事演习或者实战中,军事部署往往会忽略最远的敌人最易攻击的特点,由于距离远,士兵警戒防线低,红方和蓝方总指挥根据敌我双方的整体位置进行调兵遣将,假设红方选派一名士兵攻击蓝方最远的k个敌人,那么该红方士兵需要成为蓝方攻击的最远k个目标之一才能进行有效伏击(即:该红方士兵是蓝方的rkfn),反之,则按兵不动,听从指示,利用这种rkfn策略在一定程度上能起到出奇制胜的作战效果。其中rkfn查询验证不仅在军事演习或者实战中,在大型场景游戏等方面也有重要应用。这在劳民伤财的任务中,能起到预防和保护作用,倘若在军事战争中,因为错误信息,指挥长发出了错误的决断,而导致战争的失败,这是一笔惨痛的代价;倘若在大型场景游戏中,战友获取错误信息,导致对决的惨败,将要承担被队友指责或者损失金钱等后果,所以这种安全且正确的验证机制在一些应用环境中是不可缺少的。因为人们的需求不同,所以有不同的查询请求(knn、rknn、skyline、rfn、rkfn等),验证机制保障了用户获取正确结果的权益,让用户有最终的决定权。其中,范围查询验证技术和knn查询验证技术相对成熟,rknn查询验证、skyline查询验证技术也相继提出,但是rkfn查询验证技术至今空白,本发明的目的就是弥补在外包空间数据库中基于位置服务的rkfn查询验证的空缺,并提出了一种可行的验证方法,使得用户能快速地获取到正确结果,为此,我们需要考虑到下面三大问题:第一,如何选取适合rkfn查询请求的索引结构众所周知,随着信息时代的快速发展,数据量爆发式地增长,利用传统的处理方式来检索出有价值的信息,是耗时且成本高昂的,因此,我们针对rkfn查询请求方式,应采用哪种索引结构来加快请求的处理,是我们首要考虑的问题。第二,针对rkfn查询请求,客户端采用何种验证方法来避免用户获取错误结果用户获取错误信息的来源主要有传输过程中数据丢失、黑客攻击服务器并篡改其数据等,用户被动的接受信息,可能致使用户在错误信息的引导下偏离目标,或者提供的并非最佳抵达目的地的方案,针对这种情况,客户端应如何设计验证方法来达到验证结果的目的,这是我们需要考虑的必要问题。第三,如何减少传输代价、客户端验证和计算等代价来降低成本花销根据knn查询验证的思想,服务器端生成的验证对象(vo)供客户端来验证结果的可靠性,然后通过knn方法对vo中的所有对象进行计算,最后客户端判断服务器提供的结果和客户端对vo的计算结果是否完全一致,如果一致则接受结果,否则,拒绝接受。rkfn查询验证总体思想与knn查询验证的思想基本一致,在这个过程中,我们要考虑到客户端存储能力是有限的这一硬性指标,可能成为接受vo的瓶颈,而且当客户端通过vo来验证结果时,验证的代价和计算代价等又直接受vo大小影响,所以我们将主导传输和验证等代价的vo尽量缩减,设计出一种优化vo的方法,使得用户尽可能少的消耗流量,这是我们需要考虑的重要问题。在现代社会,人们对基于位置服务的需求不断加大,高效地处理海量数据成为研究者们的热门课题,由于rkfn查询验证技术具有很大的商业和军事价值,所以我们设计算法要兼顾到上面的三大方面,进而设计出一个适用于外包数据库反最远邻居算法就显得尤为重要。技术实现要素:为了填补外包空间数据库中反最远邻居验证技术的空白,本发明提供一种基于mr-tree验证索引结构和最新发布的反最远邻居查询方法的验证技术。本发明采用的技术方案:一种适合外包空间数据库中反最远邻居验证方法,其特征在于,外包数据过程工,使得第三方服务器和客户端之间不存在安全信任关系,客户端通过mr-tree索引机制对数据来源的可靠性进行正确地检验,整个处理流程分为第三方服务器端处理和客户端验证两个部分,包括以下步骤:第三方服务器端处理:步骤1:预处理高维空间数据,建立mr-tree索引机制;步骤2:离线构建k-depthcontour并为处于k-depthcontour内部的无效数据对象生成fvo;步骤3:判断用户请求与k-depthcontour的所属关系;步骤4:利用influencedzone筛选出结果集,生成验证结果集的fvo;步骤5:第三方服务器发送其计算的结果集、uvo、fvo、uroot、froot、influencedzone;客户端验证:步骤6:uvo、fvo、uroot、froot逆向生成验证数据来源的正确性;步骤7:利用fvo验证influencedzone的正确性;步骤8:利用四象限测试法验证influencedzone为空;步骤9:验证结果集的正确性。步骤2:第一次对fvo做压缩处理,其具体操包括如下:预处理k-depthcontour及计算出k-depthcontour内部无效查询的验证对象;1)利用已有mr-tree技术和k-depthcontour生成算法,计算出外包空间数据的验证框架和基于所有数据的k-depthcontour,将空间中所有数据对象按照k-depthcontour划分;2)对于处在k-depthcontour上或者外部的数据对象,将其所在最小边界矩形内的所有对象有序地加载到fvo中,而处在k-depthcontour内部的最大矩形以实体形式有序地加载到fvo中;3)初步计算出k-depthcontour内部的无效查询的验证对象fvo。客户端验证结果集的核心依据,是influencedzone的形成,该influencedzone是对fvo进行了第二次压缩,该influencedzone构建思想将直接影响通信和验证等代价;所述步骤3中判断用户请求与k-depthcontour的所属关系如下;步骤3-1:采用shenluwang提出“efficientlycomputingreversekfurthestneighbors”的反最远邻居查询方法,当服务器接受到用户请求,首先判断该请求是否存在于k-depthcontour内部,若存在,则将相应k取值的无效查询fvo直接发送给客户端,客户端利用四象限测试法进行验证处理;若该请求不存在于k-depthcontour内部,则进行步骤3-2处理;步骤3-2:在mr-tree中检索出k-depthcontour上和外部的数据对象,将这些对象与请求对象进行半平面修剪,该技术保证了被修剪掉的区域经过至少k次修剪,形成最终的influencedzone;所述步骤4:以userset为数据集构建的mr-tree索引树中,进行influencedzone区域查询验证,若数据对象存在于influencedzone中,则将该数据对象加载到结果集中,同时将其所在的最小边界矩形中的所有数据对象有序地加载到uvo,将不存在于influencedzone内的最大矩形以实体的形式有序地加载到uvo中;所述步骤5:第三方服务器将最终计算出的结果集、uvo和fvo、uroot和froot、influencedzone发送给客户端;所述步骤6:客户端接受到服务器端发送来的信息,首先对uvo和fvo进行逆向操作,分别生成其对应的mr-tree的根的hash值,判断计算出的hash值和服务器端发送来的uroot和froot是否一致,如果完全一致,则进行后续操作,否则验证失败,拒绝接受当前服务器端发送来的所有数据信息。客户端验证influencedzone方式,所述步骤7利用fvo来检验influencedzone的边和顶点正确性,所述步骤8利用四象限测试法和fvo来验证influencedzone为空的情况,而客户端验证的核心技术就是对influencedzone的检验,其验证过程如下:在influencedzone存在的前提下,利用fvo来验证influencedzone是否正确;步骤7-1:验证influencedzone的边界点是否正确;influencedzone的边界点由非数据空间边界点组成或者由非数据空间边界点和数据空间边界点共同组成,因此,对于非数据空间边界点的验证用如下公式:而对于数据空间边界点的验证将采用下面的公式:这里,vi代表非数据空间边界点,vj代表数据空间边界点,表示圆上及外部区域,(vi,q)代表vi为圆心,vi到q的距离为半径形成的圆上及外部区域,dk代表fvo中的数据对象,mk代表fvo中的实体对象;如果influencedzone的边界点验证失败,则客户端将拒绝接受服务器端发送来的结果集;否则,将进行步骤7-2处理;步骤7-2:验证influencedzone的边是否正确;influencedzone边由查询请求q和fvo中某数据对象的中垂线构成的,或者可能外加部分数据空间边界线构成的;首先检验influencedzone边是否是q和fvo中某数据对象形成的中垂线,对于不是中垂线形成的边,进一步检验该边是不是数据空间的边界线,如果都不是,则验证失败,客户端拒收服务器端发送来的结果,否则,将继续验证influencedzone边;验证无数据空间边界顶点组成的边(ei)采用如下公式:而有数据空间边界顶点组成的边(ej)则采用下面公式进行检验:如果influencedzone通过了上述验证,则说明该influencedzone是正确的,客户端需要进行下一步结果集的检验;步骤8:influencedzone不存在,客户端将判断服务器端发来的信息的可靠性和正确性;对于influencedzone为空的情况有两种:一是查询请求处于在k-depthcontour内部,即为无效查询,二是查询请求处于k-depthcontour上或者外部,influencedzone为空是由于被修剪至空,这两种情况采用的思想一致;以查询请求q为原点,以查询请求q为原点,根据图13的四象限测试法的原理,划分数据空间为四个象限,统计fvo中数据对象分布在每个象限的数目,如果某个象限的数目超过k个,则对角线的象限被修剪,通过被修剪的象限中数据对象来修剪未被修剪的象限,如果整个数据空间被修剪掉,则说明服务器端发送来的信息是完全正确的,否则,验证失败,重新发送查询请求。步骤9结果集验证如下:验证结果集的正确性;由于结果集存在,则说明influencedzone一定存在,所以将influencedzone作为范围查询的区域,然后判断uvo中的数据对象是否存在于influencedzone区域中,存在的数据对象将标记下来,不存在于该区域的数据对象不做任何处理,而uvo中的实体对象是不应该相交于该区域的,若出现相交的情况,则验证失败,客户端拒收结果集,最后将客户端计算的结果信息和服务器端发来的结果集进行对比,如果一致,则接受该结果集信息,否则,拒收该结果集。本发明的优点是:该发明的实现涉及到众多技术的支持,首先是外包空间数据库承包的处理,该技术是信息发展和运行模式产物,特别是在云存储模型的提出,外包数据库的安全性受到威胁,但该技术能高效地处理众多用户请求;其次是mr-tree验证索引结构技术,该技术既保证了外包空间数据库的正确性,又能使得客户端对接收的结果的验证;然后是利用反最远邻居方法检索出满足条件的结果;最后,客户端利用本发明特有的方法验证influencedzone正确与否,在influencedzone正确的前提下,采用范围查询验证技术来检验最终结果的正确性。附图说明图1外包数据库以及第三方服务器和客户端交互框架。图2高维空间数据以r-tree进行数据分割形式。图3mr-tree验证索引结构。图4mr-tree叶子节点摘要的存储形式。图5mr-tree中间节点摘要的存储形式。图6生成k-depthcontour流程图。图72-depthcontour生成实例。图8基于2-depthcontour半平面修剪技术实例。图9-1是外包空间数据库中划分数据r-tree图。图9-2针对无效区域构建vo过程以及vo验证数据来源可靠性实例。图10-1丢失数据等因素导致influencedzone出错情况之一。图10-2丢失数据等因素导致influencedzone出错情况之二。图11验证influencedzone边界点实例。图12验证influencedzone边的实例。图13四象限测试法的原理。图14利用四象限测试influencedzone为空的实例。图15服务器处理和客户端验证以及两者间交互的过程。具体实施方式结合附图1-15对本发明做进一步描述。一种适合外包空间数据库中反最远邻居验证方法,第三方服务器首先利用k-depthcontour和半平面修剪技术生成influencedzone,该区域的构建可以缩减vo大小;然后采用高级图形学中射线法和多边形顶点排除方法来检索influencedzone内的结果;最后以influencedzone为基准,有序地加载相应对象到vo中,并将结果、influencedzone和vo发送到客户端。客户端接受到第三方服务器传来的信息,首先是验证vo的正确性,判断数据集来源是否可靠;然后是借助vo来检验influencedzone边界是否完整;最后将计算的结果和传来的结果进行比对,从而选择是否接受。外包空间数据库的思想是将数据库承包给第三方服务器,该服务器能满足一类用户的特定需求,比如用户出行所用的地图导航(百度地图,高德地图等),就是根据人们出行便捷的需求而设计的,使其具有专一化,特征化的性质,并能有效地响应用户请求,但是第三方服务器却不能保证用户获得的结果正确性,其缺乏安全性。面临海量数据地冲击,索引结构能加快查找速度,验证结构能保证信息的正确性,但是验证对象的大小会直接导致传输代价的增加,所以我们设计一种缩减vo大小的反最远邻居的验证技术。为了加快服务器处理数据,我们需要前期的预处理工作,考虑k-depthcontour的构建,可以提前处理,并存储到硬盘中,以备可以直接读取并使用,这样既可以直接判断出查询请求的有效性,又可以节省k-depthcontour构建所消耗的时间。请求若存在于k-depthcontour内部,即视为无效查询,可以预先计算出k-depthcontour的无效区域的vo,这样可以减少无效查询处理的时间,降低查询和计算的代价。一种适合外包空间数据库中反最远邻居验证方法,首先,对外包空间数据库中的数据构建mr-tree验证索引结构,该结构既可以加速检索请求,又可以为客户端验证提供依据;然后第三方服务器利用k-depthcontour和半平面修剪技术生成influencedzone,该区域可以缩减vo大小;接着采用高级图形学中射线法和多边形顶点排除方法来检索influencedzone内的结果;最后以influencedzone为基准,将存在于influencedzone中的对象所在最小边界矩形(mbr)内所有对象有序地加载到vo中,不存在于influencedzone中的最大矩形以实体形式有序地加载到vo中,并将结果、influencedzone和vo发送到客户端。客户端接受到第三方服务器传来的信息,首先是按照mr-tree结构的逆向生成树的思想来验证vo正确性,判断数据来源是否可靠;然后借助vo来检验influencedzone边界是否完整;最后将计算结果和传来结果进行对比。考虑传输等各方面花销代价,本发明设计并实现一种适合海量数据中反最远邻居验证的市场需求任务。外包空间数据库中反最远邻居验证的实现最主要是如何形成优良的验证对象,好的验证对象在整个验证过程中起到至关重要的作用,缩减验证对象的大小也是本发明研究的核心问题。本发明的内容是实现反最远邻居验证技术,最主要的内容是计算influencedzone和验证influencedzone。本发明分成两个级别——第三方服务器级和客户端级,第三方服务器需要实现三个方面——预处理验证索引树mr-tree、离线预处理k-depthcontour、生成influencedzone。客户端验证的实现需要处理三个方面——验证vo是否正确、利用vo验证influencedzone、通过正确的influencedzone验证结果集的正确性。其中核心算法是如何用vo来验证influencedzone的过程。接下来本人将验证的整体流程和发明的主要内容做如下说明。步骤1:预处理高维空间数据,建立mr-tree索引机制。步骤1-1:针对高维空间数据库中所有数据(如:facilityset,该集合的验证对象用fvo表示)按照r-tree构建原则进行数据分割,然后对r-tree划分的数据进行hash加密处理,形成mr-tree验证索引树,将mr-tree存储起来,便于后期检索,mr-tree索引结构参看图2和图3,fvo的形式参见图4和图5。步骤1-2:预处理用户需要获得的空间数据库中的数据集(如:userset),构建mr-tree索引结构,然后把以该结构组织的数据进行存储。步骤2:利用mr-tree中所有数据对象构建出k-depthcontour,在k-depthcontour上或者外部的数据对象,将其所在最小边界矩形内的所有对象加载到fvo中,而在k-depthcontour内部的最大矩形以实体形式有序地加载到fvo中,k-depthcontour外部区域按照范围查询验证思想进行处理,处于k-depthcontour内部的请求则生成无效查询的验证对象fvo。因为考虑到人们的现实需求,一般k的取值较小,那么在k-depthcontour上或者外围的数据对象相比内部的数据对象要少很多,这样利于缩减fvo,从而降低通信代价等。步骤3:判断用户请求与k-depthcontour的所属关系。步骤3-1:服务器接受用户请求,首先判断该请求是否存在于k-depthcontour内部,若存在,则将相应k取值的无效查询fvo直接发送给客户端。若该请求不存在于k-depthcontour内部,则进行步骤3-2处理。步骤3-2:在mr-tree中检索出k-depthcontour上和外部的数据对象,将这些对象与请求对象进行半平面修剪,该技术保证了被修剪掉的区域经过至少k次修剪,形成最终的influencedzone。这里用到的半平面修剪技术参见图8。步骤4:以userset为数据集构建的mr-tree索引树中,进行influencedzone区域查询验证,如果数据对象存在于influencedzone,则将该数据对象加载到结果集中,同时将其所在的最小边界矩形中的所有数据对象有序地加载到uvo(区分facilityset的验证对象fvo),将不存在于influencedzone内的最大矩形以实体的形式有序地加载到uvo中。步骤5:第三方服务器将最终计算出的结果集、uvo和fvo、uroot(uroot:userset的mr-tree树根root的hash值)和froot(froot:facilityset的mr-tree树根root的hash值)、influencedzone发送给客户端。客户端在接受到服务器端发送来的结果集、uvo和fvo、influencedzone之后,将做进一步的验证处理,从而有权选择是否接受当前的结果信息。具体步骤如下:步骤6:首先对uvo和fvo进行逆向操作,分别生成其对应的mr-tree的根的hash值,判断计算出的hash值和服务器端发送来的uroot和froot是否一致,如果完全一致,则进行步骤7操作,否则验证失败,拒绝接受当前服务器端发送来的所有数据信息。步骤7:利用fvo来验证influencedzone是否正确,若influencedzone不存在,即不存在满足条件的结果,将跳过步骤7,直接进入步骤8。步骤7-1:验证influencedzone的边界点是否正确。influencedzone的边界点由非数据空间边界点组成或者由非数据空间边界点和数据空间边界点共同组成,因此,对于非数据空间边界点的验证用如下公式:而对于数据空间边界点的验证将采用下面的公式:这里,vi代表非数据空间边界点,vj代表数据空间边界点,表示圆上及外部区域,(vi,q)代表vi为圆心,vi到q的距离为半径形成的圆上及外部区域,dk代表fvo中的数据对象,mk代表fvo中的实体对象。如果influencedzone的边界点验证失败,则客户端将有权直接拒绝服务器端发送来的结果集;否则,将进行步骤7-2处理。步骤7-2:验证influencedzone的边是否正确。influencedzone边由查询请求q和fvo中某数据对象的中垂线构成的,或者可能外加部分数据空间边界线构成的。首先检验influencedzone边是否是q和fvo中某数据对象形成的中垂线,对于不是中垂线形成的边,进一步检验该边是不是数据空间的边界线,如果都不是,则验证失败,客户端拒收服务器端发送来的结果,否则,将继续验证influencedzone边。验证无数据空间边界顶点组成的边(ei)采用如下公式:而有数据空间边界顶点组成的边(ej)则采用下面公式进行检验:经过上述对influencedzone边的成功验证,接下来我们将进行最后一步处理——结果集的检验,如果结果集验证成功,则客户端将会接受该结果,否则拒绝接受它,其中步骤9说明了如何验证结果集。步骤8:influencedzone不存在,客户端将判断服务器端发来的信息的可靠性和正确性。对于influencedzone为空的情况有两种:一是查询请求处于在k-depthcontour内部,即为无效查询,二是查询请求处于k-depthcontour上或者外部,influencedzone为空是由于被修剪至空,这两种情况采用的思想一致。根据图13的四象限测试法的原理,以查询请求q为原点,将数据空间划分为四个象限,统计fvo中数据对象分布在每个象限的数目,如果某个象限的数目超过k个(包括k),则对角线的象限被修剪,通过被修剪的象限中数据对象来修剪未被修剪的象限,如果整个数据空间被修剪掉,则说明服务器端发送来的信息是可靠而正确的,否则,验证失败,重新发送查询请求。步骤9:验证结果集的正确性。因为有结果集存在,则说明influencedzone一定存在,所以将influencedzone作为范围查询的区域,然后判断uvo中的数据对象是否存在于influencedzone区域中,存在的数据对象将标记下来,不存在于该区域的数据对象不做处理,而uvo中的实体对象是不应该相交于该区域的,若出现相交的情况,则验证失败,客户端拒收结果集,最后将客户端计算的结果信息和服务器端发来的结果集进行对比,如果一致,则接受该结果集信息,否则,拒收该结果集。服务器和客户端的处理过程以及彼此交互的过程参见图15。经过上述步骤的处理,客户端验证结果的任务已全部实现。k-depthcontour的构建是第一步缩减fvo关键,influencedzone概念的实现是对fvo做进一步缩小。这样就使得通信代价,验证代价以及存储代价等都得到有效地降低。本发明的一个示例,采用图9中mr-tree验证索引结构的示例进行说明。其中将图9中的数据对象作为一个小的数据集进行反最远邻居验证技术的测试用例。本发明方法的具体实施步骤如下:步骤1:预处理高维空间数据,建立mr-tree索引机制(已有技术支撑)。针对facilityset(这里userset和facilityset为同一个数据集合)中的所有数据对象,按照图9的mr-tree构建原理进行数据分割并按照该组织结构存储数据到磁盘中,便于后期可以加快检索查询速度,叶子节点的存储除了自身的信息外,还有保存其hash值,而中间节点则保存了其孩子节点信息和孩子节点的摘要信息。步骤2:利用mr-tree中所有数据对象构建出2-depthcontour,其构建的具体过程参看图7。将2-depthcontour上或者外部的数据对象所在最小边界矩形内的所有对象加载到fvo中,图9-1中展示了满足要求的数据对象有f4,f5,f3,f12,f1,f2,而在2-depthcontour内部的最大矩形以实体形式有序地加载到fvo中,图9-2中的2-depthcontour内部的最大矩形为n6,其中vo中的对象是有顺序的,vo形成过程说明了其顺序性。数据对象处于2-depthcontour内部,即视为无效查询,因此,我们可以提前生成2-depthcontour无效区域的验证对象fvo。步骤3:判断用户请求q(这里将f5作为查询请求q)与2-depthcontour的所属关系。步骤3-1:利用高级图形学的知识可以判断出一个点是否存在于多边形内部。如果q属于2-depthcontour内部,则服务器不做任何处理,直接将预处理的2-depthcontour无效查询的验证对象fvo发送给客户端。否则,进行步骤3-2处理。步骤3-2:将2-depthcontour无效查询的fvo中的所有数据对象与请求q进行半平面修剪,该半平面修剪过程参看图8,图8中展示了每个区域块被修剪的次数,区域块被修剪的次数不小于k(这里k=2),则该区域块将被修剪掉,对于未被修剪掉的区域块,其共同形成的区域即为influencedzone,图8中influencedzone是由那些被修剪次数不超过2的区域块共同组成,即为1或者0的区域块构成。步骤4:以userset为数据集构建的mr-tree索引树中,进行influencedzone区域查询验证,该处理过程与范围查询验证过程一致,从mr-tree的根实体开始查找,判断该矩形是否完全被包含在influencedzone中,如果被包含在influencedzone,则将该矩形中包含的所有数据对象加载到uvo;如果不完全包含,则指向该矩形包含的孩子节点,将所有孩子节点再与influencedzone进行相交与否的判断。以此类推,直到叶子层。根据图8和图9,uvo=[[n4,[f12,f3]][[f1,f2][f6,f7,f8,f9,f10,f11]]],结果集result中包含数据对象为{f2,f3,f6,f10,f11},由于数据集过小,体现不出该算法的优势,因为现实中可能使用比较有代表性的两个数据集,即使使用的相同的数据集,通过influencedzone可以修剪掉的一半还多的空间区域,这里通过较小的数据集进行算法的可靠性、有效性和完整性的测试。步骤5:第三方服务器将最终计算出的结果集{f2,f3,f6,f10,f11}、uvo=[[n4,[f12,f3]][[f1,f2][f6,f7,f8,f9,f10,f11]]]和fvo=[[[f4,f5][f3,f12]][n6,[f1,f2]]]、uroot和froot、influencedzone发送给客户端。客户端在接受到服务器端发送来的结果集、uvo和fvo、influencedzone之后,将做进一步的验证处理,从而有权选择是否接受当前的结果信息。客户端验证结果集正确性的实现步骤如下:步骤6:首先对uvo和fvo进行逆向操作,分别生成其对应的mr-tree的根hash值,判断计算出的hash值和服务器端发送来的uroot和froot是否一致,如果完全一致,则进行步骤7操作;否则,验证失败,拒绝呈现给用户。图9-1展示了vo的逆向生成mr-tree根的hash值过程,计算出的根植为n1的hash值,再与froot比较,判断是否相等,相等则说明服务器端传来的facilityset的fvo中的所有数据以及实体都是可靠的。uvo的验证操作与vo的验证操作相同。步骤7:利用fvo来验证influencedzone是否完整,若influencedzone不存在,即不存在满足条件的结果,将跳过步骤7,直接进入步骤8。步骤7-1:验证influencedzone的边界点是否正确。图10-1图中的influencedzone缺失了一部分△pc1c2,图10-2图中influencedzone缺失一部分△c4c5c6。通过实验,先检验influencedzone边界点是否在正确,利用其相关公式。对于非数据空间边界点的验证用如下公式:而对于数据空间边界点的验证将采用下面的公式:这里,vi代表非数据空间边界点,vj代表数据空间边界点,表示圆上及外部区域,(vi,q)代表vi为圆心,vi到q的距离为半径形成的圆上及外部区域,dk代表fvo中的数据对象,mk代表fvo中的实体对象。当influencedzone区域是正确时,我们通过以下表格进行influencedzone的边界点的验证说明。图10显示出influencedzone中边界点出现错误的情况,边界点的验证原理参看图11,我们依然采用表格的形式进行influencedzone边界点的验证说明,表1展现了influencedzone边界点的验证过程,这样既直观,又可以清楚地展现出客户端验证边界点的操作流程。表1:验证influencedzone边界点的形式化表示针对图10-1图中influencedzone边界点出错的验证处理,一旦发现边界点错误,直接退出,验证失败,客户端拒绝接受服务器端发送的结果集。否则,将进行步骤7-2处理。步骤7-2:验证influencedzone的边是否正确。influencedzone边由查询请求q和fvo中数据对象的中垂线构成的,或者可能外加部分数据空间边界线构成的。首先,以influencedzone边作为中垂线,计算出q关于中垂线对称的点,如果该点是fvo中的数据对象,这只能说明通过粗粒度的计算,该计算过程如表2,经过表2的计算,姑且认为该边正确,我们需要进行第二步细粒度的验证计算,计算过程如表3,确保该边最终的正确。表2:利用中垂线原理进行粗粒度地验证influencedzone边influencedzone边vo中存在数据对象空间边界线操作c1c2f3nextc2c3f4nextc3c4f2nextc4c5f3nextc5c6f1nextc6c7f2nextc7c8√nextc8c9√nextc9c1√correctinfluencedzone边在通过中垂线思想的检验之后,需要继续验证influencedzone边的正确性。我们采用向量测试法,在靠近influencedzone边界点(除了由数据空间点)上,沿着经过该点的两个方向上,任取一点,判断这些点是否有满足条件的,一旦发现,立即终止验证,客户端将拒接呈现结果信息给用户。对influencedzone边的验证分为两个公式进行,同时采用表格的形式展现。验证无数据空间边界顶点组成的边(ei)采用如下公式:而有数据空间边界顶点组成的边(ej)则采用下面公式进行检验:针对图10-2的情况,将会缺少边c4c5和边c5c6,增加一条边c4c6,参照图12检验原理进行验证处理,具体的处理情况如表3。表3:采用向量测试法验证influencedzone边这种向量法的验证代价看上去很大,但是相比服务器端用半平面修剪技术的计算量还是要少很多,因为半平面修剪的要标记每个区域块被修剪的次数,这对客户端的计算能力和存储能力来说,都是相当大的考验,所以,向量法的计算代价是客户端能够接受的。经过上述对influencedzone边的成功验证,接下来我们将进行最后一步处理,即检验结果集的正确性,如果结果集验证成功,客户端会把结果信息反馈给用户,否则拒绝该结果集,结果集的验证实现过程参看步骤9。步骤8:influencedzone不存在,客户端将判断服务器端发来的信息的可靠性和正确性。具体实现的例子参看图14,在图14中,以q为查询点,将数据空间划分为a、b、c、d四个象限,a象限中包含fvo中数据对象为1个,b象限中包含fvo中数据对象为1个,c象限中包含fvo中数据对象为2个,d象限中包含fvo中数据对象为2个,则c、d象限中的数据对象将a、b象限区域修剪掉;然后利用a、b象限中的数据对象f4、f7修剪掉了象限d;最后利用f4、f7和象限d中的数据对象f1共同修剪掉象限c,致使整个数据空间被修剪,进而服务器端发送来的信息是正确的,否则,验证失败,重新发送查询请求。步骤9:验证结果集的正确性。因为有结果集存在,则说明influencedzone一定存在,所以将influencedzone作为范围查询的区域,然后判断uvo=[[n4,[f12,f3]][[f1,f2][f6,f7,f8,f9,f10,f11]]]中的数据对象哪些处于influencedzone区域中,即验证f1,f2,f3,f6,f7,f8,f9,f10,f11,f12哪些处于influencedzone内部,参看图8,处于influencedzone中的数据对象的集合为result_after{f2,f3,f6,f10,f11},接着判断uvo中所有实体对象是否相交于influencedzone,图8显示了n4与influencedzone没有交集,验证实体对象成功。最后对比结果集result和result_after中的数据是否完全一致,一旦发现两个集合不相同,则验证失败,这里result和result_after集合完全相同,则验证成功,客户端可以将接受的结果信息反馈给用户查看,为用户提供有价值信息。中英文对照说明如下:mr-tree(merkler-tree):merkleb-tree和r*-tree的结合形式lbs(location-basedservice):基于位置服务vo(verificationobject):验证对象fvo(verificationobjectoffacilityset):生成facilityset的验证对象froot:针对facilityset构建的mr-tree的根节点信息uvo(verificationobjectofuserset):生成userset的验证对象uroot:针对userset构建的mr-tree的根节点信息ads(authenticateddatastructure):验证数据结构mbr(minimumboundingrectangle):最小边界矩形knn(knearestneighbor):k最近邻rknn(reverseknearestneighbor):反向k最近邻rfn(reversefurthestneighbors):反向最远邻居rkfn(reversekfurthestneighbors):反向k最远邻influencedzone:受影响区域,该区域是用来验证结果集的正确性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1