数据分类的方法和装置与流程
本公开涉及数据处理领域,具体地,涉及一种数据分类的方法和装置。
背景技术:
风能作为最具规模开发潜力的可再生新能源,近年来发展十分迅速,但是,当风力发电机的某些部件发生异常时,使得风力发电机的实际发电量无法达到目标发电量(即风力发电厂给风力发电机下达的发电量),从而造成限功率。
为了解决这种情况,可以通过采集风力发电机的工作数据,并通过已知的限功率数据和非限功率数据对采集的工作数据进行分类,以确定该工作数据是造成限功率的限功率数据还是未造成限功率的非限功率数据,并根据分类结果确定会造成限功率的工作数据,从而调整风力发电机的工作数据,以避免限功率的发生。现有的分类方法包括获取未确定分类结果的待分类数据以及已知分类结果的数据分类样本(即限功率数据和非限功率数据),并将数据分类样本代入svm(supportvectormachine,支持向量机)模型中进行训练得到训练后的分类模型,通过该训练后的分类模型对待分类数据进行分类得到初始分类结果,为了提高初始分类结果的准确率,进一步采用tsvm(transductivesupportvectormachine,直推支持向量机)方法根据预先为该待分类数据设置的分类权重对初始分类结果不断进行迭代,直至迭代后得到的分类结果对应的目标分类权重满足预设分类终止条件,从而提高分类结果的准确率。
但是,在对初始分类结果不断迭代的过程中,当分类结果中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,会使得即使分类错误,该目标分类权重也会满足预设分类终止条件,例如,若采集到的风力发电机的工作数据共有100个,其中限功率数据包含的数据的第一数量为95个,非限功率数据包含的数据的第二数量为5个,那么即使将该另一类数据全部错误划分到该一类数据中,该数据分类结果的正确率也达到了95%(但实际分类是错误的),因此,采用上述分类方式在第一数量和第二数量相差较大时,数据分类结果仍然存在分类错误的数据。
技术实现要素:
为克服相关技术中存在的问题,本公开提供一种数据分类的方法和装置。
根据本公开实施例的第一方面,提供一种数据分类的方法,所述方法包括:获取待分类数据以及已知分类结果的数据分类样本;根据所述数据分类样本对所述待分类数据进行分类得到第一分类结果;获取所述数据分类样本的第一分类权重和所述待分类数据的第二分类权重,其中,所述第一分类权重表示所述数据分类样本的分类结果的置信度,所述第二分类权重表示所述待分类数据的分类结果的置信度;根据所述第二分类权重得到对应所述第一分类结果的第三分类权重和第四分类权重;根据所述第三分类权重和所述第四分类权重得到目标分类权重;在所述目标分类权重和所述第一分类权重满足预设分类终止条件时,确定分类完成。
可选地,所述第一分类结果包括第一类数据和第二类数据,在所述根据所述第二分类权重得到对应所述第一分类结果的第三分类权重和第四分类权重前,所述方法还包括:获取所述第一类数据包括的数据的第一数量和所述第二类数据包括的数据的第二数量;计算所述第一数量和所述第二数量之间的和值;所述根据所述第二分类权重得到对应所述第一分类结果的第三分类权重和第四分类权重包括:根据所述和值以及第二分类权重得到所述第一类数据对应的第三分类权重和所述第二类数据对应的第四分类权重。
可选地,所述根据所述和值以及第二分类权重得到所述第一类数据对应的第三分类权重和所述第二类数据对应的第四分类权重包括:
通过以下公式获取所述第三分类权重:
其中,
通过以下公式获取所述第四分类权重:
其中,
可选地,在所述根据所述第三分类权重和所述第四分类权重得到目标分类权重前,所述方法还包括:计算所述第一数量和所述第二数量之间的差值;确定所述差值是否大于或者等于0;所述根据所述第三分类权重和所述第四分类权重得到目标分类权重包括:在所述差值大于或者等于0时,通过以下公式得到所述目标分类权重:
其中,
在所述差值小于0时,通过以下公式得到所述目标分类权重:
其中,
可选地,所述预设分类终止条件包括:根据所述目标分类权重得到的第五分类权重大于或者等于所述第一分类权重,所述第五分类权重为所述目标分类权重与预设参数的乘积,所述预设参数为大于1的数值。
可选地,所述方法还包括:在所述目标分类权重和所述第一分类权重不满足所述预设分类终止条件时,将所述第五分类权重替换所述第二分类权重,并继续根据所述第五分类权重对所述第一分类结果进行重新分类得到第二分类结果,并根据所述第五分类权重得到对应所述第二分类结果的第六分类权重和第七分类权重,根据所述第六分类权重和所述第七分类权重得到新的目标分类权重,直至所述新的目标分类权重和所述第一分类权重满足预设分类终止条件。
根据本公开实施例的第二方面,提供一种数据分类的装置,所述装置包括:第一获取模块,用于获取待分类数据以及已知分类结果的数据分类样本;分类模块,用于根据所述数据分类样本对所述待分类数据进行分类得到第一分类结果;第二获取模块,用于获取所述数据分类样本的第一分类权重和所述待分类数据的第二分类权重,其中,所述第一分类权重表示所述数据分类样本的分类结果的置信度,所述第二分类权重表示所述待分类数据的分类结果的置信度;第三获取模块,用于根据所述第二分类权重得到对应所述第一分类结果的第三分类权重和第四分类权重;第四获取模块,用于根据所述第三分类权重和所述第四分类权重得到目标分类权重;第一确定模块,用于在所述目标分类权重和所述第一分类权重满足预设分类终止条件时,确定分类完成。
可选地,所述第一分类结果包括第一类数据和第二类数据,所述装置还包括:第五获取模块,用于获取所述第一类数据包括的数据的第一数量和所述第二类数据包括的数据的第二数量;第一计算模块,用于计算所述第一数量和所述第二数量之间的和值;所述第三获取模块,用于根据所述和值以及第二分类权重得到所述第一类数据对应的第三分类权重和所述第二类数据对应的第四分类权重。
可选地,所述第三获取模块,还用于通过以下公式获取所述第三分类权重:
其中,
通过以下公式获取所述第四分类权重:
其中,
可选地,所述装置还包括:第二计算模块,用于计算所述第一数量和所述第二数量之间的差值;第二确定模块,用于确定所述差值是否大于或者等于0;该第四获取模块,用于在所述差值大于或者等于0时,通过以下公式得到所述目标分类权重:
其中,
在所述差值小于0时,通过以下公式得到所述目标分类权重:
其中,
可选地,所述预设分类终止条件包括:根据所述目标分类权重得到的第五分类权重大于或者等于所述第一分类权重,所述第五分类权重为所述目标分类权重与预设参数的乘积,所述预设参数为大于1的数值。
可选地,所述装置还包括:循环模块,用于在所述目标分类权重和所述第一分类权重不满足所述预设分类终止条件时,将所述第五分类权重替换所述第二分类权重,并继续根据所述第五分类权重对所述第一分类结果进行重新分类得到第二分类结果,并根据所述第五分类权重得到对应所述第二分类结果的第六分类权重和第七分类权重,根据所述第六分类权重和所述第七分类权重得到新的目标分类权重,直至所述新的目标分类权重和所述第一分类权重满足预设分类终止条件。
通过上述技术方案,可以获取待分类数据以及已知分类结果的数据分类样本,根据该数据分类样本对该待分类数据进行分类得到第一分类结果,获取该数据分类样本的第一分类权重和该待分类数据的第二分类权重,根据该第二分类权重得到对应该第一分类结果的第三分类权重和第四分类权重,根据该第三分类权重和该第四分类权重得到目标分类权重;在该目标分类权重和该第一分类权重满足预设分类终止条件时,确定分类完成,这样,若在分类后的第一类数据包括的数据的第一数量与第二类数据包括的数据的第二数量相差较大时,可以通过第一类数据对应的第三分类权重和第二类数据对应的第四分类数据得到目标分类权重,从而均衡考虑了不同分类结果对目标分类权重的影响,避免了在分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,数量较多的数据在迭代过程中对目标分类权重影响较大,而造成在目标分类权重满足预设分类终止条件时,数据分类结果仍然存在分类错误的数据。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1是根据一示例性实施例示出的一种数据分类的方法的流程图;
图2是根据一示例性实施例示出的另一种数据分类的方法的流程图;
图3是根据一示例性实施例示出的一种数据分类的方法的示意图;
图4是根据一示例性实施例示出的一种基于数据分类的方法构建的决策树的示意图;
图5是根据一示例性实施例示出的第一种数据分类的装置的框图;
图6是根据一示例性实施例示出的第二种数据分类的装置的框图;
图7是根据一示例性实施例示出的第三种数据分类的装置的框图;
图8是根据一示例性实施例示出的第四种数据分类的装置的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
本公开可以应用于数据分类的场景,在该场景下,采集用于分类的工作数据,该用于分类的工作数据可以包括已知分类结果的数据分类样本和未确定分类结果的待分类数据,并根据数据分类样本对待分类数据进行分类,示例地,在风力发电领域中,数据分类样本包括已经确定是否会造成风力发电机限功率的工作数据,如限功率数据和非限功率数据,而待分类数据可以包括还未确定是否会造成风力发电机限功率的工作数据,例如,若采集的工作数据包括变频器发电机侧功率为1375w,发电机转矩为1240n·m,1号叶片角度为1.9,超速传感器转速为12.9m/s,发电机定子温度为86度,机舱气象站风速为8.9m/s,轮毂转速为12m/s,在确定该工作数据造成风力发电机限功率时,则确定该工作数据为限功率数据;又如,若采集的工作数据包括变频器发电机侧功率为1380w,发电机转矩为1260n·m,1号叶片角度为2.3,超速传感器转速为14m/s,发电机定子温度为82度,机舱气象站风速为8.6m/s,轮毂转速为11m/s,在确定该工作数据未造成风力发电机限功率时,则确定该工作数据为非限功率数据,上述变频器发电机侧功率、发电机转矩、1号叶片角度和超速传感器转速以及发电机定子温度、机舱气象站风速和轮毂转速即为数据特征,这样,当采集到待分类数据时,可通过上述限功率数据和非限功率数据对该待分类数据进行分类,从而确定该待分类数据为限功率数据,还是为非限功率数据,上述示例只是举例说明,本公开对此不作限定。
现有技术在数据分类的过程中,在数据初始分类完成后,通过待分类数据的分类权重(本公开中为第二分类权重)对初始分类结果(本公开中为第一分类结果)进行迭代,并得到迭代后的分类结果对应的目标分类权重,该目标分类权重表示对待分类数据的初始分类结果进行迭代后得到的分类结果的置信度,当目标分类权重满足预设分类终止条件时,确定迭代完成,进而确定分类完成,但是,当分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,则确定数量较多的数据的分类结果的可信程度更高,使得目标分类权重会偏向该数量较多的数据的分类结果,造成数量较少的数据的分类结果的可信程度对目标分类权重的影响较小,导致迭代完成后的分类结果的可信程度更接近数量较多的数据的分类结果的可信程度(即数量较多的数据的分类结果对目标分类权重的影响较大),从而使得在分类完成后,分类结果中仍然存在分类错误的数据。
为了解决上述问题,本公开提供一种数据分类的方法和装置,能够将第二分类权重按照初始分类结果进行划分得到第三分类权重和第四分类权重,并根据第三分类权重和第四分类权重得到目标分类权重,从而均衡考虑了不同分类结果对目标分类权重的影响,避免了在分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,数量较多的数据在迭代过程中对目标分类权重影响较大,而造成在目标分类权重满足预设分类终止条件时,数据分类结果仍然存在分类错误的数据。
下面通过具体实施例对本公开提供的数据分类方法进行详细说明。
图1是根据一示例性实施例示出的一种数据分类的方法的流程图,如图1所示,该方法包括以下步骤:
s101,获取待分类数据以及已知分类结果的数据分类样本。
示例地,以风力发电领域中的限功率数据和非限功率数据为例,当采集到的工作数据包括变频器发电机侧功率为1375w,发电机转矩为1240n·m,1号叶片角度为1.9,超速传感器转速为12.9m/s,发电机定子温度为86度,机舱气象站风速为8.9m/s,轮毂转速为12m/s时,若确定该工作数据会造成风力发电机限功率,则该工作数据为限功率数据(相当于数据分类样本);当采集到的工作数据包括变频器发电机侧功率为1380w,发电机转矩为1260n·m,1号叶片角度为2.3,超速传感器转速为14m/s,发电机定子温度为82度,机舱气象站风速为8.6m/s,轮毂转速为11m/s时,若确定该工作数据未造成风力发电机限功率,则该工作数据为非限功率数据(相当于数据分类样本);若采集到的工作数据为还未确定是否会造成风力发电机限功率的工作数据,则该工作数据为待分类数据。
s102,根据该数据分类样本对该待分类数据进行分类得到第一分类结果。
在本步骤中,将数据分类样本代入svm模型中进行训练得到训练后的分类模型,通过该训练后的分类模型对待分类数据进行初始分类得到第一分类结果,其中,svm模型是一种二类分类模型,其模型可以定义为空间上的间隔最大的线性分类器。
s103,获取该数据分类样本的第一分类权重和该待分类数据的第二分类权重。
在本步骤中,该第一分类权重与该第二分类权重都是预先设置的,该第一分类权重表示该数据分类样本的分类结果的置信度,该第二分类权重表示该待分类数据的分类结果的置信度,其中,该置信度表示数据的分类结果的可信程度,即该置信度越大,则该数据的分类结果越可信,反之,该置信度越小,则该数据的分类结果越不可信。
需要说明的是,由于该数据分类样本为已知分类结果的数据,则该数据分类样本的分类结果的可信程度较高,所以可以将第一分类权重设置的较大,而该待分类数据为未确定分类结果的数据,因此,该待分类数据的分类结果的可信程度较低,所以可以将该第二分类权重设置为一个小于该第一分类权重的较小值。
s104,根据该第二分类权重得到对应该第一分类结果的第三分类权重和第四分类权重。
其中,该第一分类结果可以包括第一类数据和第二类数据,在本步骤中,获取该第一类数据包括的数据的第一数量和该第二类数据包括的数据的第二数量,这样,可以按照该第一数量和该第二数量之间的比值将该第二分类权重分成该第一类数据对应的第三分类权重和该第二类数据对应的第四分类权重。
s105,根据该第三分类权重和该第四分类权重得到目标分类权重。
在本步骤中,若该第一数量与该第二数量之间的差值大于或者等于0,则根据预设权重函数调整该第三分类权重,该目标分类权重即为该第四分类权重与调整后的第三分类权重的和值;若该第一数量与该第二数量之间的差值小于0,则根据预设权重函数调整该第四分类权重,该目标分类权重即为该第三分类权重与调整后的第四分类权重的和值。
这样,通过调整数量较多的数据对应的分类权重,从而均衡不同分类结果对目标分类权重的影响,避免了数量较多的数据对目标分类权重的影响较大,造成在分类完成后,仍然存在分类错误的问题。
s106,在该目标分类权重和该第一分类权重满足预设分类终止条件时,确定分类完成。
采用上述方法,能够将第二分类权重按照初始分类结果进行划分得到第三分类权重和第四分类权重,并根据第三分类权重和第四分类权重得到目标分类权重,从而均衡考虑了不同分类结果对目标分类权重的影响,避免了在分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,数量较多的数据在迭代过程中对目标分类权重影响较大,而造成在目标分类权重满足预设分类终止条件时,数据分类结果仍然存在分类错误的数据。
图2是根据一示例性实施例示出的一种数据分类的方法的流程图,如图2所示,该方法包括以下步骤:
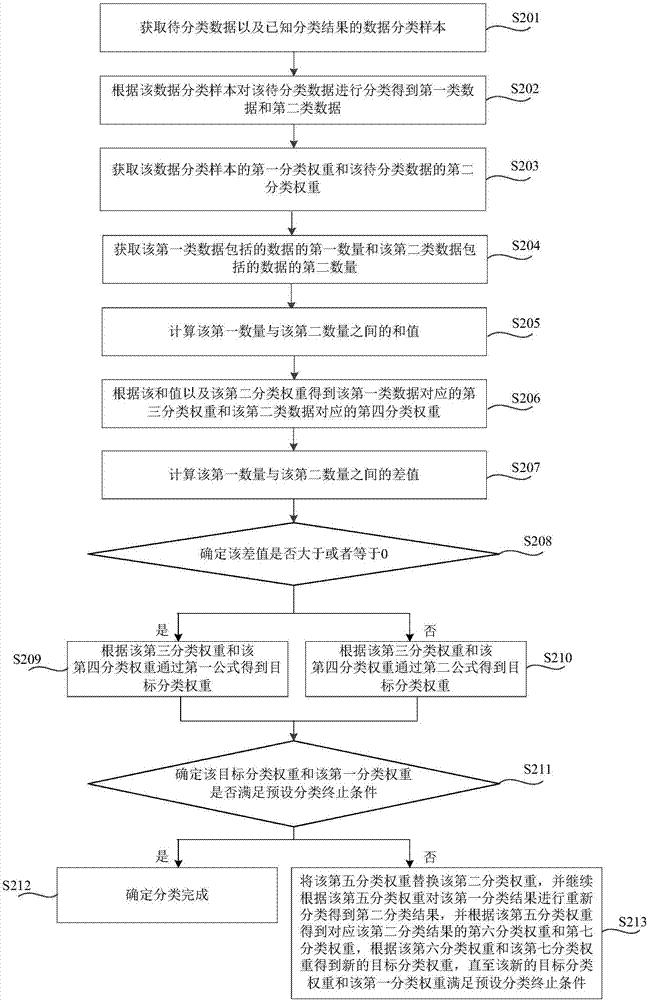
s201,获取待分类数据以及已知分类结果的数据分类样本。
其中,关于待分类数据和数据分类样本的说明可以参考上述实施例中步骤s101的说明,此处不再赘述。
s202,根据该数据分类样本对该待分类数据进行分类得到第一类数据和第二类数据。
在本步骤中,可以将数据分类样本代入svm模型中进行训练得到训练后的分类模型,通过该训练后的分类模型对待分类数据进行初始分类得到第一分类结果,即将该待分类数据分为第一类数据和第二类数据。
其中,svm模型是一种二类分类模型,其模型可以定义为空间上的间隔最大的线性分类器,这样,可以将该数据分类样本和该待分类数据映射到n维空间中,并根据该数据分类样本获取超平面,其中,该超平面的一边的数据分类样本为一类数据,该超平面的另一边的数据分类样本为另一类数据,并且该超平面将该待分类数据进行初始分类得到第一分类结果,若该待分类数据在该超平面的一边,则该待分类数据与该超平面的一边的数据分类样本为同一类数据,即为第一类数据,若该待分类数据在该超平面的另一边,则该待分类数据与该超平面的另一边的数据分类样本为同一类数据,即为第二类数据,继续以上述风力发电为例进行说明,如图3所示,加号表示限功率数据,减号表示非限功率数据,圆圈表示待分类数据,图3中的实线即为超平面,该超平面将该限功率数据和该非限功率数据划分到该实线的两边,实线左边为限功率数据,实线右边为非限功率数据,此时,位于实线左边的待分类数据,则初步认为是限功率数据,位于实线右边的待分类数据,则初步认为是非限功率数据。
为了方便描述,本公开实施例以将该数据分类样本和该待分类数据映射至二维平面为例进行说明,可以采用以下方式获取超平面:
首先,建立该超平面函数y(x)=wx+b,并假设该超平面为wx+b=0;其次,该假设的超平面将该数据分类样本进行分类,其中,超平面的一边的数据分类样本中存在一个距离该超平面最近的点a,则过点a存在一个平行该超平面的第一平面wx+b=1,同样,超平面的另一边的数据分类样本中存在一个距离该超平面最近的点b,则过点b存在一个平行该超平面的第二平面wx+b=-1;然后,获取该第一平面和该第二平面之间的距离公式,如d=2/||w||,d为该第一平面与该第二平面之间的距离,由于在svm模型中,d越大则第一分类结果越准确,因此,在假设d为最大值即||w||为最小值的情况下,可以根据该距离公式和该超平面的一边的数据分类样本的限制条件(wx+b≥1)以及该超平面的另一边的数据分类样本的限制条件(wx+b≤-1)利用拉格朗日乘子法求解得到w和b的值,从而确定该超平面。
另外,在获取到超平面后,将该待分类数据代入超平面函数y(x)=wx+b中,若y≥1,则确定该待分类数据与超平面的一边的数据分类样本为同一类数据,若y≤-1,则确定该待分类数据与超平面的另一边的数据分类样本为同一类数据。
s203,获取该数据分类样本的第一分类权重和该待分类数据的第二分类权重。
在本步骤中,该第一分类权重与该第二分类权重都是预先设置的,该第一分类权重表示该数据分类样本的分类结果的置信度,该第二分类权重表示该待分类数据的分类结果的置信度,其中,该置信度表示数据的分类结果的可信程度,即该置信度越大,则该数据的分类结果越可信,反之,该置信度越小,则该数据的分类结果越不可信。
需要说明的是,由于该数据分类样本为已知分类结果的数据,则该数据分类样本的分类结果的可信程度较高,所以可以将第一分类权重设置的较大,而该待分类数据为未确定分类结果的数据,因此,该待分类数据的分类结果的可信程度较低,所以可以将该第二分类权重设置为一个小于该第一分类权重的较小值。示例地,可以将该第二分类权重设置为该第一分类权重的百分之一,如该第一分类权重为100,则该第二分类权重为1,上述示例只是举例说明,本公开对此不作限定。
s204,获取该第一类数据包括的数据的第一数量和该第二类数据包括的数据的第二数量。
s205,计算该第一数量与该第二数量之间的和值。
s206,根据该和值以及该第二分类权重得到该第一类数据对应的第三分类权重和该第二类数据对应的第四分类权重。
其中,该第三分类权重可以用于表示该第一类数据的分类结果的置信度,该第四分类权重可以用于表示该第二类数据的分类结果的置信度。
在本步骤中,可以通过以下公式获取该第三分类权重:
其中,
可以通过以下公式获取该第四分类权重:
其中,
s207,计算该第一数量与该第二数量之间的差值。
s208,确定该差值是否大于或者等于0。
在该差值大于或者等于0时,执行步骤s209和步骤s211;
在该差值小于0时,执行步骤s210和步骤s211。
s209,根据该第三分类权重和第四分类权重通过第一公式得到目标分类权重。
其中,该第一公式包括:
其中,
s210,根据该第三分类权重和第四分类权重通过第二公式得到目标分类权重。
其中,该第二公式包括:
其中,
需要说明的是,随着该第一数量与该第二数量的差值的增大,该预设权重函数趋近于0,从而该目标分类权重比该第二分类权重小,由于预设分类终止条件与该目标分类权重相关,因此,若该目标分类权重与该第二分类权重相比减小时,则在后续步骤中对该第一分类结果进行迭代时需要经过多次迭代才可以满足迭代终止条件(相当于增加了迭代次数),从而提高了分类结果的准确率;随着该第一数量与该第二数量的差值的减小,该预设权重函数趋近于1,从而该目标分类权重与该第二分类权重近似相等,从而在后续步骤中对该第一分类结果进行迭代时迭代次数变化较小。
s211,确定该目标分类权重和该第一分类权重是否满足预设分类终止条件。
其中,该预设分类终止条件可以包括:根据该目标分类权重得到的第五分类权重大于或者等于该第一分类权重,该第五分类权重为该目标分类权重与预设参数的乘积,该预设参数为大于1的数值,若该预设参数越大,则该目标分类权重增长地越快,这样,减少了对该第一分类结果进行迭代的迭代次数,使得该目标分类权重可以快速满足预设分类终止条件,从而提高了分类效率,但是由于相应地减少了迭代次数,使得分类准确率较低;相反,若该预设参数越小,则在迭代的过程中,该目标分类权重增长地越慢,这样,增加了对该第一分类结果进行迭代的迭代次数,从而提高分类准确率,但由于相应地增加了迭代次数,从而降低了分类效率,因此,该预设参数可以兼顾分类效率和分类准确率进行设置,例如,该预设参数可以设置为2。
在确定该目标分类权重和该第一分类权重满足预设分类终止条件时,执行步骤s212;
在确定该目标分类权重和该第一分类权重不满足预设分类终止条件时,执行步骤s213。
s212,确定分类完成。
需要说明的是,在该分类完成后,可以根据该分类后的第一类数据和第二类数据构建分类模型,这样,当重新获取到一个新的待分类数据时,可以通过该分类模型对该新的待分类数据进行分类,从而得到该新的待分类数据的分类结果。
在一种可能的实现方式中,该分类模型可以是决策树,可以获取分类后的全部数据的数据特征,并通过获取的数据特征建立该决策树,在建立决策树的过程中,可以获取每个数据特征的信息熵,该信息熵越小,则对应的数据特征在决策树中的位置越靠近根节点。
示例地,仍然以上述风力发电为例进行说明,得到的第一类数据可以是限功率数据,得到的第二类数据可以是非限功率数据,例如,根据该限功率数据和非限功率数据获取的数据特征可以是变频器发电机侧功率、发电机转矩、1号叶片角度和超速传感器转速以及发电机定子温度、机舱气象站风速和轮毂转速,若通过计算得到该数据特征为变频器发电机侧功率的信息熵最小,则该数据特征为变频器发电机侧功率位于决策树的根节点,此时根据该变频器发电机侧功率的范围将该决策树分成两个分枝,示例地,将变频器发电机侧功率大于1373w和变频器发电机侧功率小于或者等于1373w作为两个分枝,此时在变频器发电机侧功率大于1373w时,继续计算满足变频器发电机侧功率大于1373w的工作数据对应的数据特征的信息熵,将最小信息熵对应的数据特征作为分枝“变频器发电机侧功率大于1373w”的决策节点,以此类推,可以示例性地构建出如图4所示的决策树,当然,上述示例只是举例说明,本公开对此不作限定。
这样,在获取到新的待分类数据后,可以根据该决策树确定该新的待分类数据的类别,例如,该新的待分类数据包括:变频器发电机侧功率1388w,发电机转矩1240n·m,1号叶片角度1.72,超速传感器转速14.5m/s,发电机定子温度86℃,机舱气象站风速9.41m/s和轮毂转速12.21m/s,则将该待分类数据代入决策树中,确定该变频器发电机侧功率1388w是否小于或者等于1373w,由于该变频器发电机侧功率1388w大于1373w,则如图4所示,该新的待分类数据被划分到该决策树的根节点为变频器发电机侧功率的右侧部分,继续确定发电机转矩1240n·m是否小于或者等于1255n·m,由于发电机转矩1240n·m小于1255n·m,则该待分类数据被划分到该决策节点为发电机转矩的左侧,依次类推,可以确定该新的待分类数据为限功率数据;又如,该新的待分类数据包括:变频器发电机侧功率1397w,发电机转矩1261n·m,1号叶片角度1.83,超速传感器转速13.5m/s,发电机定子温度84.5℃,机舱气象站风速7.91m/s和轮毂转速11.25m/s时,则将该待分类数据代入决策树中,确定该变频器发电机侧功率1397w是否小于或者等于1373w,由于该变频器发电机侧功率1397w大于1373w,则如图4所示,该新的待分类数据被划分到该决策树的根节点为变频器发电机侧功率的右侧部分,继续确定发电机转矩1261n·m是否小于或者等于1255n·m,由于发电机转矩1261n·m大于1255n·m,则该新的待分类数据被划分到该决策节点为发电机转矩的右侧,则确定该新的待分类数据为非限功率数据,上述示例只是举例说明,本公开对此不作限定。
此外,上述的分类是以分成两类为例进行的说明,也可以分成更多类,如三类,此时,仍然可以采用上述数据分类的方法将待分类数据分为第一数据和第二数据,其中该第一数据包括第一种类型数据,该第二数据包括除该第一种类型数据外的其他数据,并继续通过上述数据分类的方法将该第二数据进行分类,直至该第二数据按照不同类型数据全部分类完成。例如,对于疾病数据的类别包括健康数据,亚健康数据和疾病数据三类,则可以通过上述数据分类的方法将待分类数据分为第一数据(包括疾病数据)和第二数据(包括健康数据和亚健康数据),再继续通过数据分类的方法将该第二数据进行分类,分成第三数据(包括健康数据)和第四数据(包括亚健康数据),上述示例只是举例说明,本公开对此不作限定。
s213,将该第五分类权重替换该第二分类权重,并继续根据该第五分类权重对该第一分类结果进行重新分类得到第二分类结果,并根据该第五分类权重得到对应该第二分类结果的第六分类权重和第七分类权重,根据该第六分类权重和该第七分类权重得到新的目标分类权重,直至该新的目标分类权重和该第一分类权重满足预设分类终止条件。
在本步骤中,根据该第五分类权重对该第一分类结果进行重新分类得到第二分类结果的过程如下:
由上述步骤s202可知该第一分类结果是在只考虑该数据分类样本的情况下确定的该超平面,导致该第一分类结果可能不准确,因此,为了提高第一分类结果的准确率,可以引入松弛变量以减小初始分类导致的误差,此时,可以根据该松弛变量以及该待分类数据和该数据分类样本的限制条件重新获取新的超平面,示例地,以该待分类数据的限制条件为例进行说明,若该待分类数据经过初始分类后被划分到超平面的一边,则该超平面的一边的待分类数据的限制条件为:
当获取到该限制条件后,可以根据该第一分类权重和该第五分类权重以及该松弛变量得到目标函数
其中,根据该新的超平面将该待分类数据重新进行分类得到待确定分类结果,但是该待确定分类结果中可能仍然存在明显分类错误的数据,为了提高分类准确率,在一种可能的实现方式中,可以通过以下方式确定该待确定分类结果中是否存在明显分类错误的数据:
首先,分别获取新的超平面的一边的每个待分类数据的第一目标松弛变量
其次,计算
再次,确定
最后,在确定
其中,该预设阈值可以取值为2,在确定该待确定分类结果中存在明显分类错误的数据后,交换该
采用上述方法,能够将第二分类权重按照初始分类结果进行划分得到第三分类权重和第四分类权重,并根据第三分类权重和第四分类权重得到目标分类权重,从而均衡考虑了不同分类结果对目标分类权重的影响,避免了在分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,数量较多的数据在迭代过程中对目标分类权重影响较大,而造成在目标分类权重满足预设分类终止条件时,数据分类结果仍然存在分类错误的数据。
图5是根据一示例性实施例示出的一种数据分类的装置的框图,参照图5,该装置包括第一获取模块501,分类模块502,第二获取模块503,第三获取模块504和第四获取模块505以及第一确定模块506。
该第一获取模块501,用于获取待分类数据以及已知分类结果的数据分类样本;
该分类模块502,用于根据该数据分类样本对该待分类数据进行分类得到第一分类结果;
该第二获取模块503,用于获取该数据分类样本的第一分类权重和该待分类数据的第二分类权重,其中,该第一分类权重表示该数据分类样本的分类结果的置信度,该第二分类权重表示该待分类数据的分类结果的置信度;
该第三获取模块504,用于根据该第二分类权重得到对应该第一分类结果的第三分类权重和第四分类权重;
该第四获取模块505,用于根据该第三分类权重和该第四分类权重得到目标分类权重;
该第一确定模块506,用于在该目标分类权重和该第一分类权重满足预设分类终止条件时,确定分类完成。
可选地,图6是图5所示实施例示出的一种数据分类的装置的框图,该第一分类结果包括第一类数据和第二类数据,该装置还包括:
第五获取模块507,用于获取该第一类数据包括的数据的第一数量和该第二类数据包括的数据的第二数量;
第一计算模块508,用于计算该第一数量和该第二数量之间的和值;
该第三获取模块504,用于根据该和值以及第二分类权重得到该第一类数据对应的第三分类权重和该第二类数据对应的第四分类权重。
可选地,该第三获取模块504,用于通过以下公式获取该第三分类权重:
其中,
通过以下公式获取该第四分类权重:
其中,
可选地,图7是图6所示实施例示出的一种数据分类的装置的框图,该装置还包括:
第二计算模块509,用于计算该第一数量和该第二数量之间的差值;
第二确定模块510,用于确定该差值是否大于或者等于0;
第四获取模块505,用于在该差值大于或者等于0时,通过以下公式得到该目标分类权重:
其中,
在该差值小于0时,通过以下公式得到该目标分类权重:
其中,
可选地,该预设分类终止条件包括:根据该目标分类权重得到的第五分类权重大于或者等于该第一分类权重,该第五分类权重为该目标分类权重与预设参数的乘积,该预设参数为大于1的数值。
可选地,图8是图5所示实施例示出的一种数据分类的装置的框图,该装置还包括:
循环模块511,用于在该目标分类权重和该第一分类权重不满足该预设分类终止条件时,将该第五分类权重替换该第二分类权重,并继续根据该第五分类权重对该第一分类结果进行重新分类得到第二分类结果,并根据该第五分类权重得到对应该第二分类结果的第六分类权重和第七分类权重,根据该第六分类权重和该第七分类权重得到新的目标分类权重,直至该新的目标分类权重和该第一分类权重满足预设分类终止条件。
采用上述装置,能够将第二分类权重按照初始分类结果进行划分得到第三分类权重和第四分类权重,并根据第三分类权重和第四分类权重得到目标分类权重,从而均衡考虑了不同分类结果对目标分类权重的影响,避免了在分类结果中其中一类数据包括的数据的第一数量与另一类数据包括的数据的第二数量相差较大时,数量较多的数据在迭代过程中对目标分类权重影响较大,而造成在目标分类权重满足预设分类终止条件时,数据分类结果仍然存在分类错误的数据。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!