一种基于演唱者声音特质的歌曲推荐方法与流程
本发明涉及歌唱领域的音频信号处理方法,特别是涉及一种基于演唱者声音特质的歌曲推荐方法。
背景技术:
音乐推荐系统重在向用户推荐其可能喜欢听的歌曲,采用的推荐技术主要可以分为基于内容的推荐和基于协同过滤的推荐。基于内容的推荐算法主要根据音乐自身的音频特征进行推荐,包括mfcc等底层特征或者旋律、节奏、流派、情感等特征。基于协同过滤的推荐算法主要根据用户之间的点播行为或者播放记录,以用户之间的相似性为基础进行推荐。
近年来,在移动互联网应用的快速发展和各档大型真人音乐选秀类节目的双重刺激下,音乐推荐系统从为用户推荐喜欢听的歌曲这一传统应用场景逐渐迁移,进而渗透进入为用户推荐喜欢唱的歌曲等新兴应用场景。
然而,应用场景的迁移并没有伴随着音乐推荐方法的同步迁移。以唱吧app为例,app中的推荐功能推荐的歌曲以当前热门歌曲为主。但是,热门歌曲并不适合所有用户演唱。有可能歌曲音调太高了,由于用户自身演唱音域范围及演唱能力的限制导致高音部分唱不上去;也有可能歌曲适合用粗犷的、有爆发力的声音去演绎,而用户却是个声音甜美的女生。
显然,新的推荐应用场景需要新的推荐模式。在k歌的应用场景下,用户不仅仅是听歌曲,更重要的是能最大程度地演绎好歌曲。这是一个双向匹配的过程,一方面,需要考虑用户自身声音的特质,例如用户实际的演唱音域及声音的音色等;另一方面,需要考虑歌曲对演唱能力的要求,例如歌曲要求的音域范围及怎样的音色更适合演绎该歌曲的情感等。
为了更好的介绍基于演唱者声音特质的歌曲推荐的概念,介绍一些相关音乐、人声理论的基本概念。
音色:音色是指声音在听觉上产生的某种属性,听音者能够据此判断两个以同样方式呈现、具有相同音高和响度的声音的不同。
音域:音域有总的音域和个别的人声或乐器的音域两种。总的音域指音列的总范围,即从最低音到最高音的范围。个别的人声或乐器的音域指某个人声或某种乐器在整个音域中所能到达的最低音到最高音的范围。乐器的音域相对固定,而人声的音域由于每个人先天的声带大小,长短、厚薄不同及后天有无经过系统的声乐训练等原因,有着较大的区别。
midi(musicalinstrumentdigitalinterface),是一种数字音乐、乐器的通信标准。midi文件可以灵活的记录歌曲的音高及音长等信息,便于计算机进行音高的分析与处理。
cqt谱,一种音色频率物理特征,通过中心频率成指数分布的滤波器组,将乐音信号表示为确定音乐单音的谱能量,滤波器组的品质因子q保持常数。
个体演唱能力包括演唱者音域范围的宽窄及在各个音级上的音准控制能力等。发声能力是演唱能力的基础,医学上利用发声范围档案记录个人的发声音域及响度动态范围。专业歌手则通过系统的声乐训练方法来提升自身的演唱能力,但普通演唱者一般不会去使用特定的训练方法。
因此,本申请基于上述分析,利用歌曲简谱和歌手清唱带等信息,建立歌曲特征文件库,提取歌曲的演唱音域和歌手的音色特征。同时利用用户演唱歌曲时的清唱录音文件与歌曲的简谱信息,在音级完成质量高的前提下,提取用户的演唱音域和音色特征。综合考虑用户的演唱音域与曲库中歌曲音域要求之间的匹配度以及用户音色与曲库中歌手音色之间的相似度,计算曲库中每首歌曲对于该用户的推荐度,并向用户推荐推荐度高的歌曲。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于演唱者声音特质的歌曲推荐方法,对演唱者与歌手之间音域相似度以及音色相似度、歌曲推荐进行分析。
本发明采用以下方案实现:一种基于演唱者声音特质的歌曲推荐方法,包括如下步骤:
步骤s1:分析曲库中歌曲的简谱信息,得到各个歌曲的midi音高基准序列,分析出歌曲的音级分布直方图,得到各个歌曲的演唱音域要求;
步骤s2:采用melodia算法分析用户清唱录音文件,得到演唱者演唱该歌曲的midi音高值序列,取得步骤s1中得到的同一歌曲的midi音高基准序列,计算演唱者的基准演唱能力,提取其演唱音域;
步骤s3:对歌手的清唱文件提取时频信号表征,输入到深度卷积神经网络中对网络进行迭代训练,得到训练好的深度卷积神经网络及人声音色嵌入空间;
步骤s4:根据歌手的清唱文件提取时频信号表征,将其输入到步骤s3中训练好的深度卷积神经网络中,网络的输出对应于人声音色嵌入空间的3维音色特征向量,将这3维音色特征向量作为原唱歌手的人声音色表征;
步骤s5:分析演唱者的清唱声音片段,同样采用步骤s4的方法,得到人声音色嵌入空间中的一组3维音色特征向量,作为演唱者人声音色表征;
步骤s6:根据歌曲的演唱音域要求和演唱者的演唱音域,计算出用户与歌曲之间的音域匹配度;
步骤s7:根据原唱歌手和演唱者的人声音色表征,计算演唱者与各歌手的音色相似度;
步骤s8:根据音域匹配度和音色相似度,计算曲库中每首歌曲对于该用户的推荐度。
进一步地,所述步骤s6具体包括以下步骤:
步骤s61:根据歌曲音级分布直方图得到每个音级的权重,每个音级的权重等于该音级出现的次数除以该歌曲中所有音级出现次数的总和,计算公式的定义具体为:
其中,num(x)表示音级x在简谱中出现的次数,xmax表示简谱中音符的最大midi值,xmin表示简谱中音符的最小midi值;
步骤s62:利用歌曲的音级分布情况与用户在各个音级的演唱能力评估值,计算出用户演唱音域与歌曲音域要求的匹配度,音域匹配度的计算公式的定义具体为:
其中,u(x)表示用户在音级x上的演唱能力评估值。
进一步地,所述步骤s7中,演唱者的声音片段嵌入到音色嵌入空间中后,分别计算演唱者与嵌入空间中各歌手的音色相似度,音色相似度的计算公式的定义具体为:
tim_sim(u,s)=1-tanh(μ||z1-z2||2)
其中,||z1-z2||2表示两点之间的欧氏距离,μ为经验系数,tanh为双曲正切函数。
进一步地,所述步骤s8中,在进行最终的推荐时,综合考虑用户的演唱音域与曲库中歌曲的音域要求的匹配度以及用户的音色与曲库中歌手的音色相似性,计算曲库中每首歌曲对于该用户的推荐度,推荐度的计算公式的定义具体为:
recom(u,s)=cran_mat(u,s)+(1-c)tim_sim(u,s)
其中,recom(u,s)表示歌曲s对于用户u的推荐度,ran_mat(u,s)表示歌曲s对于用户u的音域匹配度,tim_sim(u,s)表示用户u的音色与歌曲s的原唱歌手音色的相似度,c取值为0.7。
与现有技术相比,本发明具有如下优点:该方法利用用户的演唱歌曲时的清唱录音文件与歌曲的简谱信息,在音级完成质量高的前提下,提取用户的演唱音域。同时利用歌曲简谱和歌手清唱带等信息,建立歌曲特征文件库,提取歌手的演唱音域和音色特征。与利用音域的宽度计算用户与歌曲的匹配度,但在某些情况下不适用相比,利用歌曲midi音高模型分析出歌曲的音级分布直方图与用户在各个音级的演唱能力评估值,计算出用户演唱音域与歌曲音域要求的匹配度,适用范围更广也更准确,同时用户在演唱过程中也可以完善其演唱音域。并且借助深度卷积网络强大的降维能力及特征学习能力,将高维的、时序的人声频谱特征嵌入到3维的音色嵌入空间中,从而在3维音色嵌入空间内实现音色相似性的可度量性。最后综合考虑用户的演唱音域与曲库中歌曲的音域要求的匹配度以及用户的音色与曲库中歌手的音色相似性,计算曲库中每首歌曲对于该用户的推荐度。可以根据不同的应用场景,设置不同的参数值值。从而向用户推荐合适且推荐度高的歌曲。
附图说明
图1是本发明的方法流程示意框图。
图2是本发明用户u3部分歌曲推荐结果列表。
具体实施方式
下面结合附图表及实施例对本发明做进一步说明。
本实施例提供一种基于演唱者声音特质的歌曲推荐方法,如图1所示包括如下步骤:
步骤s1:分析曲库中歌曲的简谱信息,得到各个歌曲的midi音高基准序列,分析出歌曲的音级分布直方图,得到各个歌曲的演唱音域要求;
步骤s2:采用melodia算法分析用户清唱录音文件,得到演唱者演唱该歌曲的midi音高值序列,取得步骤s1中得到的同一歌曲的midi音高基准序列,计算演唱者的基准演唱能力,提取其演唱音域;
步骤s3:对歌手的清唱文件提取时频信号表征,输入到深度卷积神经网络中对网络进行迭代训练,得到训练好的深度卷积神经网络及人声音色嵌入空间;
步骤s4:根据歌手的清唱文件提取时频信号表征,将其输入到步骤s3中训练好的深度卷积神经网络中,网络的输出对应于人声音色嵌入空间的3维音色特征向量,将这3维音色特征向量作为原唱歌手的人声音色表征;
步骤s5:分析演唱者的清唱声音片段,同样采用步骤s4的方法,得到人声音色嵌入空间中的一组3维音色特征向量,作为演唱者人声音色表征;
步骤s6:根据歌曲的演唱音域要求和演唱者的演唱音域,计算出用户与歌曲之间的音域匹配度;
步骤s7:根据原唱歌手和演唱者的人声音色表征,计算演唱者与各歌手的音色相似度;
步骤s8:根据音域匹配度和音色相似度,计算曲库中每首歌曲对于该用户的推荐度。
在本实施例中,所述步骤s6具体包括以下步骤:
步骤s61:根据歌曲音级分布直方图得到每个音级的权重,每个音级的权重等于该音级出现的次数除以该歌曲中所有音级出现次数的总和,计算公式的定义具体为:
其中,num(x)表示音级x在简谱中出现的次数,xmax表示简谱中音符的最大midi值,xmin表示简谱中音符的最小midi值。
步骤s62:利用歌曲的音级分布情况与用户在各个音级的演唱能力评估值,计算出用户演唱音域与歌曲音域要求的匹配度,音域匹配度的计算公式的定义具体为:
其中,u(x)表示用户在音级x上的演唱能力评估值。
在本实施例中,所述步骤s7中,演唱者的声音片段嵌入到音色嵌入空间中后,分别计算演唱者与嵌入空间中各歌手的音色相似度,音色相似度的计算公式的定义具体为:
tim_sim(u,s)=1-tanh(μ||z1-z2||2)
其中,||z1-z2||2表示两点之间的欧氏距离,μ为经验系数,tanh为双曲正切函数。
在本实施例中,所述步骤s8中,在进行最终的推荐时,综合考虑用户的演唱音域与曲库中歌曲的音域要求的匹配度以及用户的音色与曲库中歌手的音色相似性,计算曲库中每首歌曲对于该用户的推荐度,推荐度的计算公式的定义具体为:
recom(u,s)=cran_mat(u,s)+(1-c)tim_sim(u,s)
其中,recom(u,s)表示歌曲s对于用户u的推荐度,ran_mat(u,s)表示歌曲s对于用户u的音域匹配度,tim_sim(u,s)表示用户u的音色与歌曲s的原唱歌手音色的相似度,c取值为0.7。
在本实施例中,根据以上方法给出实例,具体包括以下步骤:
步骤1:分析曲库中歌曲的简谱信息,得到各个歌曲的midi音高基准序列,分析出歌曲的音级分布直方图,得到各个歌曲的演唱音域要求。具体步骤如下:
步骤11:搜集整理曲库中用户演唱歌曲的简谱,根据歌曲简谱中的调号及唱名等信息,将简谱信息转换为对应的midi音高值序列,并根据对应歌曲伴奏的开始时间、持续时间等信息,建立该歌曲的标准midi音高特征文件。
步骤12:由歌曲midi音高值序列分析出歌曲的音级分布直方图,歌曲的音级分布直方图统计了歌曲midi音高值序列中,每个音级出现的次数,并按照音列从低到高的顺序排列。因此,音级分布直方图的最左和最右两个音级所包含的音域部分,对应该歌曲的演唱音域要求。
步骤2:采用melodia算法分析用户清唱录音文件,得到演唱者演唱该歌曲的midi音高值序列,取得曲库中同一歌曲的midi音高基准序列,计算演唱者的基准演唱能力,提取其演唱音域。具体步骤如下:
步骤21:采用melodia算法分析用户清唱录音文件,melodia算法能自动检测歌曲中主要旋律的基频f0,具体参数设置为{"minfqr":82.0,"maxfqr":1047.0,"voicing":0.2,"minpeaksalience":0.0}。将基频f0转换为midi音高值p,转换公式的具体定义为:
步骤22:下面以用户u1例,用户u1为男性,具有一定的演唱经验,但是太高的音唱不上去。根据步骤11取得曲库中同一歌曲的midi音高基准序列,统计u1的音级x在歌曲集合中出现的次数及演唱者唱准次数来评价音级x的完成质量,记为β(x),累加至用户的历史文件中,更新用户的演唱音域历史记录。计算每个音级的威尔逊置信区间下界,作为更新后的音级完成质量。
步骤23:遍历更新后的音级完成质量,然后计算出基准演唱能力α。α的计算公式的定义具体为:
α=mean(β(x))-std(β(x))
其中,mean(β(x))表示总音域内各个音级完成质量的平均值,std(β(x))表示总音域内各个音级完成质量的标准差。经统计,用户u1演唱20首歌曲之后,各个音级的平均完成质量为0.84,标准差为0.16,计算出其基准演唱能力α为0.68。
步骤24:用<α,[xmin,xmax],sequ[β(xmin),β(xmax)],min(β(x))>表示演唱者的演唱音域,是一个五元组。其中,xmin为midi值最小的音级为,xmax为midi值最大的音级,sequ[β(xmin),β(xmax)]为xmin与xmax之间的音级完成质量序列,音质完成质量下界值为min(β(x))。分析得到用户u1大于基准演唱能力的最小音级为a3,最大音级为g5。而各个音级完成质量序列值为[0.86,0.99,…],其中最小的音质完成质量下界值为0.28。最终得到用户u1的演唱音域为<0.68,[a3,g5],[0.86,0.99,…],0.28>。
步骤3:对歌手的清唱文件提取时频信号表征,输入到深度卷积神经网络中对网络进行迭代训练,得到训练好的深度卷积神经网络及人声音色嵌入空间。具体步骤如下:
步骤31:将歌手分为15人一组,对每组歌手的清唱音频进行分帧,对其提取cqt特征,每一帧的cqt系数为192维,选取60帧的cqt系数,构成神经网络的输入矩阵,矩阵大小为60*192。
步骤32:将步骤31中得到的输入矩阵输入到深度卷积神经网络,并采用成对训练的方法对网络进行迭代训练,得到训练好的深度卷积神经网络及相应的音色嵌入空间。
步骤4:根据歌手的清唱文件提取时频信号表征,将其输入到步骤s3中训练好的深度卷积神经网络中,网络的输出对应于人声音色嵌入空间的3维音色特征向量,将这3维音色特征向量作为原唱歌手的人声音色表征。具体步骤如下:
步骤41:对每一位歌手的声音片段,采用同步骤31的方法,提取cqt特征后,得到大小为60*192的输入矩阵。
步骤42:将步骤41得到的cqt特征输入到步骤32训练好深度卷积网络,网络的输出对应于人声音色嵌入空间的3维音色特征向量,将这3维音色特征向量作为原唱歌手的人声音色表征。
步骤5:分析演唱者的清唱声音片段,同步骤s4方法,得到人声音色嵌入空间中的一组3维音色特征向量,作为演唱者人声音色表征。具体步骤如下:
步骤51:对演唱者的声音片段,采用同步骤31的方法,提取cqt特征后,得到大小为60*192的输入矩阵。
步骤52:将步骤51得到的cqt特征输入到步骤32训练好深度卷积网络,网络的输出对应于人声音色嵌入空间的3维音色特征向量,将这3维音色特征向量作为演唱者的人声音色表征。
步骤6:根据歌曲的演唱音域要求和演唱者的演唱音域,计算出用户与歌曲之间的音域匹配度。具体步骤如下:
步骤61:根据歌曲音级分布直方图得到每个音级的权重,每个音级的权重等于该音级出现的次数除以该歌曲中所有音级出现次数的总和,计算公式的定义具体为:
其中,num(x)表示音级x在简谱中出现的次数,xmax表示简谱中音符的最大midi值,xmin表示简谱中音符的最小midi值。
步骤62:以用户u2的演唱音域和刘若英唱的歌曲《当爱在靠近》进行实例分析。用户u2,女性,其演唱音域为<0.18,[f4,g5],[0.183,0.409,…],0.08>,即用户u2在音域[f4,g5]范围内的各音级完成度为0.183,0.409,…,音域范围外的演唱能力估值为0.08。该歌曲的音域要求是[d4,g5]。
计算出歌曲音级分布直方图中每个音级的权重之后,音域匹配度等于用户在各个音级上的演唱能力评估值乘以歌曲音级分布直方图的权重之和。音域匹配度的计算公式的定义具体为:
其中,u(x)表示用户在音级x上的演唱能力评估值,根据音级x是否属于用户的演唱音域,u(x)取不同的值。具体计算公式定义具体为:
其中,β(x)表示用户在演唱音域内各音级的完成质量,min(β(x))表示用户的音级完成质量的最小值。
最终得到用户u2演唱刘若英所唱的歌曲《当爱在靠近》的音域匹配度为0.36。
步骤7:根据步骤4和步骤5的方法分别得到原唱歌手和演唱者在各个音色嵌入空间中的一组3维音色特征向量,利用与歌手之间的欧氏距离,分别计算与各个嵌入空间中各歌手的音色相似度。以歌手子集c8{梁静茹,刘若英,陈小春,张学友,范玮琪,范晓萱,tank,任贤齐}为例。
音色相似度的计算公式的定义具体为:
tim_sim(u,s)=1-tanh(μ||z1-z2||2)
其中,||z1-z2||2表示两点之间的欧氏距离,μ为经验系数,取0.05,tanh为双曲正切函数。歌手梁静茹与其他歌手的相似性为{{范玮琪:0.53},{刘若英:0.55},{范晓萱:0.55},{陈小春:0.22},{tank:0.37},{任贤齐:0.40},{张学友:0.24}}。
步骤8:在进行最终的推荐时,综合考虑用户的演唱音域与曲库中歌曲的音域要求的匹配度以及用户的音色与曲库中歌手的音色相似性,计算曲库中每首歌曲对于该用户的推荐度。音域匹配度的计算如前述步骤6所示,音色相似度的计算如前述步骤7所示。以用户u3进行实例分析,用户u3,男性,其演唱音域模型为<0.58,[a3,g5],[0.835,0.602,…],0.26>,即用户u3在音域[a3,g5]范围内的各音级完成度为0.835,0.302,…,音域范围外的演唱能力估值为0.26。
推荐度的计算公式的定义具体为:
recom(u,s)=cran_mat(u,s)+(1-c)tim_sim(u,s)
其中,recom(u,s)表示歌曲s对于用户u的推荐度,ran_mat(u,s)表示歌曲s对于用户u的音域匹配度,tim_sim(u,s)表示用户u的音色与歌曲s的原唱歌手音色的相似度,c为常数,0≤c≤1。c取值为0.7。通过歌曲s对用户u的音域匹配度和音色相似度,计算出其推荐度,最终根据推荐度,推荐歌曲给用户。
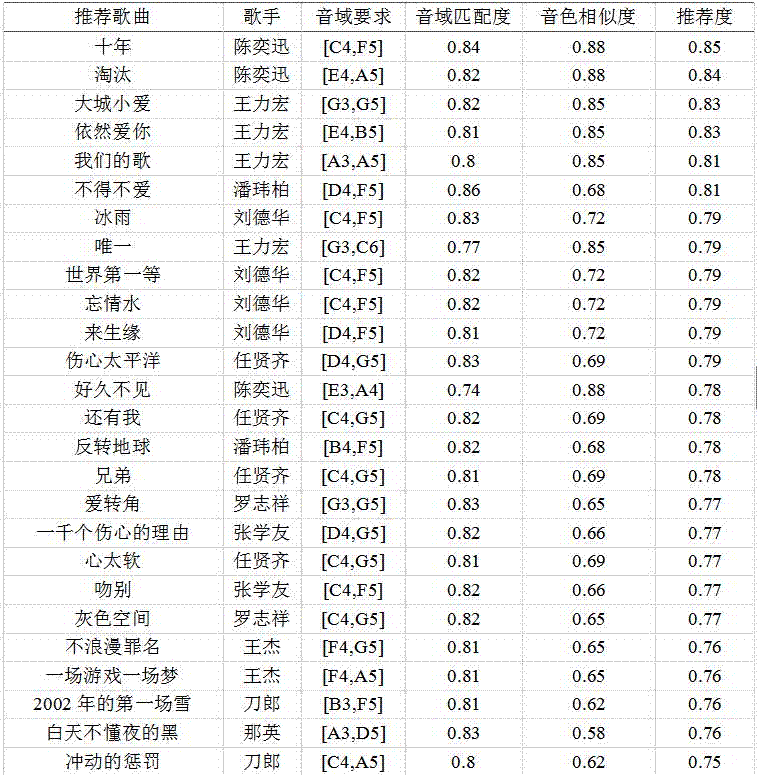
最终用户u3推荐度最高的推荐歌曲详细信息为:歌曲《十年》,歌手陈奕迅,音域要求[c4,f5]。其音域匹配度为0.84,音色相似度为0.88,最终计算匹配度0.85。图2给出了用户u3更全的部分推荐结果。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!