基于决策树和SVM混合模型的中文句型分类方法与流程
本发明涉及一种文本分类,特别涉及一种基于决策树和svm(支持向量机)混合模型的中文句型分类方法。
背景技术:
现今时代互联网发展迅速,信息急剧膨胀,充斥着人们的生活。微博、微信、论坛等信息发布和社交网络平台,在各个方面渗透着人们的生活,已然成为人们获取信息、交流互动、发表观点的平台。互联网上的中文文本信息传播量大、类型多样、更新快,随着情报加工的深入,对文本数据精确判断的要求也越来越高。在分析中文句子时,不同句型即使使用类似的关键词,表达的含义仍有很大差别,特别是在情感判断中,更需要精准判断关键词的作用。因此,通过精准的句法分析对这些中文文本进行句型判别成为一个热门的研究话题。上述问题是一个文本多分类问题,即判断句子是属于疑问句、否定句,还是属于其他类别。问题看似简单,实际上却存在许多难点。第一,中文的语法灵活多变,句法复杂多样;句子中不仅包含了多种句法成分,而且不同句法成分的搭配生成了各种各样的语义,导致句子难以统一归纳分析。第二,句子中的某些词语对句子类型起到了关键作用,但这些关键词在不同语境下有不同语义,发挥着不同的作用,造成了一词多义的难题;第三,来自微博、论坛等社交网络平台的中文文本,绝大部分都是口语化的句子;这些句子有的缺少完整的句法成分,有的存在明显的语法错误,有的甚至不符合口语化的使用规律,导致难以按照正确的语法规则来分析,极大地增加了挑战性。
当前常用的分类算法主要有:
决策树:决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。主要的决策树算法有id3、c4.5(c5.0)、cart、public、sliq和sprint算法等。它们在选择测试属性采用的技术、生成的决策树的结构、剪枝的方法以及时刻,能否处理大数据集等方面都有各自的不同之处。
贝叶斯算法:贝叶斯(bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯(naivebayes)算法。这些算法主要利用bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。由于贝叶斯定理的成立本身需要一个很强的条件独立性假设前提,而此假设在实际情况中经常是不成立的,因而其分类准确性就会下降。为此就出现了许多降低独立性假设的贝叶斯分类算法,如tan(treeaugmentednaivebayes)算法,它是在贝叶斯网络结构的基础上增加属性对之间的关联来实现的。
k-近邻算法:k-近邻(knn,k-nearestneighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
支持向量机:支持向量机(svm,supportvectormachine)是vapnik根据统计学习理论提出的一种新的学习方法,它的最大特点是根据结构风险最小化准则,以最大化分类间隔构造最优分类超平面来提高学习机的泛化能力,较好地解决了非线性、高维数、局部极小点等问题。对于分类问题,svm算法根据区域中的样本计算该区域的决策曲面,由此确定该区域中未知样本的类别。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于决策树和svm混合模型的中文句型分类方法,该方法将首先通过特殊陈述句决策树、疑问句决策树和否定句决策树对句子进行句型判定,在未判定出结果的情况下,再采用svm分类器进行判定,本发明方法以决策树算法为核心,以svm算法为辅助,可以很好地解决传统决策树模型无法判断的特殊点,提升句型分类的准确率。
本发明的目的通过下述技术方案实现:一种基于决策树和svm混合模型的中文句型分类方法,其特征在于,步骤如下:
s1、获取到多个训练样本,并且人工标注出各个训练样本的句型,得到训练样本集;训练样本集中包括特殊陈述句句型、疑问句句型和否定句句型的训练样本;
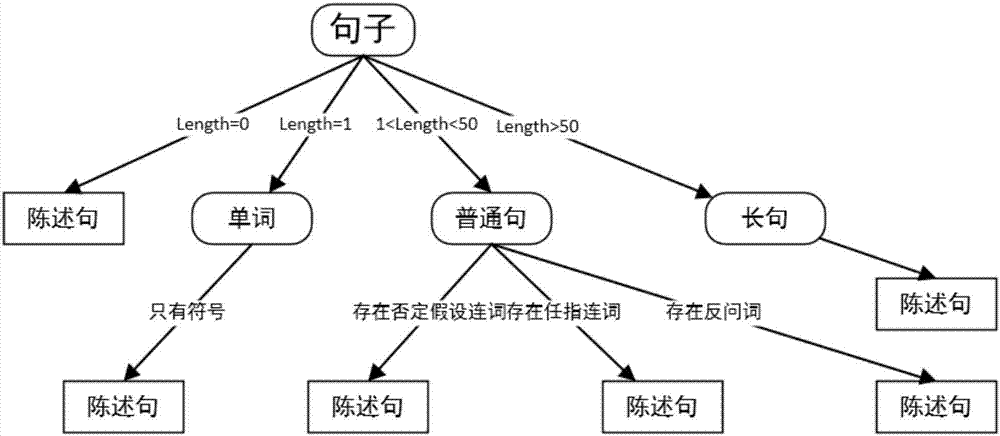
s2、构建特殊陈述句决策树,首先根据已知的中文语法规则以及训练样本集中各类特殊陈述句训练样本所具备的特征获取到特殊陈述句的判定规则,根据上述判定规则构建得到特殊陈述句决策树;其中根据特殊陈述句句型具备的特征将其分为非正常句、任指型陈述句、否定假设句和反问句,具体如下:将句子为空、句子只有一个符号或句子长度超过一定值句子定义为非正常句;将句中包括任指连词的句子定义为任指型陈述句;将句中包括否定假设词的句子定义为否定假设句;将句中包括反问词的句子定义为反问句;
构建疑问句决策树,首先根据已知的中文语法规则以及训练样本集中各类疑问句训练样本所具备的特征获取到疑问句的判定规则,根据上述判定规则构建得到疑问句决策树;其中根据疑问句句型所具备的特征将其分为是非疑问句、选择疑问句、正反疑问句和特殊疑问句;
构建否定句决策树,首先提取训练集中否定句训练样本谓语中心语及状语,通过上述提取的谓语中心语及状语获取到否定句训练样本所具备的以下特征:否定词、状语、谓语否定词数量、状语否定词数量、状语否定词修饰谓语否定词;然后根据已知的中文语法规则以及训练样本集中否定句训练样本所具备的特征获取到否定句的判定规则,最后根据否定句的判定规则和否定句训练样本所具备的特征训练得到否定句决策树;
s3、构建svm分类器,具体步骤如下:
s31、将训练样本集中的各个训练样本首先分别输入至步骤s2中构建得到的特殊陈述句决策树、疑问句决策树和否定句决策树中,获取到上述三个决策树均不能判定出结果的训练样本;
s32、针对步骤s31获取到的这些训练样本,根据第一疑问词词典和否定词词典,识别出每个训练样本中的疑问词、及其前置词性和后置词性,其中疑问词前置词性和后置词性分别指的是疑问词相邻前面词的词性和相邻后面词的词性;识别出每个训练样本中的否定词、及其前置词性和后置词性,其中否定前置词性和后置词性分别指的是否定词相邻前面词的词性和相邻后面词的词性;识别出每个训练样本中的疑问词和否定词的相对位置,识别出每个训练样本中否定词的个数;所述第一疑问词词典包括疑问代词和副词;
s33、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个疑问词时句子成为疑问句的概率,出现某个疑问词和某种前置词性搭配时句子为疑问句的概率;出现某个疑问词和某种后置词性搭配时句子为疑问句的概率;然后将出现某个疑问词和某种前置词性搭配时句子为疑问句的概率除以出现某个疑问词时句子成为疑问句的概率得到出现某个疑问词和某种前置词性搭配时句子为疑问句的条件概率;将出现某个疑问词和某种后置词性搭配时句子为疑问句的概率除以出现某个疑问词时句子成为疑问句的概率得到出现某个疑问词和某种后置词性搭配时句子为疑问句的条件概率;
s34、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个否定词时句子成为否定句的概率,出现某个否定词和某种前置词性搭配时句子为否定句的概率;出现某个否定词和某种后置词性搭配时句子为否定句的概率;然后将出现某个否定词和某种前置词性搭配时句子为否定句的概率除以出现某个否定词时句子成为否定句的概率得到出现某个否定词和某种前置词性搭配时句子为否定句的条件概率;将出现某个否定词和某种后置词性搭配时句子为否定句的概率除以出现某个否定词时句子成为否定句的概率得到出现某个否定词和某种后置词性搭配时句子为否定句的条件概率;
s35、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个疑问词在前而某个否定词在后时句子分别成为疑问句和否定句的概率,出现某个否定词在前而某个疑问词在后时句子分别成为疑问句和否定句的概率;
s36、针对于步骤s31获取到的三个决策树均不能判定出结果的训练样本,通过以下步骤提取出这些训练样本中每个训练样本的特征,具体如下:
s361、当训练样本中识别出疑问词时,分别获取到该疑问词的前置词性和后置词性,然后通过步骤s33获取到出现该疑问词和该前置词性时句子成为疑问句的概率,作为训练样本第一特征值;同时通过步骤s33获取到出现该疑问词和该后置词性时句子成为疑问句的概率,作为训练样的第二特征值;当训练样本未出现疑问词时,则训练样本的第一特征值和训练样本的第二特征值分别为零;
s362、当训练样本中识别出否定词时,统计否定词的个数,将否定词的个数作为训练样本的第三特征值;同时分别获取到该否定词的前置词性和后置词性,然后通过步骤s34获取到出现该否定词和该前置词性时句子成为否定句的概率,作为训练样本的第四特征值;同时通过步骤s34获取到出现该否定词和该后置词性时句子成为否定句的概率,作为训练样本的第五特征值;当训练样本未出现否定词时,则训练样本对应的第四特征值和第五特征值分别为零;
s363、当训练样本中同时识别出疑问词和否定词时,获取该疑问词和该否定词的相对位置,将该相对位置作为训练样本的第六特征值;训练样本中若该疑问词在前而该否定词在后,则通过步骤s35获取到出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;训练样本中若该否定词在前而该疑问词在后,则通过步骤s35获取到出现该否定词在前而该疑问词在后时句子分别成为疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;
s37、将步骤s36中获取到的训练样本的第一特征值、第二特征值、第三特征值、第四特征值、第五特征值、第六特征值、第七特征值和第八特征值分别作为输入对svm进行训练,得到svm分类器;
s4、当获取到测试文本数据时,首先进行数据预处理得到测试样本,然后将测试样本输入至步骤s2构建得到的特殊陈述句决策树中,通过特殊陈述句决策树判断测试样本句型,若特殊陈述句决策树未能判定出测试样本,那么进行步骤s5的处理;
s5、首先根据第二疑问词词典和否定词词典判断测试样本中是否有疑问词和否定词,若测试样本中只有疑问词而没有否定词,则将测试样本作为候选疑问句,进入步骤s6;若测试样本只有否定词而没有疑问词,则将测试样本作为候选否定句,进入步骤s7;若测试样本中既有否定词又有疑问词,则进入步骤s8;其中第二疑问词词典为第一疑问词词典基础上加上疑问语气词后得到的词典;
s6、将测试样本输入至步骤s2构建的疑问句决策树,通过疑问句决策树对测试样本的句型进行判定,输出测试样样本的句型判定结果,若疑问句决策树未能输出测试样本的句型判定结果,则将测试样本进行步骤s8的处理;
s7、提取出测试样本的谓语以及修饰该谓语的状语,并且输入至步骤s2中构建的否定句决策树,否定句决策树根据测试样本的谓语以及修饰该谓语的状语对测试样本的句型进行判定,输出判定结果,若否定句决策树未能输出测试样本的判定结果,则将测试样本进行步骤s8的处理;
s8、通过第一疑问词词典和否定词词典分别识别出测试样本中的疑问词和否定词,然后通过以下步骤提取出测试样本的特征;
s81、当测试样本中有疑问词时,分别获取到该疑问词的前置词性和后置词性,然后通过步骤s33获取到出现该疑问词和该前置词性时句子成为疑问句的概率,作为测试样本第一特征值;同时通过步骤s33获取到出现该疑问词和该后置词性时句子成为疑问句的概率,作为测试样本的第二特征值;当测试样本未出现疑问词时,则测试样本的第一特征值和第二特征值分别为零;
s82、当测试样本中有否定词时,统计否定词的个数,将否定词的个数作为测试样本的第三特征值;同时分别获取到该否定词的前置词性和后置词性,然后通过步骤s34获取到出现该否定词和该前置词性时句子成为否定句的概率,作为测试的第四特征值;同时通过步骤s34获取到出现该否定词和该后置词性时句子成为否定句的概率,作为测试样本的第五特征值;当测试样本未出现否定词时,则测试样本的第四特征值和第五特征值分别为零;
s83、当测试样本中同时有疑问词和否定词时,获取该疑问词和该否定词的相对位置,将该相对位置作为测试样本的第六特征值;测试样本中若该疑问词在前而该否定词在后,则通过步骤s35获取到出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率,且分别作为测试样本的第七特征值和第八特征值;测试样本中若该否定词在前而该疑问词在后,则通过步骤s35获取到出现该否定词在前而该疑问词在后时句子分别成为疑问句和否定句的概率,且分别作为测试样本的第七特征值和第八特征值;
s9、将测试样本的第一特征值、第二特征值、第三特征值、第四特征值、第五特征值、第六特征值、第七特征值和第八特征值分别输入至步骤s364训练好的svm分类器中,通过svm分类器的输出获取到测试样本的句型判定结果。
优选的,所述步骤s2中在构建特殊陈述句决策树时,当根据已知的中文语法规则以及训练样本集中疑问句训练样本所具备的特征获取到疑问句的判定规则时,将训练样本集中符合上述判定规则的特殊陈述句训练本输入至上述判定规则进行验证,若验证的准确率达到设定阈值,则将对应的判断规则加入到决策树中,从而获取到特殊陈述句决策树。
优选的,所述步骤s2中在构建疑问句决策树时,将训练样本集中符合上述判定规则的疑问句训练样本输入至上述判定规则进行验证,若验证的准确率达到设定阈值,则将对应的判断规则加入到决策树中,从而获取到疑问句决策树。
优选的,所述步骤s2中在构建否定句决策树时,根据否定句的判定规则和否定句训练样本所具备的特征,并且采用id3算法训练得到否定句决策树。
更进一步的,所述通过id3算法训练后,否定句决策树从上至下每一层的特征分别为:判定是否存在否定词、判定是否存在状语、判定谓语否定词数量、判定状语否定词数量、判定状语否定词是否修饰谓语否定词。
优选的,其特征在于,所述第二疑问词词典为第一疑问词词典的基础上加入疑问语气词“吗、呢、吧、咩、捏、咯、?、?”后得到;
所述步骤s2中,将句中包含正反疑问词且正反疑问词不在句尾的句子定义为正反疑问句;将句中出现空格、正反疑问词在空格前且空格后只有一个词的句子也作为正反疑问句;所述步骤s2中根据已知的中文语法规则以及训练样本集中正反疑问句训练样本所具备的上述特征获取到正反疑问句的判定规则;
所述步骤s2中,将句中包含选择疑问词“是”和“还是”、“是”在“还是”前面、“是”前面没有疑问词并且“是”和“还是”之间没有空格的句子定义为选择疑问句,所述步骤s2中根据已知的中文语法规则以及训练样本集中选择疑问句训练样本所具备的上述特征获取到选择疑问句的判定规则;
所述步骤s2中,将句中包含疑问语气词且疑问语气词位置满足一定条件的句子定义为是非疑问句,其中疑问语气词分为强疑问语气词和弱疑问语气词,所述强疑问语气词包括“吗”和“么”,所述弱疑问词包括“吧”和“啊”;将句中包含强疑问语气词且强疑问语气词在句末或者强疑问语气词后面只有标点符号的句子定义为是非疑问句,将句中包含强疑问语气词、强疑问语气词未在句末且强疑问语气词后面词的个数小于3的句子定义为是非疑问句;将句中包含弱疑问语气词且弱疑问语气词在句末或者弱疑问语气词后面跟着问号的句子定义为是非疑问句;所述步骤s2中根据已知的中文语法规则以及训练样本集中是非疑问句训练样本所具备的上述特征获取到是非疑问句的判定规则;
所述步骤s2中,将句中包含不含歧义的疑问代词或疑问副词且句尾出现疑问语气词的句子定义为特殊疑问句,其中句尾出现的疑问语气词不为“吗”和“吧”;所述步骤s2中根据已知的中文语法规则以及训练样本集中特殊疑问句训练样本所具备的上述特征获取到特殊疑问句的判定规则;
根据上述获取到的正反疑问句的判定规则、选择疑问句的判定规则、是非疑问句的判定规则和特殊疑问句的判定规则获取到疑问句决策树。
优选的,其特征在于,还包括构建非否定词词典,所述非否定词词典中存储带否定字眼而不属于否定词的非否定词,所述步骤s5中当根据否定词词典判断出测试样本中有否定词时,则再根据非否定词词典判断是否为带否定字眼而不属于否定词的非否定词,若是,则判定测试样本没有否定词,若否,则将判定测试样本有否定词。
优选的,其特征在于,所述步骤s4中,数据预处理的过程具体如下:
s41、以汉语标点符号中的句号、感叹号、问号和逗号以及英文标点符号中的感叹号、问号和逗号作为断句的分隔符对测试文本数据进行断句,得到测试样本,并且保留汉语标点符号中的问号和英文标点符号中的问号;
s42、对断句后的获取到的测试样本进行去干扰处理;
s43、利用分词工具对测试样本进行分词和词性标注,得到分词和词性标注后的测试样本。
优选的,所述步骤s7中根据测试样本的谓语以及修饰该谓语的状语获取到测试样本以下特征:是否有否定词、是否有状语、谓语否定词数量、状语否定词数量、是否存在状语否定词修饰谓语否定词;所述否定句决策树根据测试样本上述特征通过规则对测试样本进行判定:
s71、若测试样本只有谓语,没有状语,则如果谓语包含有否定词且谓语否定词的数量个数不为2,则将测试样本判定为否定句;
s72、若测试样本既有谓语,也有状语,但谓语不包含否定词,则如果状语存在否定词,且状语否定词个数不为2,则将测试样本判定为否定句;
s73、若测试样本既有谓语,也有状语,但状语不包含否定词,则如果谓语包含有否定词,且谓语否定词个数不为2,则将测试样本判定为否定句;
s74、若测试样本既有谓语,也有状语,且状语和谓语都有否定词,但状语否定词并不是修饰谓语否定词,则将测试样本判定为否定句。
优选的,所述步骤s2中通过依存句法分析提取出训练集中否定句训练样本谓语中心语及状语;所述步骤s7中通过依存句法分析提取出测试样本的谓语以及修饰该谓语的状语。
本发明相对于现有技术具有如下的优点及效果:
(1)本发明中文句型分类方法首先获取到训练样本,并且对训练样本的句型进行人工标注,得到训练样本集;然后根据训练样本集中各类句型的训练样本构建得到特殊陈述句决策树、疑问句决策树和否定句决策树,并且将训练样本集中的各训练样本分别输入至特殊陈述句决策树、疑问句决策树和否定句决策树进行句型判定;最后提取出特殊陈述句决策树、疑问句决策树和否定句决策树均不能判定的训练样本,针对这些训练样本提取相关特征值,将这些训练样本的相关特征值输入至svm中对svm进行训练,最终得到svm分类器。当获取到测试样本后,首先通过特殊陈述句决策树进行句型判定,在特殊陈述句决策树未判定出结果的情况下,首先根据第二疑问词词典和否定词词典判断测试样本中是否有疑问词和否定词,在只有疑问词的情况下,将测试样本作为候选疑问句输入至疑问句决策树进行判定;在只有否定词的情况下,将测试样本作为候选否定句输入至否定句决策树进行判定;将疑问句决策树和否定句决策树均未能判定出结果的测试样本以及既有疑问词又有否定词的测试样本输入至svm分类器进行分类;可见,本发明将特殊陈述句决策树、疑问句决策树、否定句决策树和svm分类器相结合,既可以比较准确地判断出大部分正常的句子,又可以相对高效地处理一部分难以归纳总结的句子。本发明方法以决策树算法为核心,以svm算法为辅助,可以很好地解决传统决策树模型无法判断的特殊点,提升句型分类的准确率。
(2)本发明在构建svm分类器时,首先根据第一疑问词典和否定词典提取出特殊陈述句决策树、疑问句决策树和否定句决策树均不能判定出结果的训练样本中的疑问词和否定词关键词,然后统计出训练样本集中出现某个疑问词和某种前置词性搭配时句子为疑问句的条件概率、出现某个疑问词和某种后置词性搭配时句子为疑问句的条件概率、出现某个否定词和某种前置词性搭配时句子为否定句的条件概率、出现某个否定词和某种后置词性搭配时句子为否定句的条件概率、出现某个疑问词在前而某个否定词在后时句子分别成为疑问句和否定句的概率、出现某个否定词在前而某个疑问词在后时句子分别成为疑问句和否定句的概率;然后针对于特殊陈述句决策树、疑问句决策树和否定句决策树均不能判定出结果的每个训练样本以及需要进行句型分类的测试样本,首先识别出疑问词及其前置词性和后置词性、否定词及其前置词性和后置词性,将出现该疑问词和该前置词性时句子成为疑问句的概率作为样本第一特征值;将出现该疑问词和该后置词性时句子成为疑问句的概率作为样本的第二特征值;将出现的否定词个数作为样本的第三特征值;将出现该否定词和该前置词性时句子成为否定句的概率作为样本的第四特征值;将出现该否定词和该后置词性时句子成为否定句的概率作为样本的第五特征值;将该疑问词和该否定词的相对位置作为样本的第六特征值;将出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率分别作为样本的第七特征值和第八特征值;或者将出现该否定词在前而该疑问词在后时句子分别成为疑问句和否定句的概率作为样本的第七特征值和第八特征值;在训练阶段,将训练样本对应的上述第一特征值至第八特征值作为输入对svm进行训练,得到svm分类器;在测试阶段,针对不能通过特殊陈述句决策树、疑问句决策树和否定句决策树判定出结果的测试样本,提取对应的上述第一特征值至第八特征值输入svm分类器,通过svm分类器对测试样本进行分类,得到最终的分类结果。本发明svm分类器将疑问词及其前置词性和后置词性、否定词及其前置词性和后置词性以及疑问词及其前后否定词作为关键特征实现对句型的分类,较好地解决疑问词和否定词多义性的问题,进一步提高了句型分类的准确率。
(3)本发明方法中还构建有非否定词词典,其中非否定词词典用于存储带否定字眼而不属于否定词的非否定词,当根据否定词词典判断出测试样本中有否定词时,本发明方法中再根据非否定词词典判断是否只是为带否定字眼而不属于否定词的非否定词,在不是的情况下,才将判定测试样本判定为有否定词。进一步提高了否定句分类的准确率。
(4)本发明方法通过依存句法分析提取出否定句训练样本中的谓语中心语及状语,然后通过提取的谓语中心语及状语获取到否定句训练样本所具备的以下特征:否定词、状语、谓语否定词数量、状语否定词数量、状语否定词修饰谓语否定词;通过上述否定句训练样本所具备的上述特征以及否定句判断规则训练得到否定句决策树;同时本发明通过依存句法分析提取出候选否定句测试样本中的谓语中心语及状语,否定句决策树根据测试样本中的谓语中心语及状语对否定句进行判定,能够较好地处理否定句判断的问题,进一步提高否定句分类的准确率。
附图说明
图1是本发明中文句型分类方法流程图。
图2是本发明特殊陈述句决策树模型图。
图3是本发明疑问句决策树的决策流程图。
图4是本发明否定句决策树模型图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
本实施例公开了一种基于决策树和svm混合模型的中文句型分类方法,如图1所示,步骤如下:
s1、获取到多个训练样本,并且人工标注出各个训练样本的句型,得到训练样本集;训练样本集中包括特殊陈述句句型、疑问句句型和否定句句型的训练样本;
s2、构建特殊陈述句决策树,首先根据已知的中文语法规则以及训练样本集中各类特殊陈述句训练样本所具备的特征获取到特殊陈述句的判定规则,根据上述判定规则构建得到特殊陈述句决策树;在本实施例中将训练样本集中符合上述判定规则的特殊陈述句训练本输入至上述判定规则进行验证,若验证的准确率达到设定阈值70%,则将对应的判断规则加入到决策树中,从而获取到特殊陈述句决策树。
在本实施例中根据特殊陈述句句型具备的特征将其分为非正常句、任指型陈述句、否定假设句和反问句;具体如下:
在本实施例中将句子为空、句子只有一个符号或句子长度超过一定值句子定义为非正常句;
在本实施例中将句中包括任指连词的句子定义为任指型陈述句,本实施例中任指连词包括“无论”、“不论”和“不管”,当句中出现任指连词“无论”、“不论”时,则定义句子为任指型陈述句,当句中出现任指连词“不管”且任指连词“不管”在句首时,则定义句子为任指型陈述句;例如“无论他怎么做”、“无论他去上学了没有”、“不管他去上学了没有”均为任指型陈述句,而“我不管他了”,此处的“不管”做否定谓语,在本实施例中不被定义为任指型陈述句。
在本实施例中将句中包括否定假设词的句子定义为否定假设句;本实施例中否定假设词包括“即使”、“尽管”、“哪怕”、“就算”和“纵使”,比如“即使他不是中国人”、“就算他没完成作业”均属于否定假设句。
在本实施例中将句中包括反问词的句子定义为反问句。本实施例中反问词包括“还敢”、“何曾”、“何来”、“何止”、“难道”、“难不成”、“岂不是”和“怎能”。
如图2所示,即为本实施例构建得到的特殊陈述句决策树。
构建疑问句决策树,首先根据已知的中文语法规则以及训练样本集中各类疑问句训练样本所具备的特征获取到疑问句的判定规则,根据上述判定规则构建得到疑问句决策树;本实施例中将训练样本集中符合上述判定规则的疑问句训练样本输入至上述判定规则进行验证,若验证的准确率达到设定阈值70%,则将对应的判断规则加入到决策树中,从而获取到疑问句决策树。
其中根据疑问句句型所具备的特征将其分为是非疑问句、选择疑问句、正反疑问句和特殊疑问句;具体如下:
在本实施例中将句中包含正反疑问词且正反疑问词不在句尾的句子定义为正反疑问句;如句子:“今天是个好天气有木有!”、“他是个好人好不好。”,由于上述两个句子中正反疑问词在句尾,因此不为正反疑问句;另外本实施例中将句中出现空格、正反疑问词在空格前且空格后只有一个词的句子也作为正反疑问句,如“你爱不爱他不爱。”这个句子为正反疑问句。因此本实施例中根据已知的中文语法规则以及训练样本集中正反疑问句训练样本所具备的上述特征获取到正反疑问句的判定规则;
在本实施例中将句中包含选择疑问词“是”和“还是”、“是”在“还是”前面、“是”前面没有疑问词并且“是”和“还是”之间没有空格的句子定义为选择疑问句,其中最后一个条件“是”和“还是”之间没有空格针对的问题是使用空格当分隔符时,使得空格前后为两个独立的句子。如“今天是个好天气我们还是去学校吧。”空格前后是两个句子,因此“是”和“还是”有空格时,将不认为是选择疑问句;本实施例中根据已知的中文语法规则以及训练样本集中选择疑问句训练样本所具备的上述特征获取到选择疑问句的判定规则;
在本实施例中将句中包含疑问语气词且疑问语气词位置满足一定条件的句子定义为是非疑问句,其中疑问语气词分为强疑问语气词和弱疑问语气词,所述强疑问语气词包括“吗”和“么”,所述弱疑问词包括“吧”和“啊”;将句中包含强疑问语气词且强疑问语气词在句末或者强疑问语气词后面只有标点符号的句子定义为是非疑问句;将句中包含强疑问语气词、强疑问语气词未在句末且强疑问语气词后面词的个数小于3的句子定义为是非疑问句,例如在句末加表情的句子,此时表情个数小于3,所以也被认为是非疑问句;将句中包含弱疑问语气词且弱疑问语气词在句末或者弱疑问语气词后面跟着问号的句子定义为是非疑问句;本实施例中根据已知的中文语法规则以及训练样本集中是非疑问句训练样本所具备的上述特征获取到是非疑问句的判定规则;
本实施例中将句中包含不含歧义的疑问代词或疑问副词且句尾出现疑问语气词的句子定义为特殊疑问句,其中句尾出现的疑问语气词不为“吗”和“吧”;本实施例中根据已知的中文语法规则以及训练样本集中特殊疑问句训练样本所具备的上述特征获取到特殊疑问句的判定规则。
构建否定句决策树,首先通过依存句法分析提取出训练集中否定句训练样本谓语中心语及状语,通过上述提取的谓语中心语及状语获取到否定句训练样本所具备的以下特征:否定词、状语、谓语否定词数量、状语否定词数量、状语否定词修饰谓语否定词;然后根据已知的中文语法规则以及训练样本集中否定句训练样本所具备的特征获取到否定句的判定规则,最后根据否定句的判定规则和否定句训练样本所具备的特征,采用id3算法训练得到否定句决策树;本实施例中通过id3算法训练后,否定句决策树从上至下每一层的特征分别为:判定是否存在否定词、判定是否存在状语、判定谓语否定词数量、判定状语否定词数量、判定状语否定词是否修饰谓语否定词,如图4所示即为本实施例构建得到的否定句决策树模型。
s3、构建svm分类器,具体步骤如下:
s31、将训练样本集中的各个训练样本首先分别输入至步骤s2中构建得到的特殊陈述句决策树、疑问句决策树和否定句决策树中,获取到上述三个决策树均不能判定出结果的训练样本;
s32、针对步骤s31获取到的三个决策树均不能判定出结果的训练样本,根据第一疑问词词典和否定词词典,识别出每个训练样本中的疑问词、及其前置词性和后置词性,其中疑问词前置词性和后置词性分别指的是疑问词相邻前面词的词性和相邻后面词的词性;识别出步骤s31获取到的这些训练样本中的每个训练样本中的否定词、及其前置词性和后置词性,其中否定前置词性和后置词性分别指的是否定词相邻前面词的词性和相邻后面词的词性;识别出每个训练样本中的疑问词和否定词的相对位置,识别出每个训练样本中否定词的个数;本实施例中第一疑问词词典包括中文和英文的疑问代词和副词;本实施例中第一疑问词词典包括如下疑问代词和副词:how、how、what、what、when、when、where、where、which、which、who、who、whom、whom、whose、whose、why、why、到底、多会儿、多會兒、多久、多少、多咱、反倒、干吗、干嘛、干什么、幹嗎、幹嘛、幹什麼、何、何来、何來、何时、何時、何为、何為、何用、何在、几时、幾時、究竟、可好、毛线、毛線、莫非、哪、哪儿、哪兒、哪个、哪個、哪会儿、哪會兒、哪款、哪里、哪裡、哪些、哪种、哪種、难道、难怪、難道、難怪、岂、豈、如何、啥、啥时候、啥時候、什么、什麼、神马、神馬、孰是孰非、谁、誰、为何、为毛、为啥、为什么、為何、為毛、為啥、為什麼、要不、有何、有木有、怎、怎的、怎地、怎会、怎會、怎么、怎么办、怎么回事、怎么弄、怎么样、怎么着、怎么做、怎麼、怎麼辦、怎麼回事、怎麼弄、怎麼樣、怎麼著、怎麼做、怎样、怎樣、知否、肿么、腫麼。本实施例中否定词词典包括以下否定词:別、别、并非、並非、不、不必、不曾、不成、不大、不得、不对、不對、不敢、不够、不夠、不管用、不好、不合理、不会、不會、不见、不見、不堪、不可、不了、不利、不利於、不利于、不料、不能、不配、不然、不让、不讓、不是、不说、不說、不同、不想、不要、不宜、不易、不用、不再、不足、吃不得、从不、从来不、從不、從來不、都木、都木有、非、覅、搞不懂、还没、還沒、行不通、毫不、记不清、記不清、经不起、經不起、决不能、決不能、绝不、绝不能、絕不、絕不能、看错、看錯、来不及、來不及、卵、沒、沒法、沒什麼、沒用、沒用過、沒有、没、没法、没什么、没用、没用过、没有、木、木有、少於、少于、未必、未能、无、无度、无法、无可、無、無度、無法、無可、勿、也別、也别。
s33、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个疑问词时句子成为疑问句的概率,出现某个疑问词和某种前置词性搭配时句子为疑问句的概率;出现某个疑问词和某种后置词性搭配时句子为疑问句的概率;然后将出现某个疑问词和某种前置词性搭配时句子为疑问句的概率除以出现某个疑问词时句子成为疑问句的概率得到出现某个疑问词和某种前置词性搭配时句子为疑问句的条件概率;将出现某个疑问词和某种后置词性搭配时句子为疑问句的概率除以出现某个疑问词时句子成为疑问句的概率得到出现某个疑问词和某种后置词性搭配时句子为疑问句的条件概率;
例如针对训练样本中识别出的某疑问词a,某疑问词a前一个词的词性b1,后一个词的词性b2;则
出现某个疑问词和某种前置词性搭配时句子为疑问句的条件概率为:
p(前置搭配属于疑问句)=p(a,b1)/p(a);
出现某个疑问词和某种后置词性搭配时句子为疑问句的条件概率为:
p(后置搭配属于疑问句)=p(a,b2)/p(a);
其中p(a,b1)为出现某个疑问词a和某种前置词性b1搭配时句子为疑问句的概率,p(a,b2)为出现某个疑问词a和某种后置词性b2搭配时句子为疑问句的概率,p(a)为出现某个疑问词a时句子成为疑问句的概率。
s34、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个否定词时句子成为否定句的概率,出现某个否定词和某种前置词性搭配时句子为否定句的概率;出现某个否定词和某种后置词性搭配时句子为否定句的概率;然后将出现某个否定词和某种前置词性搭配时句子为否定句的概率除以出现某个否定词时句子成为否定句的概率得到出现某个否定词和某种前置词性搭配时句子为否定句的条件概率;将出现某个否定词和某种后置词性搭配时句子为否定句的概率除以出现某个否定词时句子成为否定句的概率得到出现某个否定词和某种后置词性搭配时句子为否定句的条件概率;
s35、根据步骤s31获取到的这些训练样本的人工标注的句型,采用数据统计法统计出训练样本中出现某个疑问词在前而某个否定词在后时句子分别成为疑问句和否定句的概率,出现某个否定词在前而某个疑问词在后时句子分别成为疑问句和否定句的概率;
例如针对训练样本中出现疑问词a,否定词b,且a在b之前。则本实施例方法统计出的训练样本中出现某个疑问词在前而某个否定词在后时句子分别成为疑问句和否定句的概率为:
py(a_b)=cy(a_b)/c(a_b);
pf(a_b)=cf(a_b)/c(a_b);
其中c(a_b)为步骤s31获取到的训练样本中出现疑问词a在前而否定词b在后的次数;cy(a_b)表示出现疑问词a在前而否定词b在后的训练样本中为疑问句的个数,cf(a_b)表示出现疑问词a在前而否定词b在后的训练样本中为否定句的个数;py(a_b)表示出现某个疑问词在前而某个否定词在后时句子成为疑问句的概率;pf(a_b)表示出现某个疑问词在前而某个否定词在后时句子成为否定句的概率;
s36、针对于步骤s31获取到的三个决策树均不能判定出结果的训练样本,通过以下步骤提取出这些训练样本中每个训练样本的特征,具体如下:
s361、当训练样本中识别出疑问词时,分别获取到该疑问词的前置词性和后置词性,然后通过步骤s33获取到出现该疑问词和该前置词性时句子成为疑问句的概率,作为训练样本第一特征值;同时通过步骤s33获取到出现该疑问词和该后置词性时句子成为疑问句的概率,作为训练样的第二特征值;当训练样本未出现疑问词时,则训练样本的第一特征值和训练样本的第二特征值分别为零;
s362、当训练样本中识别出否定词时,统计否定词的个数,将否定词的个数作为训练样本的第三特征值;同时分别获取到该否定词的前置词性和后置词性,然后通过步骤s34获取到出现该否定词和该前置词性时句子成为否定句的概率,作为训练样本的第四特征值;同时通过步骤s34获取到出现该否定词和该后置词性时句子成为否定句的概率,作为训练样本的第五特征值;当训练样本未出现否定词时,则训练样本对应的第四特征值和第五特征值分别为零;
s363、当训练样本中同时识别出疑问词和否定词时,获取该疑问词和该否定词的相对位置,将该相对位置作为训练样本的第六特征值,在本实施例中,若疑问词在否定词前,则训练样本的第六特征值为1,反之为-1;训练样本中若该疑问词在前而该否定词在后,则通过步骤s35获取到出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;训练样本中若该否定词在前而该疑问词在后,则通过步骤s35获取到出现该否定词在前而该疑问词在后时句子分别成为疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;
s37、将步骤s36中获取到的训练样本的第一特征值、第二特征值、第三特征值、第四特征值、第五特征值、第六特征值、第七特征值和第八特征值分别作为输入对svm进行训练,得到svm分类器;
s4、当获取到测试文本数据时,首先进行数据预处理得到测试样本,然后将测试样本输入至步骤s2构建得到的特殊陈述句决策树中,如图2所示,通过特殊陈述句决策树判断测试样本句型,若特殊陈述句决策树未能判定出测试样本,那么进行步骤s5的处理;其中图2中length表示的是句子的长度;在本实施例中数据预处理的过程具体如下:
s41、以汉语标点符号中的句号、感叹号、问号和逗号以及英文标点符号中的感叹号、问号和逗号作为断句的分隔符对测试文本数据进行断句,得到测试样本,并且保留汉语标点符号中的问号和英文标点符号中的问号;
s42、对断句后的获取到的测试样本进行去干扰处理;在本实施例中去除测试样本中的以下干扰:
(1)将测试样本中出现的中括号【】及中括号【】里面的内容进行删除;
(2)将测试样本中出现的【和?以及【和?之间的内容进行删除,将测试样本中的【和?以及【和?之间的内容进行删除;
(3)将测试样本中#以及#和#之间的内容进行删除;
(4)将测试样本中//@和:以及//@和之间的内容进行删除,将测试样本中的//@和:以及//@和:之间的内容进行删除;
(5)将测试样本中@和制表符及它们之间的内容进行删除,将测试样本中的@和空格符及它们之间的内容进行删除;
(6)当测试样本中仅有】而没有【时,则将】及其之前的内容进行删除;
(7)将测试样本中尖括号《》及其中的内容进行删除;
(8)将测试样本中括号及其中的内容进行删除:
(9)将测试样本中的中文省略号“……”替换为逗号“,”;
(10)将测试样本中的中文分号“;”和英文分号“;”替换为逗号“,”;
(11)将测试样本中的双引号“”及双引号“”中的内容进行删除;
(12)将测试文本中的网址进行删除;
s43、利用分词工具对测试样本进行分词和词性标注,得到分词和词性标注后的测试样本,即为数据预处理后的测试样本。
s5、首先根据第二疑问词词典和否定词词典判断测试样本中是否有疑问词和否定词,若测试样本中只有疑问词而没有否定词,则将测试样本作为候选疑问句,进入步骤s6;若测试样本只有否定词而没有疑问词,则将测试样本作为候选否定句,进入步骤s7;若测试样本中既有否定词又有疑问词,则进入步骤s8;其中第二疑问词词典为第一疑问词词典基础上加上疑问语气词后得到的词典;其中加上的疑问语气词包括中文疑问语气词“吗、呢、吧、咩、捏、咯、?、?”。
s6、将测试样本输入至步骤s2构建的疑问句决策树,通过疑问句决策树对测试样本的句型进行判定,输出判定结果,若疑问句决策树未能输出测试样本的判定结果,则将测试样本进行步骤s8的处理;其中如图3所示,本实施例中疑问句决策树针对输入的测试样本首先判定是否为正反疑问句,当判定为不是正方疑问句的情况下判断是否为选择疑问句,当判定为不是选择疑问句时再判定是否为是否非疑问句,当判定为不是是非疑问句时再判定是否为特殊疑问句,当判定为不是特殊疑问句时,即疑问句决策树没有输出判定结果时,则将测试样本进行步骤s8的处理。
s7、通过依存句法分析提取出测试样本的谓语以及修饰该谓语的状语,根据测试样本的谓语以及修饰该谓语的状语获取到测试样本以下特征:否定词、状语、谓语否定词数量、状语否定词数量、状语否定词修饰谓语否定词;并且输入至步骤s2中构建的否定句决策树,如图4所示,否定句决策树根据测试样本上述特征对测试样本的句型进行判定,输出判定结果,若否定句决策树未能输出测试样本的判定结果,则将测试样本进行步骤s8的处理;
本步骤中否定句决策树根据测试样本上述特征通过规则对测试样本进行判定:
s71、若测试样本只有谓语,没有状语,则如果谓语包含有否定词且谓语否定词的数量个数不为2,则将测试样本判定为否定句;
s72、若测试样本既有谓语,也有状语,但谓语不包含否定词,则如果状语存在否定词,且状语否定词个数不为2,则将测试样本判定为否定句;
s73、若测试样本既有谓语,也有状语,但状语不包含否定词,则如果谓语包含有否定词,且谓语否定词个数不为2,则将测试样本判定为否定句。
s74、若测试样本既有谓语,也有状语,且状语和谓语都有否定词,但状语否定词并不是修饰谓语否定词,则将测试样本判定为否定句。
其中图4中neg_exist=1表示句中存在否定词;adv_exist=0表示测试样本只有谓语而没有状语;adv_exist=1表示测试样本既有谓语也有状语;neg_count表示谓语否定词的个数,neg_count=0表示谓语否定词的数量个数为0个,neg_count=1表示谓语否定词的数量个数为1个,neg_count!=2表示谓语否定词的数量个数不为2个,neg_count>=2表示谓语否定词的数量个数大于等于2个;adv_neg_count表示状语包含否定词的个数,adv_neg_count=0表示状语否定词的个数为0;adv_neg_count!=2表示状语否定词的个数不为2个;adv_neg_count>=2表示状语否定词的个数大于等于2个。
s8、通过第一疑问词词典和否定词词典分别识别出测试样本中的疑问词和否定词,然后通过以下步骤提取出测试样本的特征;
s81、当测试样本中有疑问词时,分别获取到该疑问词的前置词性和后置词性,然后通过步骤s33获取到出现该疑问词和该前置词性时句子成为疑问句的概率,作为测试样本第一特征值;同时通过步骤s33获取到出现该疑问词和该后置词性时句子成为疑问句的概率,作为测试样本的第二特征值;当测试样本未出现疑问词时,则测试样本的第一特征值和第二特征值分别为零;
s82、当测试样本中有否定词时,统计否定词的个数,将否定词的个数作为测试样本的第三特征值;同时分别获取到该否定词的前置词性和后置词性,然后通过步骤s34获取到出现该否定词和该前置词性时句子成为否定句的概率,作为测试的第四特征值;同时通过步骤s34获取到出现该否定词和该后置词性时句子成为否定句的概率,作为测试样本的第五特征值;当测试样本未出现否定词时,则测试样本的第四特征值和第五特征值分别为零;
s83、当测试样本中同时有疑问词和否定词时,获取该疑问词和该否定词的相对位置,将该相对位置作为测试样本的第六特征值,在本实施例中,若疑问词在否定词前,则测试样本的第六特征值为1,反之为-1;测试样本中若该疑问词在前而该否定词在后,则通过步骤s35获取到出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率,且分别作为测试样本的第七特征值和第八特征值;测试样本中若该否定词在前而该疑问词在后,则通过步骤s35获取到出现该否定词在前而该疑问词在后时句子分别成为疑问句和否定句的概率,且分别作为测试样本的第七特征值和第八特征值;
s9、将测试样本的第一特征值、第二特征值、第三特征值、第四特征值、第五特征值、第六特征值、第七特征值和第八特征值分别输入至步骤s364训练好的svm分类器中,通过svm分类器的输出获取到测试样本的句型判定结果。
本实施例中还包括构建非否定词词典的步骤,其中非否定词词典中存储带否定字眼而不属于否定词的非否定词;本实施例中非否定词词典包括以下非否定词:不变、不變、不错、不錯、不但、不得不、不等、不过、不過、不介意、不仅、不僅、不久、不久前、不愧、不满、不滿、不停、不吐不快、对不起、對不起、告別、告别、绝不、絕不、沒錯、沒關係、沒事、沒准、没错、没关系、没事、没准、无所谓、无忧、無所謂、無憂、要不是、只不过、只不過。
本实施例上述步骤s5中当根据否定词词典判断出测试样本中有否定词时,则再根据非否定词词典判断是否为带否定字眼而不属于否定词的非否定词,若是,则判定测试样本没有否定词,若否,则将判定测试样本有否定词。进而进行步骤s5之后的操作。通过本实施例中的非否定词词典带将带否定字眼而不属于否定词的非否定词去掉,以避免将非否定词误认为是否定词,进一步提到否定句分类的准确性。
在信息论中,信息熵(entropy)越小表示数据的混乱程度越低,数据纯度越高。其中id3算法中采用信息增益(informationgain)来衡量节点分裂后的信息量损失。该算法的核心思想是选择分裂后信息增益最大的特征进行分裂。
设d为训练元组集合,则采用以下公式计算d的信息熵:
上式中,m代表该元组集合总共被划分到多少个类别,“句式判定”是每个元组的类别,因此m=2。p(i)代表的是第i个类别出现的概率。假设现在对属性a进行分裂,则可以根据下面的公式求出a分裂后的信息熵:
在上述公式中,v代表属性a的取值个数,比如a的取值有{a1,a2,a3,a4},则v=4。dj代表所有属性a值等于aj的元组集合。|d|表示的是元组集合d的元组数量。该公式代表的含义是a分裂后的信息熵等于分裂后各个节点各自的信息熵之和。
信息增益即为上述两者的差值:
gain(a)=entropy(d)-entropya(d)
本实施例上述步骤s2中否定句决策树训练所采用的id3算法就是在每次分裂前,使用信息增益计算还未使用特征的信息增益,然后选择出信息增益值最大的特征作为分裂标准。重复这一过程直到决策树训练完毕。
本实施例上述方法首先获取到训练样本,并且对训练样本的句型进行人工标注,得到训练样本集;然后根据训练样本集中各类句型的训练样本构建得到特殊陈述句决策树、疑问句决策树和否定句决策树,并且将训练样本集中的各训练样本分别输入至特殊陈述句决策树、疑问句决策树和否定句决策树进行句型判定;最后提取出特殊陈述句决策树、疑问句决策树和否定句决策树均不能判定的训练样本,针对这些训练样本,通过第一疑问词词典和否定词词典提取各训练样本中的疑问词和否定词,并且统计出以下情况:出现某个疑问词和某种前置词性搭配时句子为疑问句的条件概率、出现某个疑问词和某种后置词性搭配时句子为疑问句的条件概率、出现某个否定词和某种前置词性搭配时句子为否定句的条件概率、出现某个否定词和某种后置词性搭配时句子为否定句的条件概率、出现某个疑问词在前而某个否定词在后时句子分别成为疑问句和否定句的概率、出现某个否定词在前而某个疑问词在后时句子分别成为疑问句和否定句的概率;然后识别出每个训练样本中的疑问词及其前置词性和后置词性、否定词及其前置词性和后置词性,获取到出现该疑问词和该前置词性时句子成为疑问句的概率,作为训练样本第一特征值;获取到出现该疑问词和该后置词性时句子成为疑问句的概率,作为训练样的第二特征值;获取到训练样本中否定词的个数作为训练样本的第三特征值;获取到出现该否定词和该前置词性时句子成为否定句的概率,作为训练样本的第四特征值;获取到出现该否定词和该后置词性时句子成为否定句的概率,作为训练样本的第五特征值;获取该疑问词和该否定词的相对位置,将该相对位置作为训练样本的第六特征值;获取到出现该疑问词在前而该否定词在后时句子分别成为疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;或者获取到出现该否定词在前而该疑问词在后时句子分别成为训练样本的疑问句和否定句的概率,且分别作为训练样本的第七特征值和第八特征值;将训练样本的第一特征值至第八特征值分别作为输入对svm进行训练,得到svm分类器。当获取到测试样本后,首先通过特殊陈述句决策树进行句型判定,在特殊陈述句决策树未判定出结果的情况下,首先根据第二疑问词词典和否定词词典判断测试样本中是否有疑问词和否定词,在只有疑问词的情况下,将测试样本作为候选疑问句输入至疑问句决策树进行判定;在只有否定词的情况下,将测试样本作为候选否定句输入至否定句决策树进行判定;将疑问句决策树和否定句决策树均未能判定出结果的测试样本以及既有疑问词又有否定词的测试样本提取第一特征值至第八特征值后,通过svm分类器进行分类,得到分类结果;可见,本实施例方法将特殊陈述句决策树、疑问句决策树、否定句决策树和svm分类器相结合既可以比较准确地判断出大部分正常的句子,又可以相对高效地处理一部分难以归纳总结的句子。本发明方法以决策树算法为核心,以svm算法为辅助,可以很好地解决传统决策树模型无法判断的特殊点,提升句型分类的准确率。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!